Hive基础
Hive
数据仓库
数据仓库是存数据的,企业的各种数据往里存,主要目的是为了分析有效数据,后续会基于它产出供分析挖掘的数据,或者数据应用需要的数据,如企业的分析性报告和各类报表等。
可以理解为:数据仓库是面向分析的存储系统
主要特征:是面向主题的、集成的、非易失的和时变的数据集合,用于支持管理决策。数据库与数据仓库的区别:
数据仓库是在数据库已经大量存在的情况下,为了进一步挖掘数据资源,为了决策需要而产生的,它绝不是所谓的 “大型数据库”。
1 Hive介绍
传入一条交互式的SQL在海量的数据中查询
Hive是基于Hadoop的一个数据仓库工具(离线),可以将结构化的数据文件映射成一张表,并提供SQL查询功能。
其本质是将SQL语句转化为MapReduce任务在hadoop上执行,底层是由HDFS来提供数据的存储。可以理解为是一个将SQL语句转化为MapReduce任务的工具,也可以说hive就是MapReduce的客户端
Hive中的一个表、库其实就是HDFS上的一个目录,按表名把文件夹分开 ,如果是分区表,则分区值是子文件夹。
2 Hive架构
- 元数据保存在mysql 中
- 数据保存在hdfs 上
- 使用MapReduce处理

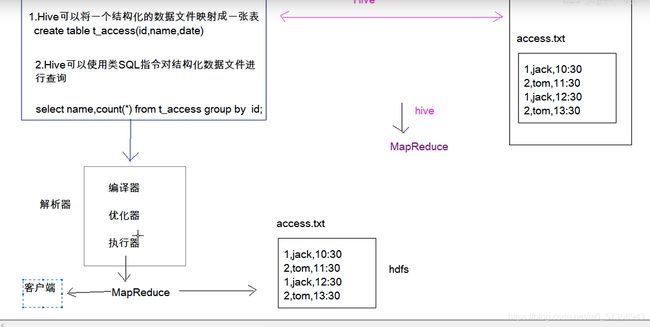
用户接口 :就可以理解为那些类SQL指令(HQL)就是用户接口。
元数据存储 :Hive将元数据存储在数据库中(metastore),目前只支持mysql、derby。
通常使用mysql存储元数据,不用自带的derby。
因为元数据一般比较小,数据量比较少,需要查询速度快。元数据包括表的名字、表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等;
由解释器、编译器、优化器完成HQL语句查询,生成的查询保存在HDFS中,并在随后由MapReduce调用执行。
3 Hive存储格式
- 列式存储和行式存储对比

-
行存储特点:
查询一整行数据时,行存储只需找到其中一个值,其余的值都在相邻地方,而列存储则需要去每个聚集的字段找到对应的每个列的值,此时行存储查询快。 -
列存储特点:
因为每个字段的数据聚集存储,所以在查询只需要少数几个字段的时候,能大大减少读取的数据量;每个字段的数据类型一定是相同的,列式存储可以针对性的设计更好的压缩算法。

每个orc文件由header、body、tail三部分组成。
body由1个或多个stripe组成,每个stripe一般为hdfs的块大小。每个stripe由index data、row data、stripe footer组成。
index data:轻量级的索引,默认是为各列每隔1W行做一个索引。每一W行进行列存。
textfile、sequencefile、orc、parquet
1、TextFile:文本格式,不做压缩,hive在创建的时候如果不指定格式,默认这种格式
优点:简单,加载速度快
缺点:磁盘开销大2、SequenceFile:以二进制方式存储,压缩率比较高
优点:磁盘占用最低
缺点:加载速度比较慢3、orc:列式存储的文件格式,orc文件可以提高hive读写数据和处理数据的性能
优点:磁盘空间占用少一点(少10%)
缺点:加载速度慢一点4、parquet:列式存储的文件格式,是spark默认的存储格式
行组(row group):一个行组对应逻辑表中的若干行。
列块(column chunk):一个行组中的一列保存在一个列块中。
页(page):一个列块的数据会划分为若干个页
4 Hive建表
create (external) table student
( id bigint (comment) '学生id', // 定义字段名,字段类型,comment是注解,可写可不写
name string,
age int,
gender string,
clazz string
)
partitioned by(pt string) // 可选,创建分区表
clustered by (clazz) into 12 buckets // 可选,创建分桶
row format delimited fields terminated by ',' // 必选,指定列分隔符
location '/data/hive' // 可选, 指定Hive表的数据的存储位置,通常跟外部表一起使用
stored as rcfile; // 可选,指定储存格式为rcfile,默认textfile格式
partitioned by(year string,month string) //二级分区
4.1 建表方式(5种)
- 使用默认建表方式
create table student
( id bigint, // 定义字段名,字段类型
name string,
age int,
gender string,
clazz string
)
row format delimited fields terminated by ','; //指定分割符
- 指定location
create external table student
( id bigint,
name string,
age int,
gender string,
clazz string
)
row format delimited fields terminated by ','
location '/data/hive'; //指定Hive表的数据的存储位置,一般在数据已经上传到HDFS(也就是在目录已经存在,指定一下位置指向这个目录),想要直接使用,会指定Location,通常Location会跟外部表(external)一起使用,内部表一般使用默认的location
- 指定存储格式
create table student
( id bigint,
name string,
age int,
gender string,
clazz string
)
row format delimited fields terminated by ','
stored as rcfile; //指定存储格式
注意:除textfile以外,其他存储格式的数据都不能直接加载(就是不能直接select,格式不一样),需要使用从表加载的方式(就是insert into)
- **create table xxx as select_statement(SQL语句) **
create table student as select * from student1;
truncate table students; //不要表的内容了,内部表才能truncate
- create table xxx like table_name
create table student like student1; //只想建表,不加载数据
5 Hive加载数据
小技巧:在hive里也可以操作hdfs命令,就是把hdfs去掉,直接从dfs开始写
-
使用 hdfs dfs -put ’ linux 本地数据’ ‘hive表对应的hdfs下的目录’
-
使用 load data inpath
//下列命令需要在hive shell里执行
方式1:
//将hdfs上的/input1目录下的数据 移动至 students表对应的hdfs目录下。移动、移动、移动
load data inpath '/input1/students.txt' into table students;
方式2:
//加上 local 关键字,可以将Linux本地路径下的文件,上传至hive表所对应的hdfs目录下
load data local inpath '/usr/local/soft/data/students.txt' into table students;
方式3:
// overwrite 表示覆盖
load data local inpath '/usr/local/soft/data/students.txt' overwrite into table students;
-
create table xxx as SQL语句
-
insert into / overwrite table xxx SQL语句 (没有as)
//将student1 表的数据加载到students中,这里是复制,不是移动,students1表中的数据不会丢失
insert into table students select * from students1;
//overwrite 覆盖插入
insert overwrite table students select * from students1;
6 Hive的各种表
6.1 内部表与外部表
内部表(Managed tables)vs 外部表(External tables)
// 内部表
create table students_internal
(
id bigint,
name string,
age int,
gender string,
clazz string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
LOCATION '/input1';
// 外部表
create external table students_external
(
id bigint,
name string,
age int,
gender string,
clazz string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
LOCATION '/input2';
删除表 :
hive> drop table students_internal;
Moved: 'hdfs://master:9000/input1' to trash at: hdfs://master:9000/user/root/.Trash/Current
OK
Time taken: 0.474 seconds
hive> drop table students_external;
OK
Time taken: 0.09 seconds
hive>
可以看出,删除内部表时,表中的数据(hdfs上的目录文件)会和表的元数据一起删除;
删除外部表时,只会删除表的元数据,表中的数据不会被删除(可以理解为在HDFS上还保存着,但在Hive中已经没有了,查不到此表信息了)一般在公司中,外部表使用的多一点,可以避免误删。外部表的数据跟表是分开的,只是表结构和表信息交由hive管理。
外部表还可以将其他数据源中的数据 映射到hive中,比如HBase
设计外部表的初衷就是 让 表的元数据 与 数据 解耦
6.2 分区表
分区表实际上是在表的目录下以分区命名,又创建一个子目录
作用:进行分区裁剪,避免全局扫描,减少MapReduce处理的数据量,提高效率一般在公司的hive中,所有的表基本上都是分区表,通常按日期分区、地域分区。
分区表在使用的时候记得加上分区字段分区也不是越多越好,一般不超过3级,根据实际业务衡量
建立分区表 :
create table students_pt
(
id bigint,
name string,
age int,
gender string,
clazz string
)
PARTITIONED BY(pt string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
删除、增加
// 增加一个分区
alter table students_pt add partition(pt='20210614');
// 删除一个分区
alter table students_pt drop if exists partition(pt='20210614');
往分区中插入数据 :
insert into table students_pt partition(pt='20210614');
load data local inpath '/usr/local/soft/data/students.txt' into table students_pt partition(pt='20210614');
查询分区表数据 :
// 全表扫描,效率低
select count(*) from students_pt;
// 使用where条件进行分区扫描,避免全表扫描,效率高
select count(*) from students_pt where pt='20210614';
// 也可以在where条件中使用非等值(一个范围)判断
select count(*) from students_pt where pt<='20210616' and pt>='20210614';
6.3 动态分区
有时候原始表中的数据里面包含了 “日期字段 dt”,我们需要根据dt 中不同的日期,分为不同的分区,将原始表改造为分区表。
hive默认不开启动态分区
动态分区 :根据数据中某几列不同的取值 划分不同的分区
开启hive的动态分区支持
# 表示开启动态分区
hive> set hive.exec.dynamic.partition=true;
# 表示动态分区模式:strict(需要配合静态分区一起使用)、nostrict
# strict: insert into table students_pt partition(dt='anhui',pt) select ......,pt from students;
hive> set hive.exec.dynamic.partition.mode=nostrict;
# 表示支持的最大的分区数量为1000,可以根据业务自己调整
hive> set hive.exec.max.dynamic.partitions.pernode=1000;
建立原始表加载数据
create table students_dt
(
id bigint,
name string,
age int,
gender string,
clazz string,
dt string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
建立分区表并加载数据
create table students_dt_p
(
id bigint,
name string,
age int,
gender string,
clazz string
)
PARTITIONED BY(dt string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
插入数据
// 分区字段需要放在 select 的最后,如果有多个分区字段 同理,它是按位置匹配,不是按名字匹配,也不能用*
insert into table students_dt_p partition(dt) select id,name,age,gender,clazz,dt from students_dt;
// 比如下面这条语句会使用age作为分区字段,而不会使用student_dt中的dt作为分区字段
insert into table students_dt_p partition(dt) select id,name,age,gender,dt,age from students_dt;
上单讲分区:https://developer.aliyun.com/article/81775
6.4 分桶
分桶实际上是对文件(数据)的进一步切分
相同的key进入同一个reduce中
Hive默认关闭分桶
作用:在往分桶表中插入数据的时候,会根据 clustered by 指定的字段 进行hash分组 对指定的buckets个数 进行取余,进而可以将数据分割成buckets个数个文件,以达到是数据均匀分布,方便我们取抽样数据,提高join效率
分桶字段 需要根据业务进行设定 可以解决数据倾斜问题
开启分桶开关
hive> set hive.enforce.bucketing=true;
建立分桶表
create table students_buks
(
id bigint,
name string,
age int,
gender string,
clazz string
)
CLUSTERED BY (clazz) into 12 BUCKETS
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
往分桶表中插入数据
// 直接使用load data 并不能将数据打散
load data local inpath '/usr/local/soft/data/students.txt' into table students_buks;
// 需要使用下面这种方式插入数据,才能使分桶表真正发挥作用
insert into students_buks select * from students;
Hive会自动根据bucket个数自动分配Reduce task的个数
Reduce个数与bucket个数一致https://zhuanlan.zhihu.com/p/93728864 Hive分桶表的使用场景以及优缺点分析
7 HQL基本规则
- count(*)、count(1)、count(字段名)
1、count(*)包括了所有的列,相当于行数,在统计结果的时候,不会忽略列值为NULL
2、count(1)包括了忽略所有列,用1代表代码行,在统计结果的时候,不会忽略列值为NULL
3、count(列名)只包括列名那一列,在统计结果的时候,会忽略列值为空(这里的空不是只空字符串或者0,而是表示null)的计数,即某个字段值为NULL时,不统计。https://blog.csdn.net/Jame_s/article/details/102926383
- HQL执行优先级
from 、join on 、where 、group by 、having(再组内过滤) 、select 、order by 、limit
首先我是不是需要知道我要从哪个表去获取我想要的,也就是from;现在我知道从哪个表获取了,可是并不是这个表里面所有的信息都是我需要的,我需要把一些不需要的去掉(比如测试订单),或是把一些我需要的筛选出来,这就是where;现在我把我需要的订单明细筛选出来,可是我想要每个品类的订单量,这个时候是不是需要做一个分组聚合,也就是group by;分组聚合后的结果也并不是我们全部都要,我们只要大于10的品类,所以需要把大于10的筛选出来,非大于10的品类过滤掉,这就是having;现在我们想要的大部分信息都已经出来了,我们就可以用select把他们查询出来了;因为我们最后需要取前三的品类,所以我们需要把查询出来的结果进行一个降序排列,即order by;最后一步就是只把前三显示出来,做一个限制就行,也就是limit
https://blog.csdn.net/junhongzhang/article/details/90746217
- where 条件里不支持子查询,实际上支持 in、not in、exists、not exists
select * from dept where deptno in (select deptno from dept a where a.deptno == 40);
select * from dept t1 where exists (select deptno from dept t2 where t1.deptno == t2.deptno);
-
Hive中大小写不敏感
-
在hive中,数据中如果有null字符串,加载到表中的时候会变成 null (不是字符串)
如果需要判断 null,使用 某个字段名 is null 这样的方式来判断
或者使用 nvl() 函数,不能 直接 某个字段名 == null
8 Hive 数据类型
整型:tinyint 、smallint 、 int 、 bigint
浮点型:float 、double
布尔型:boolean 一般布尔类型会转换为1和0
字符串:string
时间类型 :
-
时间戳:timestamp 从1970年1月1日 0时0分0秒0毫秒 到现在
-
日期:date
create table testDate( ts timestamp ,dt date ) row format delimited fields terminated by ','; 数据(格式有严格要求):2021-01-14 14:24:57.200,2021-01-11
复杂数据类型:
-
array
create table testArray( name string, weight array<string> ) row format delimited fields terminated by '\t' collection items terminated by ','; //指定这些数之间的分割符 数据: 杨老板 140,160,180 张志凯 160,200,180 select * from testArray; 杨老板 ["140","160","180"] 张志凯 ["160","200","180"] select name,weight[0] from testArray; 杨老板 140 张志凯 160 -
map
key:value,key2:v2,k3:v3 create table scoreMap( name string, score map<string,int> ) row format delimited fields terminated by '\t' collection items terminated by ',' map keys terminated by ':'; //指定kv之间的分隔符 数据: 小明 语文:91,数学:110,英语:40 小红 语文:100,数学:130,英语:140 select name,score['语文'] from scoreMap; 小明 {"语文":91,"数学":110,"英语":40} 小红 {"语文":100,"数学":130,"英语":140} select name,score['语文'] from scoreMap; 小明 91 小红 100 -
struct
create table scoreStruct( name string, score struct<course:string,score:int,course_id:int,tearcher:String> ) row format delimited fields terminated by '\t' collection items terminated by ','; 数据: 小明 语文,91,000001,余老师 小红 数学,100,000002,体育老师 select name,score.course,score.score from scoreStruct; 小明 语文 91 小红 数学 100
https://blog.csdn.net/woshixuye/article/details/53317009
HQL语法
- DDL
创建数据库 create database xxxxx;
查看数据库 show databases;
删除数据库 drop database tmp;
强制删除数据库:drop database tmp cascade; //cascade级联,把库里面的表也删了
查看表:SHOW TABLES;
查看表的元信息:
desc test_table;
describe extended test_table;
describe formatted test_table;
查看建表语句:show create table table_XXX
重命名表:
alter table test_table rename to new_table;
修改列数据类型:alter table lv_test change column colxx string;
增加、删除分区:
alter table test_table add partition (pt=xxxx)
alter table test_table drop if exists partition(...);
- DML
select id,name from tb t where ... and .... group by xxx having xxxx order by xxx asc/desc limit n;
-
where: 过滤数据,分区裁剪
-
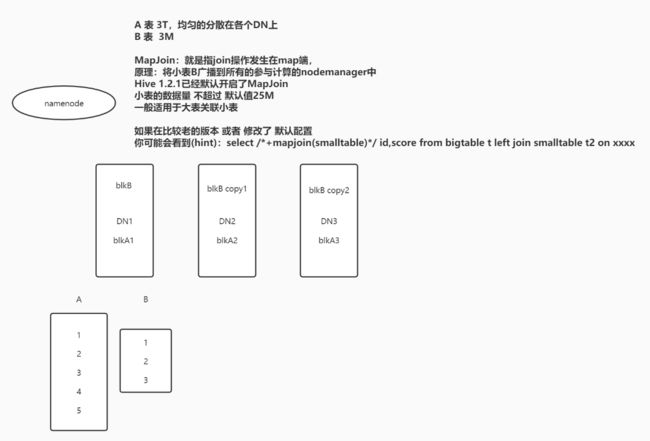
join: left join、right join、join、mapjoin
mapjoin:join发生在map端,小表不切分,广播到所有节点上 大表放左边
- group by:通常和聚合函数一起使用:sum、count、max、avg
- distinct:去重 底层原理是group by
- order by:全局排序

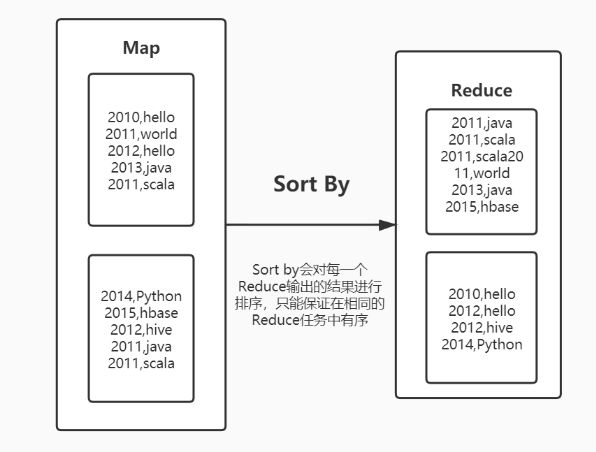
- sort by :局部排序
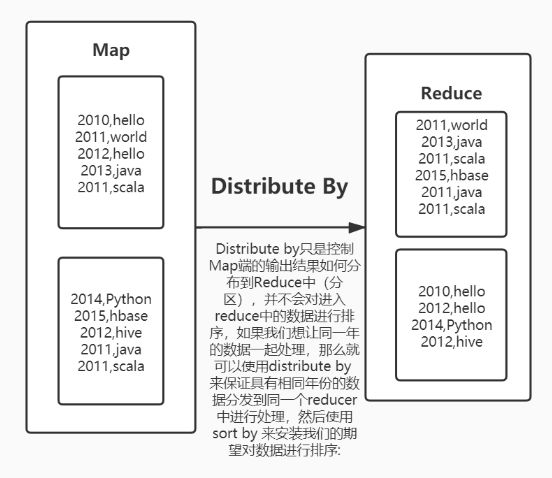
- distribute by:分区
- cluster by
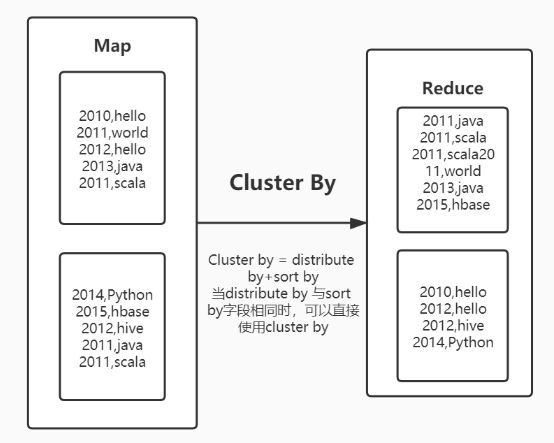
https://zhuanlan.zhihu.com/p/93747613 order by、distribute by、sort by、cluster by详解
数值型
TINYINT — 微整型,只占用1个字节,只能存储0-255的整数。
SMALLINT– 小整型,占用2个字节,存储范围–32768 到 32767。
INT– 整型,占用4个字节,存储范围-2147483648到2147483647。
BIGINT– 长整型,占用8个字节,存储范围-263到263-1。
布尔型BOOLEAN — TRUE/FALSE
浮点型FLOAT– 单精度浮点数。
DOUBLE– 双精度浮点数。
字符串型STRING– 不设定长度。
9 学生SQL练习
1、模仿建表语句,创建subject表,并使用hdfs dfs -put 命令加载数据
create table subject(
subject_id bigint comment '学科id',
subject_name string comment '学科名称'
) comment '学科名字表'
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
学生表
create table students(
id bigint comment '学生id',
name string comment '学生姓名',
age int comment '学生年龄',
gender string comment '学生性别',
clazz string comment '学生班级'
) comment '学生信息表'
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
得分表
create table score(
id bigint comment '学生id',
score_id bigint comment '科目id',
score int comment '学生成绩'
) comment '学生成绩表'
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
2、查询学生分数(输出:学号,姓名,班级,科目id,科目名称,成绩)
select s1.id
,s1.name
,s1.clazz
,s2.score_id
,s3.subject_name
,s2.score
from
students s1
left join
score s2 on s1.id=s2.id
left join
subject s3 on s2.score_id=s3.subject_id
limit 10;
3、查询学生总分(输出:学号,姓名,班级,总分)
先求总分再关联:(1000次)
select s2.id
,s2.name
,s2.clazz
,s1.sum
from students s2
left join
(
select id,sum(score) as sum
from score group by id) s1
on s1.id=s2.id
limit 10;
先关联再求总分:(6000次)
select ss1.id //可以写ss1 或 不写(直接写id),就是不能写s1
,ss1.name
,ss1.clazz
,sum(ss1.score)
from
(
select s1.id
,s1.name
,s1.clazz
,s2.score
from students s1
left join
score s2
on s1.id=s2.id) ss1 group by ss1.id,ss1.name,ss1.clazz
limit 10;
注意:前面查询的字段必须全都放在group by 里面,聚合函数除外(这是和mysql不一样的地方)
其实传一个字段和传很多字段没有区别,对结果没有影响
比如:id可以确定一个人,id+name也可以确定一个人,还更精确了
4、查询全年级总分排名前三(不分文理科)的学生(输出:学号,姓名,班级,总分)
先求总分再关联:
select s1.id
,s1.name
,s1.clazz
,s2.sum
from students s1
left join (
select id
,sum(score) as sum
from score s1
group by id) s2
on s1.id=s2.id
order by s2.sum desc //
limit 3;
5、查询文科一班学生总分排名前10的学生(输出:学号,姓名,班级,总分)
先求总分在关联过滤:
相比第四题加一个where条件:
select s1.id
,s1.name
,s1.clazz
,s2.sum
from students s1
left join(
select id
,sum(score) as sum
from score
group by id) s2
on s1.id=s2.id
where s1.clazz="文科一班" //
order by s2.sum desc
limit 10;
先求总分、过滤,在关联:
select s1.id
,s1.name
,s1.clazz
,s2.sum
from
(select id
,name
,clazz
from students
where clazz="文科一班") s1 //
left join
(select id
,sum(score) sum
from score
group by id) s2
on s1.id=s2.id
order by s2.sum desc //
limit 10;
6、查询每个班级学生总分的平均成绩(输出:班级,平均分)
select s1.clazz
,avg(s2.sum)
from students s1
left join(
select id
,sum(score) as sum
from score
group by id) s2
on s1.id=s2.id
group by s1.clazz;
7、查询每个班级的最高总分(输出:班级,总分)
select s1.clazz
,max(s2.sum)
from students s1
left join(
select id
,sum(score) sum
from score
group by id) s2
on s1.id=s2.id
group by s1.clazz;
8、(思考)查询每个班级总分排名前三的学生(输出:学号,姓名,班级,总分)
开窗函数:
select *
from (
select s1.id
,s1.name
,s1.clazz
,s2.sum
,row_number() over (partition by s1.clazz order by s2.sum desc) as pm
from students s1
left join(
select id
,sum(score) sum
from score
group by id) s2
on s1.id=s2.id) ss1
where ss1.pm<=3;
10 hive常用函数
关系运算
// 等值比较 = == <=>
// 不等值比较 != <>
// 区间比较: select * from default.students where id between 1500100001 and 1500100010;
// 空值/非空值判断:is null、is not null
// like、rlike、regexp用法
数字计算
取整函数:round
向上取整:ceil
向下取整:floor
条件函数
- if: if(表达式,如果表达式成立的返回值,如果表达式不成立的返回值)
select if(1>0,1,0);
select if(1>0,if(-1>0,-1,1),0);
- COALESCE
select COALESCE(null,'1','2'); // 1 从左往右 一次匹配 直到非空为止
select COALESCE('1',null,'2'); // 1
- case when
select score
,case when score>120 then '优秀'
when score>100 then '良好'
when score>90 then '及格'
else '不及格'
end as pingfen
from default.score limit 20;
select name
,case name when "施笑槐" then "槐ge"
when "吕金鹏" then "鹏ge"
when "单乐蕊" then "蕊jie"
else "算了不叫了"
end as nickname
from default.students limit 10;
注意条件的顺序
日期函数
select from_unixtime(1610611142,‘YYYY/MM/dd HH:mm:ss’);
select from_unixtime(unix_timestamp(),‘YYYY/MM/dd HH:mm:ss’);
// ‘2021年01月14日’ -> ‘2021-01-14’
select from_unixtime(unix_timestamp(‘2021年01月14日’,‘yyyy年MM月dd日’),‘yyyy-MM-dd’);
// “04牛2021数加16逼” -> “2021/04/16”
select from_unixtime(unix_timestamp(“04牛2021数加16逼”,“MM牛yyyy数加dd逼”),“yyyy/MM/dd”);
字符串函数
concat(‘123’,‘456’); // 123456
concat(‘123’,‘456’,null); // NULLselect concat_ws(‘#’,‘a’,‘b’,‘c’); // a#b#c
select concat_ws(‘#’,‘a’,‘b’,‘c’,NULL); // a#b#c 可以指定分隔符,并且会自动忽略NULLselect substring(“abcdefg”,1); // abcdefg HQL中涉及到位置的时候 是从1开始计数
select split(“abcde,fgh”,“,”); // [“abcde”,“fgh”]
select explode(split(“abcde,fgh”,“,”)); // abcde
// fgh// 解析json格式的数据
select get_json_object(‘{“name”:“zhangsan”,“age”:18,“score”:[{“course_name”:“math”,“score”:100},{“course_name”:“english”,“score”:60}]}’,“$.score[0].score”); // 100
去看PDF
先看语法,再看返回值,自己试一下。从from去掉后面的。比如:
1. 取整函数 :round
语法: round(double a)
返回值: BIGINT
说明: 返回 double 类型的整数值部分 (遵循四舍五入)
举例:
hive> select round(3.1415926)
3
hive> select round(3.5)
42. 基础类型强制转换 :cast
语法: cast(expr as )返回值:
说明: 将 expr 转换成
举例:
hive> select cast(‘1’ as DOUBLE) ;
OK
1.0
- 时间戳转日期函数 :from_unixtime
语法: from_unixtime(bigint unixtime[, string format])
返回值: stringhive> select from_unixtime(1624280037,“yyyy年MM月dd日”);
OK
2021年06月21日
- 获取当前 UNIX 时间戳函数 : unix_timestamp
hive> select unix_timestamp();
OK
1624280458
先转成了这个格式:2021-04-16 00:00:00
//很乱的日期转换:
// "04牛2021数加16逼" -> "2021/04/16"
select from_unixtime(unix_timestamp("04牛2021数加16逼","MM牛yyyy数加dd逼"),"yyyy/MM/dd");
-
coalesce
select COALESCE(null,'1','2'); // 1 从左往右 一次匹配 直到非空为止 select COALESCE('1',null,'2'); // 1 -
get_json_object:解析json函数
解析json格式的数据 select get_json_object('{"name":"zhangsan","age":18,"score":[{"course_name":"math","score":100},{"course_name":"english","score":60}]}',"$.score[0].score"); // 100 //$代表json本身
Hive 中的wordCount
create table words(
words string
)row format delimited fields terminated by '|';
// 数据
hello,java,hello,java,scala,python
hbase,hadoop,hadoop,hdfs,hive,hive
hbase,hadoop,hadoop,hdfs,hive,hive
select word,count(*) from (select explode(split(words,',')) word from words) a group by a.word; //explode:拆分成多行
// 结果
hadoop 4
hbase 2
hdfs 2
hello 2
hive 4
java 2
python 1
scala 1
11 开窗函数
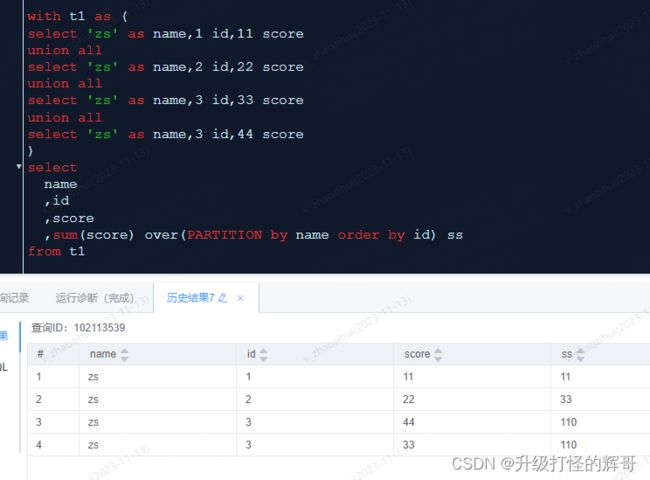
开窗函数 就是又增加了一列数据。
在sql中有一类函数叫做聚合函数,例如sum()、avg()、max()等等。
语法上加 over() 就是开窗函数,例如:sum(score) over(partition by name order by score)。
开窗函数与聚合函数相比,不用写group by,分组字段写在partition by位置。
基本1
over()
emp表:
select avg(SAL)
,1 as tmp_id
from emp;
结果:
2073.214285714286 1
================手动分割线=================
select avg(SAL) over() as avg_sal
,1 as tmp_id
from emp;
结果:
2073.214285714286 1
2073.214285714286 1
2073.214285714286 1
2073.214285714286 1
2073.214285714286 1
2073.214285714286 1
2073.214285714286 1
2073.214285714286 1
2073.214285714286 1
2073.214285714286 1
2073.214285714286 1
2073.214285714286 1
2073.214285714286 1
2073.214285714286 1
================手动分割线=================
select ENAME
,SAL
,avg(SAL) over() as avg_sal -- 开窗函数只是增加一列,不用写group by
from emp;
MILLER 1300 2073.214285714286
FORD 3000 2073.214285714286
JAMES 950 2073.214285714286
ADAMS 1100 2073.214285714286
TURNER 1500 2073.214285714286
KING 5000 2073.214285714286
SCOTT 3000 2073.214285714286
CLARK 2450 2073.214285714286
BLAKE 2850 2073.214285714286
MARTIN 1250 2073.214285714286
JONES 2975 2073.214285714286
WARD 1250 2073.214285714286
ALLEN 1600 2073.214285714286
SMITH 800 2073.214285714286
================手动分割线=================
select ENAME
,SAL
,DEPTNO
,avg(SAL) over(partition by DEPTNO) as avg_sal -- 根据部门编号聚合求平均
from emp;
结果:
MILLER 1300 10 2916.6666666666665
KING 5000 10 2916.6666666666665
CLARK 2450 10 2916.6666666666665
ADAMS 1100 20 2175.0
SCOTT 3000 20 2175.0
SMITH 800 20 2175.0
JONES 2975 20 2175.0
FORD 3000 20 2175.0
TURNER 1500 30 1566.6666666666667
ALLEN 1600 30 1566.6666666666667
BLAKE 2850 30 1566.6666666666667
MARTIN 1250 30 1566.6666666666667
WARD 1250 30 1566.6666666666667
JAMES 950 30 1566.6666666666667
基本2 *
row_number: 无并列排名
dense_rank:有并列排名,依次递增
rank:有并列排名,(跳级)
percent_rank:用法暂时未知 计算公式 = (rank-1) / (组内个数-1)
建表语句
create table new_score(
id int
,score int
,clazz string
,department string
) row format delimited fields terminated by ",";
测试数据
111,69,'class1','department1'
112,80,'class1','department1'
113,74,'class1','department1'
114,94,'class1','department1'
115,93,'class1','department1'
121,74,'class2','department1'
122,86,'class2','department1'
123,78,'class2','department1'
124,70,'class2','department1'
211,93,'class1','department2'
212,83,'class1','department2'
213,94,'class1','department2'
214,94,'class1','department2'
215,82,'class1','department2'
216,74,'class1','department2'
221,99,'class2','department2'
222,78,'class2','department2'
223,74,'class2','department2'
224,80,'class2','department2'
225,85,'class2','department2'
结果展示:
select id
,score
,clazz
,department
,row_number() over (partition by clazz order by score desc) as row_number_rk
,dense_rank() over (partition by clazz order by score desc) as dense_rk
,rank() over (partition by clazz order by score desc) as rk
,percent_rank() over (partition by clazz order by score desc) as percent_rk
from new_score;
id score clazz department row_number_rk dense_rk rk percent_rk
114 94 class1 department1 1 1 1 0.0
214 94 class1 department2 2 1 1 0.0
213 94 class1 department2 3 1 1 0.0
211 93 class1 department2 4 2 4 0.3
115 93 class1 department1 5 2 4 0.3
212 83 class1 department2 6 3 6 0.5
215 82 class1 department2 7 4 7 0.6
112 80 class1 department1 8 5 8 0.7
113 74 class1 department1 9 6 9 0.8
216 74 class1 department2 10 6 9 0.8
111 69 class1 department1 11 7 11 1.0
221 99 class2 department2 1 1 1 0.0
122 86 class2 department1 2 2 2 0.125
225 85 class2 department2 3 3 3 0.25
224 80 class2 department2 4 4 4 0.375
123 78 class2 department1 5 5 5 0.5
222 78 class2 department2 6 5 5 0.5
121 74 class2 department1 7 6 7 0.75
223 74 class2 department2 8 6 7 0.75
124 70 class2 department1 9 7 9 1.0
拓展
lag(col,n):往前第n行数据
lead(col,n):往后第n行数据
fisrt_value(col):组内排序后,取第一个数据
last_value(col):组内排序后,截止到当前行,对于有并列排序的,取最后一个数据
ntile(n):对组内数据再分成 n 组 ,然后标上组号
select id
,score
,clazz
,department
,lag(id,2) over (partition by clazz order by score desc) as lag_num
,lead(id,2) over (partition by clazz order by score desc) as lead_num
,fisrt_value(id) over (partition by clazz order by score desc) as first_v_num
,last_value(id) over (partition by clazz order by score desc) as last_v_num
,ntile(3) over (partition by clazz order by score desc) as ntile_num
from new_score;
id score clazz department lag_num lead_num first_v_num last_v_num ntile_num
114 94 class1 department1 NULL 213 114 213 1
214 94 class1 department2 NULL 211 114 213 1
213 94 class1 department2 114 115 114 213 1
211 93 class1 department2 214 212 114 115 1
115 93 class1 department1 213 215 114 115 2
212 83 class1 department2 211 112 114 212 2
215 82 class1 department2 115 113 114 215 2
112 80 class1 department1 212 216 114 112 2
113 74 class1 department1 215 111 114 216 3
216 74 class1 department2 112 NULL 114 216 3
111 69 class1 department1 113 NULL 114 111 3
221 99 class2 department2 NULL 225 221 221 1
122 86 class2 department1 NULL 224 221 122 1
225 85 class2 department2 221 123 221 225 1
224 80 class2 department2 122 222 221 224 2
123 78 class2 department1 225 121 221 222 2
222 78 class2 department2 224 223 221 222 2
121 74 class2 department1 123 124 221 223 3
223 74 class2 department2 222 NULL 221 223 3
124 70 class2 department1 121 NULL 221 124 3
https://blog.csdn.net/qq_26937525/article/details/54925827
12 行转列 *
lateral view
explode
posexplode:相比与explode,加了一个索引
lateral view explode(weight) testarray t1 as col1
lateral view 先将 explode(weight) testarray 注册成一张表
select name,col1 from testarray lateral view explode(weight) t1 as col1;
//之间也不需要什么关联,直接空格
志凯 150
志凯 170
志凯 180
上单 150
上单 180
上单 190
=========手动分割线==============
select name,col1,col2 from testarray lateral view explode(map('key1',1,'key2',2,'key3',3)) t1 as col1,col2;
志凯 key1 1
志凯 key2 2
志凯 key3 3
上单 key1 1
上单 key2 2
上单 key3 3
=========手动分割线==============
pose : 加上一个索引
select name,col1,col2 from testarray2 lateral view posexplode(weight) t1 as col1,col2;
志凯 0 150
志凯 1 170
志凯 2 180
上单 0 150
上单 1 180
上单 2 190
13 列转行
collect_list
collect_set: 去重
// table
name col1
志凯 150
志凯 170
志凯 180
上单 150
上单 180
上单 190
select name,collect_list(col1) from table group by name;
// 结果
上单 ["150","180","190"]
志凯 ["150","170","180"]
14 自定义函数
自定义函数,可以自己埋点Log打印日志,出错或数据异常方便调试
UDF
一进一出,解析公共字段
继承UDF,重写evaluate方法
UserDefineFunction
-
创建maven项目,并加入依赖
<dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-exec</artifactId> <version>1.2.1</version> </dependency> -
编写代码,继承org.apache.hadoop.hive.ql.exec.UDF,实现evaluate方法,在evaluate方法中实现自己的逻辑
import org.apache.hadoop.hive.ql.exec.UDF; public class MyHiveUDF extends UDF { // hadoop => #hadoop$ public String evaluate(String col1) {//传入的是字符串,返回的也是字符串 // 给传进来的数据 左边加上 # 号 右边加上 $ String result = "#" + col1 + "$"; return result; } }
-
打成jar包并上传至Linux虚拟机
-
在hive shell中,使用 add jar 路径 将jar包作为资源添加到hive环境中
add jar /usr/local/soft/jars/HiveUDF2-1.0.jar; -
使用jar包资源注册一个临时函数,fun_name 是你的函数名(自己起一个名字)
create temporary function fun_name as 'com.shujia.MyHiveUDF'; -
使用函数名处理数据
select fun_name(name) from students limit 10; #施笑槐$ #吕金鹏$ #单乐蕊$ #葛德曜$ #宣谷芹$ #边昂雄$ #尚孤风$ #符半双$ #沈德昌$ #羿彦昌$
UDTF
一进多出
继承GenericUDTF,重写3个方法:
initialize(自定义输出的列名和类型)
process(将结果返回 forword(result) )
close
"key1:value1, key2:value2, key3:value3"
key1 value1
key2 value2
key3 value3
方法一:使用 explode+split
select split("key1:value1,key2:value2,key3:value3",",");
结果:["key1:value1","key2:value2","key3:value3"]
select explode(split("key1:value1,key2:value2,key3:value3",","));
结果:
key1:value1
key2:value2
key3:value3
再按照冒号进行切割,取第0个数据,取第一个数据:
select split(t.col1,":")[0],split(t.col1,":")[1]
from (select explode(split("key1:value1,key2:value2,key3:value3",",")) as col1) t;
结果:
key1 value1
key2 value2
key3 value3
方法二:自定UDTF
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import java.util.ArrayList;
public class HiveUDTF extends GenericUDTF {
// 指定输出的列名 及 类型
@Override
public StructObjectInspector initialize(StructObjectInspector argOIs) throws UDFArgumentException {
ArrayList<String> filedNames = new ArrayList<String>();
ArrayList<ObjectInspector> filedObj = new ArrayList<ObjectInspector>();
filedNames.add("col1");
filedObj.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
filedNames.add("col2");
filedObj.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
return ObjectInspectorFactory.getStandardStructObjectInspector(filedNames, filedObj);
}
// 处理逻辑 my_udtf(col1,col2,col3)
// "key1:value1,key2:value2,key3:value3"
// my_udtf("key1:value1,key2:value2,key3:value3")
@Override
public void process(Object[] cols) throws HiveException {
// cols 表示传入的N列
String col1 = cols[0].toString();
// key1:value1 key2:value2 key3:value3
String[] splits = col1.split(",");
for (String str : splits) {
String[] str1 = str.split(":");
String key = str1[0];
String value = str1[1];
Object obj[] = new Object[2];
obj[0] = key;
obj[1] = value;
// 将数据输出
forward(obj);
}
}
// 在UDTF结束时调用
@Override
public void close() throws HiveException {
}
}
接下来的步骤和上面UDF的步骤一样了
最终结果:
select fun_name("key1:value1, key2:value2, key3:value3");
key1 value1
key2 value2
key3 value3
15 Hive shell
-
第一种:就在linux终端里写
hive -e "select * from test1.students limit 10" -
第二种
hive -f hql文件路径 // 就是将HQL写在一个文件里,再使用 -f 参数指定该文件
16 Hive优化
建表优化
-
分区、分桶
建分区表可以避免全表扫描,进行分区裁剪,减少数据量提高查询效率;
分桶是可以将数据均匀的落到每一个文件里面去。
-
使用外部表,避免数据误删
-
选择合适的文件压缩格式(磁盘很大就不用压缩)
查询优化
- 分区裁剪,先用where过滤,再join
- 分区分桶,合并小文件。关联的时候,对应的桶之间进行关联,用不上的桶,不用关联。分桶不能太多,分桶太多,小文件就会很多。
- 适当的子查询。mapjoin
- order by 、sort by 、distribute by 、cluster by
数据倾斜优化
原因:
key分布不均匀,数据重复
表现:
任务进度长时间维持在99%(或100%),查看任务监控页面,发现只有少量(1个或几个)reduce子任务未完成。因为其处理的数据量和其他reduce差异过大。
单一reduce的记录数与平均记录数差异过大,通常可能达到3倍甚至更多。 最长时长远大于平均时长。
解决方案:
-
从数据源头,业务层面进行优化
-
找到key重复的具体值,进行拆分,hash。异步求和。(就是把key拆开了)
create table data_skew( key string ,col string ) row format delimited fields terminated by ','; // 直接分组求count select key,count(*) from data_skew group by key; // 使用hash 异步求和 select key ,sum(cnt) as sum_cnt from( select key ,hash_key ,count(*) as cnt from( select key ,col ,if(key=='84401' or key == 'null',hash(floor(rand()*6)),0) as hash_key from data_skew ) t1 group by key,hash_key ) tt1 group by tt1.key;
作业调优
-
合理设置 map 数和 reduce 数
- 太多的map 会导致启动产生过多的开销
- reduce 数量太多,小文件也就越多,启动过多的reduce 也会消耗时间和资源
-
mapjoin (默认开启):map端的join
-
开启 map 端的 combiner:map端的预聚合(只能用于求和、求最大值的操作)
- set hive.map.aggr = true (hive2默认开启)
-
开启数据倾斜负载均衡
- 思想:就是先随机分发并处理,再按照 key group by 来分发处理。(就是将key先打散,异步求和。)
小文件如何产生:
1、动态分区插入数据,会产生大量小文件,从而导致map数量剧增,所以要合并小文件。
2、reduce数量越多,小文件数量就越多。(reduce数量和输出的小文件个数是对应的)
3,数据源本身含有大量小文件。
17 hive读时模式
Hive是 读时模式 的:hive在加载数据的时候,并不会检查我们的数据是不是符合规范,只有在读的时候才会根据schema去解析数据
MYSQL是 写时模式 的
hive优化
- 建表优化
- 建分区表、分桶表、外部表
分区表:分区就是hdfs的分目录,是hdfs文件系统的一个文件夹。
分桶表:对分桶字段的值进行hash,然后除以分桶数量取余,决定该条记录放在哪个桶里
外部表:external,避免数据误删,只删元数据信息
- 指定合适的存储格式
textfile:默认的格式,不做压缩
orcfile:适当的压缩
sequencefile:压缩率比较高
parquet:二进制方式存储
- 语法查询优化
- 禁止使用select * 操作,只查询需要的字段
- 加分区查询
- 用left semi join 替换 in/exists
- 大表和小表join时,使用mapjoin,小表加载到内存里,在map端就进行join
- 作业优化
- 合理设置map数量。(通过参数配置)
当文件很大时,增加map数量,使每个map任务处理的数据量减少,提高效率;
当小文件很多时,map任务执行前合并小文件,减少map数。map任务执行之后也可以合并小文件
开启map端的combiner,预聚合
- 合理设置reduce数量
过多的reduce数量也会消耗资源;
有多少个reduce,就会输出多少个文件。如果生成太多的小文件,那么这些小文件就会作为下一个任务的输入,会造成小文件过多。
设置reduce数量时考虑两个原则:
1、处理大数据量时利用合适的reduce数
2、单个reduce任务处理的数据量大小要合适
- 数据倾斜优化
现象:少数任务运行很慢
原因:key分布不均,少量任务负责绝大部分的数据的计算,产生了shuffle。
处理:进行双重聚合,将key加前缀进行第一次聚合,去掉key进行第二次聚合。
两表关联时产生倾斜,设置合理的参数:
1、# join 的键对应的记录条数超过这个值则会进行分拆,值根据具体数据量设置
set hive.skewjoin.key=100000;
# 如果是 join 过程出现倾斜应该设置为 true
set hive.optimize.skewjoin=false;
2、大表和大表join时:
进行SMB join (sort merge bucket),通过设置参数开启:
set hive.optimize.bucketmapjoin = true;
set hive.optimize.bucketmapjoin.sortedmerge = true;
但有两个前提,必须是分桶表,建表语句需指定:clustered by () sorted by ()
两张表分桶的列必须是join key。