python分析北京朝阳链家租房信息-数据分析建模实战
近日学习的大数据创新课即将结课,要求大作业答辩,做完之后分享一下,有需要的朋友可以拿去借鉴。

数据爬取
Beautifulsoup部分说明:
由于网页界面采用的是静态页面分布,由于个人喜好,我采用的是Beautifulsoup进行网页分析,关于Beautifulsoup不太熟悉的小伙伴可以去Beautiful Soup 4.4.0 官方文档https://beautifulsoup.cn/查阅学习。
Xpash部分说明:
当然也可以使用Xpash来获取网页标签,个人认为xpash更方便,可以在浏览器网页按F11键进入开发者模式,直接复制Xpash路径,会更加轻松一些。
爬虫代码展示
接下来就是附上数据采集爬虫方面的完整代码:
import requests
from bs4 import BeautifulSoup
import csv
import re
def get_date(url,time=10):
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36 Edg/110.0.1587.69"}
try:
rel = requests.get(url,timeout = time,headers = headers)
rel.encoding = rel.apparent_encoding
rel.raise_for_status()
return rel.text
except Exception as err:
print(err)
def find_date(rel):
pricelist=[]
arealist=[]
northlist=[]
floorlist=[]
homelist1=[]
homelist2=[]
homelist3=[]
result=[]
count=[]
soup = BeautifulSoup(rel,"html.parser")
targets1 = soup.select(".content__list>div>div")
i=0
for item in targets1:
try:
err=re.sub(r'[^a-zA-Z0-9\s]','', item.select("p")[1].text.strip().split("室")[0].split("/")[-1].strip())
if "0"div>div>span")
i=0
j=0
for item in targets:
if j 如果哪方面有能改进的地方,也希望uu萌能帮我指出来(抱拳了)!!!
爬取内容展示
总共是七列数据,当然这些都是一些刚采集来的数据,还没有经过清洗,后续还会通过pandas对数据进行进一步的清洗工作。
数据清洗
数据清洗和数据建模部分,是放在Jupyter Notebook 中进行。
Jupyter Notebook介绍
什么是Jupyter Notebook
Jupyter Notebook 是一个基于 Web 的交互式计算环境,支持多种编程语言,包括 Python、R、Julia 等。它的主要功能是将代码、文本、数学方程式、可视化和其他相关元素组合在一起,创建一个动态文档,用于数据分析、机器学习、科学计算和数据可视化等方面。Jupyter Notebook 提供了一个交互式的界面,使用户能够以增量和可视化的方式构建和执行代码。
导入数据
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
data = pd.read_csv(r"C:\Users\86132\Desktop\北京朝阳租房.csv")
data数据展示
查看数据是否有缺失值
缺失值可以通过多种方法进行填补,如果数据量够大,也可以直接进行删除(我是比较懒,所以选择了删除,uu萌不要学我)
同时也给大家介绍一些缺失值的处理方法:
(1)删除
将存在遗漏信息属性值的样本(行)或特征(列)删除,从而得到一个完整的数据表。
(2)插补
1、手写
当你对数据集足够了解时,可以选择自己填写缺失值。然而一般来说,该方法很费时,当数据规模很大、空值很多的时候,该方法是不可行的。一般不推荐。
2、特殊值填充
将空值作为一种特殊的属性值来处理,它不同于其他的任何属性值。如所有的空值都用“unknown”填充。一般作为临时填充或中间过程。有时可能导致严重的数据偏离,一般不推荐。
3、平均值填充
将初始数据集中的属性分为数值属性和非数值属性来分别进行处理。
如果空值是数值型的,就根据该属性在其他所有对象的取值的平均值来填充该缺失的属性值; 如果空值是非数值型的,就根据统计学中的众数原理,用该属性在其他所有对象的取值次数最多的值(即出现频率最高的值)来补齐该缺失的属性值。
与其相似的另一种方法叫条件平均值填充法。在该方法中,用于求平均的值并不是从数据集的所有对象中取,而是从与该对象具有相同决策属性值的对象中取得。这两种数据的补齐方法,其基本的出发点都是一样的,以最大概率可能的取值来补充缺失的属性值,只是在具体方法上有一点不同。与其他方法相比,它是用现存数据的多数信息来推测缺失值。
4、K最近距离邻法
先根据欧式距离或相关分析来确定距离具有缺失数据样本最近的K个样本,将这K个值加权平均来估计该样本的缺失数据。
5、回归
基于完整的数据集,建立回归方程,或利用机器学习中的回归算法。对于包含空值的对象,将已知属性值代入方程来估计未知属性值,以此估计值来进行填充。当变量不是线性相关时会导致有偏差的估计。较常用。
data.isnull().sum()
data.dropna(inplace=True)去重
data.drop_duplicates(inplace=True)对数据进行量化处理
由于楼盘朝向是字符串形式,对后续进行数据建模很不友好,所以对朝向进行量化处理,首先因为,有的朝向中间有空格,所以先对其进行去除:
data['dirction'] = data['dirction'].str.replace(' ', '')
print(data)接下来就是,先创建一个映射字典,然后使用映射字典进行量化替换
direction_mapping ={
'东': 1,
'南': 2,
'西': 3,
'北': 4,
'东北': 5,
'东南': 6,
'西北': 7,
'西南': 8,
'南北':9
}
# 使用映射字典进行量化替换
data['dirction'] = data['dirction'].replace(direction_mapping)
print(data)其中,南北是有的楼盘有双朝向,所以单独列了出来。
由于作业要求1000条数据以上即可,所有对量化过后出现的一些异常值,直接选择删除处理(其实就是因为博主比较懒,不想处理了哈哈)
可视化
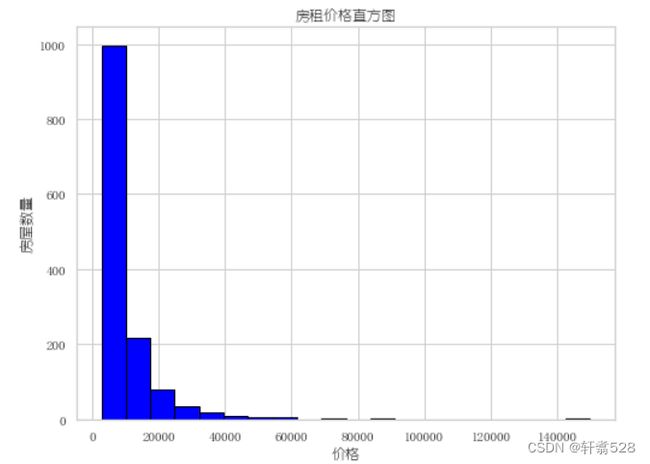
直方图
直方图又称质量分布图,是一种统计报告图,它是根据具体数据的分布情况,画成以组距为底边、以频数为高度的一系列连接起来的直方型矩形图。
用以展示数据的分布情况,诸如众数、中位数的大致位置、数据是否存在缺口或者异常值。
import matplotlib
matplotlib.rc("font",family='YouYuan')
prices = data['price']
# 绘制直方图
plt.figure(figsize=(8, 6))
plt.hist(prices, bins=20, color='blue', edgecolor='black') # 设置20个柱子
plt.title('房租价格直方图')
plt.xlabel('价格')
plt.ylabel('房屋数量')
plt.show()其中由于matplotlib不能很好的显示中文,我查了各种的资料,然后得出解决方法,只需要网代码里面加一条代码即可:
matplotlib.rc("font",family='YouYuan')#后面family中写你需要的字体虽然我也不清楚这是为啥,但是能用就行!!!
最终我的直方图也是成功的展示了出来
相关系数矩阵(Correlation matrix)
相关系数矩阵(Correlation matrix)是数据分析的基本工具。它们让我们了解不同的变量是如何相互关联的。
相关性
相关性是统计学中的一个概念,用于衡量两个随机变量之间的线性关系的强度和方向。如果一个变量增大时另一个变量也增大,那么这两个变量具有正相关性;反之,如果一个变量增大时另一个变量减小,那么这两个变量具有负相关性。相关性的值介于-1和1之间,0表示没有相关性,1或-1表示完全正相关或完全负相关。
相关性矩阵
可以帮助我们: 了解变量之间的关系。 发现可能的多重共线性问题(多重共线性是指自变量之间高度相关,可能会导致线性回归模型的系数估计不稳定)。 为特征选择提供依据(如果两个变量高度相关,我们可能只需要保留其中一个)
我们可以通过python中pandas库中写好的函数corr()来直接获取相关系数矩阵:
features = data[["area","dirction","floor","bed","sitting","bath","price"]]
correlation_matrix = features.corr()
print(correlation_matrix)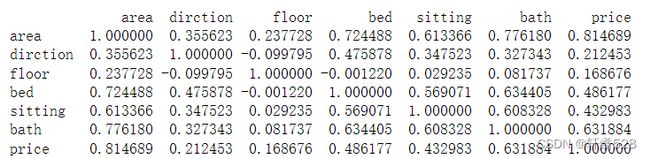
但是由于这样看着太丑了,不够花哨,也没法清晰的看出他们之间的关系,所有接下来我们通过得到的相关系数矩阵来画一个热图:
热图
plt.figure(figsize=(8, 6))
matplotlib.rc("font",family='YouYuan')
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', fmt=".2f", linewidths=0.5)
plt.title('特征相关系数矩阵热图')
plt.show()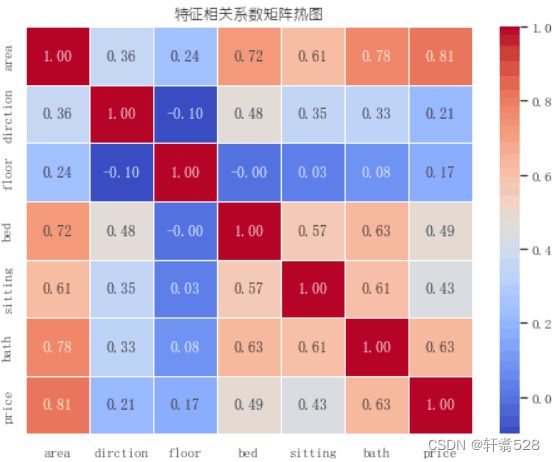
这样可以一目了然的看出他们之间的相关性,而且也更有美观性。
机器学习模型
一元线性回归
一元 线性回归 是分析只有一个 自变量 (自变量x和因变量y)线性相关关系的方法。 一个 经济指标 的数值往往受许多因素影响,若其中只有一个因素是主要的,起决定性作用,则可用一元线性回归进行预测分析。
我们首先对面积和价格之间进行建模
x = data.loc[:,"area"]
y = data.loc[:,"price"]导入 LinearRegression库
from sklearn.linear_model import LinearRegression
lr_model = LinearRegression()对数据维度进行变换
x = np.array(x)
x = x.reshape(-1,1)
y = np.array(y)
y = y.reshape(-1,1)
print(type(x),x.shape,type(y),y.shape)对模型进行训练,以及得到预测值和一元线性模型的系数和截距:
lr_model.fit(x,y)
y_predict = lr_model.predict(x)
print(y_predict)
a = lr_model.coef_
b = lr_model.intercept_
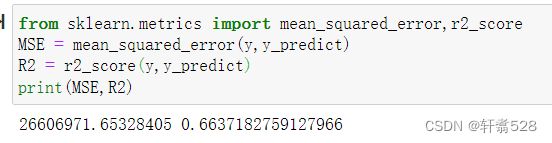
print(a,b)利用R2分数来查看模型的精确程度
from sklearn.metrics import mean_squared_error,r2_score
MSE = mean_squared_error(y,y_predict)
R2 = r2_score(y,y_predict)
print(MSE,R2)但是模型精度并不是很理想,只有0.66。
多元线性回归
于是我进一步选择多元线性回归模型来进行回归
X_multi = data.drop(['price'],axis=1)
X_multi
同一元线性回归代码差不多,无非是多了一些x参数:
LR_multi = LinearRegression()
LR_multi.fit(X_multi,y)获得预测值:
y_predict_multi = LR_multi.predict(X_multi)
print(y_predict_multi)再次进行模型测评:
mean_squared_error_multi = mean_squared_error(y,y_predict_multi)
r2_score_multi = r2_score(y,y_predict_multi)
print(mean_squared_error_multi,r2_score_multi)但是结果依旧不太友好,只是从0.66提升到了0.69,我就在想是不是这个数据集不太适合线性回归,但是题目要求用线性回归,难道是数据集出了问题,为了验证线性回归的合理性,我选择换一种机器学习模型 随机森林算法 进行重新建模,并对两个模型的结果进行比对。
随机森林回归
随机森林的思想
随机森林是属于集成学习,其核心思想就是集成多个弱分类器以达到三个臭皮匠赛过诸葛亮的效果。随机森林采用Bagging的思想,所谓的Bagging就是:
(1)每次有放回地从训练集中取出 n 个训练样本,组成新的训练集;
(2)利用新的训练集,训练得到M个子模型;
(3)对于分类问题,采用投票的方法,得票最多子模型的分类类别为最终的类别;对于回归问题,采用简单的平均方法得到预测值。
将多个决策树结合在一起,每次数据集是随机有放回的选出,同时随机选出部分特征作为输入,所以该算法被称为随机森林算法。可以看到随机森林算法是以决策树为估计器的Bagging算法。
接下来直接附上代码:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error, r2_score
# 提取特征和标签
X = data[["area","dirction","floor","bed","sitting","bath"]] # 特征
y = data['price'] # 标签
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建随机森林回归模型
rf_regressor = RandomForestRegressor(n_estimators=100, random_state=42)
# 训练模型
rf_regressor.fit(X_train, y_train)
# 使用模型进行预测
y_pred = rf_regressor.predict(X_test)
# 评估模型性能
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print("均方误差 (MSE):", mse)
print("决定系数 (R^2):", r2)结语
最后通过随机森林回归得到的R2分数依旧是0.67,所以我认为应该是数据集的问题,而并非模型的问题。后续也没再改了,等哪天该出来了,再发给uu萌具体的改进方法。
以上就是我的这次大作业的全部过程,希望能对uu萌有所帮助。