三、机器学习基础知识:Python常用机器学习库(中文文本分析相关库)
文章目录
- 1、Jieba库
-
- 1.1 主要函数
- 1.2 词性标注
- 1.3 关键词提取
- 2、WordCloud库
-
- 2.1 常见参数
- 2.2 词云绘制
文本分析是指对文本的表示及其特征的提取,它把从文本中提取出来的特征词进行量化来表示文本信息,经常被应用到文本挖掘以及信息检索的过程当中。
1、Jieba库
在自然语言处理过程中,为了能更好地处理句子,往往需要把句子拆分成一个一个的词语,这样能更好地分析句子的特性,这个过程就称为分词。由于中文句子不像英文那样天然自带分属,并且存在各种各样的词组,从而使中文分词具有一定的难度。Jieba 是一个Python 语言实现的中文分词组件,在中文分词界非常出名,支持简体、繁体中文,高级用户还可以加入自定义词典以提高分词的准确率,其应用范围较广,不仅能分词,还提供关键词提取和词性标注等功能。
Jieba库的调用需要使用自动安装命令 pip install jieba进行安装,之后使用代码import jieba 引入即可。
1.1 主要函数
| 函数名 | 作用 |
|---|---|
| jieba.cut(s) | 精确模式,返回一个可迭代的数据类型 |
| jieba.cut(s.cut_all=True) | 全模式,输出文本s中的所有可能单词 |
| jieba.cut_for_search(s) | 搜索引擎模式,适合搜索引擎建立索引的分词结果 |
| jieba.lcut(s) | 精确模式,返回一个列表类型 |
| jieba.lcut(s,cut_all=True) | 全模式,返回一个列表类型 |
| jieba.lcut_for_search(s) | 搜索引擎模式,返回一个列表类型 |
| jieba.add_word(w) | 向分词词典中增加新词w |
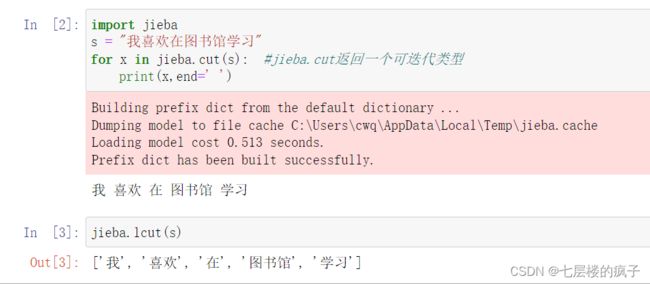
精确分词实例:
import jieba
s = "我喜欢在图书馆学习"
for x in jieba.cut(s): #jieba.cut返回一个可迭代类型
print(x,end=' ')
jieba.lcut(s)
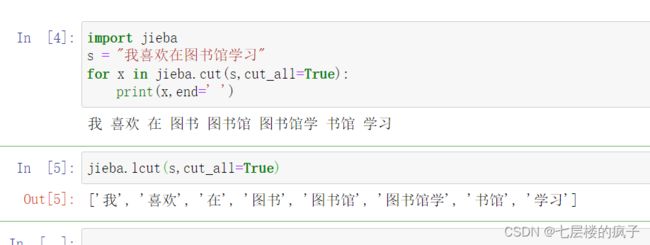
全模式分词实例:
import jieba
s = "我喜欢在图书馆学习"
for x in jieba.cut(s,cut_all=True):
print(x,end=' ')
jieba.lcut(s,cut_all=True)
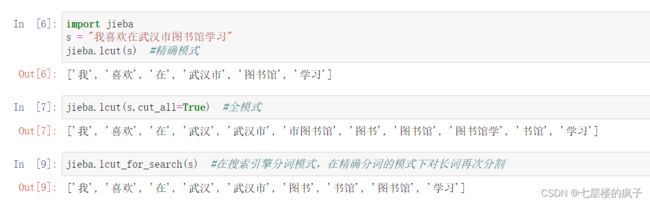
搜索引擎模式分词实例:
import jieba
s = "我喜欢在武汉市图书馆学习"
jieba.lcut(s) #精确模式
jieba.lcut(s,cut_all=True) #全模式
jieba.lcut_for_search(s) #在搜索引擎分词模式,在精确分词的模式下对长词再次分割
1.2 词性标注
词性是词汇基本的语法范畴,通常也称为词类,主要用来描述一个词在上下文中的作用。例如人物、地名、事物等是名词,表示动作的词是动词等。词性标注的过程就是确定一个句子中出现的每个词分别属于名词、动词还是形容词等,它是语法分析、信息抽取等应用领域重要的信息处理基础性工作。
不同的语言有不同的词性标注集,为了方便指明词的词性,需要给每个词性编码,常用词性编码如下:
| 词性编码 | 词性 | 词性编码 | 词性 |
|---|---|---|---|
| n | 名词 | m | 数词 |
| v | 动词 | o | 拟声词 |
| a | 形容词 | y | 语气词 |
| p | 介词 | z | 状态词 |
| c | 连词 | nr | 人名 |
| d | 副词 | ns | 地名 |
| ul | 助词 | t | 时间 |
| q | 量词 | w | 标点符号 |
| r | 代词 | x | 未知符号 |
中文分词及词性的标注可以使用jieba.posseg模块,其中的cut()方法能够同时完成分词和词性标注两个功能,它返回一个数据序列,其中包含word和flag两个序列,word是分词得到的词语,flag是对各个词的词性标注。
词性标注实例:
import jieba.posseg as psg
text = "我喜欢在武汉市图书馆学习"
seg = psg.cut(text) #词性标注
for e in seg:
print(e,end = ' ')

1.3 关键词提取
关键词抽取就是从文本里面把与这篇文档意义最相关的一些词抽取出来。关键词在文本聚类、分类、自动摘要等领域中有着重要的作用。例如,在聚类时将关键词相似的几篇文档看成一个团簇,可以大大提高聚类算法的收敛速度;从某天所有的新闻中提取出这些新闻的关键词,就可以大致了解那天发生了什么事情;将某段时问内几个人的微博拼成一篇长文本,然后抽取关键词就可以知道他们主要在讨论什么话题。因此,关键词是最能够反应文本主题或者意思的词语。
可以利用jieba分词系统中的TF-IDF接口抽取关键词,实例如下:
from jieba import analyse
# 原始文本
text = '''关键词抽取就是从文本里面把与这篇文档意义最相关的一些词抽取出来。关键词在文本聚类、分类、自动摘要等领域中有着重要的作用。例如,在聚类时将关键词相似的几篇文档看成一个团簇,可以大大提高聚类算法的收敛速度;从某天所有的新闻中提取出这些新闻的关键词,就可以大致了解那天发生了什么事情;将某段时问内几个人的微博拼成一篇长文本,然后抽取关键词就可以知道他们主要在讨论什么话题。'''
# 基于TF-IDF算法进行关键词抽取
# topK表示最大抽取个数,默认为20个
# withWeight表示是否返回关键词权重值,默认值为 False
# 还有一个参数allowPOS默认为('ns','n','vn','v')即仅提取地名、名词、动名词、动词
keywords = analyse.extract_tags(text, topK = 10, withWeight = True)
print ("keywords by tfidf:")
# 输出抽取出的关键词
for keyword in keywords:
print ("{:<5} weight:{:4.2f}".format(keyword[0], keyword[1]))

2、WordCloud库
词云(WordCloud)是对文本中出现频率较高的关键词数据给予视觉差异化的展现方式。词云图突出展示高频高质的信息,也能过滤大部分低频的文本。利用词云,可以通过可视化形式凸显数据所体现的主旨,快速显示数据中各种文本信息的频率。
2.1 常见参数
Python中的词云(WordCloud)库中存在一个WordCloud()函数,可以利用该函数进行词云对象的构造,该函数中的主要参数如下所示:
| 属性 | 数据类型 | 说明 |
|---|---|---|
| font_path | string | 字体文件所在的路径 |
| width | int | 画布宽度,默认为400px |
| height | int | 画布高度,默认为400px |
| min_font_size | int | 显示的最小字体大小,默认为4 |
| max_font_size | int | 显示的最大字体大小,默认为None |
| max_words | number | 显示的词的最大个数,默认为200 |
| relative_scaling | float | 词频和字体大小的关联性,默认为5 |
| color_func | callable | 生成新颜色的函数,默认为空 |
| prefer_horizontal | float | 词语水平方向排版出现的频率,默认为0.9 |
| mask | ndarray | 默认为None,使用二维遮罩绘制词云。如果mask非空,将忽略画布的宽度和高度,遮罩形状为mask |
| scale | float | 放大画布的比例,默认为1(1倍) |
| stopwords | 字符串 | 停用词,需要屏蔽的词,默认为空。如果为空,则使用内置的STOPWORDS |
| background_color | 字符串 | 背景颜色,默认为‘black’ |
2.2 词云绘制
例如将26个大写英文字母作为字典的键,针对每个键随机生成1-100之间的正整数作为,基于此字典生成词云:
import wordcloud
import random
import string # 导入string库
# string.ascii_uppercase可以获取所有的大写字母
lstChar = [x for x in string.ascii_uppercase]
# 使用randint获取26个随机整数
lstfreq = [random.randint(1,100) for i in range(26)]
# 使用字典生成式,产生形式如{'A': 80, 'B': 11, 'C': 38……}的字典
freq = {x[0]:x[1] for x in zip(lstChar,lstfreq)}
print(freq)
wcloud = wordcloud.WordCloud(
background_color = "white",width=1000,
max_words = 50,
height = 860, margin = 1).fit_words(freq)# 利用字典freq生成词云
wcloud.to_file("resultcloud.png") # 将生成的词云图片保存
print('结束')
生成的字典如下:
![]()
生成的词云如下图所示:
