列联图(交叉分析)的R代码实现
一、简介
交叉分析 Cross-Analysis
适用场景:研究两个或多个分类变量之间的关系。通常使用二维列联表,行列各表示一个分类变量
意义:了解变量之间的相互依赖关系,计算关联度量(如卡方值)检验变量之间的独立性
二、R实现
练习数据集采用NHANES包的NHANES数据集,这是一个规模较大的示例数据框,主题是个人的健康与营养方面的信息。
library(tidyverse) # Wickham的数据整理的整套工具
library(NHANES); data(NHANES)
dplyr::glimpse(NHANES) #用dplyr查看数据框内行数、列数、变量细节数据集有10000条数据,76个变量。部分结果展示:

其中,各个参与者的生存结局日期不同,部分参与者有多个观测值,因此进行数据筛选。
d_nhsub <- NHANES |>
dplyr::filter(SurveyYr == "2011_12") |> #筛选其中SurveyYr为2011_12的观测
group_by(ID) |> #分组汇总
slice_tail(n=1) |> #选择(保留)多个观测中的最后一个
ungroup() #去除已分组数据的分组,避免影响下次运算
dim(d_nhsub)最终得到了3211条数据。
本次练习,我们主要考察两个分类变量性别(Gender)和教育程度(Education)之间的关系。
交叉分析可以用以下代码实现,不同代码有不同结果,可以按需选取
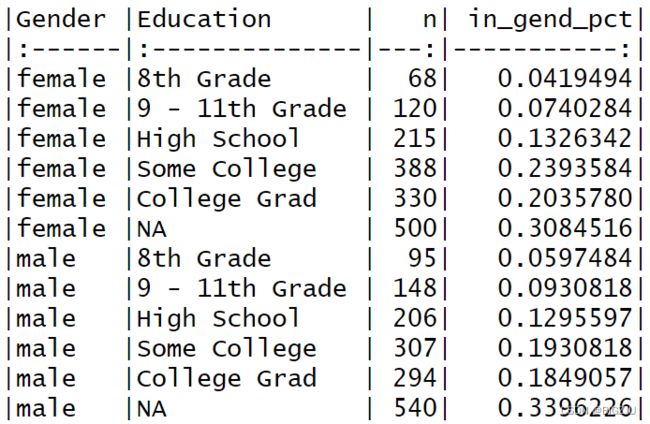
#计算交叉频数分布
d_gened <- d_nhsub |>
count(Gender, Education) |>
group_by(Gender) |>
mutate(in_gend_pct = n / sum(n)) |> #性别内部的学历比例
ungroup()
knitr::kable(d_gened) #输出一个比较好看的数据框结果如下:
# 输出分类后数据框,但不计算比例
with(d_nhsub, table(
Education, Gender
))结果如下:

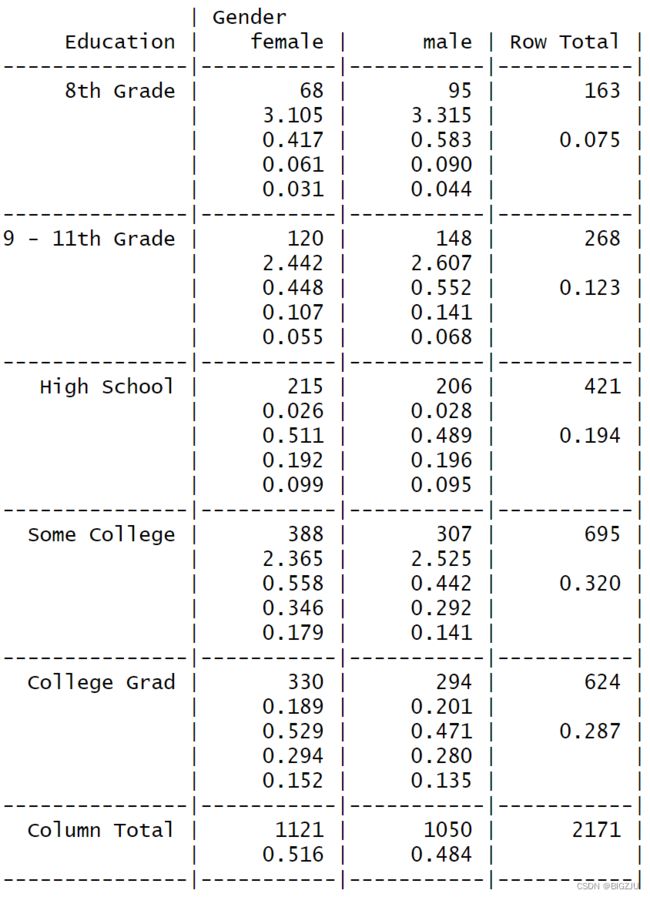
#直接列联表
with(d_nhsub, gmodels::CrossTable(
Education, Gender
))结果如下:
三、使用ggplot作图
得出的结果我们可以用ggplot做出更美观的可视化结果。
#堆叠条形图
ggplot(d_gened, aes(
x = Gender, fill = Education, y = n)) +
geom_col(position = "stack") #垂直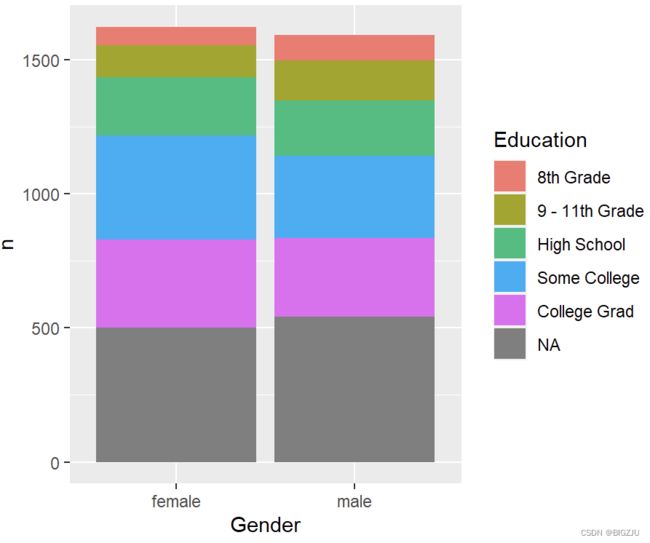
#并列条形图,使用百分比比较
ggplot(d_gened, aes(
x = Gender, fill = Education, y = in_gend_pct)) +
geom_col(position = "dodge") #并列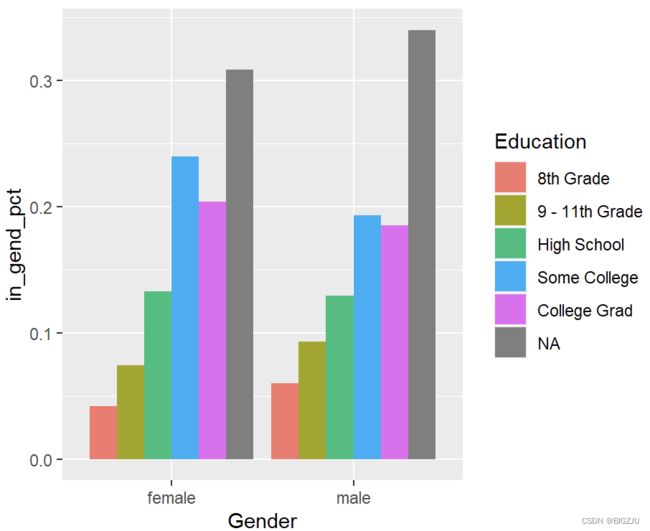
或许大家也注意到了两图中灰色的NA值,即数据缺失值,本次我们不进行数据补全,可以使用以下代码去除缺失值。
#不显示缺失值
ggplot(drop_na(d_gened), aes(
x = Gender, fill = Education, y = in_gend_pct)) +
geom_col(position = "dodge") +
labs(y="") #去除空值NA并删去相应的标签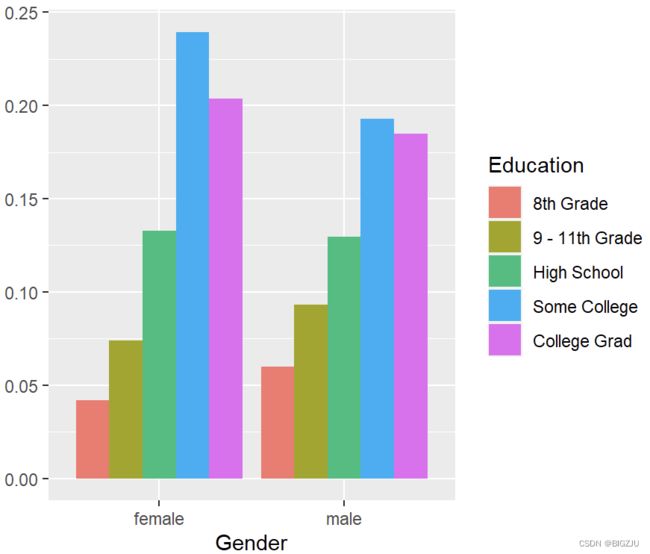
如有需要,我们也可以把图横过来。
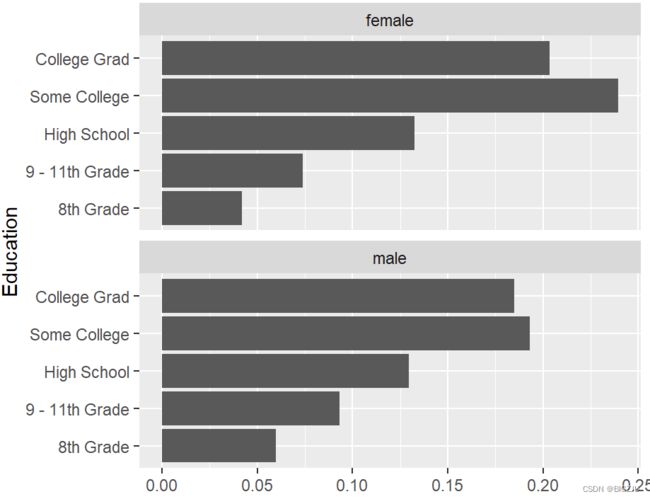
#分两组比较
ggplot(drop_na(d_gened), aes(
x = Education, y = in_gend_pct)) +
facet_wrap(~ Gender, ncol=1) + #按性别分组,成一列
geom_col() +
coord_flip() + #横纵坐标位置转换
labs(y="")