mysql存储过程与函数、触发器、游标、变量等知识点详解
引言:该文章仅供自己学习整理
mysql执行顺序
语法顺序
写sql的关键字顺序
select [distinct]
from
join(如left join)
on
where
group by
having
union
order by
limit
执行顺序
在数据库底层执行时sql按照下面的顺序进行执行
from
on
join
where
group by
having
select
distinct
union
order by
mysql存储过程和函数
需要用到的表
#建表语句
#users表
create table if not EXISTS users(
id int(20) PRIMARY KEY,
name varchar(32),
age int(10),
status int(10),
score int(10),
accontid varchar(32)
);
DELETE from users;
insert into users VALUES
(1,"张三",19,0,40,10001),
(2,"李四",15,1,0,10002),
(3,"王五",15,2,0,10001),
(5,"王力",20,3,0,10003);
#orders表
create table if not EXISTS orders(
id int(20) PRIMARY KEY,
order_num varchar(64),
create_date datetime,
money decimal(12,3)
);
DELETE from orders;
insert into orders VALUES
(1,201902020001,'2019-02-20 10:53:22',200),
(2,201902019002,'2019-02-19 10:53:22',100),
(3,20190219003,'2019-02-19 11:53:22',300)
#test1表
create table if not EXISTS test1(
id int(20) PRIMARY KEY
);
#shops_info表
create table if not EXISTS shops_info(
pid varchar(32) PRIMARY KEY,
name varchar(64),
price int(20),
pdesc varchar(64)
);
insert into shops_info VALUES
('001','手机',2500,'打电话'),
('002','电话机',5000,'看电视'),
('003','电饭煲',2500,'煮饭')
#mytest表
create table if not EXISTS mytest(
id int(20) PRIMARY KEY,
name varchar(64),
money int(20)
);
DELETE from mytest;
insert into mytest VALUES
(1,'admin',200),
(2,'guest',8800),
(3,'user',7777)
#cursor_table
CREATE TABLE cursor_table
(
id INT ,
name VARCHAR(10),
age INT
)ENGINE=innoDB DEFAULT CHARSET=utf8;
insert into cursor_table values(1, "孙悟空", 500);
insert into cursor_table values(2, "猪八戒", 200);
insert into cursor_table values(3, "沙悟净", 100);
insert into cursor_table values(4, "唐僧", 20);
#store表
CREATE TABLE IF NOT EXISTS `store` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) NOT NULL,
`count` int(11) NOT NULL DEFAULT '1',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1 AUTO_INCREMENT=7;
INSERT INTO `store` (`id`, `name`, `count`) VALUES
(1, 'android', 15),
(2, 'iphone', 14),
(3, 'iphone', 20),
(4, 'android', 5),
(5, 'android', 13),
(6, 'iphone', 13);
#t表
create table if not EXISTS t(
id int(20)
);
#tablea表
create table if not EXISTS tablea(
id int(20) ,
fix int(20)
);
INSERT INTO tablea (`id`, `fix`) VALUES
(1,1),
(2,1),
(3,2),
(4,2),
(5,2),
(6,3),
(7,4),
(8,5);
#oplog表
create table if not EXISTS oplog(
id int(20) PRIMARY KEY,
userid int(20),
username varchar(32),
action varchar(32),
optime TIMESTAMP,
old_values varchar(32),
new_values varchar(32)
);
存储过程定义
存储过程(Stored Procedure)是在大型数据库系统中,一组为了完成特定功能的SQL 语句集,存储在数据库中,经过第一次编译后调用不需要再次编译,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它。存储过程是数据库中的一个重要对象。
简单的说,存储过程就是一条或多条sql语句的集合,可视为批文件但其作用不仅限于批处理。
存储过程的特点
1、能完成较复杂的判断和运算
2、可编程行强,灵活
3、SQL编程的代码可重复使用
4、执行的速度相对快一些
5、减少网络之间的数据传输,节省开销
创建存储过程
1、创建存储过程的语法:

CREATE PROCEDURE sp_name([proc_parameter])
[characteristics...] routine body
#1、sp_name 为存储过程的名称
#2、proc_parameter为指定存储过程的参数列表
#列表形式如下:
#[IN|OUT|INOUT param_name type] type 是指参数的数据类型
#IN表示输入参数,OUT表示输出参数,INOUT表示既可以输入也可以输出,param_name是参数名称
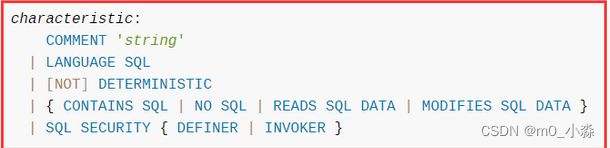
#characteristics指定存储过程的特性,有以下取值:LANGUAGE SQL、[NOT] DETERMINISTIC等
#routine body 是sql代码的内容,用begin...end来表示sql代码的开始与结束
'''**LANGUAGE SQL**
存储过程语言,默认是sql,说明存储过程中使用的是sql语言编写的,暂时只支持sql,后续可能会支持其他语言
**NOT DETERMINISTIC**
是否确定性的输入就是确定性的输出,默认是NOT DETERMINISTIC,只对于同样的输入,输出也是一样的,当前这个值还没有使用
**CONTAINS SQL**
提供子程序使用数据的内在信息,这些特征值目前提供给服务器,并没有根据这些特征值来约束过程实际使用数据的情况,说白了就是没有使用的
包括以下四种选择
1.CONTAINS SQL表示子程序不包含读或者写数据的语句
2.NO SQL 表示子程序不包含sql
3.READS SQL DATA 表示子程序包含读数据的语句,但是不包含写数据的语句
4.MODIFIES SQL DATA 表示子程序包含写数据的语句。
**SQL SECURITY DEFINER**
用来指定存储过程是使用创建者的许可来执行,还是执行者的许可来执行,默认值是DEFINER
DEFINER 创建者的身份来调用,对于当前用户来说:如果执行存储过程的权限,且创建者有访问表的权限,当前用户可以成功执行过程的调用的
说白了就是当前用户调用存储过程,存储过程执行的具体操作是借助定义存储过程的user的权限执行的。
INVOKER 调用者的身份来执行,对于当前用户来说:如果执行存储过程的权限,以当前身份去访问表,如果当前身份没有访问表的权限,即便是有执行过程的权限,仍然是无法成功执行过程的调用的。
说白了就是当前用户调用存储过程,只有当前用户有执行存储过程中涉及的对象的操作的权限的时候,才能成功执行。'''
创建一个简单的存储过程
create procedure 名称()
begin
.........
end
#创建存储过程
create procedure testa()
begin
select * from users;
select * from orders;
end;
#调用存储过程
call testa();
带变量的存储过程
在存储过程中时用declare定义变量的语法:
declare var_name[,varname]...data_type [DEFAULT value]
#var_name为局部变量的名称。DEFAULT value 子句给变量提供一个默认值。值除了可以被声明为一个常数之外,还可以被指定为一个表达式。如果没有DEFAULT子句,初始值为NULL。
#data_type是变量的数据类型
例子1
create procedure test2()
begin
-- 使用 declare语句声明一个变量
declare username,age varchar(32) default '';
-- 使用set语句给变量赋值
set username='xiaoxiao',age='xinxin';
-- 将users表中id=1的名称赋值给username
select name into username from users where id=1;
-- 返回变量
select username,age;
end;
CALL test2()
概括
(1)、变量必须先声明后使用;
(2)、变量具有数据类型和长度,与mysql的SQL数据类型保持一致,因此甚至还能制定默认值、字符集和排序规则等;
(3)、变量可以通过set来赋值,也可以通过select into的方式赋值;
(4)、变量需要返回,可以使用select语句,如:select 变量名。
变量的作用域
1、变量作用域说明:
(1)、存储过程中变量是有作用域的,作用范围在begin和end块之间,end结束变量的作用范围即结束。
(2)、需要多个块之间传值,可以使用全局变量,即放在所有代码块之前
(3)、传参变量是全局的,可以在多个块之间起作用
例子1
drop procedure if EXISTS test3;
create procedure test3()
begin
begin
declare userscount int default 0; -- 用户表中的数量
declare ordercount int default 0; -- 订单表中的数量
select count(*) into userscount from users;
select count(*) into ordercount from orders;
select userscount,ordercount; -- 返回用户表中的数量、订单表中的数量
end;
begin
declare maxmoney int default 0; -- 最大金额
declare minmoney int default 0; -- 最小金额
select max(money) into maxmoney from orders;
select min(money) into minmoney from orders;
select maxmoney,minmoney; -- 返回最金额、最小金额
#若改成select userscount,ordercount,maxmoney,minmoney; 则会因为作用域的问题而报错
end;
end;
call test3()
例子2
正确的调用第一个begin…end中的变量需要将其中的变量提到所有代码之前然后再加一个begin…end包括起来
drop procedure if EXISTS test3;
create procedure test3()
begin
declare userscount int default 0; -- 用户表中的数量
declare ordercount int default 0; -- 订单表中的数量
begin
select count(*) into userscount from users;
select count(*) into ordercount from orders;
select userscount,ordercount; -- 返回用户表中的数量、订单表中的数量
end;
begin
declare maxmoney int default 0; -- 最大金额
declare minmoney int default 0; -- 最小金额
select max(money) into maxmoney from orders;
select min(money) into minmoney from orders;
select userscount,ordercount,maxmoney,minmoney; -- 返回最金额、最小金额
end;
end;
CALL test3()
例子3
drop procedure if EXISTS test;
create PROCEDURE test()
begin
select @data;
set @data = 5;
select @data;
end;
set @data = 1;
call test()#@data是全局变量,所以会被存储过程修改
带参数的存储过程
基本语法
create procedure 名称([IN|OUT|INOUT] 参数名 参数数据类型 )
begin
.........
end
说明:
(1)、传入参数:类型为in,表示该参数的值必须在调用存储过程事指定,如果不显示指定为in,那么默认就是in类型。
(2)、IN类型参数一般只用于传入,在调用过程中一般不作为修改和返回
(3)、如果调用存储过程中需要修改和返回值,可以使用OUT类型参数
存储过程的传出参数IN
例子1
drop procedure if EXISTS test4;
create procedure test4(userId int)
begin
declare username varchar(32) default '';
declare ordercount int default 0;
select name into username from users where id=userId;
select username;
end;
CALL test4(2)
结果:
例子2
#为了避免存储过程中分号(";")结束语句,我们使用分隔符告诉mysql解释器,该段命令是否已经结束了。
/**
案例功能:求1-n的和
*/
drop procedure if EXISTS p1;
delimiter $
create procedure p1(in n int)
begin
declare total int default 0;
declare num int default 0;
while num < n do
set num:=num+1;
set total:=total+num;
end while;
select total;
end$
call p1(10)$
例子3
drop procedure if EXISTS test;
create PROCEDURE test(in data_in int)
begin
SELECT data_in;
set data_in = 5;
select data_in;
end;
set @data = 1;
call test(@data); #首先查出data_in = 1 修改之后 data_in = 5
select @data #data = 1,因为存储过程中修改的是局部变量,不影响全局
例子4
更新数据
-- 创建更新的存储过程
drop procedure if exists updateMyTest;
DELIMITER //
CREATE PROCEDURE updateMyTest(uid INT,newMoney DOUBLE)
BEGIN
DECLARE isexists INT DEFAULT 0; -- 定义变量必须在当前的begin中
SELECT COUNT(1) INTO isexists FROM mytest WHERE id=uid ; -- 使用查询的(into)方式赋值
IF isexists<>0 THEN -- 第一个条件
IF newMoney>0 THEN -- 第二个条件
UPDATE mytest SET money=newMoney WHERE id=uid;
SET isexists=1; -- 使用set方式为变量赋值
ELSE
SET isexists=-1;
END IF; -- 结束第二个条件
END IF; -- 结束第一个条件
SELECT (CASE isexists WHEN -1 THEN '执行失败' WHEN 0 THEN 'id不存在' ELSE '执行成功' END)AS '执行结果' ;-- 使用case when then else end 的switch条件
END //
DELIMITER ;
CALL updateMyTest(1,10000);
存储过程的传出参数out
例子1
drop procedure if EXISTS test5;
create procedure test5(in userId int,out username varchar(32))
begin
select name into username from users where id=userId;
end;
set @uname='';
call test5(2,@uname);
select @uname as username
例子2
#这里还要注意一点的就是我们的输出参数一定要设置相应类型的初始,否则不管你怎么计算得出的结果都为NULL值
/**
案例功能:求1-n的和
*/
drop procedure if EXISTS p2;
delimiter $
create procedure p2(in n int,out total int)
begin
declare num int default 0;
set total:=0;
while num < n do
set num:=num+1;
set total:=total+num;
end while;
end$
/*注意:对于第一个输入参数我们可以理解,但是第二个输出参数我们到底应该怎么输?
这里我们需要对第二个参数定义一个变量名(更形象点就是你输入一个输入类型的参数n,由输出参数total往外发射输出我们只需要定义一个变量名来接收这个输出值即可)*/
call p2(100,@sum)$#这里的@sum就是我定义用来接收处处total的值
select @sum$
例子3
drop procedure if EXISTS test;
create PROCEDURE test(out data_out int)
begin
set data_out = 5;
end;
set @data = 1;
call test(@data);
select @data #data被修改,因为是回传参数。
存储过程的可变参数INOUT
例子1
drop procedure if EXISTS test6;
create procedure test6(inout userId int,inout username varchar(32))
begin
set userId=2;
set username='';
select id,name into userId,username from users where id=userId;
end;
set @uname='',@userId=0;
call test6(@userId,@uname);
select @uname,@userId
例子2
drop procedure if EXISTS p3;
delimiter $
/**
功能:传一个年龄,自动让年龄增长10岁
*/
create procedure p3(inout age int)
begin
set age:=age+10;
end$
/*注意:调用的时候,我这里需要和大家声明一下,inout型的参数值既是输入类型又是输出类型,你给它一个值,值不是变量,不是变量那out的时候它怎么赋给这个值是不是?
因此我们需要先设置一个变量并初始化这个值,调用的时候直接传这个变量即可。*/
set @currentAge=8$
call p3(@currentAge)$
select @currentAge$
例子3
drop procedure if EXISTS test;
create PROCEDURE test(inout data_inout int)
begin
select data_inout; #data_inout = 1
set data_inout = 5;
end;
set @data = 1;
call test(@data);
select @data #data = 5
#data被修改,因为回传参数。
流程控制语句
loop,leave和iterate
LOOP 及 LEAVE、ITERATE
这里LOOP用来标记循环;
而LEAVE表示离开循环,好比编程里面的break一样;
ITERATE则继续循环,好比编程里面的continue一样。
存储过程条件语句
if语句:
基本语法
IF expr_condition THEN statement_list
[ELSEIF expr_condition THEN statement_list]
[ELSE tatement_list]
1、条件语句基本结构:
if() then...else...end if;
2、多条件判断语句:
if() then...
elseif() then...
else ...
end if;
实例
drop procedure if EXISTS test7;
create procedure test7(in userId int)
begin
declare username varchar(32) default '';
if(userId%2=0)
then
select name into username from users where id=userId;
select username;
else
select userId;
end if;
end;
call test7(3)
多条件语句应用示例
drop procedure if EXISTS test8;
create procedure test8(in userid int)
begin
declare my_status int default 0;
select status into my_status from users where id=userid;
if(my_status=1)
then
update users set score=score+10 where id=userid;
elseif(my_status=2)
then
update users set score=score+20 where id=userid;
else
update users set score=score+30 where id=userid;
end if;
end;
call test8(1)
case语句
第一种格式
基本语法:
CASE case_expr
WHEN when_value THEN statement_list
[WHEN when_value THEN statement_list]...
[ELSE statement_list]
END CASE
#其中,case_expr参数表示条件判断的表达式,决定了哪一个WHEN子句会被执行;when_value 参数表示表达式可能的值,如果某个 when_value 表达式与case_expr表达式结果相同,则执行对应THEN关键字后的statement_list中的语句;statement_list参数表示不同when_value值的执行语句。
例子:
CASE val
when 1 then select 'val is 1';
when 2 then select 'val is 2';
ELSE select 'val is not 1 or 2'
END CASE
第二种格式
基本语法
CASE
WHEN expr_condition THEN statement_list
[WHEN expr_condition THEN statement_list]...
[ELSE statement_list]
END CASE
#其中,expr_condition 参数表示条件判断语句;statement_list 参数表示不同条件的执行语句。该语句中,WHEN语句将被逐个执行,直到某个expr_condition表达式为真,则执行对应THEN关键字后面的statement_list语句。如果没有条件匹配,ELSE子句里的语句被执行。
例子
CASE
when val is null then select 'val is null';
when val<0 then select 'val is less then 0';
when val>0 then select 'val is greater then 0';
ELSE select 'val is 0';
END CASE
例子
例子1
drop procedure if EXISTS test;
create PROCEDURE test()
BEGIN
DECLARE data int default 1;
case data
when data < 0 then
set data = data + 1;
when 1 then
set data = data - 1;
else
set data = 5;
end case;
select data;
end;
call test()
例子2
DROP PROCEDURE IF EXISTS testcate;
create procedure testcate(userid int)
begin
declare my_status int default 0;
select status into my_status from users where id=userid;
case my_status
when 1 then update users set score=10 where id=userid;
when 2 then update users set score=20 where id=userid;
when 3 then update users set score=30 where id=userid;
else update users set score=40 where id=userid;
end case;
end;
call testcate(1)
存储过程循环语句
while语句
####### while语句的基本结构
while(表达式) do
......
end while;
####### 例子
例子1
drop procedure if EXISTS test9;
create procedure test9()
begin
declare i int default 0;
while(i<10) do
begin
select i;
set i=i+1;
insert into test1(id) values(i);
end;
end while;
end;
call test9()
例子2
drop procedure if EXISTS test;
create PROCEDURE test()
BEGIN
DECLARE data int DEFAULT(5);
while data < 10 do
select data;
set data = data + 1;
end while;
end;
call test()
repeat语句
####### 基本语法
REPEAT statement_list
UNTIL expr_condition
END REPEAT
####### 例子
例子1
drop procedure if EXISTS test10;
create procedure test10()
begin
declare i int default 0;
repeat
begin
select i;
set i=i+1;
insert into test1(id) values(i);
end;
until i>=10 -- 如果i>=10,则跳出循环
end repeat;
end;
call test10()
例子2
drop procedure if EXISTS test;
create PROCEDURE test()
BEGIN
DECLARE data int DEFAULT(5);
REPEAT
select data;
set data = data + 1;
UNTIL data > 10 END REPEAT;
end;
call test()
LOOP语句
LOOP循环语句用来重复执行某些语句,与IF和CASE 语句相比,LOOP只是创建一个循环操作的过程,并不进行条件判断。LOOP内的语句一直重复执行直到循环被退出(使用LEAVE子句),跳出循环过程。
LOOP语句的基本格式如下∶
[loop_label:] LOOP
statement_list
END LOOP [loop_label]
#其中,loop_label表示LOOP语句的标注名称,该参数可以省略;statement_list参数表示需要循环执行的语句。
例子
例子1
drop procedure if EXISTS test;
create PROCEDURE test()
BEGIN
DECLARE data int DEFAULT(5);
loop_name:loop
select data;
set data = data + 1;
if data = 10 then
leave loop_name;
end if;
end loop loop_name;
end;
call test()
LEAVE 语句
标号可以用在begin repeat while 或者loop 语句前,语句标号只能在合法的语句前面使用。可以跳出循环,使运行指令达到复合语句的最后一步。leave 语句用来退出任何被标注的流程控制语句。
例子1
add_num:LOOP
set @count=@count+1;
if @count=50 then leave add_num;
end loop add_num;
ITERATE语句
简介
ITERATE 语句将执行顺序转到语句段开头处,ITERATE只可以出现在LOOP、REPEAT和WHILE语句内。ITERATE的意思为"再次循环",label参数表示循环的标志。ITERATE 语句必须跟在循环标志前面。
例子
例子1
drop procedure if exists proc10;
CREATE PROCEDURE proc10()
begin
declare v int;
set v=0;
LOOP_LABLE:loop
if v=3 then
set v=v+1;
ITERATE LOOP_LABLE;
end if;
insert into t values(v);
set v=v+1;
if v>=5 then
leave LOOP_LABLE;
end if;
end loop;
end;
call proc10()
例子2
DROP PROCEDURE IF EXISTS doiterate;
create procedure doiterate()
begin
DECLARE p1 int default 0;
my_loop:loop
set p1=p1+1;
if p1<10 then iterate my_loop;
elseif p1>20 then leave my_loop;
end if;
select 'p1 is between 10 and 20';
end loop my_loop;
end;
call doiterate()
#初始化p1=0,如果p1的值小于10时,重复执行p1加1操作;当p1大于等于10并且小于等于20时,打印消息“pl is between 10 and 20”;当pl大于20时,退出循环。
存储过程游标的使用
游标(光标)简介
什么是游标
游标是保存查询结果的临时区域,有了游标可以方便的对该结果集进行逐行处理。 游标的设计是一种数据缓冲区的思想,用来存放SQL语句执行的结果
游标的优缺点
(1)游标的优点:
因为游标是针对行操作的,所以对从数据库中select查询得到的每一行可以进行分开的独立的相同或不同的操作,是一种分离的思想。可以满足对某个结果行进行特殊的操作。 游标与基于游标位置的增删改查能力。
(2)游标缺点
游标的缺点是针对有点而言的,也就是只能一行一行操作,在数据量大的情况下,是不适用的,速度过慢。 数据库大部分是面对集合的,业务会比较复杂,而游标使用会有死锁,影响其他的业务操作,不可取。 当数据量大时,使用游标会造成内存不足现象。
游标的使用场景
MySQL数据库中,可以在存储过程、函数、触发器、事件中使用游标。
游标的特性
游标具有三个属性:
A、不敏感(Asensitive):数据库可以选择不复制结果集
B、只读(Read only)
C、不滚动(Nonscrollable):游标只能向一个方向前进,并且不可以跳过任何一行数据。
原理
游标就是把数据按照指定要求提取出相应的数据集,然后逐条进行数据处理。
DECLARE … HANDLER语句
mysql官方文档
//在一个或者多个condition_value满足时,先执行statement语句,然后执行handler_action动作。
DECLARE handler_action HANDLER
FOR condition_value [, condition_value] ...
statement
Mysql中,定义一个handler处理一个或多个条件(condition_value ),如果某一个条件被触发, 则会执行定义的SQL语句(statement),然后执行动作(handler_action)。下面对statement、condition_value、handler_action这三个元素进行分别解释。
statement
statement语句可以是一行简单的SQL语句,如SET var_name = value,也可以是多行复杂的的SQL语句,但多行SQL语句需要使用BEGIN和END包围。
#这里的SET FOUND=FALSE就是一条statement,至于词句完整含义,在最后讲解
DECLARE CONTINUE HANDLER FOR NOT FOUND SET FOUND=FALSE;
handler_action
条件被满足时,执行定义好的SQL语句,然后再执行动作。主要有以下三种选择:
handler_action的取值如下:
handler_action: {
CONTINUE
| EXIT
| UNDO
}
CONTINUE:表示继续执行当前SQL脚本。
EXIT:表示终止执行当前SQL脚本。即使condition_value由statement语句的BEGIN…AND语句块引发,也是一样会终止执行。
condition_value
六种条件类型
condition_value: {
mysql_error_code
| SQLSTATE [VALUE] sqlstate_value
| condition_name
| SQLWARNING
| NOT FOUND
| SQLEXCEPTION
}
下面是这6种条件的释义:
1、mysql_error_code:MySQL的错误码,整数类型:
DECLARE CONTINUE HANDLER FOR 1051
BEGIN
-- body of handler
END;
2、SQLSTATE :用5个字符表示的SQLSTATE值
DECLARE CONTINUE HANDLER FOR SQLSTATE '42S02'
BEGIN
-- body of handler
END;
以’00’开始的值表示成功。
**3、condition_name:使用DECLARE … CONDITION定义的条件的名称
如何使用DECLARE … CONDITION定义条件
4、SQLWARNING:相当于值从’01’开始的SQLSTATE
5、NOT FOUND:相当于值从’02’开始的SQLSTATE
比如说,你执行以下语句时
select * from user_role r where r.user_id = p_id;
如果找不到数据,那么就满足了not found这个条件,就会执行set done=true这条指令。
declare continue handler for not found set done = true;
总结:NOT FOUND可能被触发的条件有:
1、 SELECT INTO 语句或 INSERT 语句的子查询的结果为空表。
2、 在搜索的 UPDATE 或 DELETE 语句内标识的行数为零。
3、 在 FETCH 语句中引用的游标位置处于结果表最后一行之后。
6、SQLEXCEPTION:相当于值不为’00’,‘01’,'02’的所有 SQLSTATE
DECLARE CONTINUE HANDLER FOR 1051
BEGIN
-- body of handler
END;
DECLARE CONTINUE HANDLER FOR NOT FOUND
1、它的含义是:若没有数据返回,程序继续,并将变量IS_FOUND设为0 ,这种情况是出现在select XX into XXX from tablename的时候发生的。
2、每个游标必须使用不同的declare continue handler for not found set done=1来控制游标的结束
DECLARE CONTINUE HANDLER FOR NOT FOUND SET FOUND=FALSE;
SQL脚本....
handler_action:CONTINUE,执行动作,表示继续执行当前SQL脚本。
condition_value :NOT FOUND,触发条件
statement:SET FOUND=FALSE;定义的SQL语句
对应关系如上,如果执行Sql脚本到某一步时,NOT FOUND被触发,执行SET FOUND=FALSE;然后继续执行SQL脚本的接下来部分
游标的基本语法
声明光标
基本语法:
DECLARE <游标名> CURSOR FOR select 语句;
DECLARE cursor_name CURSOR FOR select_statement
#其中,cursor_name参数表示光标的名称;select_statement参数表示SELECT语句的内容,返回一个用于创建光标的结果集。
#例子
DECLARE cursor_fruit CURSOR FOR select f_name,f_price from fruits;
打开光标
基本语法:
OPEN cursor_name[光标名称]
#例子
OPEN cursor_fruit
使用光标
FETCH cursor_name into var_name[,var_name...][参数名称]
#例子
FETCH cursor_fruit into fruit_name,fruit_price
declare 变量1 数据类型(与列值的数据类型相同)
declare 变量2 数据类型(与列值的数据类型相同)
declare 变量3 数据类型(与列值的数据类型相同)
FETCH [ NEXT | PRIOR | FIRST | LAST|ABSOLUTE n|RELATIVE n] ] FROM <游标名> [ INTO 变量名1,变量名2,变量名3[,…] ]
说明:
NEXT——如果是在OPEN后第一次执行FETCH命令,则返回结果集的第一行,否则使游标的指针指向结果集的下一行,NEXT是默认的选项。
PRIOR——返回结果集当前行的前一行。
FIRST——返回结果集的第一行。
LAST——返回结果集的最后一行。
ABSOLUTE n——如果n是正数,返回结果集的第n行,如果n是负数,则返回结果集的倒数第n行
RELATIVE n——如果n是正数,返回当前行后的第n行,如果n是负数,则返回当前行开始倒数的第n行。
INTO——该语句的功能是把游标取出的当前记录送入到主变量,INTO后的主变量要与在DECLARE CURSOR中SELECT的字段相对应。
关闭光标
CLOSE cursor_name[光标名称]
#例子
close cursor_fruit
loop循环
例子1
drop procedure if exists getTotal;
CREATE PROCEDURE getTotal()
BEGIN
DECLARE total INT;
##创建接收游标数据的变量
DECLARE sid INT;
DECLARE sname VARCHAR(10);
#创建总数变量
DECLARE sage INT;
#创建结束标志变量
DECLARE done INT DEFAULT FALSE;
#创建游标
DECLARE cur CURSOR FOR SELECT id,name,age FROM cursor_table WHERE age>30;
#指定游标循环结束时的返回值
DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = TRUE;
#设置初始值
SET sage = 0;
SET total=0;
#打开游标
OPEN cur;
#开始循环游标里的数据
read_loop:LOOP
#根据游标当前指向的一条数据
FETCH cur INTO sid,sname,sage;
#判断游标的循环是否结束
IF done THEN
LEAVE read_loop; #跳出游标循环
END IF;
#获取一条数据时,将count值进行累加操作,这里可以做任意你想做的操作,
SET total = total + 1;
#结束游标循环
END LOOP;
#关闭游标
CLOSE cur;
#输出结果
SELECT total;
END; -- 存储过程结束
DELIMITER ;-- 重新定义结束符为默认的;
#调用存储过程
call getTotal();
例子2
用存储过程做一个功能,统计iphone的总库存是多少,并把总数输出到控制台
drop procedure if exists StatisticStore;
drop procedure if exists StatisticStore;
CREATE PROCEDURE StatisticStore()
BEGIN
-- 创建接收游标数据的变量
declare c int;
declare n varchar(20);
-- 创建总数变量
declare total int default 0;
-- 创建结束标志变量
declare done int default false;
-- 创建游标
declare cur cursor for select name,count from store where name = 'iphone';
-- 指定游标循环结束时的返回值
declare continue HANDLER for not found set done = true;
-- 设置初始值
set total = 0;
-- 打开游标
open cur;
-- 开始循环游标里的数据
read_loop:loop
-- 根据游标当前指向的一条数据
fetch cur into n,c;
-- 判断游标的循环是否结束
if done then
leave read_loop; -- 跳出游标循环
end if;
-- 获取一条数据时,将count值进行累加操作,这里可以做任意你想做的操作,
set total = total + c;
-- 结束游标循环
end loop;
-- 关闭游标
close cur;
-- 输出结果
select total;
END;
-- 调用存储过程
call StatisticStore();
fetch是获取游标当前指向的数据行,并将指针指向下一行,当游标已经指向最后一行时继续执行会造成游标溢出。
使用loop循环游标时,他本身是不会监控是否到最后一条数据了,像下面代码这种写法,就会造成死循环;
read_loop:loop
fetch cur into n,c;
set total = total+c;
end loop;
在MySql中,造成游标溢出时会引发mysql预定义的NOT FOUND错误,所以在上面使用下面的代码指定了当引发not found错误时定义一个continue 的事件,指定这个事件发生时修改done变量的值。
declare continue HANDLER for not found set done = true;
所以在循环时加上了下面这句代码
-- 判断游标的循环是否结束
if done then
leave read_loop; --跳出游标循环
end if;
如果done的值是true,就结束循环。继续执行下面的代码
while 循环
例子1
drop procedure if exists getTotal;
CREATE PROCEDURE getTotal()
BEGIN
DECLARE total INT;
##创建接收游标数据的变量
DECLARE sid INT;
DECLARE sname VARCHAR(10);
#创建总数变量
DECLARE sage INT;
#创建结束标志变量
DECLARE done INT DEFAULT false;
#创建游标
DECLARE cur CURSOR FOR SELECT id,name,age from cursor_table where age>30;
#指定游标循环结束时的返回值
DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = true;
SET total = 0;
OPEN cur;
FETCH cur INTO sid, sname, sage;
WHILE(NOT done)
DO
SET total = total + 1;
FETCH cur INTO sid, sname, sage;
END WHILE;
CLOSE cur;
SELECT total;
END;
#调用存储过程
call getTotal();
例子2
drop procedure if exists StatisticStore1;
drop procedure if exists StatisticStore1;
CREATE PROCEDURE StatisticStore1()
BEGIN
declare c int;
declare n varchar(20);
declare total int default 0;
declare done int default false;
declare cur cursor for select name,count from store where name = 'iphone';
declare continue HANDLER for not found set done = true;
set total = 0;
open cur;
fetch cur into n,c;
while(not done) do
set total = total + c;
fetch cur into n,c;
end while;
close cur;
select total;
END;
call StatisticStore1();
Repeat循环
例子1
drop procedure if exists getTotal;
CREATE PROCEDURE getTotal()
BEGIN
DECLARE total INT;
##创建接收游标数据的变量
DECLARE sid INT;
DECLARE sname VARCHAR(10);
#创建总数变量
DECLARE sage INT;
#创建结束标志变量
DECLARE done INT DEFAULT false;
#创建游标
DECLARE cur CURSOR FOR SELECT id,name,age from cursor_table where age > 30;
#指定游标循环结束时的返回值
DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = true;
SET total = 0;
OPEN cur;
REPEAT
FETCH cur INTO sid, sname, sage;
IF NOT done THEN
SET total = total + 1;
END IF;
UNTIL done END REPEAT;
CLOSE cur;
SELECT total;
END;
call getTotal();
例子2
drop procedure if exists StatisticStore2;
CREATE PROCEDURE StatisticStore2()
BEGIN
declare c int;
declare n varchar(20);
declare total int default 0;
declare done int default false;
declare cur cursor for select name,count from store where name = 'iphone';
declare continue HANDLER for not found set done = true;
set total = 0;
open cur;
repeat
fetch cur into n,c;
if not done then
set total = total + c;
end if;
until done end repeat;
close cur;
select total;
END;
call StatisticStore2();
游标嵌套
例子1
一、需求描述
1、在项目中,需要将A表中主键id,逐个取出,作为条件,在B表中去逐一查询,将B表查询到的结果集(A表B表关系:一对多),逐一遍历,连同A表的id,逐个插入到C表中。
二、思路
1、要实现逐行获取数据,需要用到MySQL中的游标,一个游标相当于一个for循环,这里需要用到2个游标。在MySQL中实现游标双层循环。
三、代码实现
创建表
#client表
drop table if EXISTS client;
create table if not EXISTS client(
name varchar(255)
);
insert into client VALUES
("小八54545"),
("李四"),
("王五"),
("王力"),
("小米6677"),
(" ")
#account表
drop table if EXISTS account;
create table if not EXISTS account(
balance int(20)
);
insert into account VALUES
(800),
(1600),
(900),
(1000);
")
#account表
drop table if EXISTS account;
create table if not EXISTS account(
balance int(20)
);
insert into account VALUES
(800),
(1600),
(900),
(1000);
要实现client表和account表中数据组合插入到batch表中
创建存储过程
注意:存储过程中declare要最先写,比create等操作语句要先。
DROP PROCEDURE IF EXISTS pro_cursor_nest;
CREATE PROCEDURE pro_cursor_nest()
BEGIN -- out BEGIN
DECLARE c_name VARCHAR(200) ;
DECLARE out_done INT DEFAULT FALSE ; -- 外层游标控制变量
DECLARE out_cursor CURSOR FOR (SELECT NAME FROM client ); -- 外层游标
DECLARE CONTINUE HANDLER FOR NOT FOUND SET out_done = TRUE ; -- 外层游标执行结束,置为TRUE
drop table if EXISTS batch;
create table if not EXISTS batch(
id varchar(255),
name varchar(255),
age int(20)
);
OPEN out_cursor ; -- 打开外层游标
WHILE NOT out_done DO -- out WHILE
FETCH out_cursor INTO c_name ; -- 从【外层游标】中获取数据,赋值到定义变量中
IF NOT out_done THEN -- out IF
-- 开始定义内层游标
BEGIN -- inner BEGIN
DECLARE money INT ;
DECLARE inner_done int DEFAULT FALSE ;
DECLARE inner_cursor CURSOR FOR ( SELECT balance FROM account );
DECLARE CONTINUE HANDLER FOR NOT FOUND SET inner_done = TRUE ;
OPEN inner_cursor ; -- 打开内层游标
WHILE NOT inner_done DO -- inner WHILE
FETCH inner_cursor INTO money ; -- 从【内层游标】中获取数据,赋值到定义变量中
IF NOT inner_done THEN
INSERT INTO `batch` (`id`, `name`, `age`) VALUES (UUID(),c_name ,money);
END IF;
END WHILE ; -- END inner WHILE
CLOSE inner_cursor; -- 循环结束后,关闭内层游标
END; -- END inner BEGIN
END IF; -- END out IF
END WHILE; -- END out WHILE
CLOSE out_cursor ; -- 循环结束后 ,关闭外层游标
END;
CALL pro_cursor_nest ();
四、总结
1、创建一个游标步骤如下:
定义变量,接收游标赋值 c_name
定义游标开关变量 done
定义游标 out_cursor
游标结束后,关闭开关 — DECLARE CONTINUE HANDLER FOR NOT FOUND SET
打开游标 OPEN out_cursor
开启循环 WHILE … DO ( 还有LOOP ,REPEAT 也可以)
从游标中获取数据,赋值到变量 (FETCH)
判断游标是否执行结束 (IF NOT out_done )
执行相应业务逻辑操作 do Something
结束循环 (END WHILE)
关闭游标 (CLOSE out_cursor)
2、创建双层游标,即在 【执行相应业务逻辑操作】,再 BEGIN … END , 重新定义一个新游标,注意嵌套关系即可。
3、觉得双层游标循环麻烦,不易理解的,分别写两个存储过程,也可以,那样业务更简单,易于理解,便于后期维护。
例子2
在mysql中,每个begin end 块都是一个独立的scope区域,由于MySql中同一个error的事件只能定义一次,如果多定义的话在编译时会提示Duplicate handler declared in the same block。即:一个begin…end中只能有一次。
drop procedure if exists StatisticStore3;
CREATE PROCEDURE StatisticStore3()
BEGIN
declare _n varchar(20);
declare done int default false;
declare cur cursor for select name from store group by name;
declare continue HANDLER for not found set done = true;
open cur;
read_loop:loop
fetch cur into _n;
if done then
leave read_loop;
end if;
begin
declare c int;
declare n varchar(20);
declare total int default 0;
declare done int default false;
declare cur cursor for select name,count from store where name = 'iphone';
declare continue HANDLER for not found set done = true;
set total = 0;
open cur;
iphone_loop:loop
fetch cur into n,c;
if done then
leave iphone_loop;
end if;
set total = total + c;
end loop;
close cur;
select _n,n,total;
end;
begin
declare c int;
declare n varchar(20);
declare total int default 0;
declare done int default false;
declare cur cursor for select name,count from store where name = 'android';
declare continue HANDLER for not found set done = true;
set total = 0;
open cur;
android_loop:loop
fetch cur into n,c;
if done then
leave android_loop;
end if;
set total = total + c;
end loop;
close cur;
select _n,n,total;
end;
begin
end;
end loop;
close cur;
END;
call StatisticStore3();
动态sql
基本语法
MySQL官方将prepare、execute、deallocate统称为PREPARE STATEMENT。即,预处理语句。
基本用法:
//获取预处理语句
PREPARE statement_name FROM sql_text /*定义*/
//执行预处理语句(可传入用户变量)
EXECUTE statement_name [USING variable [,variable...]] /*执行预处理语句*
//释放掉预处理资源
{DEALLOCATE | DROP} PREPARE stmt_name;
说明:
使用PAREPARE STATEMENT可以减少每次执行SQL的语法分析,
比如用于执行带有WHERE条件的SELECT和DELETE,或者UPDATE,或者INSERT,只需要每次修改变量值即可。
同样可以防止SQL注入,参数值可以包含转义符和定界符。
PREPARE … FROM可以直接接用户变量:
SET @sql1 = CONCAT(‘drop table if EXISTS ‘,v_table,’;’);
prepare stmt from @sql1; – 预处理需要执行的动态SQL,
每一次执行完EXECUTE时,养成好习惯,须执行DEALLOCATE PREPARE …语句,这样可以释放执行中使用的所有数据库资源(如游标),如果在存储过程中使用,如果不在过程中DEALLOCATE掉,在存储过程结束之后,该预处理语句仍然会有效。
例子
例子1
PREPARE prod FROM "INSERT INTO tablea VALUES(?,?)";
SET @p='1';
SET @q='2';
EXECUTE prod USING @p,@q;
SET @name='3';
EXECUTE prod USING @p,@name;
DEALLOCATE PREPARE prod;
例子2
SET @a=1;
PREPARE STMT FROM "SELECT * FROM tablea LIMIT ?";
EXECUTE STMT USING @a;
SET @skip=2; SET @numrows=2;
PREPARE STMT FROM "SELECT * FROM tablea LIMIT ?, ?";
EXECUTE STMT USING @skip, @numrows;
DEALLOCATE PREPARE stmt;
例子3
PREPARE stmt1 FROM 'SELECT SQRT(POW(?,2) + POW(?,2)) AS hypotenuse';
SET @a = 3;
SET @b = 4;
EXECUTE stmt1 USING @a, @b;
DEALLOCATE PREPARE stmt1;
使用 PREPARE 的几个注意点:
A:PREPARE stmt_name FROM preparable_stmt;预定义一个语句,并将它赋给 stmt_name ,tmt_name 是不区分大小写的。
B: 即使 preparable_stmt 语句中的 ? 所代表的是一个字符串,你也不需要将 ? 用引号包含起来。
C: 如果新的 PREPARE 语句使用了一个已存在的 stmt_name ,那么原有的将被立即释放! 即使这个新的 PREPARE 语句因为错误而不能被正确执行。
D: PREPARE stmt_name 的作用域是当前客户端连接会话可见。
E: 要释放一个预定义语句的资源,可以使用 DEALLOCATE PREPARE 句法。
F: EXECUTE stmt_name 句法中,如果 stmt_name 不存在,将会引发一个错误。
G: 如果在终止客户端连接会话时,没有显式地调用 DEALLOCATE PREPARE 句法释放资源,服务器端会自己动释放它。
H: 在预定义语句中,CREATE TABLE, DELETE, DO, INSERT, REPLACE, SELECT, SET, UPDATE, 和大部分的 SHOW 句法被支持。
1、存储动态SQL的值的变量不能是自定义变量,必须是用户变量或者全局变量 如:set sql = ‘xxx’; prepare stmt from sql;是错的,正确为: set @sql = ‘xxx’; prepare stmt from @sql;
2、即使 preparable_stmt 语句中的 ? 所代表的是一个字符串,你也不需要将 ? 用引号包含起来。
3、如果动态语句中用到了 in 则sql语句应该这样写:set @sql = "select * from user where user_id in (?,?,?)
动态建表
例子1
CREATE TABLE if not exists `${item}` (
sys_id bigint NOT NULL,
mpnt_id bigint NOT NULL,
data_date DATE NOT NULL,
data_point int NOT NULL,
data_item_id bigint NOT NULL,
val DECIMAL(10,2) NOT NULL,
KEY `${item}_sys_id` (`sys_id`),
KEY `${item}_mpnt_id` (`mpnt_id`),
KEY `${item}_data_date` (`data_date`),
KEY `${item}_data_point` (`data_point`),
KEY `${item}_data_item_id` (`data_item_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
例子2
CREATE PROCEDURE `proc_copy_table`(IN v_table VARCHAR(20),IN v_db VARCHAR(20),OUT o_result int(4))
BEGIN
DECLARE exit HANDLER FOR SQLEXCEPTION
begin
rollback; -- 有异常,进行回滚
set o_result = -500;
end;
START TRANSACTION;
SET @sql1 = CONCAT('drop table if EXISTS ',v_table,';');
-- drop table if EXISTS v_table;
prepare stmt from @sql1; -- 预处理需要执行的动态SQL,
EXECUTE stmt;
deallocate prepare stmt; -- 释放掉预处理段
set @sql2 = CONCAT('create table ',v_table,' like ',v_db,'.',v_table,';');
-- create table v_table like v_db.v_table;
prepare stmt from @sql2; -- 预处理需要执行的动态SQL,
EXECUTE stmt;
deallocate prepare stmt; -- 释放掉预处理段
set @sql3 = CONCAT('insert into ',v_table,' select * from ',v_db,'.',v_table,';');
-- insert into v_table select * from v_db.v_table;
prepare stmt from @sql3; -- 预处理需要执行的动态SQL,
EXECUTE stmt;
deallocate prepare stmt; -- 释放掉预处理段
COMMIT;
set o_result :=0;
end
set @a=1;
call proc_copy_table('student','zsm',@a);
SELECT @a
例子3
drop procedure if exists dataMove; /*删除已有的存储过程*/
create procedure dataMove()
begin
declare tablename_fix varchar(64); /*定义表的尾号*/
declare flag boolean default true;/*判断游标是否结束*/
declare fix_cursor cursor for
select fix from tablea group by fix; /*定义游标 把table_suffix列分组出来 放到游标中*/
declare continue handler for not found set flag = false;/*游标结束时 标识改为false*/
open fix_cursor;/*打开游标*/
fetch fix_cursor into tablename_fix; /*把游标里的数据取出来放到这个变量中*/
while flag do
set @tablename = concat('tablea',tablename_fix);/*concat() 拼接方法 就是+''+, 表名 原始名字+尾号列*/
/*根据表名创建表,把对应满足的数据放到创建的表中 如果已经有了表 就得改方式*/
set @sqlstr =concat('create table ', @tablename,'( SELECT * FROM tablea where fix=',tablename_fix,');');
PREPARE STMT FROM @sqlstr; /*这三句执行销毁sql*/
EXECUTE STMT;
DEALLOCATE PREPARE STMT;
fetch fix_cursor into tablename_fix; /*游标指针往下一行*/
end while;
close fix_cursor;
end;
/*调用*/
call dataMove()
动态sql例子
例子1
DROP PROCEDURE IF EXISTS proc_sql; -- 判断proc_sql存储过程存在删除
CREATE PROCEDURE proc_sql () -- 创建proc_sql存储过程
BEGIN declare p1 int; -- 设置p1变量
set p1 = 1; -- 赋值p1变量等于11
set @p1 = p1; -- 赋值字符串占位符变量等于p1
PREPARE prod FROM 'select * from users where id > ?'; -- 解析字符串为sql语句
EXECUTE prod USING @p1; -- 执行sql语句,并且用占位符变量替换sql语句中的?号 DEALLOCATE
DEALLOCATE prepare prod; -- 释放解析和执行sql语句
END;
call proc_sql()
例子2
DROP PROCEDURE IF EXISTS NewProc;
CREATE PROCEDURE `NewProc`(IN `USER_ID` int ,IN `USER_NAME` varchar(36) )
BEGIN
declare SQL_FOR_SELECT varchar(500);
set SQL_FOR_SELECT = CONCAT("select * from users where id = ",USER_ID," and name = ","'",USER_NAME,"'");
set @sql = SQL_FOR_SELECT;
PREPARE stmt FROM @sql;
EXECUTE stmt ; -- 执行sql语句
deallocate prepare stmt; -- 释放prepare
END;
call NewProc(1,'张三')
#上述是一个简单的查询用户表的存储过程,当我们调用此存储过程,可以根据传入不同的参数获得不同的值。但是:上**述存储过程中,我们必须在拼接sql语句之前把USER_ID,USER_NAME定义好,而且在拼接sql语句之后,我们无法改变USER_ID,USER_NAME的值**,如下:
DROP PROCEDURE IF EXISTS NewProc;
CREATE PROCEDURE `NewProc`(IN `USER_ID` int,IN `USER_NAME` varchar(36))
BEGIN
declare SQL_FOR_SELECT varchar(500);
set SQL_FOR_SELECT = CONCAT("select * from users where id = '",USER_ID,"' and name = '",USER_NAME,"'"); -- 拼接查询sql语句
set @sql = SQL_FOR_SELECT;
PREPARE stmt FROM @sql; -- 预处理动态sql语句
EXECUTE stmt ; -- 执行sql语句
deallocate prepare stmt; -- 释放prepare
set USER_ID = 3;
set USER_NAME = '王五';
set @sql = SQL_FOR_SELECT;
PREPARE stmt FROM @sql; -- 预处理动态sql语句
EXECUTE stmt ; -- 执行sql语句
deallocate prepare stmt; -- 释放prepare
END;
call NewProc(1,'张三')
#我们用call NewProc(1,'张三')来调用该存储过程,第一次动态执行,我们得到了‘张三’的信息,然后我们在第14,15行将USER_ID,USER_NAME改为王五,我们希望得到王五的相关信息,可查出来的结果依旧是张三的信息,说明我们在拼接sql语句后,不能再改变参数了。为了解决这种问题,下面介绍第二中方式:
'''set sql = (预处理的sql语句,可以是用concat拼接的语句,参数用 ?代替)
set @sql = sql
PREPARE stmt_name FROM @sql;
set @var_name = xxx;
EXECUTE stmt_name USING [USING @var_name [, @var_name] ...];
{DEALLOCATE | DROP} PREPARE stmt_name;'''
#**上述的代码我们就可以改成 :**
DROP PROCEDURE IF EXISTS NewProc;
CREATE PROCEDURE `NewProc`(IN `USER_ID` int,IN `USER_NAME` varchar(36))
BEGIN
declare SQL_FOR_SELECT varchar(500);
set SQL_FOR_SELECT = "select * from users where id = ? and name = ? ";
set @sql = SQL_FOR_SELECT;
PREPARE stmt FROM @sql;
set @parm1 = USER_ID;
set @parm2 = USER_NAME;
EXECUTE stmt USING @parm1 , @parm2;
set @sql = SQL_FOR_SELECT;
PREPARE stmt FROM @sql;
set @parm1 = '3';
set @parm2 = '王五';
EXECUTE stmt USING @parm1 , @parm2;
deallocate prepare stmt;
END;
call NewProc(1,'张三')
#这样,我们就可以真正的使用不同的参数(当然也可以在存储过程中通过逻辑生成不同的参数)来使用动态sql了。
#几个注意:
'''存储动态SQL的值的变量不能是自定义变量,必须是用户变量或者全局变量 如:set sql = 'xxx'; prepare stmt from sql;是错的,正确为: set @sql = 'xxx'; prepare stmt from @sql;
即使 preparable_stmt 语句中的 ? 所代表的是一个字符串,你也不需要将 ? 用引号包含起来。
如果动态语句中用到了 in 则sql语句应该这样写:set @sql = "select * from user where user_id in (?,?,?) "'''
游标例子
例子1
drop procedure if EXISTS test11;
create procedure test11()
begin
declare stopflag int default 0;
declare username VARCHAR(32);
-- 创建一个游标变量,declare 变量名 cursor ...
declare username_cur cursor for select name from users where id%2=0;
-- 游标是保存查询结果的临时区域
-- 游标变量username_cur保存了查询的临时结果,实际上就是结果集
-- 当游标变量中保存的结果都查询一遍(遍历),到达结尾,将变量stopflag设置为1,用于循环中判断是否结束
declare continue handler for not found set stopflag=1;
open username_cur; -- 打卡游标
fetch username_cur into username; -- 游标向前走一步,取出一条记录放到变量username中
while(stopflag=0) do -- 如果游标还没有结尾,就继续
begin
-- 在用户名前门拼接 '_cur' 字符串
update users set name=CONCAT(username,'_cur') where name=username;
fetch username_cur into username;
end;
end while; -- 结束循环
close username_cur; -- 关闭游标
end;
call test11()
例子2
drop procedure if exists cursor_test;
delimiter //
create procedure cursor_test()
begin
-- 声明与列的类型相同的四个变量
declare id varchar (20);
declare pname varchar (20);
declare pprice varchar (20);
declare pdescription varchar (20);
-- 1、定义一个游标mycursor
declare mycursor cursor for
select * from shops_info;
-- 2、打开游标
open mycursor;
-- 3、使用游标获取列的值
fetch next from mycursor into id,pname,pprice,pdescription;
-- 4、显示结果
select id,pname,pprice,pdescription;
-- 5、关闭游标
close mycursor;
end ;
//
delimiter ;
call cursor_test();
例子3
例子从游标中检索第一行:
drop procedure if exists processorders;
create procedure processorders()
begin
declare o VARCHAR(64);
declare ordernumbers cursor for select order_num from orders;
open ordernumbers;
-- 利用fetch检索出第一行的order_num存储到一个名为o的局部变量中。
fetch ordernumbers into o;
SELECT o;
close ordernumbers;
end;
call processorders()
例子4
例子检索游标中的所有行,从第一行到最后一行
drop procedure if exists processorders;
create procedure processorders()
begin
declare done boolean default 0;
declare o varchar(64);
declare ordernumbers cursor for select order_num from orders;
/*
这条语句定义了一个continue handler,它是在条件出现时被执行的代码。这里,它指出当
sqlstate "02000"出现时,set done = 1。sqlstate "02000"是一个未找到条件,当
repeate由于没有更多的行供循环而不能继续时,出现这个条件。
*/
declare continue handler for sqlstate "02000" set done = 1;
open ordernumbers;
-- 当done为真(非零)时结束循环。
repeat
fetch ordernumbers into o;
select o;
until done end repeat;
close ordernumbers;
end;
call processorders()
例子5
从游标中取出的数据进行某种实际的处理
drop procedure if exists processorders;
create procedure processorders()
begin
declare done boolean default 0;
declare o varchar(64);
declare t int(20) default 1;
declare ordernumbers cursor for select order_num from orders;
declare continue handler for sqlstate "02000" set done = 1;
-- 创建一个表用来存放结果
create table if not exists ordertotals
(order_num varchar(64), total int(20));
open ordernumbers;
repeat
fetch ordernumbers into o;
set t=t+1;
insert into ordertotals(order_num, total)
values(o, t);
until done end repeat;
close ordernumbers;
end;
-- 此存储过程不返回数据,但它能创建和填充另一个表。
call processorders()
创建存储函数
基本语法
CREATE FUNCTION func_name([func_parameter])
RETURN type
[characteristics...] routine body
#1、func_name 为存储函数的名称
#2、func_parameter为指定存储过程的参数列表
#列表形式如下:
#[IN|OUT|INOUT param_name type] type 是指参数的数据类型
#IN表示输入参数,OUT表示输出参数,INOUT表示既可以输入也可以输出,param_name是参数名称
#characteristics指定存储函数的特性,取值和存储过程类似,有以下取值:LANGUAGE SQL、[NOT] DETERMINISTIC等
#routine body 是sql代码的内容
#RETURN type表示函数返回的数据类型
'''**LANGUAGE SQL**
存储过程语言,默认是sql,说明存储过程中使用的是sql语言编写的,暂时只支持sql,后续可能会支持其他语言
**NOT DETERMINISTIC**
是否确定性的输入就是确定性的输出,默认是NOT DETERMINISTIC,只对于同样的输入,输出也是一样的,当前这个值还没有使用
**CONTAINS SQL**
提供子程序使用数据的内在信息,这些特征值目前提供给服务器,并没有根据这些特征值来约束过程实际使用数据的情况,说白了就是没有使用的
包括以下四种选择
1.CONTAINS SQL表示子程序不包含读或者写数据的语句
2.NO SQL 表示子程序不包含sql
3.READS SQL DATA 表示子程序包含读数据的语句,但是不包含写数据的语句
4.MODIFIES SQL DATA 表示子程序包含写数据的语句。
**SQL SECURITY DEFINER**
用来指定存储过程是使用创建者的许可来执行,还是执行者的许可来执行,默认值是DEFINER
DEFINER 创建者的身份来调用,对于当前用户来说:如果执行存储过程的权限,且创建者有访问表的权限,当前用户可以成功执行过程的调用的
说白了就是当前用户调用存储过程,存储过程执行的具体操作是借助定义存储过程的user的权限执行的。
INVOKER 调用者的身份来执行,对于当前用户来说:如果执行存储过程的权限,以当前身份去访问表,如果当前身份没有访问表的权限,即便是有执行过程的权限,仍然是无法成功执行过程的调用的。
说白了就是当前用户调用存储过程,只有当前用户有执行存储过程中涉及的对象的操作的权限的时候,才能成功执行。'''
例子
例子1
SET GLOBAL log_bin_trust_function_creators = 1;
drop function if exists getScoreResult;
DELIMITER //
CREATE FUNCTION getScoreResult(score INT)
RETURNS CHAR(2)
BEGIN
DECLARE result CHAR(2) DEFAULT '';
IF score>90 THEN
SET result='优';
ELSEIF score>80 THEN
SET result='良';
ELSEIF score>70 THEN
SET result='一般';
ELSE
SET result='差';
END IF; -- 结束if条件
RETURN result;
END //
delimiter ;
SELECT getScoreResult(50),getScoreResult(90);
例子2
DROP FUNCTION IF EXISTS getusername;
create function getusername(userid int) returns varchar(32)
reads sql data -- 从数据库中读取数据,但不修改数据
begin
declare username varchar(32) default '';
select name into username from users where id=userid;
return username;
end;
SELECT getusername(1)
'''概括:
1.创建函数使用create function 函数名(参数) returns 返回类型;
2.函数体放在begin和end之间;
3.returns指定函数的返回值;
4.函数调用使用select getusername()。'''
例子3
需求:根据userid,获取accoutid,id,name组合成UUID作为用户的唯一标识
DROP FUNCTION IF EXISTS getuuid;
create function getuuid(userid int) returns varchar(64)
reads sql data -- 从数据库中读取数据,但不修改数据
begin
declare uuid varchar(64) default '';
select concat(accontid,'_',id,'_',name) into uuid from users where id=userid;
return uuid;
end;
SELECT getuuid(1)
mysql 触发器
触发器简介
触发器与函数、存储过程一样,触发器是一种对象,它能根据对表的操作时间,触发一些动作,这些动作可以是insert,update,delete等修改操作。
创建触发器
基本语法
BEFORE表示在触发事件发生之前执行触发程序。
AFTER表示在触发事件发生之后执行触发器。
FOR EACH ROW表示数据更新(INSERT、UPDATE或者DELETE)操作影响的每一条记录都会执行一次触发程序。
mySql仅支持行级触发器,不支持语句级别的触发器(例如CREATE TABLE等语句)。
OLD、NEW关键字
当向表插入新记录时,在触发程序中可以使用NEW关键字表示新记录,当需要访问新记录的某个字段值时,可以使用“NEW.字段名”的方式访问。
当从表中删除某条旧记录时,在触发程序中可以使用OLD关键字表示旧记录,当需要访问旧记录的某个字段值时,可以使用“OLD.字段名”的方式访问。
old和new
1、插入操作insert
对于insert语句,如果原表中没有数据,那么对于插入数据后表来说新插入的那条数据就是new。比如下面是SQL
drop trigger if exists insert_tableB;
-- 如果有这个触发器就先删除
create trigger insert_tableB
-- 触发表名称 insert_tableB
after insert
-- 触发条件,在insert操作之后
on tableA
-- 需要在哪个表触发
for each row
begin
insert into tableB (`code`,`id`)
values(
new.`code`,
new.`id`
);
-- sql语句
end;
当我们在tableA表中执行insert操作后,tableB表会自动插入一条数据,这个时候,这条数据用new表示。
2.更新操作 update
当使用update语句的时候,当修改原表数据的时候相对于修改数据后表的数据来说原表中修改的那条数据就是old,而修改数据后表被修改的那条数据就是new。
比如我们下面这个触发器:
drop trigger if exists update_tableB;
-- 如果有这个触发器就先删除
create trigger update_tableB
-- 触发表名称 update_tableB
after update
-- 触发条件,在update操作之后
on tableA
-- 需要在哪个表触发
for each row
begin
update tableB
set
code_code = new.`code`,
id_id =new.`id`
WHERE code_code=old.`code`;
-- sql语句
end;
其中比较关键的是:
update tableB
set
code_code = new.`code`,
id_id =new.`id`
WHERE code_code=old.`code`;
可以看出,我们set的是新值(new)。而用where条件限定的是旧值(old)。
这样就完成更新操作了。
3.删除操作delete
当使用delete语句的时候,删除的那一条数据相对于删除数据后表的数据来说就是old。
比如下面这个触发器
drop trigger if exists delete_tableB;
-- 如果有这个触发器就先删除
create trigger delete_tableB
-- 触发表名称 delete_tableB
after DELETE
-- 触发条件,在delete操作之后
on tableA
-- 需要在哪个表触发
for each row
begin
DELETE from tableB
WHERE code_code=old.`code`;
-- sql语句
end;
可以看出,我们删除B表的操作,where限定条件也是old。
4、简单总结
old表示插入之前的值,new表示新插入的值;old用在删除和修改,new用在添加和修改。
创建只有一个执行语句的触发器
CREATE TRIGGER trigger_name trigger_time trigger_event
on tb1_name for each row trigger_stmt
#其中,trigger_name表示触发器名称,用户自行指定;trigger_time表示触发时机,可以指定为before或 after; trigger event表示触发事件,包括INSERT、UPDATE和 DELETE; tbl_name 表示建立触发器的表名,即在哪张表上建立触发器;trigger_stmt是触发器执行语句。
例子:
#创建表
CREATE TABLE account(acct_num int,amount decimal(10,2))
#创建触发器
create trigger ins_sum before insert on account
for each row set@sum=@sum+new.amount
#插入数据
set @sum=0
insert into account values (1,1.00),(2,2.00)
select @sum
#首先,创建一个account表,表中有两个字段,分别为acct_num字段(定义为int类型)和amount 字段(定义成浮点类型);其次,创建一个名为ins_sum的触发器,触发的条件是向数据表account 插入数据之前,对新插入的 amount字段值进行求和计算。
创建有多个执行语句的触发器
CREATE TRIGGER trigger_name trigger_time trigger_event
on tb1_name for each row
begin
语句执行列表
end
#其中,trigger_name标识触发器的名称,用户自行指定;trigger_time标识触发时机,可以指定为before或 after; trigger_event标识触发事件,包括INSERT、UPDATE和DELETE; tbl_name标识建立触发器的表名,即在哪张表上建立触发器;触发器程序可以使用BEGIN和END作为开始和结束,中间包含多条语句。
#
例子:
#创建表
DROP table if EXISTS test1;
DROP table if EXISTS test2;
DROP table if EXISTS test3;
DROP table if EXISTS test4;
create table test1(a1 int);
create table test2(a2 int);
create table test3(a3 int);
create table test4(
a4 int not null auto_increment primary key,
b4 int DEFAULT 0);
#创建触发器
create trigger testref before insert on test1
for each row
begin
insert into test2 set a2=new.a1;
delete from test3 where a3=new.a1;
update test4 set b4= b4 +1 where a4=new.a1;
end;
#插入数据
insert into test3 (a3) values
(null),(null),(null),(null),(null),
(null),(null),(null),(null),(null);
insert into test4 (a4) values
(0),(0),(0),(0),(0),(0),(0),(0),(0),(0);
insert into test1 values
(1),(3),(1),(7),(1),(8),(4),(4);
#执行结果显示,在向表testl插入记录的时候,test2、test3、test4都发生了变化。从这个例子看INSERT触发了触发器,向 test2中插入了 test1 中的值,删除了 test3 中相同的内容,同时更新了test4中的b4,即与插入的值相同的个数。
触发器例子
例子1
需求:出于审计目的,当有人往表users插入一条记录时,把插入的userid,username,插入动作和操作时间记录下来。
#创建触发器
drop trigger if EXISTS tr_users_insert;
create trigger tr_users_insert after insert on users
for each row
begin
insert into oplog(userid,username,action,optime)
values(NEW.id,NEW.name,'insert',now());
end;
#插入数据
insert into users(id,name,age,status,score,accontid)
values(6,'小周',23,1,'60','10001');
总结:
1、创建触发器使用create trigger 触发器名
2、什么时候触发?after insert on users,除了after还有before,是在对表操作之前(before)或者之后(after)触发动作的。
3、对什么操作事件触发? after insert on users,操作事件包括insert,update,delete等修改操作;
4、对什么表触发? after insert on users
5、影响的范围?for each row
例子2
#创建表
-- ----------------------------
-- Table structure for `t_card`
-- ----------------------------
DROP TABLE IF EXISTS `t_card`;
CREATE TABLE `t_card` (
`cardId` varchar(255) NOT NULL,
`password` char(6) NOT NULL,
`balance` int(11) NOT NULL,
`open_date` date NOT NULL,
PRIMARY KEY (`cardId`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of t_card
-- ----------------------------
INSERT INTO t_card VALUES ('6221 1001', '111222', '900', '2019-08-08');
INSERT INTO t_card VALUES ('6221 1002', '111111', '500', '2019-08-08');
INSERT INTO t_card VALUES ('6221 2221', '565555', '200', '2019-08-08');
DROP TABLE IF EXISTS t_tran;
CREATE TABLE IF NOT EXISTS t_tran(
id int auto_increment PRIMARY key,
cardId varchar(255) not null,
type varchar(10) not null,
money int not null,
t_time DATE not null,
FOREIGN KEY(cardId) REFERENCES t_card(cardId)
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
#创建触发器
DROP TRIGGER IF EXISTS t_update;
CREATE TRIGGER t_update AFTER UPDATE ON t_card
FOR EACH ROW
BEGIN
DECLARE vtype VARCHAR(10);
DECLARE m1 int;
DECLARE m2 int;
SELECT OLD.balance INTO m1 from t_card where cardid=OLD.cardid;
SELECT NEW.balance INTO m2 from t_card where cardid=OLD.cardid;
IF m2>m1 THEN SET vtype='存款';
ELSE SET vtype='取款';
END IF;
INSERT INTO t_tran(cardid,type,money,t_time)VALUES(OLD.cardId,vtype,ABS(m2-m1),NOW());
END;
#更新值
UPDATE t_card set balance=balance-200 WHERE cardid='6221 1002';
SELECT * from t_card;
SELECT * from t_tran;
存储过程+event
创建事件
基本语法
create event[IF NOT EXISTS]event_name -- 创建使用create event
ON SCHEDULE schedule -- on schedule 什么时候来执行
[ON COMPLETION [NOT] PRESERVE] -- 调度计划执行完成后是否还保留
[ENABLE | DISABLE] -- 是否开启事件,默认开启
[COMMENT 'comment'] -- 事件的注释
DO sql_statement; -- 这个调度计划要做什么?
执行时间说明
1.单次计划任务示例
在2019年2月1日4点执行一次
on schedule at ‘2019-02-01 04:00:00’
2. 重复计划执行
on schedule every 1 second 每秒执行一次
on schedule every 1 minute 每分钟执行一次
on schedule every 1 day 没天执行一次
3.指定时间范围的重复计划任务
每天在20:00:00执行一次
on schedule every 1 day starts ‘2019-02-01 20:00:00’
例子
例子1
DROP PROCEDURE IF EXISTS open_lottery;
create procedure open_lottery()
begin
insert into lottery(num1,num2,num3,ctime)
select FLOOR(rand()*9)+1,FLOOR(rand()*9)+1,FLOOR(rand()*9)+1,now();
end;
create event if not exists lottery_event -- 创建一个事件
on schedule every 10 second -- on schedule 什么时候来执行,没三分钟执行一次
on completion preserve
do call open_lottery();
注意,如果event之一没有运行,请按照以下办法解决:
(1)、 show variables like ‘%event_scheduler%’;
set global event_scheduler=on;
(2)、 ALTER event lottery_event enable;
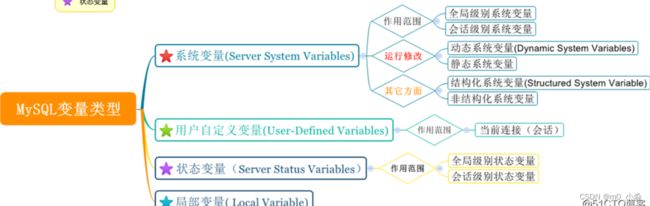
mysql变量的种类
会话变量 和 全局变量 在 MySQL 中统称为 系统变量
局部变量只存在于函数和存储过程
declare语句专门用于定义局部变量。set语句是设置不同类型的变量,包括会话变量和全局变量
通俗理解术语之间的区别:
用户定义的变量就叫用户变量。这样理解的话,会话变量和全局变量都可以是用户定义的变量。只是他们是对当前客户端生效还是对所有客户端生效的区别了。所以,用户变量包括了会话变量和全局变量
局部变量与用户变量的区分在于两点:1.用户变量是以”@”开头的。局部变量没有这个符号。2.定义变量不同。用户变量使用set语句,局部变量使用declare语句定义 3.作用范围。局部变量只在begin-end语句块之间有效。在begin-end语句块运行完之后,局部变量就消失了。
所以,最后它们之间的层次关系是:变量包括局部变量和用户变量。用户变量包括会话变量和全局变量。
1、用户变量:
以”@”开始,形式为”@变量名”。用户变量跟mysql客户端是绑定的,设置的变量,只对当前用户使用的客户端生效,也就是说,一个客户端定义的变量不能被其它客户端看到或使用。当客户端退出时,该客户端连接的所有变量将自动释放。
1) 用户变量第一种用法,使用 set,
这时可以用 “=” 或 “:=” 两种赋值符号赋值(用来把一个值赋给一个变量的标量表达式可以是复合表达式。计算,函数,系统标量以及其他用户变量都是允许的,子查询也是允许的。然后通过select语句可以获取一个用户变量的值,结果是带有一行的一个表。):
SET @var_name = expr [, @var_name = expr] ...
如:set @t1 =100;
set @age := 20;
set @var1=1, @var2='vartest', @var3=abs(-2), @var4=(select count(*) from mysql.user);
select @var1, @var2, @var3, @var4;
##
@var1 @var2 @var3 @var4
1 vartest 2 4
SET @userName = (SELECT name FROM user WHERE id = 2);
SET @currTime := CURRENT_TIMESTAMP();
在用来为一个用户变量赋值的表达式中,也可以指定其它的用户变量, 需要注意的是mysql首先确定所有表达式的值,之后才会把值赋给变量。
mysql> set @varA = 3, @varB = @varA;
mysql> select @varB;
+-------+
| @varB |
+-------+
| 2 |
+-------+
mysql> set @varA = 3;
mysql> set @varB = @varA;
mysql> select @varB;
+-------+
| @varB |
+-------+
| 3 |
+-------+
2)用户变量第二种用法,使用 select,
这时必须用 “:=” 赋值符号赋值,分配符必须为:=而不能用=,因为在非SET语句中=被视为一个比较操作符:
select @age := 32;
select @age := stu_age
from student
where stu_id = 'A001';
mysql> SELECT @t1:=(@t2:=1)+@t3:=4,@t1,@t2,@t3;
SELECT @row := row_no,@name := book_name FROM tb_book WHERE id = 1;
SELECT @userName := name FROM user WHERE id = 1;
例子1:
set @var1 = 3;
set @var2 = 2;
select @sum := ( @var1 + @var2 ) as sum, @dif := ( @var1 - @var2 ) as dif;
# 结果是 sum = 5,dif = 1
例子2
SET @t1 := 0, @t2 := 0, @t3 := 0;
SET @t1 := ( @t2 := 2 ) + ( @t3 := 4 );
select @t1; # 结果是 6
select @t2 * @t3; # 结果是 8
例子3
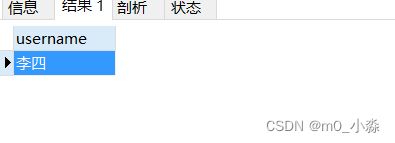
SELECT @salToLisi := salary FROM employee WHERE NAME = '李四';
-- 使用方式一
SELECT @salToLisi;
-- 使用方式二
SELECT * FROM employee WHERE salary < @salToLisi;
3)使用select… into赋值
其语法格式如下:
SELECT col_name[,...] INTO var_name[,...] FROM table_name WHERE condition;
#(1)col_name:查询的字段名称。
#(2)var_name:变量的名称。
-- 变量赋值
SELECT row_no,book_name INTO @row,@name FROM tb_book WHERE id = 1;
-- 输出结果
SELECT @row;
SELECT @name;
用户变量注意事项
1、在 SELECT 的 WHERE 、 GROUP BY 和 ORDER BY 中用户变量都不会按预期操作,它使用的是旧值,不会实时修改:
CREATE TABLE employee (
id int primary key,
salary int not null
);
INSERT INTO employee VALUES(1, 100);
INSERT INTO employee VALUES(2, 200);
INSERT INTO employee VALUES(3, 300);
SELECT salary, (@rowno := @rowno + 1) AS 'rowno'
FROM employee, (SELECT @rowno := 0) r;
###
+--------+-------+
| salary | rowno |
+--------+-------+
| 100 | 1 |
| 200 | 2 |
| 300 | 3 |
+--------+-------+
没有问题,一切都和预期一样,然后我们加一个 WHERE 条件试试:
```sql
SELECT salary, (@rowno := @rowno + 1) AS 'rowno'
FROM employee, (SELECT @rowno := 0) r
WHERE @rowno = 0;
####
+--------+-------+
| salary | rowno |
+--------+-------+
| 100 | 1 |
+--------+-------+
理论上来说,这是不应该返回数据的,但是它还就是返回了一条数据,就是 id 为 1 的那条。
为什么呢? WHERE 条件使用的 @rowno 一直都是同一个值 0 ,它不会因为 SELECT 上修改了就实时响应 。要实现 WHERE 的功能需要改写成如下:
SELECT salary, rowno
FROM (
SELECT salary, (@rowno := @rowno + 1) AS 'rowno'
FROM employee, (SELECT @rowno := 0) r
) m
WHERE rowno = 2;
####
+--------+-------+
| salary | rowno |
+--------+-------+
| 200 | 2 |
+--------+-------+
1、用户变量用在where或having(以及HAVING、GROUP BY或者ORDER BY子句)子句中,他们必须首先用另一条语句来定义,如下面例子,初次查询没有返回结果,先定以后在查询才有输出:
mysql> select @H:='localhost' from mysql.user where host = @H;
Empty set (0.00 sec)
mysql> select @H:='localhost';
+-----------------+
| @H:='localhost' |
+-----------------+
| localhost |
+-----------------+
1 row in set (0.00 sec)
mysql> select @H:='localhost', user from mysql.user where host = @H;
+-----------------+-----------------+
| @H:='localhost' | user |
+-----------------+-----------------+
| localhost | |
| localhost | jesse |
| localhost | local |
| localhost | root |
| localhost | user_tab_update |
+-----------------+-----------------+
2、用户变量为session级别,当我们关闭客户端或退出登录时用户变量全部消失。如果想用就保存自定义的变量,需要自行创建一个表,将标量insert到表里。
3、用户变量名对大小写不敏感。
4、未定义的变量初始化是null。
补充知识:mysql语句do
在do语句中,使用了一个或多个标量表达式,mysql会一条一条的处理它们,但并不显示表达式的结果。例如我们可以调用函数执行后台的某些事情,而不需要看到其结果。
mysql> do sleep(5);
Query OK, 0 rows affected (5.00 sec)
在当前的存储过程和函数中使用变量
1、定义变量:
declare 变量名[,变量名2...] 变量类型 [default 默认值]
2、赋值变量:
set 变量名1=变量值1(或者表达式)[ ,变量名2=变量值2(或者表达式)]
3、使用变量:
select 列名[,列名...] into 变量名1[,变量名二...]
使用select… into赋值
其语法格式如下:
SELECT col_name[,...] INTO var_name[,...] FROM table_name WHERE condition;
#(1)col_name:查询的字段名称。
#(2)var_name:变量的名称。
-- 变量赋值
SELECT row_no,book_name INTO @row,@name FROM tb_book WHERE id = 1;
-- 输出结果
SELECT @row;
SELECT @name;
2、全局变量(系统变量):
1)定义时,以如下两种形式出现,set GLOBAL 变量名 或者 set @@global.变量名,对所有客户端生效。
2)当服务器启动时,它将所有全局变量初始化为默认值。这些默认值可以在选项文件中或在命令行中指定的选项进行更改。
3)服务器启动后,通过连接服务器并执行SET GLOBAL var_name语句,可以动态更改这些全局变量,只有具有super权限才可以设置全局变量.
4)对于全局变量的更改可以被访问该全局变量的任何客户端看见。然而,它只影响更改后连接的客户的从该全局变量初始化的相应会话变量。不影响目前已经连接的客户端的会话变量(即使客户端执行SET GLOBAL语句也不影响)。
例子全局变量:
要想设置一个GLOBAL变量的值,使用下面的语法:
mysql> SET GLOBAL sort_buffer_size=value;
或者
mysql> SET @@global.sort_buffer_size=value;
要想检索一个GLOBAL变量的值,使用下面的语法:
mysql> SELECT @@global.sort_buffer_size;
mysql> SHOW GLOBAL VARIABLES like 'sort_buffer_size';
查看全部系统变量指令:
SHOW GLOBAL VARIABLES
查看单个系统变量:
SHOW GLOBAL VARIABLES LIKE 'wait_timeout'
设置系统变量语法:
SET GLOBAL 变量名 = 变量值
如:SET GLOBAL wait_timeout = 604800;
注:如果修改变量值后没有生效,请退出从新再试下 。
4、获取系统变量值的语法
select @@wait_timeout from dual;
3、会话变量(系统变量):
1、只对连接的客户端有效。服务器为每个连接的客户端维护一系列会话变量。在连接时使用相应全局变量的当前值对客户端的会话变量进行初始化。对于动态会话变量,客户端可以通过SET SESSION var_name语句更改它们。
2、设置会话变量不需要特殊权限,但客户端只能更改自己的会话变量,而不能更改其它客户端的会话变量。
3、LOCAL是SESSION的同义词。如果设置变量时不指定GLOBAL、SESSION或者LOCAL,默认使用SESSION。
例子会话变量:
要想设置一个SESSION变量的值,使用下面的语法:
mysql> SET SESSION sort_buffer_size=value;
mysql> SET @@session.sort_buffer_size=value;
mysql> SET sort_buffer_size=value;
要想检索一个SESSION变量的值,使用下面的语法:
mysql> SELECT @@sort_buffer_size;
mysql> SELECT @@session.sort_buffer_size;
mysql> SHOW SESSION VARIABLES like 'sort_buffer_size';
当你用SELECT @@var_name搜索一个变量时(也就是说,不指定global.、session.或者local.),MySQL返回SESSION值(如果存在),否则返回GLOBAL值。
对于SHOW VARIABLES,如果不指定GLOBAL、SESSION或者LOCAL,MySQL返回SESSION值。
当设置GLOBAL变量需要GLOBAL关键字但检索时不需要它们的原因是防止将来出现问题。如果我们移除一个与某个GLOBAL变量具有相同名字的SESSION变量,具有SUPER权限的客户可能会意外地更改GLOBAL变量而不是它自己的连接的SESSION变量。如果我们添加一个与某个GLOBAL变量具有相同名字的SESSION变量,想更改GLOBAL变量的客户可能会发现只有自己的SESSION变量被更改了。
4、局部变量:
1、declare语句专门用于定义局部变量,在存储过程和函数中通过declare定义变量在BEGIN…END中,作用范围在begin到end语句块之间,并且可以通过重复定义多个变量。
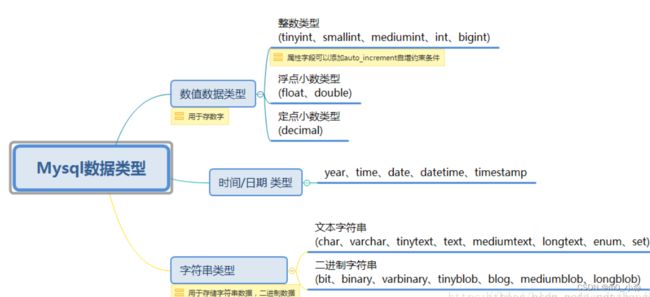
mysql数据类型