pandas基础:合并+数据清理
初始化两个DataFrame:
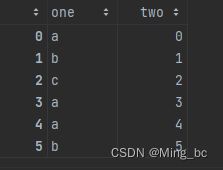
data1 = pd.DataFrame({'one':['a','b','c','a','a','b'],'two':range(6)})
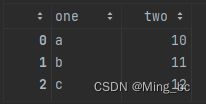
data2 = pd.DataFrame({'one':['a','b','c','d'],'two':range(10,14)})
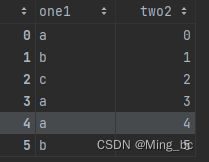
data3 = pd.DataFrame({'one1':['a','b','c','a','a','b'],'two2':range(6)})
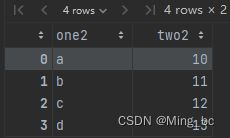
data4 = pd.DataFrame({'one2':['a','b','c','d'],'two2':range(10,14)})
data1:
data2:
data3:
data4:
pd.merge():纵向合并
合并的是全排列
当选择的列行数不同,会自动补齐,没有的用nan填充
# 有公共列的合并,参数:on指定合并的列,how指定合并的方法
pd.merge(data1,data2,on='one')
# 没有公共列,参数:right_on,lift_on:指定合并选择的列
pd.merge(data3,data4,right_on='one1',how='inner')
# 根据index进行合并,参数:right_index,left_index.
pd.merge(data3,data4,right_index=True,how='inner')
how的参数:
‘inner’:取交集
‘outer’:取并集
pd.concat():用于横向合并,也可以用作纵向合并
# 参数:ignore_index:忽略原来的索引
pd.concat([data1,data2,data3],axis=0)
pd.assign():增加一列
data1.assign(three=np.arange(10))
数据清理
data = pd.DataFrame({'k1':['one']*5,'k2':[1,1,2,3,3]})
data.duplicated()
作用:判断后面和前面的列是否有相同的
统计多少行是重复的:
(data.duplicated()).sum()
删除重复的行:
data.drop_duplicates()
删除某列中重复的值,只会保留列中重复的值的第一个值
data.drop_duplicates(‘k1’)
根据两列去重
data.drop_duplicates([‘k1’,‘k3’])
数值替换
data.k1.replace()
把a改成b:
data.k1.replace(a, b)
过滤缺失值:抛弃,填充
data.isnull()
data.notnull()
data[data.notnull()]
# 这一行只要有nan就会被删除,加上how='all'只有全是nan的时候才被删除,subset指定在那些列上查找
data.dropna()
# 列全为nan删除
data.dropna(axis=1,how='all')
# 填充nan
data.fillna(['aa':1,'bb':100])
字符串方法:
data.k1.str.replace('beijing','shanghai')
data.k1.str.contains('chushou')
data.k1.str[:]
# 字典映射
data.map(data1_dict)
bool取值
# 选择某行有一个值大于3的: 全>3的:all()
data[(data > 3).any(1)]
# >0 :1 <0:-1
np.sign(data)
连续数据离散化
# right:指定区间的右边是开还是闭,bins:表示分成多少区间
pd.cut(data.iloc[:,0],bins=[0,20,40,60,80],right=False)
# 区间等分
pd.cut(data.iloc[:,0], 4)
# 个数相同
pd.qcut(data.iloc[:,0], 4)
知识点:
1.要想在原地修改,可以先查看函数的参数里面是否有inplace参数,若没有就直接赋值回去。
2.apply会自动遍历每一个元素