《go编程技巧》----绕过map的坑
在工作中,map是我们经常使用的数据类型。但在map使用中会有很多的坑,下面总结。
1.1、不安全的map
go语言内建的map并发不安全的,当多个 Goroutine 操作同一个 map,会产生报错:fatal error: concurrent map writes。这个错误是无法使用recover进行捕获的。因为map找机会哦写
1.1.1、加锁保证map的并发安全
type Cache struct {
lock sync.Mutex
data map[int]int
}
func (c *Cache) Get(k int) int {
c.lock.Lock()
defer c.lock.Unlock()
return c.data[k]
}
func (c *Cache) put(k, v int) {
c.lock.Lock()
defer c.lock.Unlock()
c.data[k] = v
}
func main() {
const N = 100000
cache := Cache{
lock: sync.Mutex{},
data: map[int]int{},
}
for i := 0; i < N; i++ {
// 并发读写
go cache.put(i, i)
go func(i int) {
k := cache.Get(i)
fmt.Println(k)
}(i)
}
}1.1.2、sync.Map解决并发安全问题
package main
import (
"fmt"
"sync"
)
func main() {
var mm sync.Map
go func() {
for i := 0; i < 1000; i++ {
mm.Store(i, i)
}
}()
go func() {
for i := 0; i < 1000; i++ {
mm.Store(i, i)
}
}()
go func() {
for i := 0; i < 1000; i++ {
mm.Store(i, i)
}
}()
for i := 0; i < 1000; i++ {
val, _ := mm.Load(i)
fmt.Println("key:", i, " val:", val)
}
}1.2、map分片锁
无论 map+锁 还是sync.Map 都锁定整个map,锁粒度太大。我们可以使用分段锁来减小锁粒度,提高并发性。
分段锁:将数据分为一段一段的存储,然后给每一段数据配备一把锁。锁定其中一段数据,并不会影响其他段的数据。
demo1.2.1 分段锁
type ShardMap struct {
shard int // 分段数量
mu []sync.RWMutex // 锁列表, mu[i]的锁负责segment[i]的map,i为下标
segment []map[string]interface{} //map的切片,
}
func NewShardMap(shard int) *ShardMap {
mapSlice := make([]map[string]interface{}, shard)
for i := 0; i < len(mapSlice); i++ {
mapSlice[i] = map[string]interface{}{}
}
return &ShardMap{
shard: shard,
mu: make([]sync.RWMutex, shard),
segment: mapSlice,
}
}
func (s *ShardMap) getIndex(key string) int {
// 通过hash算法,选择存储在哪个map这之中
return int(fnv32(key) & uint32(s.shard-1))
}
func (s *ShardMap) Put(key string, val interface{}) {
index := s.getIndex(key)
s.mu[index].Lock()
s.segment[index][key] = val
s.mu[index].Unlock()
}
func (s *ShardMap) Get(key string) (val interface{}, exist bool) {
index := s.getIndex(key)
// 只会锁定下标为index的map
s.mu[index].RLock()
defer s.mu[index].RUnlock()
val, exist = s.Segment[index][key]
return val, exist
}
func fnv32(key string) uint32 {
hash := uint32(2166136261)
const prime32 = uint32(16777619)
for i := 0; i < len(key); i++ {
hash *= prime32
hash ^= uint32(key[i])
}
return hash
}引申:fnv算法
fnv算法:全名为 Fowler-Noll-Vo算法,它是使用位运算和乘法共同来计算hash值的。针对size较小的string 计算哈希值非常快。
| hash值的位数 |
初始值 |
成积 |
说明 |
| 32 |
2166136261 |
16777619 |
初始值、乘积都是固定值 |
| 64 |
14695981039346656037 |
1099511628211 |
初始值、乘积都是固定值 |
fnv64算法实现
func fnv64(key string) uint64 {
hash := uint64(14695981039346656037)
const prime64 = uint64(1099511628211)
for i := 0; i < len(key); i++ {
hash *= prime64
hash ^= uint64(key[i])
}
return hash
}1.3、浮点型做map的key
1.3.1、浮点数精度
请看下面一段代码,请问输出是什么?
demo1.3.1 浮点数精度
package main
import "fmt"
func main() {
c := make(map[float64]string)
k1 := 1.0
k2 := 1.001
k3 := 1.0000000000000001
c[k1] = "k1"
c[k2] = "k2"
c[k3] = "k3"
fmt.Println("c[k1]=", c[k1])
fmt.Println("c[k2]=", c[k2])
fmt.Println("c[k3]=", c[k3])
}输出为
c[k1]= k3 c[k2]= k2 c[k3]= k3
计算机无法准确的表达浮点型数字,只能通过约等、近似的方式,也就是说在某段很小的数据范围内浮点数,计算机会认为是相等的。 将本例中计算机 k1 := 1.0 和 k3 := 1.0000000000000001 认为是相同的数值。这也就是浮点数有精度的原因。超过精度范围,是无法准确表示的。
1.3.2、math.NaN做key
请看下面一段代码,请问输出是什么?
demo1.3.2 math.NaN
import (
"fmt"
"math"
)
func main() {
a := map[float64]int{}
a[math.NaN()] = 1
a[math.NaN()] = 2
fmt.Println("a[math.NaN() = ", a[math.NaN()])
for k, v := range a {
fmt.Println("key:", k, "val:", v)
}
}输出
a[math.NaN()] = 0 key: NaN val: 1 key: NaN val: 2
为什么通过math.NaN()直接获取值为零值呢?为什么不会覆盖?
- math.NaN() 类型是 float64。每次对它计算 hash,得到的结果都不一样,也就是说计算它的哈希值和它当初插入 map 时的计算出来的哈希值不一样,这样就没法准确的定位它属于哪个桶。那就会出现一些后果:这个 key 不会被
m[math.NaN()]操作获取的,是查不出来结果的,只能回去数据类型的零值。 - 因为对math.NaN() 计算hash值不同,所以math.NaN() 计算出来的桶很大可能是不一样的,所以不会出现覆盖情况
1.4、map造成的内存泄漏
在go应用,一般会由slice、协程、Ticker、channal等造成内存泄漏。往往会忽略map造成内存泄漏的情况。使用map实现本地缓存时可能会造成内存泄漏。
demo 1.4.1
在map中,先添加100000个值。
- 删除所有的值,验证删除之后内存是否释放
- gc之后,验证内存是否释放
- 2分钟之后,再次GC,验证内存是否释放
package main
import (
"fmt"
"runtime"
"time"
)
func main() {
// 统计内存
var mem runtime.MemStats
// 初始化map,并添加100000个值
cache := map[int]int{}
for i := 0; i < 100000; i++ {
cache[i] = i
}
// 获取当前内存
runtime.ReadMemStats(&mem)
fmt.Printf("初始化之后内存为:%d KB\n", mem.Alloc>>10)
// 删除所有的数值
for i := 0; i < 100000; i++ {
delete(cache, i)
}
// 获取当前内存
runtime.ReadMemStats(&mem)
fmt.Printf("删除所有key之后内存:%d KB\n", mem.Alloc>>10)
// 手动触发GC,并获取当前内存值
runtime.GC()
runtime.ReadMemStats(&mem)
fmt.Printf("GC之后内存为:%d KB\n", mem.Alloc>>10)
time.Sleep(2 * time.Minute)
runtime.GC()
runtime.ReadMemStats(&mem)
fmt.Printf("2分钟GC之后内存:%d KB\n", mem.Alloc>>10)
cache[1] = 1
}
运行结果
初始化之后内存为: 4248 KB 删除所有key之后内存:4249 KB GC之后内存为:2786 KB 2分钟GC之后内存:2786 KB
1.map删除key&val之后为何内存不会减少?
map中通过delete 删除key,只是将bucket中对应位置上的值设置成empty而不清空内存。所有桶内存不会释放。所以删除key不会减少内存
2.GC之后内存减少,但没有达到预期。为什么?
go源码中,map桶的个数是由B决定的(map中共2^B个桶)。在map扩容流程中,B的数值只会增加或者保持不变,不会减少。如果短时间map中存入大量的数据,触发map的扩容,B一定会增加。桶数组就会增加,并且不会再减小,桶内存也不会被释放
解决方案
- 创建新的map替换老map,将老map的数据复制到新map之中。此选项的主要缺点是:在复制之后直到下一次垃圾回收之前,这段时间新老map都会存在,消耗内存会增加。
- 清空map 不要使用delete, 而是创建新的map
不推荐做法:有些网上文档,建议将map的val 改为指针类型。因为指针类型比较小。在64 位系统中指针类型消耗的内存为 8 字节,32 位系统为 4 字节。即使桶数量增加,内存消耗也不会太大。详见【1.5、影响map性能的幽灵:GC】
1.5、影响map性能的幽灵:GC
先说结论:不要在大map中保存指针 !!!
下面探究一下这个问题。以下有两段相同功能的代码,MapWithPointer 使用int指针作为map的value;MapWithoutPointer 使用int作为map的value。
demo:1.5.1
func MapWithPointer() {
const NUM = 10000000
val := 0
m := make(map[int]*int) // val为int的指针
for i := 0; i < NUM; i++ {
m[i] = &val
}
now := time.Now()
runtime.GC() // 手动触发gc
fmt.Printf("With a map of pointer of int, GC took: %s\n", time.Since(now))
fmt.Println(*m[0])
fmt.Println(*m[N-1])
}
func MapWithoutPointer() {
const NUM = 10000000
m := make(map[int]int) // val为int
val := 0
for i := 0; i < NUM; i++ {
m[i] = val
}
now := time.Now()
runtime.GC() // 手动触发gc
fmt.Printf("With a map of int, GC took: %s\n", time.Since(now))
fmt.Println(m[0])
fmt.Println(m[N-1])
}验证方法一:统计GC时间
func Test_MapWithPointer(t *testing.T) {
MapWithPointer()
}
func Test_MapWithoutPointer(t *testing.T) {
MapWithoutPointer()
}运行结果如下

统计GC执行时间可以看出:
- 带指针的map : GC消耗时间 136.347863ms
- 不带指针的map: GC消耗时间 3.069063ms
验证方法二:gctrace
执行 GODEBUG='gctrace=1' go run main.go
package main
import (
"fmt"
"runtime"
"time"
)
func main() {
// 验证调用带有指针的函数时,取消注释
MapWithPointer()
// 验证不带指针的函数时,取消注释
// MapWithoutPointer()
}
func MapWithPointer() {
const N = 10000000
val := 0
m := make(map[int]*int) // val为int的指针
for i := 0; i < N; i++ {
m[i] = &val
}
now := time.Now()
runtime.GC()
fmt.Printf("With a map of pointer of int, GC took: %s\n", time.Since(now))
fmt.Println(*m[0])
fmt.Println(*m[N-1])
}
func MapWithoutPointer() {
const N = 10000000
m := make(map[int]int) // val为int
val := 0
for i := 0; i < N; i++ {
m[i] = val
}
now := time.Now()
runtime.GC()
fmt.Printf("With a map of int, GC took: %s\n", time.Since(now))
fmt.Println(m[0])
fmt.Println(m[N-1])
}带有指针的map 运行结果如下:

不带指针的map 运行结果如下:

从gctrace运行结果可以看出:
- 带有指针的map gc时间占总运行时间5%以上
- 不带指针的map gc时间占总运行时间的2%以下
原因分析
都是指针惹的祸
通过以上两种不同的方法,我们可以看 出带指针的map比不带指针的map GC开销要大的多。那是什么原因造成的呢?
我们先回忆一下GC的“三色标记法”:
- 首先创建三个集合:白、灰、黑,所有对象默认放入白色集合中。
- 然后从根节点开始遍历所有对象,把遍历到的对象从白色集合取出,放入灰色集合。
- 之后遍历灰色集合,将灰色对象引用的对象从白色集合取出 放入灰色集合,之后将此灰色对象放入黑色集合,直至灰色集合没有对象为止。那么白色集合内的对象即为“垃圾”。
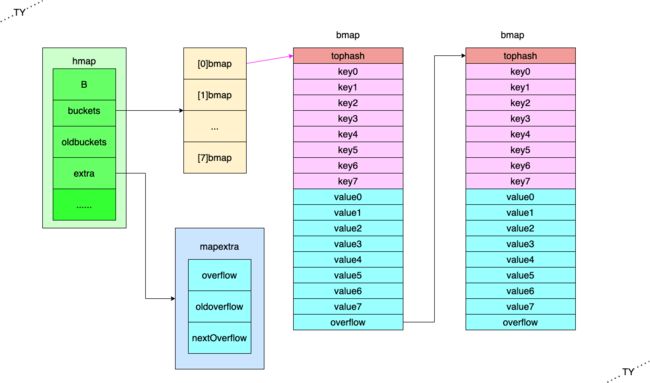
这里有个关键词“引用”,本质上就是指针。Go 语言中map是通过链表法解决哈希冲突,每个 bucket (数据类型bmap) 中都有一个bmap类型的指针overflow。如图所示:
因为 overflow 指针的缘故,所以无论 map 保存的是什么,GC 的时候就会把所有的 bmap 扫描一遍,带来巨大的 GC 开销,go1.4以及以前版本确实是这样的。
go官方优化
如果map的key和value没有指针,那么这样的map是不会产生“垃圾”的。针对key和value没有指针的map是没有必要扫描bmap的。go官方对此场景的map进行讨论(详见官方issue:runtime: Large maps cause significant GC pauses #9477) ,并在go 1.5进行了优化(3288: runtime: do not scan maps when k/v do not contain pointers )
After go version 1.5, if you use a map without pointers in keys and values, the GC will omit its content.
go源码怎么实现的优化呢?
TODO
解决方案
(1)尽量避免使用指针
在map的key & val 中尽量不要使用指针。例如demo:1.5.1 中使用 MapWithoutPointer代替MapWithPointer
除了用户定义的指针类型外,go语言存在指针类型的数据结构:string、slice、字段含指针的struct等 。指针类型的数据结构做map的k/v也会引起扫描所有的bmap,造成gc时间过长。
针对指针类型的数据结构,go语言gc是不可避免。但可以通过某些策略进行优化,减少gc扫描的数量。
(2) byte切片+key索引
string作为map的key情况下,可以通过byte