彻底掌握Java CAS自旋锁原理 汇编底层源码
cas典型使用场景
如果多个处理器同时对共享变量进行读改写(i++就是经典的读改写操作)操作,那么共享变量就会被多个处理器同时进行操作,这样读改写操作就不是原子的,操作完之后共享变量的值会和期望的不一致,举个例子:如果i=0,我们进行两次i++操作,我们期望的结果是2,但是有可能结果是1。如下图

原因是有可能多个处理器同时从各自的缓存中读取变量i,分别进行+1操作,然后分别写入系统内存当中。那么想要保证读改写共享变量的操作是原子的,就必须保证CPU1读改写共享变量的时候,CPU2不能操作缓存了该共享变量内存地址的缓存。
我们有很多种解决方法,比如用原子类解决:
// jdk5 之后的原子类
AtomicInteger atomicInteger = new AtomicInteger();
atomicInteger.incrementAndGet();
AtomicInteger.incrementAndGet其中就用到了cas算法。
cas算法基本流程就是1,获取旧的值 2,计算 3 写入值之前拿旧的值与最新的值比较,若相等说明未被他他线程改变,可以执行写入操作。否则循环进行以上操作。看完流程图后,我们一步步查看源码。
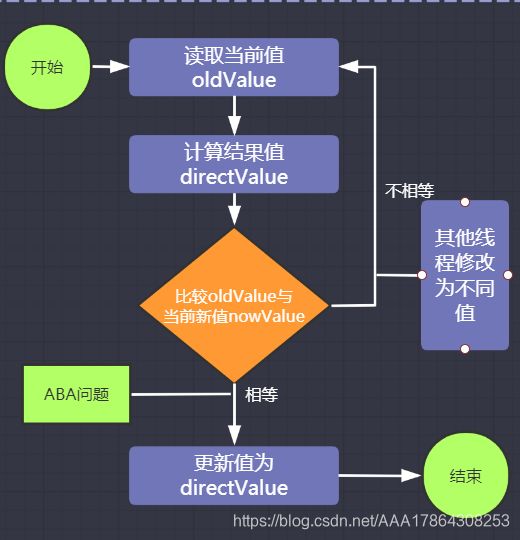
为了便于理解cas,我们场景进行场景模拟
两个线程(cpu1,cpu2)分别执行atomicInteger.incrementAndGet()
场景A cpu1执行过程中,内存中的值未被其他cpu2线程修改
cpu1读取内存当前值 :oldValue = 0
cpu1计算:directValue = 0+1=1
cpu1读取内存当前值 :nowValue=0(内存中的值未被其他线程修改)
因为oldValue =nowValue所以cpu1将内存中的值更新为directValue
场景B cpu1执行过程中,内存中的值被cpu2线程修改
cpu1读取内存当前值 :oldValue = 0
cpu1计算:directValue = 0+1=1
cpu1读取内存当前值 :nowValue=1(内存中的值已经被cpu2修改为1)
因为oldValue 不等于nowValue所以cpu1进行自旋操作 cpu1重新读取内存当前值 :oldValue = 1
cpu1计算:directValue = 1+1=2
cpu1读取内存当前值 :nowValue=1(cpu2执行结束,内存中的值未被其他线程修改)
因为oldValue =nowValue所以cpu1将内存中的值更新为directValue(2) 因次最终,值为正确的值2
场景C 同时进行内存写入
假设time1=time2代表同一时刻。
cpu1读取内存当前值 :oldValue = 0
cpu1计算:directValue = 0+1=1
cpu1读取内存当前值 :nowValue=0(内存中的值未被其他线程修改)
在time1时刻,因为oldValue =nowValue所以cpu1将内存中的值更新为directValue
cpu2读取内存当前值 :oldValue = 0
cpu2计算:directValue = 0+1=1
cpu2读取内存当前值 :nowValue=0(内存中的值未被其他线程修改)
time2时刻因为oldValue =nowValue所以cpu2将内存中的值更新为directValue
即两个线程同一时刻进行内存写入。这时候cas是怎么保证结果正确呢?下文会做出解释。
其他场景:ABA 问题
ABA问题大概理解你的女朋友在离开你的这段儿时间经历了别的人,自旋就是你空转等待,一直等到她接纳你为止。
有这么一种场景:oldValue=0,nowValue被cpu2改为1,又被cpu2或其他线程改成了0。虽然oldValue=nowValue=0,但是这个0已经不是之前的0了,但是cpu1无感知,于是进行写入操作。
并不是这种场景一定会给程序结果带来影响。若有影响解决办法是添加版本号(AtomicStampedReference)。
大家应该比较清晰了,接下来我们进行源码讲解
第一步 查看java代码AtomicInteger类的incrementAndGet()方法。
public final int incrementAndGet() {
for (;;) {
int current = get();
int next = current + 1;
if (compareAndSet(current, next))
return next;
}
}
public final boolean compareAndSet(int expect, int update) {
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
}
第二步 java代码incrementAndGet调用了unsafe类的compareAndSwapInt方法
Unsafe类是rt.jar包中的类,它提供了原子级别的操作,它的方法都是native方法,通过JNI访问本地的C++库。
public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5);
第三步 查看native compareAndSwapInt方法
native方法的具体实现是用C语言实现的,因为jdk就是用C语言编写的。当有一些需要和硬件打交道的方法,java是做不了的,于是它就偷懒声明一个native方法让c去写一个方法去和硬件打交道,c写好之后java直接调用即可。
native 方法无法从jdk中看只能查看jvm
jvm是一个标准,它的实现有很多
- 开源:Openjdk
- Sun:Hotspot
- IBM:OpenJ9
- 阿里巴巴:Alibaba JVM
- more
依照现在的授权,JVM的源码可以放在OpenJDK里提供。
这里我给出了OpenJDK源码下载链接
链接:https://pan.baidu.com/s/1ENcBozn3HEVvZ1f1xlwhDw
提取码:ye04
下载解压即可
unsafe.cpp所在目录为:
openjdk/hotspot/src/share/vm/prims/unsafe.cpp
UNSAFE_ENTRY(jboolean, Unsafe_CompareAndSwapInt(JNIEnv *env, jobject unsafe, jobject obj, jlong offset, jint e, jint x))
UnsafeWrapper("Unsafe_CompareAndSwapInt");
oop p = JNIHandles::resolve(obj);
jint* addr = (jint *) index_oop_from_field_offset_long(p, offset);
return (jint)(Atomic::cmpxchg(x, addr, e)) == e;
UNSAFE_END
可以看出返回的是(jint)(Atomic::cmpxchg(x, addr, e)) 跳转第四步
第四步 查看Atomic::cmpxchg(x, addr, e)方法
此方法在atomic_linux_x86.inline.hpp的第93行
atomic_linux_x86.inline.hpp的目录为:
openjdk/hotspot/src/os_cpu/linux_x86/vm/atomic_linux_x86.inline.hpp
inline jint Atomic::cmpxchg (jint exchange_value, volatile jint* dest, jint compare_value) {
int mp = os::is_MP();
__asm__ volatile (LOCK_IF_MP(%4) "cmpxchgl %1,(%3)"
: "=a" (exchange_value)
: "r" (exchange_value), "a" (compare_value), "r" (dest), "r" (mp)
: "cc", "memory");
return exchange_value;
}
inline内联方法,解决一些频繁调用的函数大量消耗栈空间(栈内存)的问题
is_MP代表是否多核处理器,源码请跳转第五步
实现为
__asm__ volatile ( C语言内嵌汇编)
LOCK_IF_MP(汇编指令:如果多个cpu则进行锁定,源码请跳转第六
cmpxchgl (汇编指令:compile and exchange硬件直接支持)
第五步 查看is_MP()方法
is_MP()方法在 os.hpp中
os.hpp的目录为:
openjdk/hotspot/src/share/vm/runtime/os.hpp
static inline bool is_MP() {
// During bootstrap if _processor_count is not yet initialized
// we claim to be MP as that is safest. If any platform has a
// stub generator that might be triggered in this phase and for
// which being declared MP when in fact not, is a problem - then
// the bootstrap routine for the stub generator needs to check
// the processor count directly and leave the bootstrap routine
// in place until called after initialization has ocurred.
return (_processor_count != 1) || AssumeMP;
}
第六步 查看LOCK_IF_MP方法
LOCK_IF_MP()方法在atomic_linux_x86.inline.hpp
atomic_linux_x86.inline.hpp目录为:
openjdk/hotspot/src/os_cpu/linux_x86/vm/atomic_linux_x86.inline.hpp
#define LOCK_IF_MP(mp) "cmp $0, " #mp "; je 1f; lock; 1: "
综上,它的最终实现为一条指定
lock cmpxchg
cmpxchg 不具有原子性,lock指令在执行后面指令的时候锁定一个北桥电信号,当执行cmpxchg 其他cpu不允许做修改,所以lock cmpxchg具有原子性。
所以cas还是会上锁,不过锁定北桥信号(不采用锁总线的方式)比锁定总线轻量,这就很好的解释了场景C同时写入问题。
下一期文章
synchronized与volatile的硬件级实现
如果觉得写的可以的话,能不能扫码关注公众号“云计算平台技术”呢?