MySQL索引与事务
索引
概念
索引是一种特殊的文件,包含着对数据表里所有记录的引用指针.可以对表中一列或多列创建索引并指定索引的类型,各类索引有各自的数据结构的实现.
作用
数据库中的表,数据,索引之间的关系,类似于书架上的图书,书籍内容和书籍目录之间的关系.
索引所起的作用类似于书籍目录,可以用于定位,检索数据.
索引对于提高数据库性能有很大的帮助.
特点
(1)加快查询速度
(2)索引自身是一定的数据结构,也需要占据内存
(3)当需要进行新增,删除,修改时需要先根据条件查找(速度快),也需要针对索引进行更新(速度慢)
(4)索引不是越多越好,索引过多会影响到插入性能,建立索引可使检索操作更加迅速
数据结构
数据库的索引,使用了B+树作为数据结构.
B+树的前身:B树(N叉搜索树),就是二叉搜索树的扩展.如图所示形如这样的树为B树:
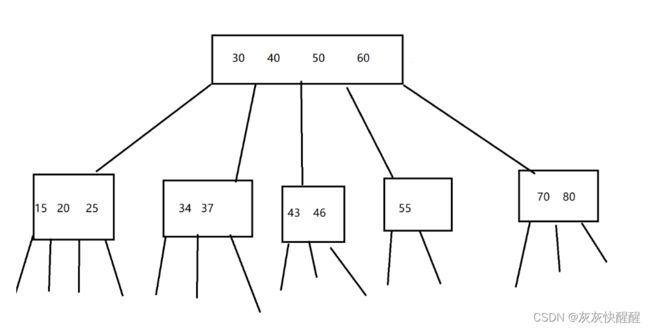
N个结点可以划分为N+1个区间.
用同样高度的树,能表示的元素相比于二叉搜索树来说,多了很多.使用B树查询时,比较次数比搜索树多了很多.
B+树是在B树的基础上进行的改进:同样是N叉搜索树,每个节点有多个key,N个key能分出N个空间
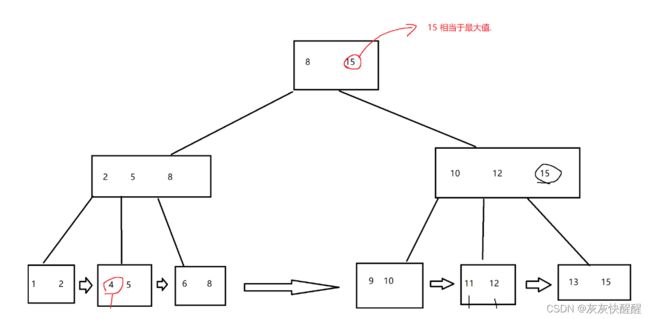
B+树的特点:
(1)N叉搜索树,每个节点有N个key,N个key划分出N个区间
(2)每个结点的N个key中,会存在最大值(如图所示,最右端的15就是第一层的最大值)
(3)每个结点的key,会在子树中重复出现,即所有数据都包含在叶子结点
(4)叶子节点之间,用链式结构进行相连,使查询时间很稳定.
使用场景
要考虑对数据库表的某列或某几列创建索引,需要考虑以下几点:
1.数据量较大,且经常对这些列进行条件查询
2.该数据库表的插入操作,及对这些列的修改操作的频率较低
3.索引会占用额外的磁盘空间.
4.不是所有的查询都需要索引,eg.小表:数据量较小时,使用全表扫描可能更为高效
满足以上条件时,考虑对表中的这些字段创建索引,以提高查询效率.
反之,如果非条件查询列,或经常做插入,修改操作,或者磁盘空间不足时,不考虑创建索引
使用
创建主键约束(primary key),唯一约束(unique), 外键约束(foreign key)时,会自动创建对应列的索引.
查看索引
show index from 表名;
注:一个表的索引可以有多个,eg.字典可以有多个目录,按照不同的目录方法查每个索引,都是根据某个具体的列来展开的->后续按照这个列进行查询,才能提高查询效率.
创建索引
对于非主键,非唯一约束,非外键的字段,可以创建普通索引.
create index 索引名 on 表名(字段名); -- 针对哪个表,哪个列.
注:也是一个比较危险的操作,就比如说表本身有很多数据,此时创建索引操作,就会引发大量的硬盘IO(就有可能将数据库给搞挂了)
删除索引
drop index 索引名 on 表名;
注:也是危险操作
因此,我们说在创建索引时,一定要在建表之初就规划好索引的设定.
但是表中已经有很多数据了,需要给一个列加索引该咋办?
另外搞一台机器,搭建数据库,把生产环境上的数据库表创建好,并加上索引.再将生产环境中的数据库导入新的数据库中(耗时但不影响),用新的数据库的这个机器,替代旧机器(一瞬间)
事务
为什么要使用事务?
原因:很多时候,进行的多个操作,期望"打包"到一起,共同执行.要么执行成功,要么都不执行.
其实是执行了,只不过在恢复数据库时将数据也还原了.
举例如下:
准备测试表:
drop table if exists accout;create table accout(id int primary key auto_increment,name varchar ( 20 ) comment ' 账户名称 ' ,money decimal ( 11 , 2 ) comment ' 金额 ');insert into accout(name, money) values( ' 阿里巴巴 ' , 5000 ),( ' 四十大盗 ' , 1000 );
-- 阿里巴巴账户减少 2000update accout set money=money- 2000 where name = ' 阿里巴巴 ' ;-- 四十大盗账户增加 2000update accout set money=money+ 2000 where name = ' 四十大盗 ' ;
事务的概念
事务指逻辑上的一组操作,组成这组操作的各个单元,要么全部成功,要么全部失败.
在不同的环境中,都可以有事务.对应在数据库中,就是数据库事务.
事务日志的概念
事务日志是数据库管理系统中的一个关键组件,用于记录数据库中发生的所有事务操作,事务日志的主要目的是为了提供数据恢复和持久性.
使用
1.开启事务:start transaction;
2.执行多条SQL语句
3.回滚或提交:rollback/commit;
(1)rollback:告诉服务器,要进行回滚.把开启事务之后,后续执行的sql恢复回去.一般不在控制台,在java代码里,代码开启事务,执行sql.某sql抛出异常,用catch进行捕获,并使用rollback.
数据库对于事务这里有特殊机制(undo log + rodo log):通过日志,写到文件夹里.记录之前的数据以及进行的操作.(如果数据库中间挂了,但日志记下来了,等到数据库重启后,读取之前的日志.看看是否有执行一半的事务,如果有就回滚).
(2)告诉服务器,事务完毕.
说明:rollback即是全部失败,commit即是全部成功.
start transaction;-- 阿里巴巴账户减少 2000update accout set money=money- 2000 where name = ' 阿里巴巴 ' ;-- 四十大盗账户增加 2000update accout set money=money+ 2000 where name = ' 四十大盗 ' ;commit;
核心特性
1.原子性:通过事务,把多个操作,打包在一起.
2.一致性:相当于原子性的延伸,当数据库出现问题了,不会产生问题.另一方面,通过约束,避免数据出现非法的情况.
3.持久性:事务的任何修改,都是持久化的存在(写入硬盘的),无论是重启程序,还是重启主机,修改都是不会消失的.
4.隔离性:多个事务并发执行时,可能会带来一些问题.通过隔离性对该问题进行权衡,看是希望数据尽量准确,还是尽量快.
有关并发的介绍:
并发:因为数据库是客户端-服务器结构的程序,一个服务器,可能会同时涉及到多个客户端.
如果有多个客户端,同时给服务器发起事务请求呢,这时叫:"并发执行事务"~~
1.如果多个事务,修改的是不同的表,问题不大.
2.如果是修改相同的表,就会产生bug.
bug的类型
bug1:脏读问题:现在有两个事务1,2
事务1:修改了某个数据,但是事务还未"提交"(提交就是告诉服务器,over)
事务2:读取了同一数据,此时事务2读到的数据,很有可能就是一个脏的数据,因为事务1以后还有可能会修改这个数据
解决脏读问题的核心思路:降低事务的并发程度,写程序加锁,加锁就意味着释放锁之前是不可访问的
bug2:不可重复读:比较像脏读,但是这是在加锁的条件下,虽然写加锁了,但是可以分多个事务,进行多次提交的方式来修改(更换了一种修改的方式):这种修改数据的方式虽然没有那么频繁,也是可能会出现的.
比如有事务1,2.其中事务1先修改数据(加了锁).事务2想读,就得等事务1提交后,事务2开始读数据(可能有多次).又来了一个事务3,事务3修改了上述数据,导致事务2读的两次结果不同.因为没有说读的时候不能写.
bug3:幻读问题:事务1修改数据,事务2开始读数据,此时事务3新增了一个其它的数据.那么事务2就会出现两次读的结果不同的情况.
解决:串行化.即不再进行任何并发,每个事务是串行执行的(执行第1个,然后是2,3个).