java集合类(6)Vector
这篇文章开始介绍Vector。他和ArrayList有一些相似,其内部都是通过一个容量能够动态增长的数组来实现的。不同点是Vector是线程安全的。因为其内部有很多同步代码快来保证线程安全。为此,这篇文章,也会通过从源码的角度来分析一下Vector,并和ArrayList等其他集合容器进行一个对比分析。
OK,开始今天的文章。
一、认识Vector
Vector可以实现可增长的对象数组。与数组一样,它包含可以使用整数索引进行访问的组件。不过,Vector的大小是可以增加或者减小的,以便适应创建Vector后进行添加或者删除操作。
为此我们先看一下Vector在整个java集合体系中的位置

从上面这张图我们也会发现Vector和ArrayList是出于一个等级上面的,继承关系也和ArrayList一样。不过从宏观上只能看到在整个体系中的位置,现在我们从Vector来看看他的继承关系。
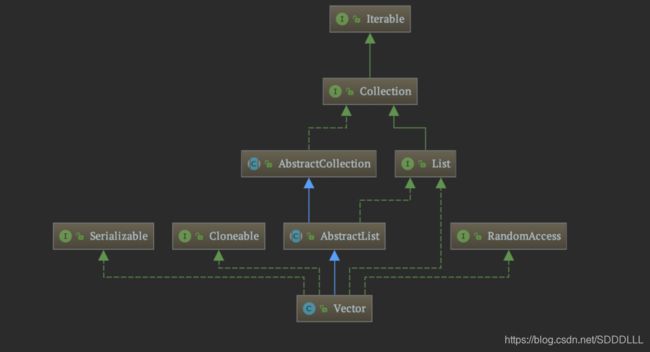
现在我们就根据这张图来进行一个分析,Vector继承于AbstractList,实现了List、RandomAccess、Cloneable、 Serializable等接口。
(1)Vector 继承了AbstractList,实现了List接口。
(2)Vector实现了RandmoAccess接口,即提供了随机访问功能。
(3)Vector 实现了Cloneable接口,即实现克隆功能。
(4)Vector 实现Serializable接口,表示支持序列化。
Vector实现的这些接口,表示会有这样的能力。但是还有一点,就是Vector是线程安全的。下面我们从源码的角度来分析一下Vector是如何实现这些接口和保持线程安全的特性的。
二、源码分析Vector
(1)构造方法
Vector的构造方法一共有四个,因为四个都比较重要,所以在这里就给出四个
第一个: 创建一个空的Vector,并且指定了Vector的初始容量为10
public Vector() {
this(10);
}
第二个:创建一个空的Vector,并且指定了Vector的初始容量
public Vector(int initialCapacity) {
this(initialCapacity, 0);
}
第三个:创建一个空的Vector,并且指定了Vector的初始容量和扩容时的增长系数
//initialCapacity:初始容量
//capacityIncrement:扩容时的增长系数
public Vector(int initialCapacity, int capacityIncrement) {
super();
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+ initialCapacity);
//这句话表明,其底层就是通过数组来建立的
this.elementData = new Object[initialCapacity];
this.capacityIncrement = capacityIncrement;
}
第四个:根据其他集合来创建一个非空的Vector
public Vector(Collection<? extends E> c) {
elementData = c.toArray();
elementCount = elementData.length;
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, elementCount, Object[].class);
}
第四个需要解释一下,首先是把其他集合转化为数组,然后复制粘贴到Vector里面。
(2)增加元素
增加元素有两个主要的方法,第一个是在Vector尾部追加,第二个是在指定位置插入元素。
第一个:在Vector尾部追加元素
public synchronized boolean add(E e) {
modCount++;
//判断容量大小:若能装下就直接放进来,装不下那就扩容
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = e;
return true;
}
我们再进来看一下ensureCapacityHelper(elementCount + 1)是如何实现的。
private void ensureCapacityHelper(int minCapacity) {
//追加一个元素后,当前的容量是minCapacity
// 若minCapacity > elementData原始的容量,则要按照minCapacity进行扩容
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
现在相当于真正扩容的方法是grow方法,别着急我们再进来看看。
private void grow(int minCapacity) {
//第一步:获取elementData的原始容量
int oldCapacity = elementData.length;
//第二步:apacityIncrement:表示需要新增加的数量,如果大于0,那就扩充这么多,如果不大于0,那就翻倍
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
//第三步:若进行扩容后,capacity仍然小,则新容量改为实际需要minCapacity的大小
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
//第四步:如果新数组的长度比虚拟机能够提供给数组的最大存储空间大,
// 则将新数组长度更改为最大正数:Integer.MAX_VALUE
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
//第五步:按照新的容量newCapacity创建一个新数组,然后再将原数组中的内容copy到新数组中
elementData = Arrays.copyOf(elementData, newCapacity);
}
在这一步我们扩容的时候首先就要排除一些异常的情况,首先就是capacityIncrement(需要增加的数量)是否大于0,如果大于0直接增加这么多。然后发现增加了上面那些还不够那就扩充为实际需要minCapacity的大小。最后发现还不够,就只能扩充到虚拟机能表示的数字最大值了。
第二个:在指定位置增加元素
这个就比较简单了。我们直接看源码就能看明白
public void add(int index, E element) {
insertElementAt(element, index);
}
public synchronized void insertElementAt(E obj, int index) {
//第一步:fail-fast机制
modCount++;
//第二步:判断index下标的合法性
if (index > elementCount) {
throw new ArrayIndexOutOfBoundsException(index+ " > " + elementCount);
}
//第三步:判断容量大小
ensureCapacityHelper(elementCount + 1);
//第四步:数组拷贝,将index到末尾的元素拷贝到index + 1到末尾的位置,将index的位置留出来
System.arraycopy(elementData, index, elementData, index + 1, elementCount - index);
elementData[index] = obj;
elementCount++;
}
(3)删除元素
删除元素时候同样也有两种方法,第一个根据元素值来删除,第二个根据下表来删除元素。
第一个:根据元素值来删除元素
public boolean remove(Object o) {
return removeElement(o);
}
我们发现删除元素其实是调用了removeElement()方法来删除元素的,没关系不要嫌麻烦,进入这个方法内部看一下。
public synchronized boolean removeElement(Object obj) {
//第一步:fail-fast机制
modCount++;
//第二步:查找元素obj在数组中的下标
int i = indexOf(obj);
//第三步:若下标不小于0:说明Vector容器中含有这个元素
if (i >= 0) {
//第四步:调用removeElementAt(int)方法删除元素
removeElementAt(i);
return true;
}
return false;
}
到了这一步,我们又发现,执行删除操作的还不是removeElement()方法,而是removeElementAt(i),我们再进入这个方法看看。
public synchronized void removeElementAt(int index) {
//第一步:fail-fast机制
modCount++;
//第二步:index下标合法性检验
if (index >= elementCount) {
throw new ArrayIndexOutOfBoundsException(index + " >= " +elementCount);
}
else if (index < 0) {
throw new ArrayIndexOutOfBoundsException(index);
}
//第三步:要移动的元素个数
int j = elementCount - index - 1;
if (j > 0) {
//第四步:将index之后的元素向前移动一位
System.arraycopy(elementData, index + 1, elementData, index, j);
}
elementCount--;
elementData[elementCount] = null;
}
到了这个方法我们其实可以分析一下,要删除元素要移动大量的元素,时间效率肯定是不好的。毕竟Vector是通过数组来实现的,而不是通过链表。
第二个:删除指定位置的元素
删除指定位置的元素就比较简单了,我们到指定的位置进行删除就好了,但是同样需要把后面的元素进行移位。
public synchronized E remove(int index) {
//第一步:fail-fast机制
modCount++;
//第二步:index下标合法性检验
if (index >= elementCount)
throw new ArrayIndexOutOfBoundsException(index);
//获取旧的元素值
E oldValue = elementData(index);
//第三步:计算需要移动的元素个数
int numMoved = elementCount - index - 1;
//第四步:将元素向前移动
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index, numMoved);
elementData[--elementCount] = null;
return oldValue;
}
(3)更改元素
更改元素我们就先看一个吧。这个在大部分场景下一般不用(大部分,根据自己业务来定)。
public synchronized void setElementAt(E obj, int index) {
if (index >= elementCount) {
throw new ArrayIndexOutOfBoundsException(index + " >= " + elementCount);
}
elementData[index] = obj;
}
(4)查找元素
查找元素我们给出三个,第一个查询Vector容器中是否包含某个元素,第二个查询第一次出现的指定元素的索引,第三个最后一次出现的指定元素的索引。
第一个:查询Vector容器中是否包含某个元素
public boolean contains(Object o) {
return indexOf(o, 0) >= 0;
}
我们发现,查询Vector是否包含某个元素时候,其实是调用了第二个方法,那我们直接就看第二个
第二个:查询第一次出现的指定元素的索引
public synchronized int indexOf(Object o, int index) {
//分为null和不为null
if (o == null) {
//从index处一个一个搜索
for (int i = index ; i < elementCount ; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = index ; i < elementCount ; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
第三个:查询最后一次出现的指定元素的索引
public synchronized int lastIndexOf(Object o, int index) {
if (index >= elementCount)
throw new IndexOutOfBoundsException(index + " >= "+ elementCount);
if (o == null) {
//从index处正向搜索,默认从索引为elementCount-1处开始
for (int i = index; i >= 0; i--)
if (elementData[i]==null)
return i;
} else {
for (int i = index; i >= 0; i--)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
小结:
1)线程安全:
从上面的构造方法还有增删改查的操作其实我们都发现了,都有这么一个synchronized关键字,就是这个关键字为Vector容器提供了一个安全机制,保证了线程安全。
2)构造方法:
Vector实际上是通过一个数组去保存数据的。当我们构造Vecotr时;使用默认构造函数,默认容量大小是10。
3)增加元素:
当Vector容量不足以容纳全部元素时,Vector的容量会增加。若容量增加系数 大于0,则将容量的值增加“容量增加系数”;否则,将容量大小增加一倍。
4)克隆:
Vector的克隆函数,即是将全部元素克隆到一个数组中。
(5)遍历
不过到这可还没结束,还有重要的一点我们还没说,那就是遍历。其实在我之前的文章介绍ArrayList时候已经提到过了,遍历方式也就那么几种,既然Vector是基于数组实现的,那么遍历方式肯定也是随机访问最快。在这里代码演示几个:
//第一种
for (String string : t) {
System.err.print(string);
}
//第二种
t.forEach(new Consumer<String>() {
@Override
public void accept(String t) {
System.out.print(t);
}
});
//第三种:效率最高
for (int i = 0; i < t.size(); i++) {
System.out.print(t.get(i));
}
//第四种
Iterator<String> it = t.iterator();
while (it.hasNext()) {
String string = (String) it.next();
System.err.print(string);
}
//第五种
Enumeration<String> enume = t.elements();
while(enume.hasMoreElements()){
System.out.print(enume.nextElement().toString());
}
三、Vector与其他容器的区别
源码看完了,对于Vector的实现,我相信你也基本上明白其内部实现了,下面就看看他和别的容器的区别,在文章一开始我们就提到了Vector其实基本上和ArrayList一样的,下面对比分下一下:
ArrayList是线程非安全的,这很明显,因为ArrayList中所有的方法都不是同步的,在并发下一定会出现线程安全问题。另一个方法就是Vector,它是ArrayList的线程安全版本,其实现90%和ArrayList都完全一样,区别在于:
1、Vector是线程安全的,ArrayList是线程非安全的
2、Vector可以指定增长因子,如果该增长因子指定了,那么扩容的时候会每次新的数组大小会在原数组的大小基础上加上增长因子;如果不指定增长因子,那么就给原数组大小*2,源代码是这样的:
int newCapacity = oldCapacity + ((capacityIncrement > 0) ? capacityIncrement : oldCapacity);
OK,今天的文章就分享到这里,如有问题还请批评指正。
欢迎关注微信公众号:java的架构师技术栈,回复关键字可获取计算机系列各种教程资源。包含java基础、java进阶、java工具、java框架、java架构师、python、android、微信小程序、数据库、前端、神经网络、机器学习等等各个方面的教程资源。
tor可以指定增长因子,如果该增长因子指定了,那么扩容的时候会每次新的数组大小会在原数组的大小基础上加上增长因子;如果不指定增长因子,那么就给原数组大小*2,源代码是这样的:
int newCapacity = oldCapacity + ((capacityIncrement > 0) ? capacityIncrement : oldCapacity);
OK,今天的文章就分享到这里,如有问题还请批评指正。
欢迎关注微信公众号:java的架构师技术栈,回复关键字可获取计算机系列各种教程资源。包含java基础、java进阶、java工具、java框架、java架构师、python、android、微信小程序、数据库、前端、神经网络、机器学习等等各个方面的教程资源。
[外链图片转存失败(img-lr17yZFI-1562924383185)(K:\自媒体\微信公众号.png)]