GPT-4充当“规划师、审计师”,颠覆性双层文生图表模型
DALL-E 3、Midjourney、Stable Diffusion等模型展现出了强大的创造能力,通过文本便能生成素描、朋克、3D、二次元等多种类型的高质量图片,但在生成科学图表(柱状、直方、箱线、树状等)方面却略显不足。
这是因为模型在生成图表时会遗漏重要的对象,生成错误的对象关系箭头,以及产生不可读的文本标签,缺乏对对象的精细布局控制。尤其是当多个对象存在复杂的箭头或线段关系时,无法渲染清晰可读的文本,而这两点对于图表生成至关重要。
为了解决这两大难题,北卡罗来纳大学提出了DiagrammerGPT框架。首先,使用GPT-4充当“规划师”,根据文本描述生成图表的布局规划信息。
规划信息包含实体(对象和文本标签)、实体之间的关系(箭头、线段等)以及实体的布局信息(边界框坐标)。然后再用GPT-4充当“审计师”来审核整个规划计划,进行图表细节优化。
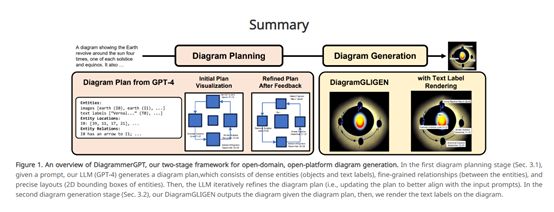
在图表生成阶段,通过DiagramGLIGEN扩散模型能够根据图表规划生成精准图表,并用Pillow库对文本标签进行渲染提升精准度。
根据测试数据显示,在多个量化指标上,DiagrammerGPT 显著优于Stable Diffusion、VPGen 和 AutomaTikZ等模型生成的图表。
在图表与文本相关性和对象关系的准确性评估方面,DiagrammerGPT分别取得36%和48%的优于基准模型的评分。该研究对于文本生成高精准图表模型来说,有着重大突破。
开源地址:https://github.com/aszala/DiagrammerGPT
论文地址:https://arxiv.org/abs/2310.12128
图表规划
DiagrammerGPT框架的最大创新在于,利用GPT-4的强大自然语言处理能力指导图表布局生成。为了生成更准确的规划,还设计了闭环反馈机制。
一个GPT-4 充当“规划师”生成初始规划,另一个 GPT-4 充当“审计师”,评估规划的准确性并提供反馈。而规划师可以根据反馈调整规划布局。
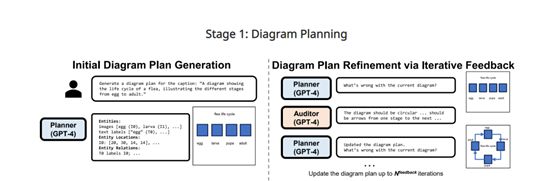
1)初始图表规划生成
研究人员对GPT-4通过10个语境学习样例进行了训练,每个样例都包含完整的图表文本描述、实体、关系和布局信息。规划包含3个要素:
实体:对象和文本标签的列表。对象指图表中的图像元素,文本标签指对象的文字说明。
关系:实体之间的关系,比如箭头连接、线段连接、文本标签标注对象等。
布局:所有实体的边界框坐标信息,[x,y,w,h]格式。
2)规划优化
为进一步提高规划质量,提出了规划师、审计师的闭环反馈机制进行迭代优化。其中GPT-4充当规划师,另一个GPT-4充当审计师。审计师会检查规划与文本描述是否匹配,提供反馈意见;规划师根据反馈更新规划。
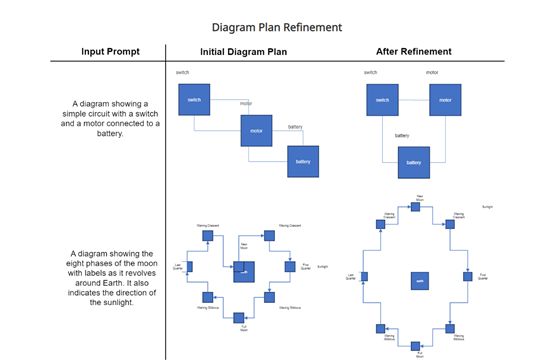
其中,审计师GPT-4也是通过特定语境学习进行训练的,以提供有效的反馈意见。两者训练使用不同的语境学习样本。

图表生成
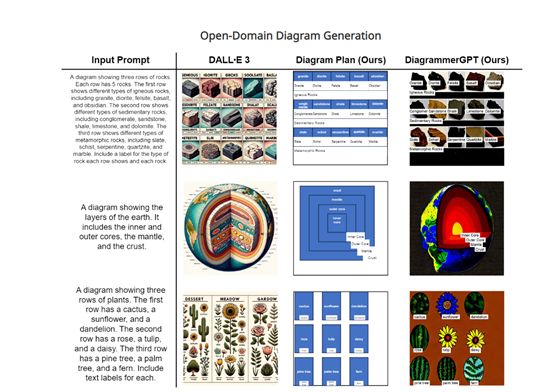
研究人员通过Diagram GLIGEN扩散模型用于图表生成,并加入了门控自注意力层,可以利用图表规划的布局信息指导图像生成。
与原始的GLIGEN模型只处理物体不同,DiagramGLIGEN可同时处理文本标签和箭头关系作为布局输入。DiagramGLIGEN在AI2D-Caption数据集上进行了训练,使其能生成特定领域的科学图表。

但由于扩散模型本身文本渲染效果不佳,无法输出清晰可读的文本,研究人员使用Pillow库显式渲染文本标签,提升文本的清晰度。
训练、评估数据集
研究人员基于AI2D科学图表数据集构建了AI2D-Caption数据集,用于文本到图表生成的训练和数据测试。AI2D包含约4900张科学图表图像,涵盖天文、生物、工程等领域。
其中选取了105张图表,使用大语言模型为每个图表生成详细的图像标题和对象描述。其中30张作为语言模型的语境学习样本,75张作为测试集。
相比原始AI2D只有简单的标题,AI2D-Caption提供了更丰富的文本描述,包括完整的图表标题和每个对象的详情。
多个基准测试数据显示,在VPEval上,DiagrammerGPT的对象、数量、关系和文本渲染准确性均明显优于基准模型,从多个方面证明了其生成图表的高质量。
在图像字幕上,DiagrammerGPT生成的图表能产生更相关的标题,标题与真值更加接近。在CLIPScore上,DiagrammerGPT的图像-文本和图像-图像相似度更高,更接近真值图表和标题。还进行了人类评估,多数人表示,更喜欢DiagrammerGPT生成的图表。
本文素材来源北卡罗来纳大学论文,如有侵权请联系删除
END