fork()函数与vfork()函数总结
fork函数与vfork函数实例分析总结
- 一、fork函数介绍如下
- 二、vfork()函数介绍如下
- 三、区别如下:
- 四、fork/vfork操作中父子进程关于文件的关系的验证
- 五、浅谈写时复制技术
这两个函数都是创建进程的函数:
首先了解一下什么是进程:进程是计算机上的程序关于某个数据及时上的一次运行活动。
进程的四要素:
(1)有一段程序供其执行(不一定是一个进程所专有的),就像一场戏必须有自己的剧本。
(2)有自己的专用系统堆栈空间(私有财产)
(3)有进程控制块(task_struct)(“有身份证,PID”)
(4)有独立的存储空间。
缺少第四条的称为线程,如果完全没有用户空间称为内核线程,共享用户空间的称为用户线程。
| 系统调用 | 描述 |
|---|---|
| fork | fork创造的子进程是父进程的完整副本,复制了父亲进程的资源,包括内存的内容task_struct内容 |
| vfork | vfork创建的子进程与父进程共享数据段,而且由vfork()创建的子进程将先于父进程运行 |
| clone | Linux上创建线程一般使用的是pthread库 实际上linux也给我们提供了创建线程的系统调用,就是clone |
一、fork函数介绍如下
#include 正确返回: 父进程中返回子进程的进程号;子进程中返回 0;(单调用双返回函数)
错误返回:-1;
子进程是父进程的一个拷贝。具体说, 子进程从父进程那得到了数据段和堆栈段,但不是与父进程共享而是单独分配内存。fork函数返回后,子进程和父进程都是从fork函数的下一条语句开始执行。
fork1.c内容如下:
实例代码:
#include 【总结】fork1.c验证了
从运行结果里面可以看出父子两个进程的pid不同,堆栈和数据资源都是完全的复制
子进程改变了count的值,而父进程中的count没有被改变。
子进程与父进程count的地址(虚拟地址)是相同的(注意他们在内核中被映射的物理地址不同)
补充一个技术:写时复制技术(Copy On Write)
原理:
这种思想相当简单:父进程和子进程共享页帧而不是复制页帧。然而,只要页帧被共享,它们就不能被修改,即页帧被保护。无论父进程还是子进程何时试图写一个共享的页帧,就产生一个异常,这时内核就把这个页复制到一个新的页帧中并标记为可写。原来的页帧仍然是写保护的:当其他进程试图写入时,内核检查写进程是否是这个页帧的唯一属主,如果是,就把这个页帧标记为对这个进程是可写的。
其基础的观念是,如果有多个呼叫者(callers)同时要求相同资源,他们会共同取得相同的指标指向相同的资源,直到某个呼叫者(caller)尝试修改资源时,系统才会真正复制一个副本(private copy)给该呼叫者,以避免被修改的资源被直接察觉到,这过程对其他的呼叫只都是通透的(transparently)。此作法主要的优点是如果呼叫者并没有修改该资源,就不会有副本(private copy)被建立。
当进程A使用系统调用fork创建一个子进程B时,由于子进程B实际上是父进程A的一个拷贝,
因此会拥有与父进程相同的物理页面.为了节约内存和加快创建速度的目标,fork()函数会让子进程B以只读方式共享父进程A的物理页面.同时将父进程A对这些物理页面的访问权限也设成只读.
这样,当父进程A或子进程B任何一方对这些已共享的物理页面执行写操作时,都会产生页面出错异常(page_fault int14)中断,此时CPU会执行系统提供的异常处理函数do_wp_page()来解决这个异常.
do_wp_page()会对这块导致写入异常中断的物理页面进行取消共享操作,为写进程复制一新的物理页面,使父进程A和子进程B各自拥有一块内容相同的物理页面.最后,从异常处理函数中返回时,CPU就会重新执行刚才导致异常的写入操作指令,使进程继续执行下去.
什么时候会触发这个技术:
当然是在共享同一块内存的类发生内容改变时,才会发生Copy On Write(写时复制)。
#include运行结果:
before vfork
pid=3402,glob=7,var=89
pid=3401,glob=6,var=88
./a.out>tmp.out | cat tmp.out的运行结果:
before vfork
pid=3410,glob=7,var=89
before vfork
pid=3408,glob=6,var=88
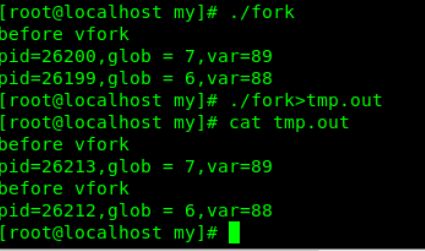
原因:当直接由终端输出时,此时标准i/o采用行缓冲,即缓冲区有换行符后马上输出:进程执行./a.out时,代码运行至printf(“before fork\n”);终端检测到缓冲区中有换行符,此时直接冲刷缓冲区,将数据输出,缓冲区为空,以至于后面执行fork()时因为父进程缓冲区中并没有数据,子进程复制的缓冲区也为空,子进程结束后,并没有数据输出
当输出重定向到文件时,此时标准i/o采用全缓冲,即缓冲区必须满一定大小后才会输出,进程结束时会刷新缓冲区,输出数据,或者调用fflush():由于采用全缓冲,缓冲区的数据并没有直接输出,因为缓冲区并没有满,以至于后面fork()函数执行时子进程也复制了父进程的缓冲区,此时两个缓冲区中都有before fork之前的缓冲内容的数据,当父进程和子进程结束时,两个缓冲区都会被冲刷。
二、vfork()函数介绍如下
使用vfork()函数创建子进程,保证子进程先运行,而fork()函数子进程父进程都内核连子进程的虚拟地址空间结构也不创建了,直接共享了父进程的虚拟空间,这种做法也顺理成章地共享了父进程的物理空间。
vfork也是创建一个子进程,但不是真正意义上的进程,因为它缺少构成进程四要素的第四个,即没有独立的内存空间,所以说它是一个线程,子进程共享父进程的空间。在vfork创建子进程之后,父进程阻塞,直到子进程执行了exec()或者exit()。vfork最初是因为fork没有实现COW机制,而很多情况下fork之后会紧接着exec,而exec的执行相当于之前fork复制的空间全部变成了无用功,所以设计了vfork。而现在fork使用了COW机制,唯一的代价仅仅是复制父进程页表的代价。
1.vfork保证子进程先运行,在它调用exec或exit之后父进程才可能被调度运行。如果在调用这两个函数之前子进程依赖于父进程的进一步动作,则会导致死锁。
2.fork要拷贝父进程的进程环境;而vfork则不需要完全拷贝父进程的进程环境,在子进程没有调用exec和exit之前,子进程与父进程共享进程环境,相当于线程的概念,此时父进程阻塞等待。
为什么会有vfork呢?
因为以前的fork当它创建一个子进程时,将会创建一个新的地址空间,并且拷贝父进程的资源,然后将会有两种行为:
1.执行从父进程那里拷贝过来的代码段
2.调用一个exec执行一个新的代码段
验证文件vfork.c文件内容如下:
#include 结果如下:
我们可以看到count的值是不一样的。

我们要注意一点,使用vfork()在子进程中返回时,应该要避免使用return,使用exit(0)或者_exit(0)都可以,使用return返回验证如下:
#include 需要深入了解的读者可以查阅关于exit、_exit()、return 的区别这篇文章。
三、区别如下:
有了fork()函数,为什么要引入vfork()?
因为以前的fork当它创建一个子进程时,将会创建一个新的地址空间,并且拷贝父进程的资源,而往往在子进程中会执行exec调用,这样,前面的拷贝工作就是白费力气了,这种情况下,聪明的人就想出了vfork,它产生的子进程刚开始暂时与父进程共享地址空间(其实就是线程的概念了),因为这时候子进程在父进程的地址空间中运行,所以子进程不能进行写操作,一旦子进程执行了exec或者exit后,这个时候父子分家。此时vfork保证子进程先运行,在她调用exec或exit之后父进程才可能被调度运行。
用vfork函数创建子进程后,子进程往往要调用一种exec函数以执行另一个程序,当进程调用一种exec函数时,该进程完全由新程序代换,而新程序则从其main函数开始执行,因为调用exec并不创建新进程,所以前后的进程id 并未改变,exec只是用另一个新程序替换了当前进程的正文,数据,堆和栈段。
1.vfork保证子进程先运行,在它调用exec或exit之后父进程才可能被调度运行。如果在调用这两个函数之前子进程依赖于父进程的进一步动作,则会导致死锁。
2.fork要拷贝父进程的进程环境;而vfork则不需要完全拷贝父进程的进程环境,在子进程没有调用exec和exit之前,子进程与父进程共享进程环境,相当于线程的概念,此时父进程阻塞等待。
fork函数调用的用途
⑴ 一个进程希望复制自身,从而父子进程能同时执行不同段的代码。
⑵ 进程想执行另外一个程序
vfork函数调用的用途
用vfork创建的进程主要目的是用exec函数执行另外的程序,与fork的第二个用途相同
这两种用途验证文件内容如下:
四、fork/vfork操作中父子进程关于文件的关系的验证
在执行fork/vfork操作后,父进程会复制所有的资源,包括文件描述符给子进程。编程验证父子进程对于相同文件操作时,是否会相互影响,即两者是会共享文件指针,还是拥有自己各自独立的指针体系。
接下来:
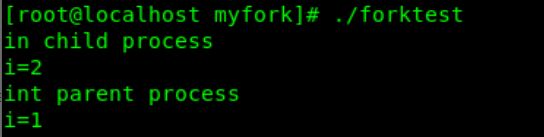
用一个forktest.c文件来验证
代码如下:
#include 结果如下:
执行vforktest.c结果如下:
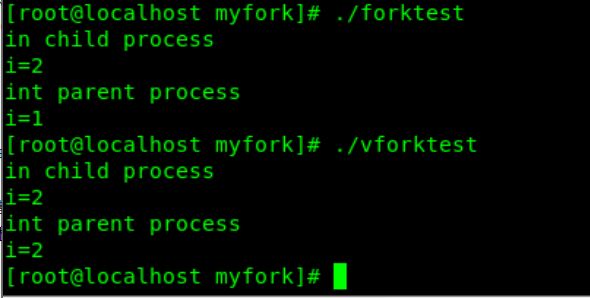
说明:forktest.c与vforktest.c文件就一行代码不一样。请看代码块中的那一行注释。
由结果可知:
(1)从test.txt的内容可以看出,父子进程对同一个文件操作,写入数据也不覆盖,即说明父子进程共享文件偏移,因此共享文件表项
(2)从i的结果可以知道,而从变量i可以看出子进程赋值后父进程的i值不变,说明父子进程各自拥有这一变量的副本,互相不影响。
验证2:
我们再看一个验证,如下:
#include首先来简要介绍一下代码,

一个父进程fork了3个子进程,就这么简单,我们来看看这个程序运行的结果,请看下图:

们可以从结果得知,父进程一直是先行的,至于这个原因,笔者也在思考中,希望广大读者知道后告知我一声,感激不尽,除此之外我们发现有很重要的两点:
- 计数器count我们在父进程中进行了相关的定义,但是每次的结果却是相同的,这无疑证明了一点,fork()函数创造的子进程是父进程的完整副本,复制了父亲进程的资源,包括内存的内容task_struct内容
- 父进程与创造出来的三个子进程共享文件表项。即这个文件为大家共享。
在这里提到了一点关于exec函数族的知识点,可以查看此文章exec函数族用法总结
有一个很重要的东西是,在fork()的调用处,整个父进程空间会原模原样地复制到子进程中,包括指令,变量值,程序调用栈,环境变量,缓冲区,等等。
这里涉及到一些缓冲区的知识,若读者对此有些迷惑,可参考笔者写的关于缓冲区的一篇文章,然后再看此篇文章。全缓冲、行缓冲、无缓冲三种缓冲区的理解
五、浅谈写时复制技术
copy-on-write工作原理
假设进程A创建子进程B,之后进程A和进程B共享A的地址空间,同时该地址空间中的页面全部被标识为写保护。此时B若写address的页面,由于写保护的原因会引起写异常,在异常处理中,内核将address所在的那个写保护页面复制为新的页面,让B的address页表项指向该新的页面,新页面可写。而A的address页表项依然指向那个写保护的页面。然后当B在访问address时就会直接访问新的页面了,不会在访问到哪个写保护的页面。当A试图写address所在的页面时,由于写保护的原因此时也会引起异常,在异常处理中,内核如果发现该页面只有一个拥有进程,此种情况下也就是A,则直接对该页面取消写保护,此后当A再访问address时不会在有写保护错误了。如果此时A又创建子进程C,则该address所在的页面又被设置为写保护,拥有进程A和C,同时其他页面例如PAGEX依然维持写保护,只是拥有进程A、B和C。如果此时A访问PAGEX,则异常处理会创建一个新页面并将PAGEX中的内容复制到该页面,同时A相应 的pte指向该新页面。如果此时C也访问PAGEX,也会复制新页面并且让C对应的pte指向新页面。如果B再访问PAGEX,则由于此时PAGEX只有一个拥有进程B,故不再复制新页面,而是直接取消该页面的写保护,由于B的pte本来就是直接指向该页面,所以无需要在做其它工作。