【图像分类】【深度学习】【Pytorch版本】ResNet模型算法详解
【图像分类】【深度学习】【Pytorch版本】 ResNet模型算法详解
文章目录
- 【图像分类】【深度学习】【Pytorch版本】 ResNet模型算法详解
- 前言
- ResNet讲解
-
- Deep residual learning framework(深度残差学习框架)
- 残差结构(Residuals)
- ResNet模型结构
- ResNet Pytorch代码
- 完整代码
- 总结
前言
ResNet是微软研究院的He, Kaiming等人在《Deep Residual Learning for Image Recognition【CVPR-2016】》【论文地址】一文中提出的模型,通过残差模块发现并解决深层网络的退化问题,使更深的卷积神经网络的训练成为可能,大大提升神经网络深度。
网络的退化问题:随着网络层数的增加,模型性能反而变得更差的现象。
ResNet讲解
神经网络将一个端到端的多层模型中的低/中/高级特征以及分类器整合起来,特征的等级可以通过所堆叠层的数量(深度)来丰富,模型的深度发挥着至关重要的作用。
训练一个更好的网络是否和堆叠更多的层一样简单呢?解决这一问题的障碍是梯度消失/梯度爆炸 (退化问题),这阻碍了模型的收敛。传统解决办法通过归一初始化(normalized initialization) 和**中间归一化(intermediate normalization)**在很大程度上解决了这一问题,它使得数十层的网络在反向传播的随机梯度下降上能够收敛。
但是当更深的网络能够开始收敛时又暴露了新的退化问题:随着网络深度的增加,准确率达到饱和后迅速下降。这种下降并不是由过拟合引起的,并且在深度适当的模型上添加更多的网络层会导致更高的训练误差。

论文中提到了一种构建神经网络的理论(思路):假设浅层网络已经取得不错的效果,新增加的网络层啥也不干,只是拟合一个恒等映射(identity mapping),就是新增网络层的输出就拟合新增网络层的输入,这样构建的深层网络至少不应该比没有新增网络层的浅层网络的训练误差要高。该理论在当时没能用实验进行证明。
Deep residual learning framework(深度残差学习框架)
依据:一个更深的模型不应当产生比它的浅层版本更高的训练错误率。
为了解决退化问题,作者在该论文中提出了“深度残差学习框架”的网络。在该框架中,每个堆叠网络块(building block) 拟合残差映射(Residual mapping)。
相较于残差结构(Plaint net),将以前的结构称之为非残差结构(Residual net)。
网络块由若干卷积层组成,非残差结构直接拟合网络块期望的基础映射(Underlying mapping) H ( X ) H(X) H(X),基础映射即将当前网络块的输入与输出之间的映射。残差结构同样是拟合网络块的基础映射 H ( X ) H(X) H(X),但网络块新增了一条shortcut分支表示恒等映射/投影(identity) X X X,网络块的主分支(堆叠的若干卷积层)拟合的就是残差映射 F ( X ) = H ( X ) − X F(X)=H(X)-X F(X)=H(X)−X,没有像非残差结构一样直接对 H ( X ) H(X) H(X)进行拟合。
恒等快捷连接既不增加额外的参数也不增加计算复杂度
在极端情况下,假设 X X X是最优的,不需要后续网络块处理,残差结构将主分支 F ( X ) F(X) F(X)置为零比非残差结构将 H ( X ) H(X) H(X)直接拟合成原始输入的 X X X更容易,即使 F ( X ) F(X) F(X)不可能得到理想的置零,但是接近于零,也足以缓解了退化问题。
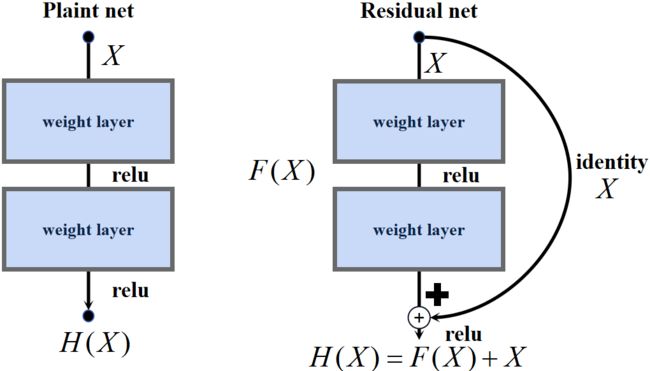
论文实验证明,优化残差映射比优化原始的基础映射容易很多,残差结构确实比其他结构更易学习!
残差结构(Residuals)
正是因为提出了残差模块,可以搭建更深的网络,论文中提到了俩种残差结构,左边的图主要是针对层数较少的网络使用的残差结构,右边的图是针对层数较多的网络使用的残差结构。

残差结构在主路上经过一系列的卷积层之后输出的特征图再与输入特征图进行一个相加的操作,主分支与shortcut分支的特征图在相同的维度上做相加的操作,之后通过激活函数输出,这就要求主分支与shortcut的输出特征图形状必须完全一致。
1×1卷积是为了升维和降维
随着网络层深度增加时,输出的特征图的尺寸会减小而通道数会增加,部分残差结构的输入特征图和输出特征图的形状不再保持一致,为了应对这种情况,会在shortcut分支上新增一层1×1卷积层,目的是为了残差结构的主分支输出特征图和shortcut分支输出特征图的形状再次保持一致。

ResNet模型结构
下图是原论文给出的关于ResNet模型结构的详细示意图: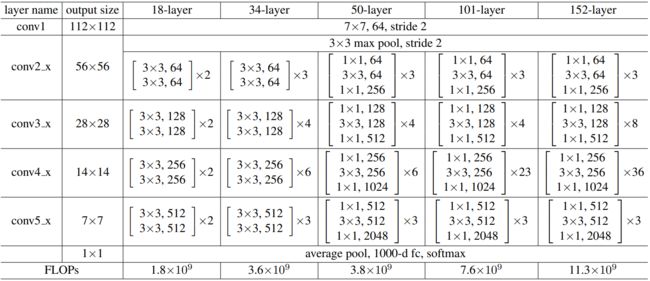
Resnet在图像分类中分为两部分:backbone部分: 主要由残差结构、卷积层和池化层(汇聚层)组成,分类器部分:由全连接层组成 。
论文通过前文提到的两种残差结构的堆叠搭建了5种网络,分别为Resnet-18、Resnet-34、Resnet-50、Resnet-101和Resnet-152。
下图以Resnet-34为例,根据Vgg的启发构建卷积神经网络:

对于输出特征图尺寸相同的层,具有相同数量的卷积核;当特征图尺寸减半则卷积核数量加倍以保持每层网络计算的时间复杂度;主要通过步长为2的卷积层直接执行下采样。
当输入和输出具有相同形状(实线shortcut),可以直接使用恒等快捷连接;当输入和输出具有不同形状时(虚线shortcut),新增一层1×1卷积层用于配准形状。
ResNet Pytorch代码
残差结构BasicBlock(小网络): 卷积层+BN层+激活函数
class BasicBlock(nn.Module):
# 小网络的输入输出的channel是保存一致的
expansion = 1
def __init__(self, in_channel, out_channel, stride=1, downsample=None, **kwargs):
super(BasicBlock, self).__init__()
# 第一层卷积层
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channel)
self.relu = nn.ReLU()
# 第二层卷积层
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel,
kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channel)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
# 第一层卷积层
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
# 第二层卷积层
out = self.conv2(out)
out = self.bn2(out)
out += identity
out = self.relu(out)
return out
残差结构Bottleneck(大网络): 卷积层+BN层+激活函数
class Bottleneck(nn.Module):
# 大网络的输出channel是输入channel的4倍
expansion = 4
def __init__(self, in_channel, out_channel, stride=1, downsample=None):
super(Bottleneck, self).__init__()
# 第一层卷积层
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
kernel_size=1, stride=1, bias=False) # 压缩channel
self.bn1 = nn.BatchNorm2d(out_channel)
# 第二层卷积层
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel,
kernel_size=3, stride=stride, bias=False, padding=1)
self.bn2 = nn.BatchNorm2d(out_channel)
# 第三层卷积层
self.conv3 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel*self.expansion,
kernel_size=1, stride=1, bias=False) # 扩展channel
self.bn3 = nn.BatchNorm2d(out_channel*self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
# 第一层卷积层
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
# 第二层卷积层
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
# 第三层卷积层
out = self.conv3(out)
out = self.bn3(out)
out += identity
out = self.relu(out)
return out
downsample(输入和输出形状不同): 卷积层+BN层
downsample = nn.Sequential(
nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(channel * block.expansion))
完整代码
import torch.nn as nn
import torch
from torchsummary import summary
class BasicBlock(nn.Module):
# 小网络的输入输出的channel是保存一致的
expansion = 1
def __init__(self, in_channel, out_channel, stride=1, downsample=None):
super(BasicBlock, self).__init__()
# 第一层卷积层
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channel)
self.relu = nn.ReLU()
# 第二层卷积层
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel,
kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channel)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
# 第一层卷积层
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
# 第二层卷积层
out = self.conv2(out)
out = self.bn2(out)
out += identity
out = self.relu(out)
return out
class Bottleneck(nn.Module):
# 大网络的输出channel是输入channel的4倍
expansion = 4
def __init__(self, in_channel, out_channel, stride=1, downsample=None):
super(Bottleneck, self).__init__()
# 第一层卷积层
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
kernel_size=1, stride=1, bias=False) # 压缩channel
self.bn1 = nn.BatchNorm2d(out_channel)
# 第二层卷积层
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel,
kernel_size=3, stride=stride, bias=False, padding=1)
self.bn2 = nn.BatchNorm2d(out_channel)
# 第三层卷积层
self.conv3 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel*self.expansion,
kernel_size=1, stride=1, bias=False) # 扩展channel
self.bn3 = nn.BatchNorm2d(out_channel*self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
# 第一层卷积层
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
# 第二层卷积层
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
# 第三层卷积层
out = self.conv3(out)
out = self.bn3(out)
out += identity
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self,
block,
blocks_num,
num_classes=1000):
super(ResNet, self).__init__()
self.in_channel = 64
self.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2,
padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(self.in_channel)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# 第一组残差块组
self.layer1 = self._make_layer(block, 64, blocks_num[0])
# 第二组残差块组
self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2)
# 第三组残差块组
self.layer3 = self._make_layer(block, 256, blocks_num[2], stride=2)
# 第四组残差块组
self.layer4 = self._make_layer(block, 512, blocks_num[3], stride=2)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # output size = (1, 1)
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
def _make_layer(self, block, channel, block_num, stride=1):
downsample = None
# 残差块组中的第一个残差块
'''
第一个残差块组是不执行下采样的,但是小网络的输入输出是channel一致,大网络输出是输入channel的四倍
因此shortcut是否需要卷积层的判断条件不再是stride,而是channel
channel不一致则是大网络的Bottleneck,第一个残差块需要卷积层调整维度
'''
if stride != 1 or self.in_channel != channel * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(channel * block.expansion))
layers = []
layers.append(block(self.in_channel,
channel,
downsample=downsample,
stride=stride))
self.in_channel = channel * block.expansion
# 残差块组中的剩余残差块
for _ in range(1, block_num):
layers.append(block(self.in_channel,
channel))
return nn.Sequential(*layers)
def forward(self, x):
# backbone主干网络部分
# resnet34为例
# N x 3 x 224 x 224
x = self.conv1(x)
# N x 64 x 112 x 112
x = self.bn1(x)
# N x 64 x 112 x 112
x = self.relu(x)
# N x 64 x 112 x 112
x = self.maxpool(x)
# N x 64 x 56 x 56
# 第一组残差块组
x = self.layer1(x)
# N x 64 x 56 x 56
# 第二组残差块组
x = self.layer2(x)
# N x 128 x 28 x 28
# 第三组残差块组
x = self.layer3(x)
# N x 256 x 14 x 14
# 第四组残差块组
x = self.layer4(x)
# N x 512 x 7 x 7
# 分类器部分
x = self.avgpool(x)
# N x 512 x 1 x 1
x = torch.flatten(x, 1)
# N x 512
x = self.fc(x)
# N x 1000
return x
def resnet18(num_classes=1000):
# https://download.pytorch.org/models/resnet34-333f7ec4.pth
return ResNet(BasicBlock, [2, 2, 2, 2], num_classes=num_classes)
def resnet34(num_classes=1000):
# https://download.pytorch.org/models/resnet34-333f7ec4.pth
return ResNet(BasicBlock, [3, 4, 6, 3], num_classes=num_classes)
def resnet50(num_classes=1000):
# https://download.pytorch.org/models/resnet50-19c8e357.pth
return ResNet(Bottleneck, [3, 4, 6, 3], num_classes=num_classes)
def resnet101(num_classes=1000):
# https://download.pytorch.org/models/resnet101-5d3b4d8f.pth
return ResNet(Bottleneck, [3, 4, 23, 3], num_classes=num_classes)
def resnet152(num_classes=1000):
# https://download.pytorch.org/models/resnet101-5d3b4d8f.pth
return ResNet(Bottleneck, [3, 8, 36, 3], num_classes=num_classes)
if __name__ == '__main__':
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = resnet34().to(device)
summary(model, input_size=(3, 224, 224))
summary可以打印网络结构和参数,方便查看搭建好的网络结构。

总结
尽可能简单、详细的介绍了残差结构的原理和在卷积神经网络中的作用,讲解了ResNet模型的结构和pytorch代码。