论文笔记1:SummaRuNNer: A RNN based Sequence Model for Extractive Summarization of Documents
引言
自动文摘(auto text summarization)在信息检索(IR)和自然语言处理(NLP)领域有很多应用,自动文摘主要分成extractive,抽取式,从原文中找到一些关键的句子,另一种是abstractive,摘要式,这需要计算机读懂原文内容,并用自己的意思将其表达出来。
现在大多数的研究是基于抽取式的自动文摘,传统的抽取式自动文摘可分为三类:
- 基于贪心算法的(greedy approaches)
- 基于图的(graph based approaches)
- 基于限制优化的(constraint optimization based approaches)
最近基于神经网络抽取式自动摘要也越来越流行:recursive autoencoder、CNN等神经网络算法被用到抽取式自动文摘。随着强大的生成神经模型(generative neural
models)在文本处理领域的出现,摘要式自动文摘也流行起来了:基于Attention机制的前馈神经网络用于标题生成、基于编码-解码模型的循环神经网络等。
这篇论文的主要工作聚焦于:单文档的句子抽取式的自动文摘。使用的语料库是CNN/Daily Mail语料库,该语料库规模比较大,适合深度神经网络训练。
这篇论文的主要贡献有以下三点:
- 提出了一个简单的基于序列分类器的循环神经网络模型:SummaRuNNer
- 该模型表述简单,可解释性强
- 展示了一个新奇的训练机制:我们的抽取式文摘生成模型可以使用人工生成的摘要式文摘(abstractive summary)来训练抽取式
SummaRuNNer模型
该模型由两层双向GRU-RNN组成,如下图,GRU公式描述如下:

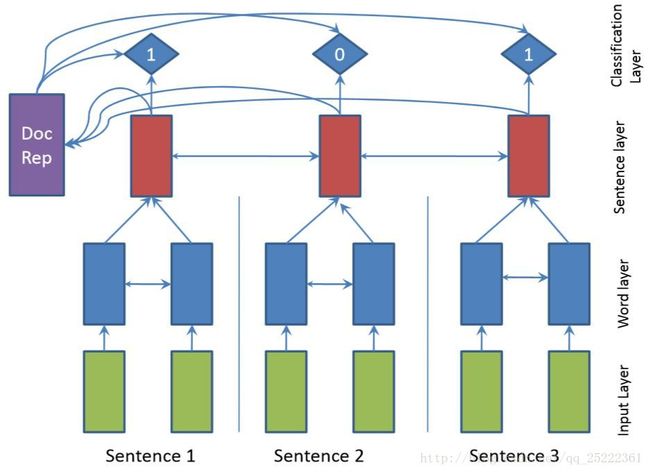
其中,word_layer可展开如下图:

后文可知,该模型的词的表示使用的是100维的word2vec向量,即是图中的 x1...xn (假设文档中的词的数量为 n ),经过公式(1)~(4)获得该层的输出wb1...wbn;wf1...wfn,假设文档的句子数量为 m ,第j个句子的单词数量为 Cj ,起始单词序号为 startj 结束单词序号为 endj :
senj 即为sentence-level层的输入,原文中并未出现该公式,此公式是我根据原文描述推断的,原文描述为:
The model also consists of a second layer of bi-directional RNN that runs at the sentence-level and accepts the average-pooled, concatenated hidden states of the bi-directional word-level RNNs as input.
模型第二层,sentent_layer可展开如下图:
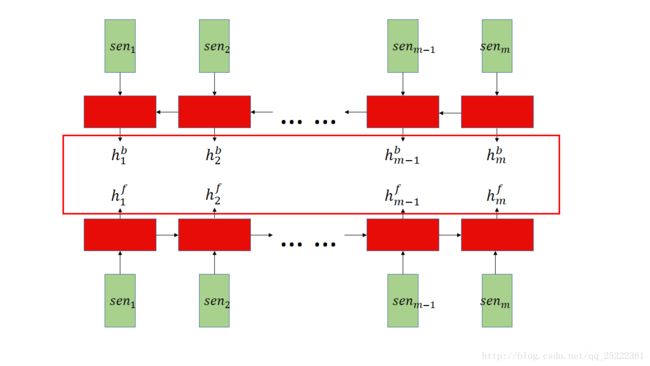
图中的 m 即为原文公式5中的Nd:

模型中的Classification_layer,输出该句被选为摘要的概率:

其中 Wc,Ws,Wr,Wap,Wrp,paj,prj,b 都是模型参数, sj 是动态的文摘表示,是已访问过的句子的sentence_level的隐藏层状态的加权和,权重就是这个句子最终是摘要的概率:
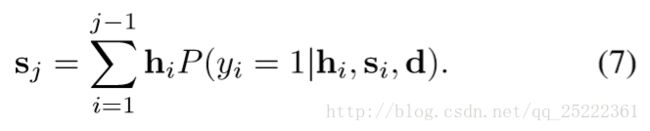
训练时的损失函数使用的是预测概率与真实文摘的cross_entropy:

抽取式训练(Extractive Training)
由于语料库的参考文摘都是摘要式(abstrctive)的,所以不能直接用于SummaRuNNer这个模型的抽取式训练。该论文使用如下贪心算法来抽取文章的句子添加到训练时使用的参考文摘里 :
def get_extractive_ground_truth():
summary_set = None
last_score = 0
while Rouge_Score(summary_set, Ground_Truth) > prev_score:
prev_score = Rouge_Score(summary_set, Ground_Truth)
add one sentence to summary_set, the added sentence will maximize the Rouge_Score
return summary_set摘要式训练(Abstrctive Training)
在SummaRuNNer这个模型的基础上,作者添加了一个decoder用来产生摘要式文摘,使得模型也可以被摘要是地训练。根据论文描述decoder大概是这样的:
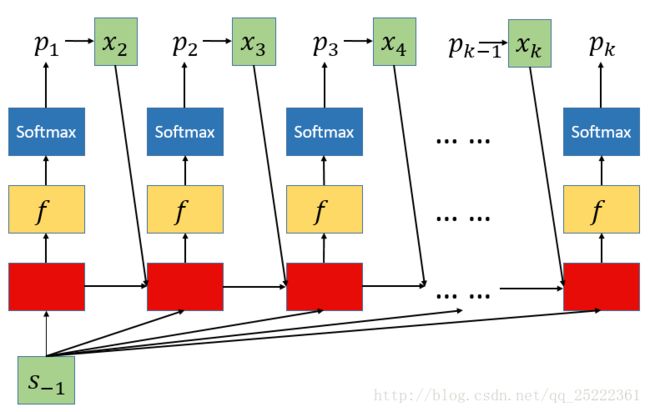
整体上是RNN结构,红色的是GRU单元,黄色是一个前馈神经层f,最后接softmax层,输出概率 pk , pk 是一个向量,维数与词汇数量相同,每一维表示某个词的概率。每一个时间步骤根据输出的 pk 得到对应的词,再将该词的词向量( xk )作为下一时间步骤的输入,同时由SummaRuNNer最后一个时间步骤得到的文摘表示 s−1 作为decoder的每个时间步骤的输入。
decoder中GRU单元相关公式:

前馈神经层f和softmax层相关公式:

最终的loss函数是最小化参考文摘的负对数似然(关于这个loss没太明白,待弄清楚后再来说明):

论文中关于loss的描述如下:
Instead of optimizing the log-likelihood of the extractive ground truth as shown in Eq. 8, we minimize the negative log-likelihood of the words in the reference summary as follows.
where Ns is the number of words in the reference summary. At test time, we uncouple the decoder from SummaRuNNer and emit only the sentence-level extractive probabilities p(yj) of Eq. 6.
相关工作
- 把自动文摘当作序列分类模型早些时候就被很多研究者考虑了,比如(Shen et al. 2007),但是论文中提出的模型不需要任何的手工标注特征,这是该论文提出的模型的一大优势。
- 一般人工提供的摘要式文摘不能直接用于抽取式训练,该论文提出一个贪心策略,使用摘要式文摘得到抽取式文摘。(Svore, Vanderwende, and Burges 2007)也使用相似的策略解决此问题。最近 (Cao et al. 2015)提出了一个基于ILP的方法来解决此问题。(Cheng and Lapata 2016)对数据的一个子集进行人工标注,并用标注的数据单独训练了一个分类器,这虽然能提高抽取出的句子的准确率,但是需要额外的人工标注。
- 大部分的单文档自动摘要数据集都容易获取到,但是规模不够大,比如DUC数据集。但是CNN and Daily Mail数据集规模够大,适合深度模型训练。(Cheng and Lapata 2016)在抽取式自动文摘工作和我们最接近,他们的模型是基于encoder-decoder的方法,encoder学习句子和文档的表示,decoder基于encoder对每个句子进行分类,并且使用了attention mechanism。我们的模型抽取式训练时没有decoder,也许会少一些参数。
实验与结果
语料库
该论文使用由(Hermann et al. 2015)构造的CNN/DailyMail语料库,还使用了DUC2002单文档自动摘要语料库。
Evaluation
使用了Rouge度量:Rouge-1、Rouge-2、Rouge-L
SummaRuNNer模型的设置
单词表示使用了word2vec(Mikolov et al. 2013)。限制词汇数量为150k,每篇文档的句子数量最多为100,句子最长含有50个单词,以加快计算。模型隐藏层大小为200,batch_size为64,并且使用了adadelta(Zeiler 2012) 。训练时还使用了gradient clipping和early stopping。
各语料库实验结果
略。
定性分析
本文提出的模型的一大优势就是便于可视化(公式6各项意义明确),这种可视化在向终端用户解释由系统做出的决定方面特别有用。一个例子如下图:

结论
本文提出了一个可解释性强的用于抽取式自动摘要的神经序列模型,该模型有着直观的可视化功能,它比现有技术的深度学习模型的表现要好或可比。我们计划进一步探索将抽取和抽象方法结合起来,作为我们未来工作的一部分。一个简单的方法可能是使用摘要式训练来预训练抽取模型。 此外,我们计划构建一个联合抽取 - 抽象模型,其中我们的提取组件的预测形成抽象组件所要消耗的随机中间单元。
该博客参考文献:
SummaRuNNer: A Recurrent Neural Network based Sequence Model for Extractive Summarization of Documents
作者: 蒋平
出处: http://blog.csdn.net/qq_25222361/article/details/78667850
欢迎转载/分享, 但请务必声明文章出处.