论文阅读笔记:Seen to Unseen Exploring Compositional Generalization of Multi-Attribute Controllable Dialogu
文章的主要工作
(1)首次探索用于多属性可控对话生成的组合泛化,并发现现有模型缺乏对分布外的多属性组合的泛化能力。
(2)提出了一种解耦的可控生成方法,DCG,它通过属性导向提示的共享映射学习从已见值到未见组合的属性概念,并使用解耦损失来分离不同的属性组合。
(3)引入了一个统一的无需参照的评估框架,MAE,用于不同粒度的属性。我们建立了两个基准测试,并且充分的实验结果证明了我们的方法和评价指标的有效性。
DCG模型
总体架构
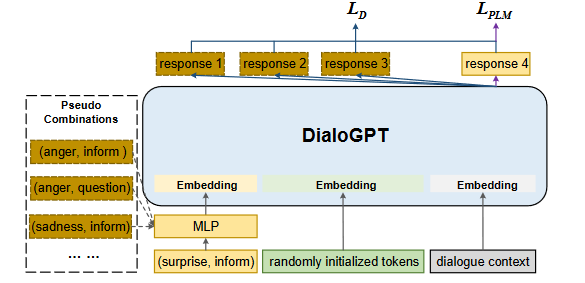
Compositional Prompt(合成提示)
1. Prompt设计
面向属性的提示
采用控制属性值的组合作为提示,指导模型聚焦于对话中的控制信息。这里所说的控制属性值,是指DailyDialog中的离散属性标签或者ConvAI2中的连续属性描述。相应组合 c c c中的多个属性值 a i a_i ai,·简单地串联成一个面向属性的提示序列,即 p a t t = [ a 1 , b 2 , . . . ] p_{att} = [a_1, b_2, ...] patt=[a1,b2,...]。我们使用预训练的DialogGPT的词嵌入层来编码提示令牌,然后采用共享的 M L P θ 1 MLP_{θ1} MLPθ1来生成面向属性提示的嵌入 E a t t E_{att} Eatt。我们不需要为每个属性值设置独立参数,只需一个共享的转换 M L P MLP MLP层。
面向任务的提示
采用一系列随机初始化的Token作为面向任务的提示, p t a s k = [ p 1 , . . . , p m ] p_{task} = [p_1, ..., p_m] ptask=[p1,...,pm],其中 m m m 是面向任务的提示序列的长度。我们在随机初始化的嵌入表 M θ 2 M_{θ_2} Mθ2 中查找该提示序列并得到提示嵌入 E t a s k E_{task} Etask 。
最后,将两个提示嵌入连接起来作为整个提示Embedding,即 E p = [ E a t t ; E t a s k ] E_p = [E_{att};E_{task}] Ep=[Eatt;Etask]。
2. Disentanglement Learning(特征解耦学习)
给定一个实例 ( d , c ) (d, c) (d,c),其中 d d d代表对话历史, c c c代表可控属性值的组合。为了迫使模型区分多个属性值的不同组合,我们设计了一些伪组合来增强提示的多样性,这样可以提高我们模型的泛化能力。我们进一步引入了一个解耦损失 L D L_D LD,以解耦组合表示,并同时训练多个组合提示:

C p s c C_{psc} Cpsc是伪组合的集合,而且在伪组合 ( c ′ ) ( c' ) (c′)中至少有一个属性值与真实组合中对应的属性值不同。在这里,我们的目标是最大化期望的正向组合的生成似然 P ( r ∣ d , c ) P(r|d, c) P(r∣d,c) 相对于伪组合的生成似然 P ( r ∣ d , c ′ ) P(r|d, c') P(r∣d,c′) ,以生成更加可控且与给定属性相关的响应。
训练策略
使用DialoGPT作为我们模型的主干网络。给定对话历史 d d d,嵌入 E d E_d Ed是通过DialoGPT获得的。然后,将提示序列 E p E_p Ep的嵌入作为整体输入嵌入矩阵前置到 E d E_d Ed之前。总体而言,PLM损失计算如下:

其中 T T T是生成序列的长度,即对话历史和回应的长度。 φ φ φ是PLM的参数且是固定的。两个提示的参数, θ 1 和 θ 2 θ1和θ2 θ1和θ2,是唯一需要更新的参数。因此,训练损失 L L L是PLM损失:

在训练完成后,我们会保存提示模块的所有参数。在推理过程中,测试集中的数据仅通过嵌入矩阵映射到提示的表示中,其中,在训练集中看到的属性特征可以转移到未见组合中。
MAE框架
总体架构
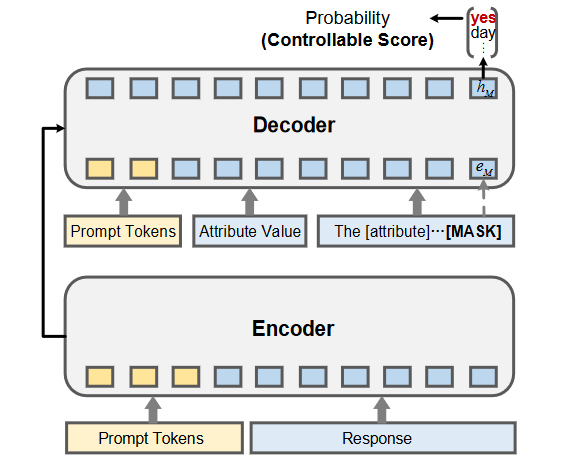
为了填补多属性可控对话生成领域度量指标的空缺,提出了一个统一且高效的评估框架,无需额外的大规模标记数据。这个框架将每个属性的评估转换为统一的文本到文本生成任务,T5被用作基础模型。设计了一个作为离散提示的模板,即“情绪/行为/人格控制响应[MASK]”。为了减轻不同手工制作模式的潜在偏见,我们进一步增加了一个可训练的连续任务导向提示,以提高稳定性和鲁棒性。
方法
连续的提示序列被作为前缀添加到响应中,构成编码器的输入部分。另一个连续的提示序列、属性值和模板被连接起来,然后馈送到解码器中。我们将生成 “yes” 对应于 [MASK] 标记的概率作为可控性评分。在训练过程中,只有连续提示的嵌入被更新,而 T5 的参数保持不变。请注意,我们的基于模型的评估方法在测试时摆脱了对黄金响应的依赖,可以统一应用于各种属性的不同粒度。
“黄金响应” 是指在自然语言处理任务中的一个参考标准响应,通常是由人类评审员或专家提供的,被认为是正确或理想的响应。在一些评估和训练任务中,研究人员使用黄金响应来衡量自动生成的文本或模型输出的质量。这可以用于评估自动翻译、文本生成、对话系统等任务的性能。黄金响应通常用作标准来比较和评估不同模型或算法的表现。