数仓理论基础
数仓理论基础
引用:尚硅谷电商数仓
什么是数仓?
存储数据、具备管理 分析能力,为企业做决策提供数据依据。
数据仓库的主体 hive
两种建模方式: ER和维度
ER模型
实体关系模型: 将复杂的数据抽象为 实体和关系。实体表示一个对象,关系指的是两个实体之间的关系,比如学生和班级之间的从属关系。
举例:学生管理系统 管理学生和班级的信息
1.抽取实体: 学生、班级
2.实体关系模型 一对多 画图 ER图
3.建表,通常一个实体对应一张表,通过外键进行关联,通常在多的一侧加外键,比如在学生一侧加上班级信息
多对多关系模型,比如说又加了一个学生选课信息
学生表和选课表是多对多的关系,一个学生可以选多门课,一门课可以被多个学生选。
处理多对多的表一般需要加一个中间表。 学生id 和选课id
数据库规范化
范式:normal form 有6种
函数:一个x对应一个y
- 完全函数依赖:f(x,y)=z 必须通过x,y得到一个z,z完全依赖于x y
- 部分函数依赖 f(x,y)=z z部分函数依赖于 x y k
- 传递函数依赖
第一范式
属性不可切割,指的是实体的属性。(也就是列不可再分)
比如5台电脑 可以被拆成数量5 和电脑
第二范式
不能存在 非主键字段 部分函数依赖于主键字段

比如上面这张表中 联合主键字段是 学号+课名,分数完全依赖于学号+课名,但是姓名部分依赖于学号,所以不满足第二范式。解决方案是把表拆成两个。能够部分减少函数冗余。
但也存在冗余 比如说 经济系和王强存储了两份数据了。
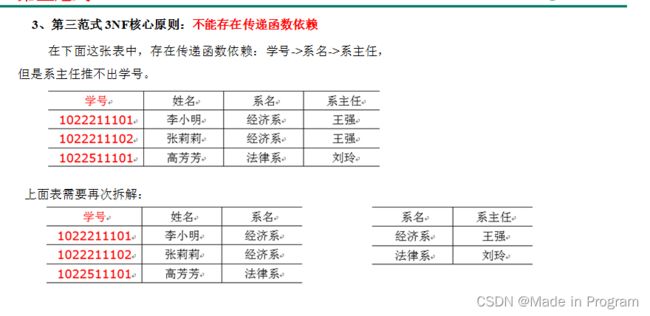
第三范式
不能存在非主键字段传递函数依赖于主键字段
学号能够推出系名—系名能够推出系主任
这种数据建模的主要目的主要是减少数据冗余,保证数据的一致性并不适合用于分析统计。
维度模型
通过事实和维度进行呈现。
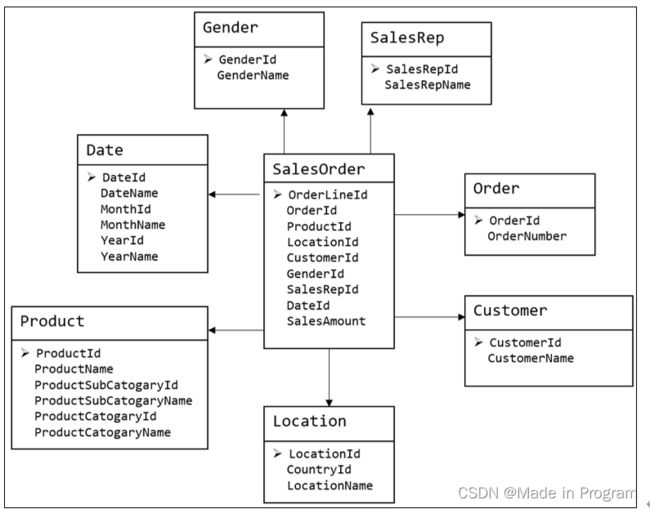
事实通常对应业务过程,例如下单、支付、加入购物车等
维度:业务过程发生时所处的环境,客观的事物(时间、地点等)、用户信息
如上图所示,中间的是事实表,旁边的一圈是维度表
事实表
事实表:包含两个 维度外键 和度量值
维度外键:和其他表关联的外键id
度量:(量化业务过程 比如下单金额 下单数量)
事实表的特点是细长,因为记录了一些事实信息,会有很多,行的增速会比较快。
事实表分类:事务型事实表、周期型快照事实表、累积型快照事实表
事务型事实表
- 事务型事实表:对应一个过程,保存最细粒度操作时间
最细粒度,能满足更多的需求。如何理解呢? 如果订单事实表中只有支付金额,没有具体购买数量,那么就无法满足统计购买总量的需求。
设计流程
遵循以下4个步骤
选择业务过程→声明粒度→确认维度→确认事实
1.选择业务过程
根据业务需求,比如下单、付款、退单等
2.声明粒度
粒度要尽可能细,即每行数据表示什么。比如订单表中最细粒度要到一行数据表示一个sku
3.确定维度
确定每张事务型事实表相关的维度有哪些。即时间、地点、人物等信息
维度的丰富程度决定了指标的丰富程度,比如按时间统计、按地点统计等
4.确认事实
事实就是每个业务过程的度量值,比如金额、个数、次数等可累加的值
不足
-
存量型指标的统计效率较低
如何理解? 什么是存量型指标,比如说京东的京豆,主要包括获取京豆和消费京豆,设计到两张事实表。A表示获取京豆的事实表,B表示消费京豆的事实表。
需求:统计截止当日所有用户的剩余京豆的数量。
思路:需要关联两张事实表A.B,做一个聚合操作,事实表通常是比较大的,所以效率比较低。
-
多事务关联统计
需求:统计近30天用户从下单到支付的平均时间间隔。
思路:关联下单事实表和支付事实表,按照订单id进行join,支付时间减去下单时间,再求平均值。需要大表join大表,效率也会比较低。
周期快照事实表
周期性打快照,保存某一个表(mysql 中的表)的当前状态,通常是一个分区表,一天一个分区。直接同步现有的结果,从结果中拿数据。
典型指标:
- 存量型:如账户余额 商品库存等。业务系统中会有对应的此表,直接同步过来即可,以满足存量型指标的统计。
- 状态型:温度、形式速度等。变化的值通常是连续的,无法捕获原子事务操作,只能定期采样。
设计流程
确定粒度→确认事实
1.确定粒度
采样周期和维度确定粒度。
采样周期一般是天
维度是要统计的指标,例:统计每个仓库每种商品的库存。
这样就能确定粒度:每天的每个仓库的商品库存
2.确认事实
根据统计指标确定,如商品、仓库
事实类型
可加事实:可按照维度表进行累加。
半可加事实:只能按照一部分维度累加是有意义的,周期快照事实表都是半可加事实。 日期+仓库+商品维度 放的是存量信息 按照日期累加是没有意义的。
不可加事实:比率型事实。比率相加会超过1,但是比率不可能会超过1,一般要避免这种表的出现。可以把比率转换成分子和分母。
累积型快照事实表
基于一个业务流程的多个业务过程。
通常具有多个日期字段。数据不是一次性写完的,如下表
| 订单id | 用户id | 下单日期 | 支付日期 | 发货日期 | 确认收货日期 | 订单金额 | 支付金额 |
|---|---|---|---|---|---|---|---|
| 1001 | 1234 | 2020-06-14 | 2020-06-15 | 2020-06-16 | 2020-06-17 | 1000 | 1000 |
发货、收获日期等都是后来才写入的。主要是用户满足时间间隔需求,比如前文提到的平均时间。
设计流程
选择业务过程→ 确认粒度 →确认维度 → 确认事实
1.选择业务过程
对应了多个业务过程,例如上表中的下单-支付-发货-确认收货
2.确认粒度
事实表的一行的数据表示粒度
3.确认维度
与业务过程相关的维度,这里每个业务过程都有一个日期维度
4.确认事实
各业务过程的度量值,比如上表中的订单金额、支付金额。
维度表
事实表周围得一圈就是维度表,一个维度表得基本组成就是一个主键字段和各种维度字段。
设计步骤
确定维度表-> 确定主维表和相关维表->确定维度属性
- 确定维度表
与事实相关得维度都要确定。某些维度比较少,可以直接在事实表中增加字段。比如支付方式 只有微信、支付宝、银联等 可以在事实表中增加响应得字段。这个操作叫做维度退化
为什么要维度退化?找到如下的解释
因为简单的模式比复杂的更容易理解,也有更好的查询性能。
应该就是减少了join操作吧。
- 确定主维表和相关维表
主维表:
- 确定维度属性
就是确定维度表字段,维度属性就是主维表和相关维表的一些字段。
需要遵循以下需求:
- 尽可能多的维度属性
- 尽量不适用编码,使用文字说明,比如支付方式1表示支付宝,一般存储支付宝
- 某个经常用的维度属性可以提前拼接
设计要点
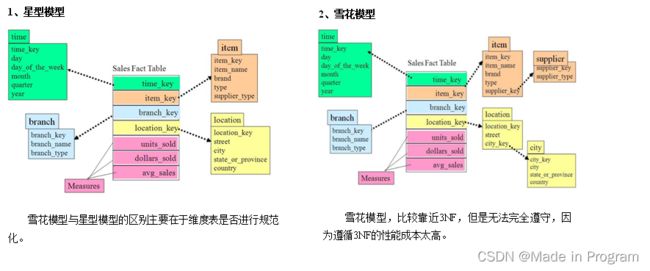
- 规范化 与反规范化
星型模型和雪花模型:区别就是对于维度表是否进行规范化设计
规范化设计得到的是雪花模型。比较接近范式建模,维度表会被拆分的比较细。
反规范化设计得到的是星型模型。
-
维度变化
维度会改变的,我们需要保存历史维度数据或者说是状态,有两种方法。全量快照表和拉链表
-
全量快照表
每天全量同步,保存一份维度数据。浪费点存储空间
-
拉链表
记录生命周期,状态改变了,就新增一条记录。如下表
-

节省了存储空间,比较适合与变化不大的维度表。如下表,手机号码变化不大,每天全量快照会浪费比较多的存储

缺点就是制作起来比较麻烦,在存储成本较低的今天,更多的是采用全量快照表的方式。
-
多值维度
一条记录对应多种维度,如一个订单对应多种商品,如何解决呢?
- 降低事实表的粒度,让一个订单对应一个商品项
- 事实表中增加字段,前提是维度个数固定
-
多值属性
维度表的某个属性有多个值,比如一个手机可以有 品牌、内存、CPU等属性
解决办法
- 将多值属性放到一个字段,用key value表示 “k1:v1,k2:v2”
- 将多值放到多个字段,前提是属性个数固定