盘一盘 Python 系列 - Cufflinks (下)

本文含 8890 字,37 图表截屏
建议阅读 46 分钟
0
引言
本文是 Python 系列的 Cufflinks 补充篇。整套 Python 盘一盘系列目录如下:
Python 入门篇 (上)
Python 入门篇 (下)
数组计算之 NumPy (上)
数组计算之 NumPy (下)
科学计算之 SciPy (上)
科学计算之 SciPy (下)
数据结构之 Pandas (上)
数据结构之 Pandas (下)
基本可视化之 Matplotlib
统计可视化之 Seaborn
炫酷可视化之 PyEcharts
交互可视化之 Cufflinks (上)
机器学习之 Sklearn
机学可视化之 Scikit-Plot
深度学习之 Keras (上)
深度学习之 Keras (中)
深度学习之 Keras (下)
Cufflinks 对于做数据分析的同学简直就是神器,可以让他们把注意力放在分析过程上,同时又能产出漂亮的可视图。
Cufflinks 可以不严谨的分解成 DataFrame、Figure 和 iplot,如下图所示:

其中
DataFrame:代表 pandas 的数据帧
Figure:代表可绘制图形,比如 bar、box、histogram 等等
iplot:代表绘制方法,其中有很多参数可进行配置,调节符合适当风格的可视图
由此可知,Cufflinks 直接在 DataFrame 上画图,而 DataFrame 是最基本的数据格式,因此很方便;Figure 只是设定图形,而 iplot 才真正的把图给画出来。
本贴结构如下,第一章解释 iplot() 函数的参数含义,当你明晰所有参数该怎么用时,你会发现用 Cufflinks 画图真的再简单不过了。第二章就“随意”画些图看看效果 (如以下视频所示)。
首先引入 Cufflinks 包,并设置离线模式画图。
import cufflinks as cf
cf.set_config_file(offline=True)
1
iplot 函数 API
用一个词形容 Cufflinks 的 API 就是优雅,所有绘图实现都写在一个函数 iplot() 里。查看其函数签名可用以下语句:
df = pd.DataFrame()
help(df.iplot)
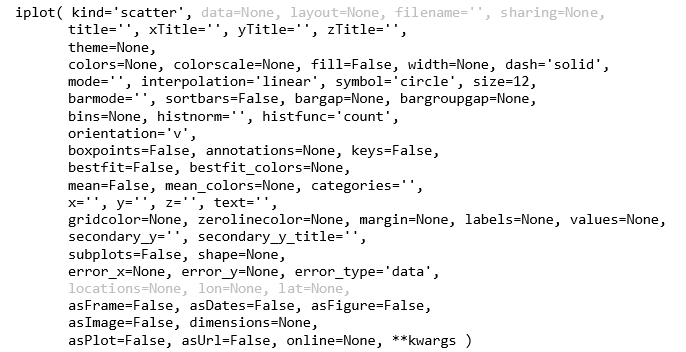
绘图函数 iplot()是一招鲜吃遍天,常用参数的解释如下。尽管内容枯燥,建议一定认真读完,细节在魔鬼,读得越细就能实现越精巧的图。
kind:字符串格式,用于设置图的种类,具体值包括
散点图 scatter、柱状图 bar、箱形图 box、差异图 spread、比率图 ratio、热力图 heatmap、平面图 surface、直方图 histogram、气泡图 bubble、三维气泡图 bubble3d、三维散点图 scatter3d、地理散点图 scattergeo、K线图 ohlc、蜡烛图 candle、饼状图 pie、地图 choroplet
title, xTitle, yTitle, zTitle:字符串格式,用于设置图表标题、x 轴、y 轴和 z 轴标题 (只适用 3D 图)
theme:字符串格式,用于设置主题风格,可用 cf.getThemes() 查看,具体值包括
ggplot, pearl, solar, space, white, polar, henanigans
colors:字典、列表或字符串格式,用于设置颜色
字典:{column:color} 按数据帧中的列标签设置颜色
列表:[color] 对每条轨迹按顺序的设置颜色
字符串:具体颜色的英文名称,适用于所有轨迹
colorscale:字符串格式,用于设置色阶,具体名称可用 cf.colors.scale() 查看,如下图所示。在颜色字符串前加 – 前缀可以反转色阶。举例 “accent” 和 “-accent” 的色阶顺序正好相反。

fill:布尔格式,用于填充轨迹 (trace) 和坐标轴之间的空白。
width:字典、列表或整数格式,用于设置轨迹宽度
字典:{column:value} 按数据帧中的列标签设置宽度
列表:[value] 对每条轨迹按顺序的设置宽度
整数:具体数值,适用于所有轨迹
dash:字典、列表或字符串格式,用于设置轨迹风格
字典:{column:value} 按数据帧中的列标签设置风格
列表:[value] 对每条轨迹按顺序的设置风格
字符串:具体风格的名称,适用于所有轨迹
具体选项有实线 solid、虚线 dash、虚点 dashdot、点 dot
mode:字典、列表或字符串格式,用于设置轨迹模式
字典:{column:value} 按数据帧中的列标签设置模式
列表:[value] 对每条轨迹按顺序的设置模式
字符串:具体模式的名称,适用于所有轨迹
具体选项有折线 lines、散点 markers、折线加散点 lines+markers、折线加文字lines+text、散点加文字 markers+text、折线加散点和文字 lines+markers+text
interpolation:字典、列表或字符串格式,用于设置插值方法
字典:{column:value} 按数据帧中的列标签设置插值方法
列表:[value] 对每条轨迹按顺序的设置插值方法
字符串:具体插值方法的名称,适用于所有轨迹
具体选项有线性 linear、三次样条 spline、 阶梯 hv 或 vh 或 vhv 或 hvh。
symbol:字典、列表或字符串格式,用于设置标记类型,仅当 mode 含 marker 才适用
字典:{column:value} 按数据帧中的列标签设置标记类型
列表:[value] 对每条轨迹按顺序的设置标记类型
字符串:具体标记类型的名称,适用于所有轨迹
具体选项有圆形 circle、圆形加点 circle-dot、菱形 diamond、方形 square 等。
size:字符串或整数格式,用于设置标记大小,仅当 mode 含 marker 才适用。
barmode:字符串格式,用于设置柱状类型,仅当 kind = bar 才适用,具体选项有分组 group、堆叠 stack、重叠 overlay。
sortbars:布尔格式,用于递减排列柱状,仅当 kind = bar 才适用。
bargap:浮点数格式,值在0和 1 之间,用于设置柱状的间隔,仅当 kind = bar 或 historgram 才适用。
bargroupgap:浮点数格式,值在 0和 1 之间,用于设置柱状分组的间隔,仅当 kind = bar 或 historgram 才适用。
bins:整数或元组格式,仅当 kind = historgram 才适用
整数:设置桶个数
元组:(start, end, size) 设置起始点、终止点、和桶的大小
histnorm:字符串格式,仅当 kind = historgram 才适用。具体选项有
频率 frequency (桶高等于计数)
百分比 percent (桶高等于每桶中计数占总数的比例)
概率 probability (桶高等于概率,桶宽为 1)
密度 density (桶高等于计数除以桶宽,使得桶面积加起来等于桶的总数)
概率密度 probability density (桶高等于概率除以桶宽,使得桶面积加起来等于 1)
histfunc:字符串格式,用于设置桶函数,仅当 kind = historgram 才适用。具体选项有计数函数 count、求和函数 sum、平均函数 avg、最小值函数 min、最大值函数 max。
orientation:字符串格式,用于设置形状的排放方式,h 代表水平 v 代表竖直,仅当 kind = bar 或 histogram 或 box 才适用
boxpoints:布尔或字符串格式,用于在箱形图中显示数据,仅当 kind = box 才适用,具体选项有离群值 outliers、全部 all、可疑离群值 suspectedoutliers、不显示False。
annotations:字典格式 {x_point: text},用于在点 x_point 上标注 text。
keys:列表格式,指定数据帧中的一组列标签用于排序。
bestfit:布尔或列表格式,用于拟合数据。
布尔:True 对所有列的数据都做拟合
列表:[columns] 对列表中包含列的数据做拟合
bestfit_colors:字典或列表格式,用于设定数据拟合线的颜色。
字典:{column:color} 按数据帧中的列标签设置颜色
列表:[color] 对每条轨迹按顺序的设置颜色
categories:字符串格式,数据帧中用于区分类别的列标签
x:字符串格式,数据帧中用于 x 轴变量的列标签
y:字符串格式,数据帧中用于 y 轴变量的列标签
z:字符串格式,数据帧中用于 z 轴变量的列标签 (只适用 3D 图)
text:字符串格式,数据帧用于显示文字的列标签
gridcolor:字符串格式,用于设定网格颜色
zerolinecolor:字符串格式,用于设定零线颜色
labels:字符串格式,将数据帧中的里列标签设为饼状图每块的标签,仅当 kind = pie 才适用。
values:字符串格式,将数据帧中的列数据的值设为饼状图每块的面积,仅当 kind = pie 才适用。
secondary_y:字符串格式,数据帧中用于第二个 y 轴变量的列标签
secondary_y_title:字符串格式,用于设置第二个 y 轴标题
subplots:布尔格式,如果 True 则画子图
shape:元组格式 (rows, cols),仅当 subplots= True 才适用,
error_x:整数或浮点数格式,用于设置 x 轴变量的误差值
error_y:整数或浮点数格式,用于设置 y 轴变量的误差值
error_type:字符串格式,用于设定误差条形的类型,具体选项有 data、constant、percent、sqrt、continuous、continuous_percent。
最后将图存成不同数据格式的布尔型参数:
asFrame:如果 True 则将图的成分存成序列
asDate:如果 True 则将时间存成 DatetimeIndex
asFigure:如果 True 则将图存成 Plotly 图格式
asImage:如果 True 则将图存成 PNG 格式
asPlot:如果 True 则将图在浏览器打开
asUrl:如果 True 则将返回网址 (online 模式) 或返回本地路径 (offline 模式)
其他参数 **kwargs 可以让图更个性化,比如 shape,subplots 等,这些在下节用具体例子来展示,读者一看就知道这些参数的效用了。
认真读参数含义!认真读参数含义!认真读参数含义!读完你就发现“诶,我怎么会用 Cufflinks 画各式各样的图了”。
2
用 iplot 画图
数据
首先用 YahooFinancials API 来下载四个股票的 2020 年到 2021年的最新数据,安装该 API 用一行代码:
pip install yahoofinancials
数据的描述如下
起始日:2020-01-01
终止日:2021-01-26
四只股票:FUTU、NIO、FUBO,DAO
下面代码就是从 API 获取数据:
该 API 返回结果 stock_daily 是「字典」格式,样子非常丑陋,将上面的「原始数据」转换成 DataFrame,代码如下:

第 3 行完全是为了 YahooFinancial 里面的输入格式准备的。如果 Asset 是加密货币,直接用其股票代码;如果 Asset 是汇率,一般参数写成 EURUSD 或 USDJPY
如果是 EURUSD,转换成 EURUSD=X
如果是 USDJPY,转换成 JPY=X
第 6 行定义好开盘价、收盘价、最低价和最高价的标签。
第 7 行获取出一个「字典」格式的数据。
第 8, 9 行用列表解析式 (list comprehension) 将日期和价格获取出来。
第 11 到 13 行定义一个 DataFrame
值为第 9 行得到的 price 列表
行标签为第 8 行得到的 index 列表
列标签为第 6 行定义好的 columns 列表
处理过后,将每个股票的收盘价合并成一个数据帧,打印其首尾三行得到:
df = pd.DataFrame()
for code in stock_code:
data = data_converter( stock_daily, code, 'EQ' )
df[code] = data['close']
df.index = pd.to_datetime(df.index)
df.head(3).append(df.tail(3))

接下来画图,代码简单到已经不需要额外文字解释了,对比着参数设置一下子就能找出图中相对应特征。
可视图
四只股票价格折线图,在 x 轴、y 轴和图上列出标题。
df.iplot( kind='line',
xTitle='日期',
yTitle='价格',
title='四只股票表现' )
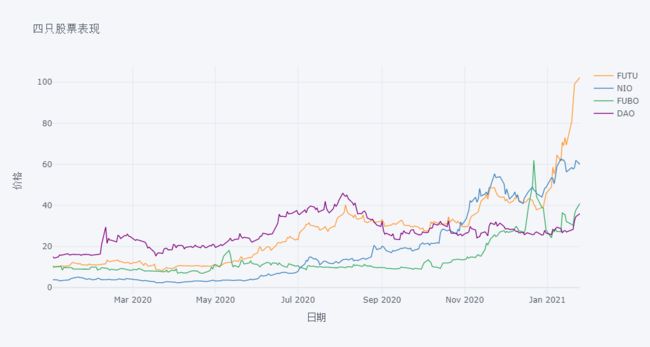
由于股票价格量纲不同,有时候多只股票放在一起比较效果很差,比如你加入 AMZN,大概 3200 多,这样那些价格只有几十的股票折线几乎像一条水平线。下面做了标准化,将起始日的价格设为 100,再进行比较。
df.div(df.iloc[0,:]).mul(100).iplot( kind='line',
xTitle='日期',
yTitle='标准化后价格',
title='四只股票表现' )

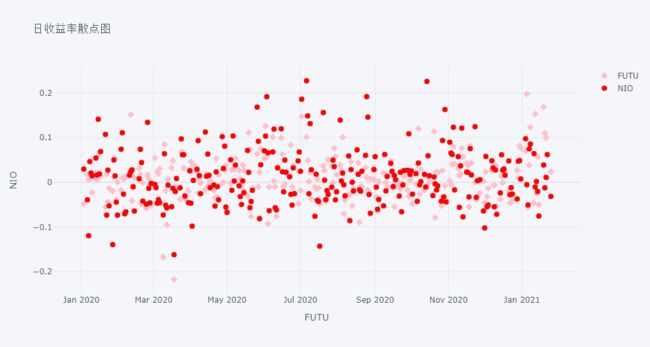
画 FUTU 和 NIO 日收益率的散点图。注意参数 color 和 symbol 的用法 (以字典个格式传入参数值)。
df[['FUTU','NIO']].pct_change().iplot(kind='scatter', mode='markers', size=8,
color={'FUTU':'pink', 'NIO':'red'},
symbol={'FUTU':'diamond', 'NIO':'circle'},
xTitle='FUTU', yTitle='NIO', title='日收益率散点图')
画 FUTU 和 NIO 价格的差异图。
df[['FUBO','NIO']].iplot(kind='spread',
xTitle='日期',
yTitle='价格',
title='FUBO 和 NIO 价格差异图')

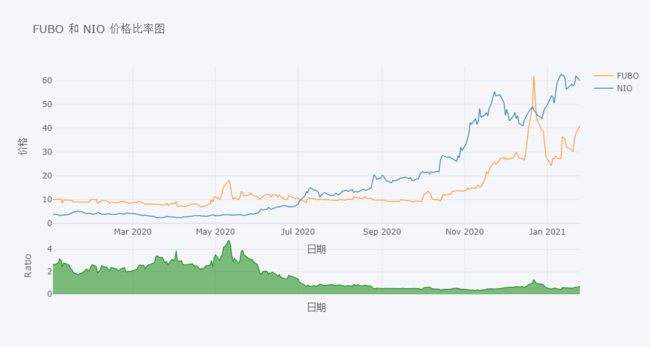
画 FUTU 和 NIO 价格的比率图。
df[['FUBO','NIO']].iplot(kind='ratio',
xTitle='日期',
yTitle='价格',
title='FUBO 和 NIO 价格比率图')
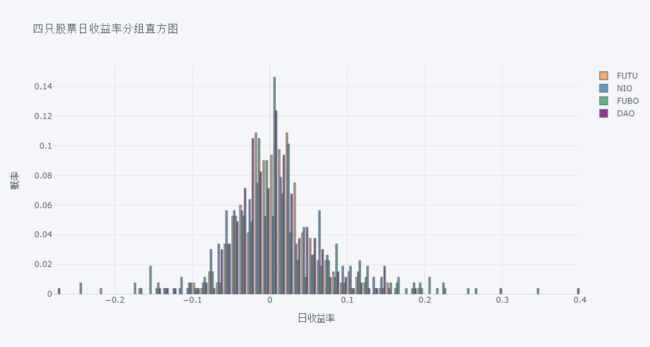
画四只股票日收益率的分组直方图。注意参数 barmode 和 histnorm 的用法。
df.pct_change().iplot(kind='histogram',
barmode='group', histnorm='probability',
xTitle='日收益率', yTitle='概率', title='四只股票日收益率分组直方图')
画四只股票日收益率的堆叠直方图。注意参数 barmode 设为 stack。
df.pct_change().iplot(kind='histogram',
barmode='stack',
xTitle='日收益率', yTitle='概率', title='四只股票日收益率堆叠直方图')

下面四图分别画四只股票日收益率的直箱形图,前三个都是竖直展示箱 (参数 orirentation ='v'),并展示全部数据点、只展示离群点,和只展示可疑离群点,最后一天按水平展示箱 (参数 orirentation ='h')。
df.pct_change().iplot(kind='box',
orientation='v', boxpoints='all',
xTitle='股票', yTitle='日收益率', title='四只股票日收益率箱形图')

df.pct_change().iplot(kind='box',
orientation='v', boxpoints='outliers',
xTitle='股票', yTitle='日收益率', title='四只股票日收益率箱形图')
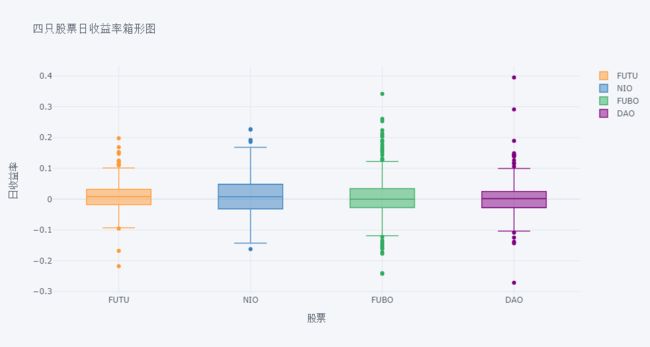
df.pct_change().iplot(kind='box',
orientation='v', boxpoints='suspectedoutliers',
xTitle='股票', yTitle='日收益率', title='四只股票日收益率箱形图')
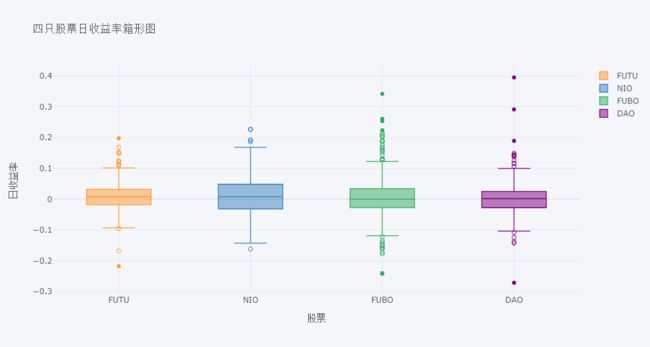
df.pct_change().iplot(kind='box',
orientation='h',
xTitle='日收益率', yTitle='股票', title='四只股票日收益率箱形图')

画四只股票按季度收益率的柱状图。按季度用 rsample('Q') 来分组;计算累计收益用 apply() 将 np.prod(1+x)-1 应用到每组中所有的数据。
df.pct_change().resample('Q').apply(lambda x: np.prod(1+x)-1).\
iplot(kind='bar',
xTitle='季度',
yTitle='收益率',
title='四只股票季度收益率柱状图')

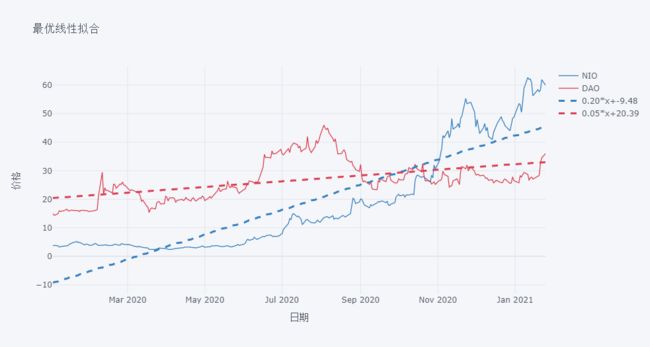
画 NIO 和 DAO 的折线+拟合图,只需设置 bestfit 为 True,此外还可用 colors 和 bestfit_colors 设置折线和拟合线的颜色。
df[['NIO','DAO']].iplot( kind='scatter',
bestfit=True,
colors=['blue','red'],
bestfit_colors=['blue','red'],
xTitle='日期', yTitle='价格', title='最优线性拟合' )
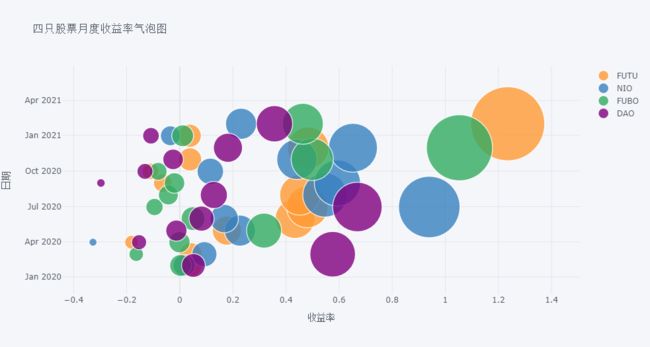
画图四只股票月收益率的气泡图。代码稍微有些复杂,但还是能一行流写出 (尽管有几个断行)。如何 resample 计算累计收益率前面已经讲了就不重复了,关键是先用 pd.melt() 将宽表变成长表,使其用三列 date, code 和 value,然后分别设为气泡的 x 轴数据、y 轴数据、和气泡大小。最后用 code 来区分不同股票的月收益率,即用不同颜色区分。
pd.melt( df.pct_change()
.resample('M')
.apply(lambda x: np.prod(1+x)-1)
.reset_index(), id_vars=['date'], var_name='code' )\
.iplot( kind='bubble',
x='value', y='date', size='value',
categories='code',
xTitle='收益率', yTitle='日期', title='四只股票月度收益率气泡图' )
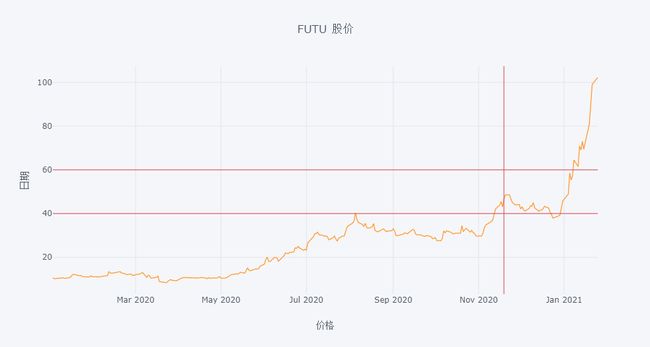
回顾上面 iplot() 函数签名中,还有 **kwargs 参数,比如添加水平线 (hline) 和竖直线 (vline)。
df[['FUTU']].iplot(hline=[40,60],
vline=['2020-11-19'],
xTitle='价格', yTitle='日期', title='FUTU 股价')
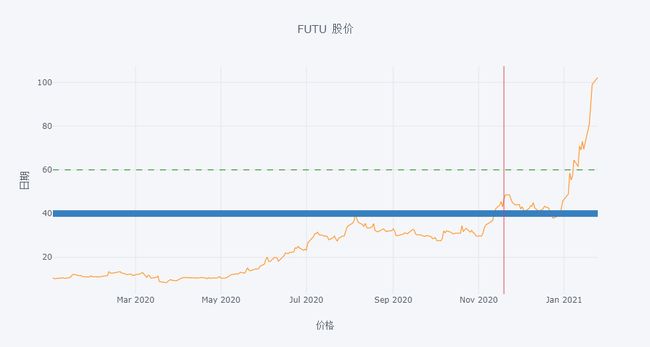
可用字典格式进一步设置水平线和竖直线的特征。
df[['FUTU']].iplot(hline=[dict(y=40,color='blue',width=10),
dict(y=60,color='green',dash='dash')],
vline=['2020-11-19'],
xTitle='价格', yTitle='日期', title='FUTU 股价')
同理,可添加水平块 (hspan) 和竖直块 (vspan)。
df[['FUTU']].iplot(hspan=[(40,60)],
vspan=[('2020-11-19','2021-01-01')],
xTitle='价格', yTitle='日期', title='FUTU 股价')
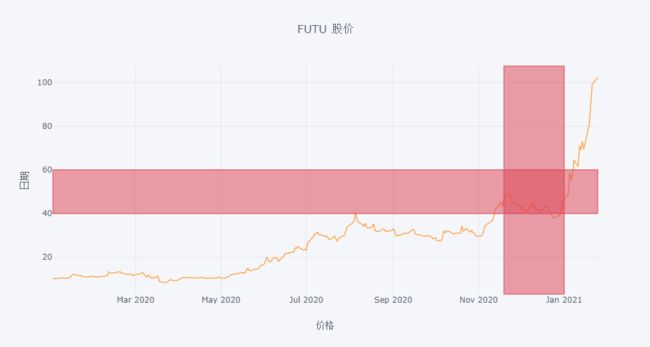
可用字典格式进一步设置水平块和竖直块的特征。
df[['FUTU']].iplot(hspan={'y0':40, 'y1':60, 'color':'black', 'fill':False},
vspan={'x0':'2020-11-19', 'x1':'2021-01-01', 'color':'blue', 'fill':True, 'opacity':0.2},
xTitle='价格', yTitle='日期', title='FUTU 股价')

画子图也可以实现,将 subplots 设为 True 即可。
df.iplot( subplots=True,
subplot_titles=True,
legend=False,
xTitle='日期', yTitle='价格', title='四只股票价格')

显式设定多图的布局也容易,用 shape 参数。
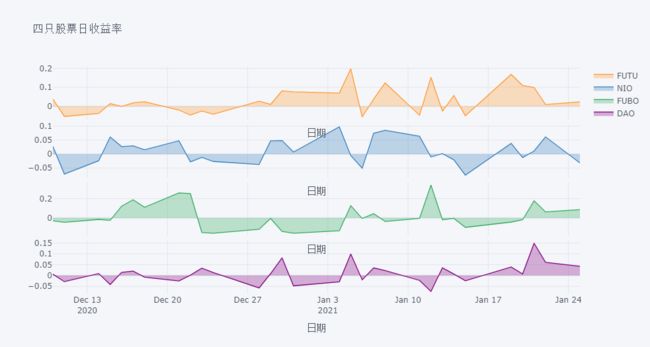
df.pct_change()[-30:].iplot( subplots=True,
shape=(4,1),
shared_xaxes=True,
vertical_spacing=.02,
fill=True,
xTitle='日期', title='四只股票日收益率')
如果多图的布局不规则怎么办?如果每个子图的类型不一样怎么办?
好办!分四步:
将具体的子图一个个按顺序放入 cf.figures() 里
创建布局,用 cf.tools.get_base_layout()
设定每个子图占布局的位置,用 cf.subplots() 并设置 specs
最后 cf.iplot() 画图即可


3
总结
Cufflinks 很简单,一行 iplot 流
Cufflinks 不简单,细节在魔鬼
熟读函数 API,很快能学会

Python 付费精品视频课
8 节 Python 数据分析 (NumPy/Pandas/Scipy) 课:
NumPy 上
NumPy 下
Pandas 上
Pandas 下
SciPy 上
SciPy 下
Pandas + 时间序列
Pandas + 高频数据
11 节 Python 基础课:
编程概览
元素型数据
容器型数据
流程控制:条件-循环-异常处理
函数上:低阶函数
函数下:高阶函数
类和对象:封装-继承-多态-组合
字符串专场:格式化和正则化
解析表达式:简约也简单
生成器和迭代器:简约不简单
装饰器:高端不简单
今年还会出 Python 三个系列:
数据可视化 (Matplotlib/Seaborn/Bokeh/Plotly/PyEcharts)
机器学习 (Scikit Learn/Scikit Plot)
深度学习 (Keras)