Apitest接口自动化脚本开发手册
文章目录
-
- 一、准备工作
-
- 准备测试执行环境
- 搭建框架开发环境(可选)
- 二、文件与配置
-
- 脚本目录结构
- 配置文件
-
- 全局配置
- 项目配置
- 用例脚本
-
- 脚本字段
- 三、脚本开发及本地运行
- 四、附录
-
- 脚本各字段使用方法详解
-
- ==No==
- ==run==
- ==group==
- ==desc==
- ==method==
- ==methodParam==
- ==url==
- ==checkpoint==
- ==save==
- ==headers==
- ==sleep==
- 五、独立功能
-
- 参数引用
- 内置函数
- 数据类型标识
- 启动命令行参数
未标注版本的工具使用最新版即可
一、准备工作
准备测试执行环境
- jre1.8(必须)+ 配置环境变量(可选)
- Cmder(可选,便于在windows环境使用命令行执行测试)
- Cmder官网
搭建框架开发环境(可选)
- jdk1.8(小版本随意)
- JDK1.8历史版本下载
- maven :安装maven,调整配置文件,设置本地库路径
- Maven下载
- Maven配置参考
- idea 社区版即可(安装mavenhelper、lombok插件)
- IntelliJ IDEA下载
- Idea如何安装插件
二、文件与配置
脚本目录结构

配置文件
全局配置
文件名 : GlobalConfig.xml
作用:设置所有项目通用的默认配置参数
<root>
<currentHost>mysqlcurrentHost>
<httpProxy enabled="false" ip="127.0.0.1" port="8888">httpProxy>
<logThreshold>infologThreshold>
<responseBody length="0">trueresponseBody>
<autoImportData>falseautoImportData>
<RunCases>RunCases-steamer-134.xmlRunCases>
<reportPublishServer ip="192.168.0.194" svcip="192.168.0.58" port="22" username="****" password="****" path="/home/yxd/report/html/">reportPublishServer>
<headers>
<header name="Content-Type" value="application/json;charset=UTF-8">header>
<header name="Accept" value="application/json, text/plain, */*">header>
headers>
<params>
params>
root>
- currentHost:待测系统默认数据库类型(只是用来决定使用哪种数据库驱动程序),该参数可以在脚本中通过指定使用哪个数据库实例而覆盖。
- httpProxy: http代理设置,设置为true时,会通过代理发送http请求(如fiddler,charles之类的工具开启的代理。用于跟踪调试请求数据包,执行环境如果没有开启代理则请求会失败)
- logThreshold:日志级别,枚举值。级别越低日志越详细。
- responseBody:日志是否显示请求返回体 设置为true时,可以额外设置展示日志最大长度,0为显示完整日志。
autoImportData : 测试执行前执行指定的SQL文件导入基础数据(历史功能现在没启用)- RunCases : 指定一个默认的项目用例配置文件,该参数可以通过启动时的命令行参数(run=文件名.xml)覆盖
- reportPublishServer : 用于发布测试报告的Nginx服务器地址,因为nginx是基于58容器云部署的,所以这里有两个IP,58是masterIP,194是nodeIp,账户名密码是用来登录node后通过ftp上传报告文件的。path是nginx的publish路径。 port是ftp端口,另有一个web访问端口是 32167,这是在创建nginx应用时设置的 (该功能属于与容器云系统绑定的功能,如脱离容器云需要另外部署docker_nginx容器以及K8S)
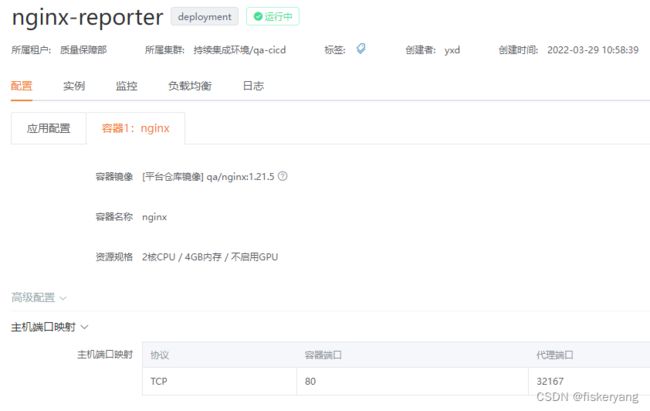
- headers : 公共请求头,脚本中所有HTTP请求都会默认带上这些请求头,可以在脚本中通过设置同名header覆盖此参数值
- params :全局参数,在此处设置的参数,可以在所有脚本中通过 ${参数名}来引用。可以在脚本中覆盖
项目配置
文件名 : RunCases-[项目名]-[环境标识].xml 如 RunCases-steamer-demo.xml
作用:针对具体项目设置项目中通用的配置参数(参数适用范围比全局的小)
<suite name="容器云冒烟测试">
<needMailReports>falseneedMailReports>
<reportMailTo>
[email protected]
reportMailTo>
<webhooks>
<webhook enabled="false" type="dingtalk">
https://oapi.dingtalk.com/robot/send?access_token=xxxxxxxx
webhook>
webhooks>
<project name="容器云" enabled="true">
<params>
<param name="rootUrl" value="http://192.168.0.134/">param>
<param name="loginUrl" value="http://192.168.0.134/api/user/signin">param>
<param name="username" value="xxx">param>
<param name="password" value="xxxxxx">param>
<param name="masterip" value="192.168.0.134">param>
<param name="master_username" value="xxx">param>
<param name="master_pwd" value="xxx">param>
<param name="node01_ip" value="192.168.0.135">param>
<param name="node01_username" value="xxx">param>
<param name="node01_pwd" value="xxx">param>
<param name="node02_ip" value="192.168.0.136">param>
<param name="node02_username" value="xxx">param>
<param name="node02_pwd" value="xxx">param>
params>
<dbs>
<db name="steamer">
<param name="dbHostPort" value="192.168.0.134:3306/steamer">param>
<param name="dbUsername" value="xxx">param>
<param name="dbPassword" value="xxxx">param>
db>
dbs>
<switchs>
switchs>
<cases priorityLevel="1">
<case enabled="true" casetype="function" name="资源管理" filepath="case/容器云/单接口/容器云_应用管理-lzq.xls" sheet="域名管理" priority="0">case>
<case enabled="true" casetype="function" name="资源管理" filepath="case/容器云/单接口/容器云_资源管理-lzq.xls" sheet="主机管理" priority="2">case>
<case enabled="true" casetype="function" name="资源管理" filepath="case/容器云/单接口/容器云_资源管理-lzq.xls" sheet="集群管理" priority="3">case>
<case enabled="true" casetype="function" name="资源管理" filepath="case/容器云/单接口/容器云_资源管理.xls" sheet="网络管理" priority="3">case>
<case enabled="true" casetype="function" name="资源管理" filepath="case/容器云/单接口/容器云_资源管理.xls" sheet="共享存储" priority="3">case>
cases>
project>
suite>
- suite : 当前测试套件的名称,会在测试报告中体现
- needMailReports:是否需要发送测试报告邮件
- reportMailTo : 测试报告发送对象,多个油箱使用分号分隔
- webhooks : 通过回调推送测试结果信息,这里存储的是回调地址
- enabled: 是否启用
- type:枚举值,暂时只支持dingtalk(钉钉机器人)
- project :项目信息配置
- name :项目名称(需要与case目录中的项目目录名称对应)
- enabled :是否启用
- params :项目参数,key-value结构,此处定义的参数可以在本项目脚本中使用${参数名}方式调用。当前配置文件样本主要是定义了一些系统访问路径,账户信息,以及容器云的主从服务器信息
- dbs : 数据库信息
- db : 数据库实例
- name : 数据库别名,该别名可以在脚本中引用,用于指定当前步骤使用哪个数据库
- param : 自定义参数
- name : dbHostPort(数据库连接字符串) 、 dbUsername(用户名) 、 dbPassword(密码)、dbType(数据库类型)
dbType字段说明 : 如这里不设置dbType则取全局文件中的currentHost,否则取当前字段值。 现在框架支持数据库类型为 mysql、postgresql- value : name对应的值
- switchs :用例开关,可通过case字段的属性(比如name,casetype等)控制case是否运行
- cases: 用例脚本配置
- priorityLevel : 用例执行优先级,取值为正整数,数值越小优先级越高。默认值为3,case的prioirty数值大于此数值将不会执行
- enabled : 是否启用
- casetype:用例类型,枚举值,支持 business和function
- name : 用例名称
- filepath : 用例脚本文件路径(excel格式)
- sheet :用例脚本文件的分页名称
- priority:用例优先级。与cases字段的 priorityLevel配合使用
注:除了suite、project、case之外,测试案例层级还有group和step,这两个层级会在脚本文件中体现
- group:用例分组,在这里我们将一组group相同的step定义为一个用例
- step:用例步骤,在接口测试中,一个step代表一次请求(http、ssh、sql、ftp)
用例脚本
用例脚本以Excel(*.xls)格式存储。 项目配置文件中的 case字段,定义了用例脚本的路径以及sheet页名称
<case enabled="true" casetype="function" name="资源管理" filepath="case/容器云/单接口/容器云_应用管理-lzq.xls" sheet="域名管理" priority="0">case>
脚本结构
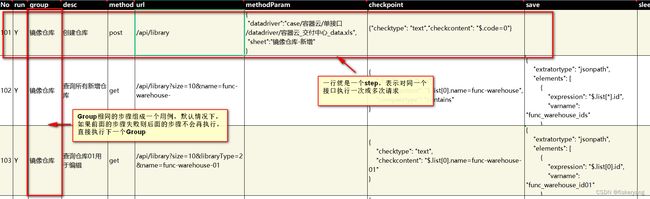
脚本字段
脚本字段使用方法详解
- No: 表示用例步骤的编号,必填
- run:用于控制该步骤是否执行,为 【Y】 时该用例才会被读取执行。选填
- group :用例的场景分组,group相同的几条步骤组成一个测试场景
- desc :该用例的描述,选填。一般可用于描述当前step的目的
- method:操作方法,查看支持的方法列表
- url:http请求步骤,此处为接口请求路径,如填入相对路径则会自动与配置文档中的rootUrl参数进行拼接,其他请求类型
- methodParam:此处表示操作方法的参数,参数格式根据实际的操作方法而定
- checkpoint:检查点,对接口返回的数据进行验证,这里只能输入Json格式的参数
- Save : 保存接口返回的动态数据,或者配合setvar方法保存自定义数据
- header : 存储当前接口的自定义请求头信息,如果GlobalConfig.xml中有相同key的头,则会优先取脚本中的值,这是一个jsonarray
格式 :[{“name”:“Content-Type”,“value”:“text/xml; charset=UTF-8”}]
注意,这里定义的头信息只有当前这一次请求生效- sleep : 表示执行当前步骤前等待时间。单位为毫秒。留空则为默认值300毫秒
三、脚本开发及本地运行
下面以容器云产品为例介绍脚本开发的过程 :
- 设计好接口测试用例场景,确定用例中需要使用接口及其参数和校验值;
- 在 \apitest.case.git\case\容器云 目录中新建一个xls文件(如果不是新模块的用例,可以编辑已有的脚本文件添加脚本步骤,然后直接跳到第5步执行)
- 按照脚本编写规则填写脚本驱动文件,保存。规则请参考这里
- 编辑项目配置文件,添加一个case节点,填入模块名,这里可以通过设置 priority、switch开关或case的enbled属性来控制用例的执行与否。
//例子
<case enabled="true" casetype="function" name="资源管理" filepath="case/容器云/单接口/容器云_应用管理-lzq.xls" sheet="域名管理" priority="0">case>
- 执行测试,可使用下面两种方式运行本地测试
-
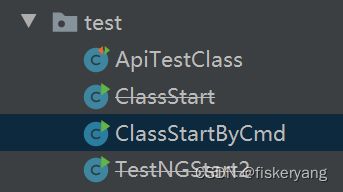
基于IDE执行测试
- 检查全局配置文件,确认默认的项目配置文件字段(RunCases)设置正确
- 找到 apitest.core.test.ClassStartByCmd 启动类,点击运行
-
脱离IDE环境独立执行
打开Cmder,进入jar包所在目录,执行以下命令java -jar apitest-1.0-SNAPSHOT-jar-with-dependencies.jar
-
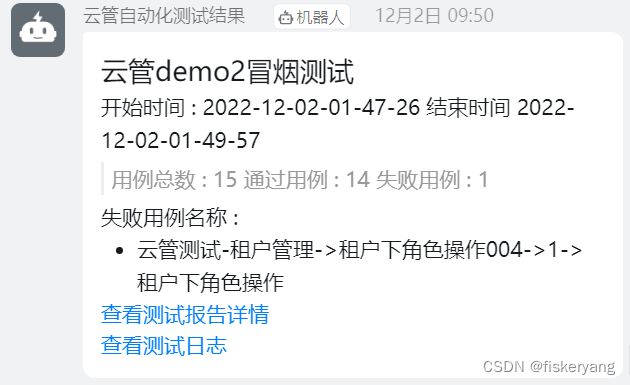
测试启动后,命令行日志信息如下图

测试完成后,会在\test-output\目录下生成HTML格式的测试报告以及ApiTestClass.log 日志文件

如配置并开启了webhook会在指定钉钉群中发送测试结果
四、附录
脚本各字段使用方法详解
No
用来表示步骤的编号,在一个Excel中建议唯一,该信息会在测试报告中展示(不唯一的话不会报错,但是在测试报告中会引起歧义,给定位异常造成麻烦)
run
标识该步骤是否执行,填入Y | y 时才会执行,留空或其他任何信息,都不会执行(这里是控制步骤是否执行的,与配置文件中的控制开关级别不一样)
group
步骤分组,group相同的步骤组成一个分组,一般用来表示一条测试案例,多个步骤从上至下顺序执行。
- 一种特殊的Group - 组名带有【数据恢复】这个词语,会在整个project的所有用例执行完后再集合一起执行,一般用于清理测试生成的脏数据。这种分组不会作为用例单位体现在测试数据统计中
这里需要注意如果有跨行步骤使用了相同的分组名,则会执行完所有同组步骤后再执行下一个分组的步骤。
desc
步骤描述,用于描述该步骤的操作目的,会在测试报告中展现
method
步骤执行的方法,框架中支持的方法如下:
- get: get请求,无参数
- post:post请求,参数
- 当 content-type = application/json 时使用Json对象
{"id":"${bizAttrId01}"} - 当 content-type = application/x-www-form-urlencoded :使用键值对,多个值用&分隔
注意,由于全局配置文件中设置了默认的content-type为json,所以这里需要在脚本中header列设置请求头a=1&b=2[{"name":"Content-Type","value":"application/x-www-form-urlencoded;charset=UTF-8"}]
- 当 content-type = application/json 时使用Json对象
- upload : post请求(上传文件专用),参数
- 当 content-type = multipart/form-data : 使用json对象,key为接口中定义,value为文件路径,使用内置函数__bodyfile(路径)引用
{"file": "__bodyfile(../apitest.case.git/assets/upload.txt)"}
- 当 content-type = multipart/form-data : 使用json对象,key为接口中定义,value为文件路径,使用内置函数__bodyfile(路径)引用
- put: put请求,参数为put请求的实际请求体Json
- delete : delete请求,参数为delete请求的实际请求体Json
- setvar : 设置参数的值 , 与Save字段配合使用。 持的参数来源为字符串和csv文件。支持的参数类型为
1. 字符串
2. 列表
3. 字典
保存的参数在后面的步骤中可通过 ${参数名} 引用-
参数为字符串型,
// 参数实例:实际保存的参数键值为 => var01=参数一 { "vartype":"string", "varname":"var01", "varvalue":"参数一" } -
参数为字符串型, 值为内置函数返回,
//实际保存的参数键值为 => beginTime1="yyyy-MM-dd HH:mm:ss" (当前的时间) { "vartype":"string", "varname":"beginTime1", "varvalue":"__now()" //内置函数 } -
参数为字符串型,同时保存多个参数,实际保存的参数键值为 =>
var01=value01 var02=value02 var03=当月的第一天 如 2022/08/01
参数名和值以 ## 分隔 如键和值的数量不等则会抛异常{ "vartype":"string", "varname":"var01##var02##var03", "varvalue":"value01##value02##__beginofmonth(yyyy/MM/dd)" } -
参数为列表,来源为字符串,实际保存的参数键值为 => var02=[101,102,103,104]
{ "vartype":"list", "varname":"var02", "varsource":"text", "varvalue":"101,102,103,104" } -
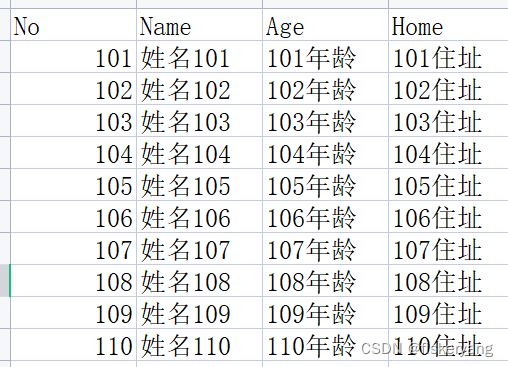
参数为列表,来源为csv文件.实际保存的参数键值为 => var03=[[第一行数组],[第二行数组],[第三行数组]…]
{ "vartype":"list", "varname":"var03", "varsource":"file", "filepath":"case/parameters/test1.csv" //驱动文件的相对路径,以下同 }test1.csv 文件内容如下:
-
参数为列表,来源为csv文件,指定列头提取。实际保存的参数键值为 => var04=[Name列的值组成的数组]
{ "vartype":"list", "varname":"var04", "varsource":"file", "filepath":"case/parameters/test1.csv", "headername":"Name" //指定列头 } -
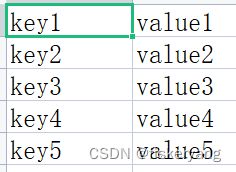
参数为字典,实际保存的参数键值为 => var05=map[key1=value1,key2=value2…]
{ "vartype":"map", "varname":"var05", "filepath":"case/parameters/test2.csv" }test2.csv 文件内容
-
- ssh : 执行ssh命令,参数为指定格式的Json。
// 参数实例 { "ip":"${masterip}", //此处为引用配置文件中设置的参数 "username":"${master_username}", "pwd":"${master_pwd}", "cmd":"kubectl get pod -A -o wide |grep volume-tester-1", "times":"3" //表示执行请求次数,默认为1 } - exesql : 执行非查询类SQL请求(insert、delete、update),参数为SQL语句,多个语句使用分号分隔
//参数实例 delete from auth_user where username like 'at-func-user%'; delete from auth_group where name like 'at-func-role%'; delete from auth_tenant where name like 'at-func-tenant%'; - exequery : 执行查询类SQL请求,主要使用场景是获取查询结果后,将结果保存为参数
//参数实例 select * from auth_tenant where `name`='at-func-tenant01' //save字段,可以对返回值进行提取,现在只支持取第一条数据。下面表示取字段为id信息保存到func_tenant_id参数 { "extratortype": "sql", "elements": [ { "expression": "id", "varname": "func_tenant_id" } ] } - login :登录专用方法,Post请求。与常规Post方法不同的是,login方法步骤会自动提取Cookie并保存到后续步骤的请求头中。 参数: 登录时发送的请求体
- iamlogin : iam登录专用方法。 与login方法不同的是,这是专用于Iam登录的方法(实际上是两部请求,先post请求到iam获取ticket后,再get请求对应系统的回调接口,并保存Cookie) 参数: 登录时发送的请求体
- mongodb: 执行MongoDB操作。参数为指定格式的Json对象
//collection: 对应的集合名,类似table //operate: 操作类型,find、insert、delete. find返回json;insert返回id;delete返回影响条数 //data: 为要insert的json数据 //filter: 过滤条件json数据, 相当于where // find样例 { "collection": "cmp_model_field", "operate": "find", "data": {}, "filter": { "code": "${fcode}" } } //delete样例 { "collection": "cmp_asset_model_group", "operate": "delete", "data": {}, "filter": { "code": "testgroup001" } } //insert样例 { "collection": "cmp_asset_model_group", "operate": "insert", "data": { "tenantId": "${t001id}", "code": "testgroup002", "name": "testgroup002", "editable": true, "index": 9999, "_class": "com.tiduyun.cmp.cmdb.model.entity.AssetModelGroup" }, "filter": {} }
methodParam
方法参数,除上面例子中提到的方法对应的参数之外,另有一类特殊的参数,可以用于支持使用指定外部数据驱动文件,循环执行当前步骤(可参数化某些指定字段)
使用条件 :
1. case项目配置文件中,当前case的 casetype=function
2. method为http请求(get,post,put,delete)
{ //datadriver 指定驱动文件(*.xls)的相对路径
"datadriver":"case/容器云/单接口/datadriver/容器云_资源管理_data.xls",
// 驱动文件的sheet页名
"sheet":"集群管理-新增"
}
驱动文件格式:分为左右两个部分,如下图所示。
- 左侧列头支持的字段为 no | run | desc | url | checkpoint | save 字段可自由组合,这些字段与父脚本中含义相同,提供了列头则会覆盖父脚本中的对应字段值。不提供则会直接使用父脚本中的值。(一般来说 No、desc、checkpoint、save这几个是需要提供的)
- 右侧列头为请求体(Json格式)摊平后生成的横向二维表,列头为json的字段,下面数据为每次请求发送的请求体(注意这里只摊平一层,第二层及以下的字段仍然是Json对象的 需要将整个Json对象一起存放到单元格内)

通过这种方式定义的测试步骤,测试执行时框架会先读取步骤信息覆盖父脚本对应字段的值,然后将其余字段拼接成Json请求体,按行逐一执行请求。实现参数化数据驱动的功能。
url
请求的路径,只有http或sql请求才需要输入该项,支持输入相对路径或绝对路径
- 相对路径 : 自动和配置文件中的host字段的值拼接
- 绝对路径 : 直接取该路径
- 当method为exesql或exequery时,该字段填入项目配置文件中的db name (为支持多数据库而设计)

checkpoint
检查点(断言)。参数为Json, 各字段描述如下
- checktype : 检查点类型,枚举值
- text:(默认值) : 校验文本值是否符合期望
- count : 校验返回信息中指定关键字的出现数量
- file : 校验文件的相关信息,如文件存在、文件大小、文件内容等
- sql :使用查询sql校验(只支持校验返回的第一行数据)
- extratortype : 提取器类型,枚举值。
- jsonpath:默认值。 jsonpath提取器,用于在json格式的返回信息中提取信息
- regex : 正则表达式提取器 ,用于在非结构化的文本信息中提取信息
- xpath:xpath提取器 ,用于在xml| html信息中提取信息
- checkcontent : 检查内容。此项根据不同的checktype和extratortype,输入格式也不同。
- checktype=text :
- 1.1 extratortype = jsonpath , 输入格式为 key1=value1;key2=value2 多个值使用分号分割其中key为jsonpath路径,value为期望值
{ // extratortype默认值为 jsonpath,所以这里不提供该字段不影响使用 "checktype": "text", "checkcontent": "$.message=为用户授权成功;$.code=0" } - 1.2 extratortype = regex,输入格式为Json数组,数组每个元素包含以下几个字段
// 该参数表示 使用正则提取器,期望提取到的值 大于等于 1 。 如断言失败,则每十秒重试一次,一共重试三次。三次都失败,则抛出断言失败 { "checktype": "text", "extratortype": "regex", "checkcontent": [ { "key": "(?:Running|CrashLoopBackOff) +?(\\d.*?) ", //正则表达式 "value": "1", "operator":">=" } ], "onerror": "retry", "retryinterval": "10" //重试间隔 单位为秒 retrycount 重试次数 默认为3次 }operator : 比较操作符 ,支持 > 、 < 、 <= 、 >= 、 = 、<> 、 between 七种操作符,
1. 操作符为between时,value可不填,但是需要提供min和max两个参数
2. =与<> 可以支持字符串与整数比较,其他操作符只支持整数比较 - 1.3 extratortype = wholeword , 直接比较请求返回值与checkcontent。
- 1.1 extratortype = jsonpath , 输入格式为 key1=value1;key2=value2 多个值使用分号分割其中key为jsonpath路径,value为期望值
- checktype = count (数量校验现在只支持正则提取器)
//count样例,该参数表示,使用正则表达式 (Running) 来匹配请求的返回值,匹配到的次数期望值为 大于等于4 { "checktype": "count", "extratortype": "regex", "checkcontent": [ { "key": "(Running)", //正则表达式 "value": "4", //期望匹配次数 "operator": ">=" //比较操作符 } ] } - checktype = file 用于校验指定路径的文件是否存在,此时checkcontent保存的是期望文件的相对路径
{ "checktype": "file", "checkcontent": "download/${func_imagedownload_filename01}", "onerror": "retry", "retryinterval": "5" } - checktype = sql 此时checkcontent可以支持输入json对象或者json数组,json对象的字段为 field 和 value
//sql样例,该参数表示 从指定的db中使用sql查询值,然后校验返回的第一条数据 两个指定字段的值 //1、checkcontent中记录字段和期望值,为jsonarray //2、只校验sqlstatement查询出来的第一行数据 //3、需要指定dbalias(数据库别名) { "checktype": "sql", "sqlstatement": "select * from auth_tenant where `name`='at-func-tenant01'", "checkcontent": [ { "field": "name", "value": "at-func-tenant01" }, { "field": "description", "value": "111111" } ], "dbalias": "steamer" } - checktype=text :
- comparetype : 比较方式,枚举值
- equals 等于 (默认值)
- contains : 包含 ,意思是实际值包含期望值即可
{ "checktype": "text", "checkcontent": "$.message=2-50个字符", "comparetype": "contains" }
- isany : 是否任意匹配,布尔值字符串 (任意匹配只支持Jsonpath提取器)
- false : 非任意匹配(默认值)
- true : 任意匹配。 当提取出的值列表元素数量大于1时,isany标识是否只要列表中任意元素与期望值匹配则为成功 (使用场景:当请求返回的值为列表并且无法确定希望匹配的值)
{ "checktype": "text", "checkcontent": "$.list[*].name=autotest-tenant-func01", //$.list[*].name这个jsonpath返回的是一个列表 "isany": "true" }
- onerror : 异常处理,枚举值
- throw : 抛出断言失败异常 (默认值)
这里需要注意的是,一个Group中有多个步骤,如果前置步骤抛出了断言失败,则该Group后续的步骤均不会执行 - retry : 重试请求,需提供两个额外参数
- 2.1 retrycount : 重试次数 默认为3
- 2.2 retryinterval : 重试间隔,默认为1 ,单位为秒
- skip : 忽略异常,不报断言失败,只会在日志里记录异常
- throw : 抛出断言失败异常 (默认值)
save
save字段有两种使用场景
- 将当前步骤返回的值保存为参数。后续步骤可通过 ${参数名} 调用。参数如下
- extratortype 提取器类型,枚举值。必填
-
jsonpath (不提供extratortype,则取默认值jsonpath)
-
regex
-
sql
-
- elements 需要保存的参数(支持多个,所以这里是个JsonArray),数组的每个元素对象字段如下
- expression : 表达式 必填,根据extratortype 提供jsonpath 或 正则表达式
- varname : 变量名称 ,必填(自定义名称,同project内同名变量会覆盖)
- group : 分组标识,选填,regex 专用,用于指定提取匹配到的第几个分组,默认为1 (也就是表达式中第几个小括号内的匹配值)
- index:索引,选填
-
- extratortype为regex时,用于指定提取匹配到的第几个元素,默认为0
-
- extratortype为jsonpath,并且返回的json为数组时,可以指定提取第几个元素,如果不提供index则保存整个json数组
-
- varsource :指示从何处提取,支持 header和 body,默认值为body(header只支持通过regex提取)
- headerkey : varsource为header时,需指定headerkey (实例参考)
- 实例:
- 3.1 Jsonpath保存列表
//将expression提取的值保存到名为func_user_ids的参数中,此时保存的参数是一个列表 { "extratortype": "jsonpath", "elements": [ { "expression": "$.list[*].id", "varname": "func_user_ids" } ] } - 3.2 Jsonpath保存单个值
//将expression提取的值保存到名为 func_app_id01的参数中,此时保存的参数是一个字符串 { "extratortype": "jsonpath", "elements": [ { "expression": "$.list[0].id", "varname": "func_app_id01" } ] } - 3.3 jsonpath 一次保存多个参数
//一次保存多个参数 { "extratortype": "jsonpath", "elements": [ { "expression": "$.list[0].id", "varname": "func_app_id01" }, { "expression": "$.list[0].name", "varname": "func_app_name01" } ] } - 3.4 Jsonpath 从列表中保存指定索引的值
//注意这里json表达式提取到的值为列表, 并且指定了索引为0,所以保存的是第一个元素的值,如不指定索引,则保存整个列表 { "extratortype": "jsonpath", "elements": [ { "expression": "$.data[?(@.tenantName=='DEMO租户')].tenantId", "varname": "tenantId", "index": 0 } ] } - 3.5 正则提取
//从行首开始取到第一个空格的字符串。场景是获取kubectl命令返回的namespace { "extratortype": "regex", "elements": [ { "expression": "^(.+?) ", "varname": "healthyck1_namespace" } ] } - 3.6 正则提取
//group : 标示取匹配的第几个分组,默认为1(第一个分组小括号里的内容)类似于jmeter里的【模板 】 //index : 标示取匹配到的第几个值,默认为0 ,类似于jmeter里的匹配数字,但是没有随机取值功能 { "extratortype": "regex", "elements": [ { "expression": "^(.+?) ", "varname": "namespace" }, { "expression": " (volume-tester-1.+?) ", "varname": "podname", "group": 1, //group默认为1 ,这里可不提供此字段 "index": 1 // index默认为0,这里必须显式声明index } ] } - 3.7 正则提取,指定varsource
//varsource : 标示用来匹配的字符串是body还是header,默认为body,如果是header则还需要指定 headerkey,框架会把指定key的value全部提取出来,拼接成以##分隔的字符串后再用正则匹配提取 //headerkey : varsource为header时,需指定headerkey { "extratortype": "regex", "elements": [ { "expression": "DUBHE-ADMIN-TOKEN=(.+?);", "varname": "token", "varsource": "header", "headerkey": "Set-Cookie" } ] } - 3.8 SQL提取
// 其他字段设置 1、method为exeQuery 2、methodParam中填入sql脚本。比如select * from auth_tenant where `name`='at-func-tenant01' //通过sql查询保存参数,可以将sql返回的第一行数据的多个字段保存为多个参数,除第一行外,其他数据将被舍弃 { "extratortype": "sql", "elements": [ { "expression": "id", "varname": "func_tenant_id" } ] }
- 3.1 Jsonpath保存列表
- extratortype 提取器类型,枚举值。必填
- 配合 setvar方法,直接保存静态变量( setvar 具体使用方法请看上面的方法介绍
headers
指定请求头,同名header会覆盖配置文件中定义的值。
//样例
[{"name":"Content-Type","value":"application/x-www-form-urlencoded;charset=UTF-8"}]
//upload头样例
[
{
"name": "Content-Type",
"value": "multipart/form-data;boundary=----WebKitFormBoundaryTSncv9iAn3oKxb7K"
},
{
"name":"size", // 这个header是容器云自定义的
"value":8
}
]
sleep
休眠时间 表示执行请求后等待多长时间再执行下一步,单位是毫秒,默认为300
五、独立功能
参数引用
对于前面步骤中已经保存的参数,可以通过 ${参数名} 方式引用,在url、methodParam 、checkpoint、save、headers字段中均可以用
注意:如果methodParam中,比如接口的body中本身就带有 ${参数名} 一类的字符,需要在外面使用标识符包裹起来 例如有这样一个body:
{
"param":"${param1}",
"name":"tom"
}
为避免脚本执行时框架去解析这个参数,需要如下处理
{
"param":"${param1}",
"name":"tom"
}
内置函数
框架内置了一些函数,可以通过 __函数名(参数) 的形式来引用。
- randomText : 生成指定长度的文本
参数1 - 长度,默认为6
参数2 - 是否为纯数字,默认为false - urlencode : 对参数进行url编码
参数1 - 需要进行编码的字符串 - today : 获取今天的日期信息
参数1 - 指定的日期格式 ,默认为 yyyy-MM-dd - yesterday : 获取昨天的日期信息
参数1 - 指定的日期格式 ,默认为 yyyy-MM-dd - beginofyear : 获取今年第一天的日期
参数1 - 指定的日期格式 ,默认为 yyyy-MM-dd - endofyear : 获取今年最后一天的日期
参数1 - 指定的日期格式 ,默认为 yyyy-MM-dd - beginofmonth : 获取本月第一天的日期
参数1 - 指定的日期格式 ,默认为 yyyy-MM-dd - endofmonth : 获取本月最后一天的日期
参数1 - 指定的日期格式 ,默认为 yyyy-MM-dd - thismonth : 获取本月的月份
参数1 - 指定的日期格式 ,默认为 yyyy-MM - lastmonth : 获取上个月的月份
参数1 - 指定的日期格式 ,默认为 yyyy-MM - now : 获取当前时间,
无参数。时间格式固定为 yyyy-MM-dd HH:mm:ss - base64encode : base64编码
参数1 - 待编码的字符串 - base64decode : base64解码
参数1 - 待解码的字符串 - md5 : md5加密
参数1 - 待加密的字符串 - uuid : 随机生成uuid
无参数 - escape : escape编码
参数1 - 待编码的字符串 - unescape : unescape解码
参数1 - 待解码的字符串 - __bodyfile : 引用文件路径,一般用于配合upload方法,指定上传附件
样例:
__randomText() : 生成6位长度的随机字符与数字混合的文本
__randomText(20):生成20位长度的随机字符与数字混合的文本
__randomText(8,true): 生成8位长度的纯数字文本
__urlEncode(你好) : 生成对【你好】进行编码后的文本【%E4%BD%A0%E5%A5%BD】
__today() : 生成今日的日期 2021-11-08
__today(yyyy/MM/dd) : 生成今日的日期 2021/11/08
__yesterday() : 2021-11-07
__beginofyear() : 2021-01-01
__endofyear() : 2021-12-31
__beginofmonth() : 2021-11-01
__endofmonth() : 2021-11-30
__thismonth() : 2021-11
__lastmonth() : 2021-10
__now() : 2021-11-08 15:32:33
__base64encode(阿萨德) 输出 :6Zi/6JCo5b63
__base64decode(6Zi/6JCo5b63) 输出 : 阿萨德
__md5(123456) 输出 : e10adc3949ba59abbe56e057f20f883e
__uuid() 输出 : 9854b6ba-c6a6-41d2-bbf2-9b861cc93122
__escape(<script>alert('hello world')</script>) 输出 : %3cscript%3ealert%28%27hello%20world%27%29%3c/script%3e
__unescape(%3cscript%3ealert%28%27hello%20world%27%29%3c/script%3e)输出 : <script>alert('hello world')</script>
保存函数生成的值为参数 : 如需将函数生成的数据保存为参数,则只需在函数后添加 @参数名@ 即可
__randomText(10,true)@num1@
数据类型标识
二级数据驱动文件是根据字段名动态拼接Json对象的,对于某些字段的值不是单纯的字符串格式,需要使用特殊标识表示出来。 比如 {“age”:18} 这个请求体,存储在excel单元格中无法指定字段类型,框架读取后生成的实际请求体为 {“age”:“18”},发送请求后可能会导致异常。所以需要在单元格中把数据类型标识出来
标识类型 :
- num## : 表示标识符后面的字符为纯数字
num##100 : 表示该字段为数值型,值为100
- raw## :
- 标识符后面第一个字符为【{】 则表示该字段为Json对象
- 标识符后面第一个字符为【[】 则表示该字段为Json数组
- 标识符后面接null,表示该字段为null
- 标识符后面为空,表示请求体将不包含此字段
raw##{"key":"name","value":"leo"} // 表示该字段为Json对象 raw##[{"key":"name","value":"leo"},{"key":"age","value":20}] // 表示该字段为Json数组 raw##null // 表示该字段为null raw## // 表示请求体将不包含此字段(模拟缺少字段时的用例)
启动命令行参数
框架支持以下几种运行时参数,可用于在命令行启动测试时,自定义某些参数的值
这些参数一般都是在持续集成环境下使用命令行启动测试时才需要使用
- run :指定项目配置文件。 在全局配置文件中有一个字段是用于定义默认的项目配置文件的。执行时可通过 run 参数来覆盖此参数。达到执行运行项目的目的 。
- needmail : 是否需要通过邮件发送测试报告。 加上此参数则表示该值设置为true
#实例 :
java -jar apitest.jar needmail run=RunCases-steamer-new.xml
- casepath : 指定用例的根目录名称。由于框架和用例项目在jenkins里是两个独立的目录。用例项目的workspace都是创建Job时自定义的。所以这里需要给框架提供用例项目的根目录名称。用于定位脚本路径。
#实例 这里定义的casepath 是根据jenkins中的job名而定的。也就是该job的workspace目录名称
java -jar apitest.jar casepath=apitest.case.git-steam
- webhook: 设置此参数后,将强制把配置文件中所有的webhook字段的enabled属性设置为true
#实例 :
java -jar apitest.jar webhook run=RunCases-steamer-new.xml