【腾讯云 HAI域探秘】完蛋,我被LLM包围了(基于HAI+ChatGLM-6B+CloudStudio)
一、背景介绍1.1 ChatGPT and ChatGLM-6B
ChatGPT(全名:Chat Generative Pre-trained Transformer),是OpenAI研发的一款聊天机器人程序,于2022年11月30日发布。ChatGPT是人工智能技术驱动的自然语言处理工具,它能够基于在预训练阶段所见的模式和统计规律,来生成回答,还能根据聊天的上下文进行互动,真正像人类一样来聊天交流,甚至能完成撰写邮件、视频脚本、文案、翻译、代码,写论文等任务。
但是自己想要部署一套ChatGPT的话,首先数据集没有开源,其次对于硬件的要求,不可估量。所幸清华大学知识工程和数据挖掘小组(Knowledge Engineering Group (KEG) & Data Mining at Tsinghua University)发布的一个开源的对话机器人ChatGLM-6B。
ChatGLM 参考了 ChatGPT 的设计思路,在千亿基座模型 GLM-130B 中注入了代码预训练,通过有监督微调(Supervised Fine-Tuning)等技术实现人类意图对齐。ChatGLM 当前版本模型的能力提升主要来源于独特的千亿基座模型 GLM-130B。它是不同于 BERT、GPT-3 以及 T5 的架构,是一个包含多目标函数的自回归预训练模型。2022年8月,我们向研究界和工业界开放了拥有1300亿参数的中英双语稠密模型 GLM-130B,该模型有一些独特的优势:
-
双语: 同时支持中文和英文。
-
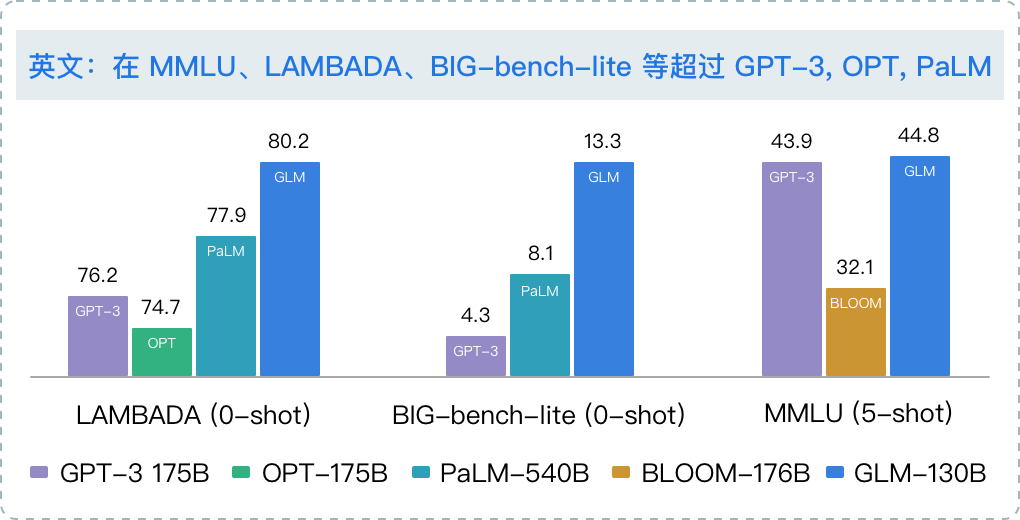
高精度(英文): 在公开的英文自然语言榜单 LAMBADA、MMLU 和 Big-bench-lite 上优于 GPT-3 175B(API: davinci,基座模型)、OPT-175B 和 BLOOM-176B。
-
高精度(中文): 在7个零样本 CLUE 数据集和5个零样本 FewCLUE 数据集上明显优于 ERNIE TITAN 3.0 260B 和 YUAN 1.0-245B。
-
快速推理: 首个实现 INT4 量化的千亿模型,支持用一台 4 卡 3090 或 8 卡 2080Ti 服务器进行快速且基本无损推理。
-
可复现性: 所有结果(超过 30 个任务)均可通过我们的开源代码和模型参数复现。
-
跨平台: 支持在国产的海光 DCU、华为昇腾 910 和申威处理器及美国的英伟达芯片上进行训练与推理。
2022年11月,斯坦福大学大模型中心对全球30个主流大模型进行了全方位的评测,GLM-130B 是亚洲唯一入选的大模型。在与 OpenAI、谷歌大脑、微软、英伟达、脸书的各大模型对比中,评测报告显示 GLM-130B 在准确性和恶意性指标上与 GPT-3 175B (davinci) 接近或持平,鲁棒性和校准误差在所有千亿规模的基座大模型(作为公平对比,只对比无指令提示微调模型)中表现不错(下图)。

图1. 斯坦福大学基础模型中心对全球 30 个大模型的评测结果(2022年11月)
关于 GLM-130B 的学术文章已被国际深度学习会议 ICLR'23 接收。自2022年8月开放以来,收到53个国家369个研究机构(截至2023年2月1日)的下载使用需求,包括谷歌、微软、脸书、AI2、华为、阿里巴巴、百度、腾讯、头条、小冰、小度、小米以及斯坦福、麻省理工、伯克利、卡耐基梅隆、哈佛、剑桥、牛津、北大、浙大、上交、复旦、中科大、国科大等国内外人工智能研究机构和高校。

通过使用与 ChatGLM(chatglm.cn)相同的技术,ChatGLM-6B 初具中文问答和对话功能,并支持在单张 2080Ti 上进行推理使用。具体来说,ChatGLM-6B 有如下特点:
-
充分的中英双语预训练: ChatGLM-6B 在 1:1 比例的中英语料上训练了 1T 的 token 量,兼具双语能力。
-
优化的模型架构和大小: 吸取 GLM-130B 训练经验,修正了二维 RoPE 位置编码实现,使用传统FFN结构。6B(62亿)的参数大小,也使得研究者和个人开发者自己微调和部署 ChatGLM-6B 成为可能。
-
较低的部署门槛: FP16 半精度下,ChatGLM-6B 需要至少 13GB 的显存进行推理,结合模型量化技术,这一需求可以进一步降低到 10GB(INT8) 和 6GB(INT4), 使得 ChatGLM-6B 可以部署在消费级显卡上。
-
更长的序列长度: 相比 GLM-10B(序列长度1024),ChatGLM-6B 序列长度达 2048,支持更长对话和应用。
-
人类意图对齐训练: 使用了监督微调(Supervised Fine-Tuning)、反馈自助(Feedback Bootstrap)、人类反馈强化学习(Reinforcement Learning from Human Feedback) 等方式,使模型初具理解人类指令意图的能力。输出格式为 markdown,方便展示。
因此,ChatGLM-6B 具备了一定条件下较好的对话与问答能力。当然,ChatGLM-6B 也有相当多已知的局限和不足:
-
模型容量较小: 6B 的小容量,决定了其相对较弱的模型记忆和语言能力。在面对许多事实性知识任务时,ChatGLM-6B 可能会生成不正确的信息;她也不擅长逻辑类问题(如数学、编程)的解答。
-
可能会产生有害说明或有偏见的内容:ChatGLM-6B 只是一个初步与人类意图对齐的语言模型,可能会生成有害、有偏见的内容。
-
较弱的多轮对话能力:ChatGLM-6B 的上下文理解能力还不够充分,在面对长答案生成,以及多轮对话的场景时,可能会出现上下文丢失和理解错误的情况。
-
英文能力不足:训练时使用的指示大部分都是中文的,只有一小部分指示是英文的。因此在使用英文指示时,回复的质量可能不如中文指示的回复,甚至与中文指示下的回复矛盾。
-
易被误导:ChatGLM-6B 的“自我认知”可能存在问题,很容易被误导并产生错误的言论。例如当前版本模型在被误导的情况下,会在自我认知上发生偏差。即使该模型经过了1万亿标识符(token)左右的双语预训练,并且进行了指令微调和人类反馈强化学习(RLHF),但是因为模型容量较小,所以在某些指示下可能会产生有误导性的内容。
二、腾讯云HAI背景介绍
高性能应用服务 HAI:澎湃算力,即开即用。以应用为中心,匹配GPU云算力资源,助力中小企业及开发者快速部署LLM、AI作画、数据科学等高性能应用。是为开发者量身打造的澎湃算力平台。无需复杂配置,便可享受即开即用的GPU云服务体验。在 HAI 中,根据应用智能匹配并推选出最适合的GPU算力资源,以确保您在数据科学、LLM、AI作画等高性能应用中获得最佳性价比。
HAI 服务优势
智能选型 :根据应用匹配推选GPU算力资源,实现最高性价比。同时,打通必备云服务组件,大幅简化云服务配置流程。
一键部署 :分钟级自动构建LLM、AI作画等应用环境。提供多种预装模型环境,包含如StableDiffusion、ChatGLM等热门模型。
可视化界面 :友好的图形界面,AI调试更为简单
即插即用 · 轻松上手
基于腾讯云GPU云服务器底层算力,提供即插即用的高性能云服务。
智能选型
根据应用匹配推选GPU算力资源,实现最高性价比。同时,打通必备云服务组件,大幅简化云服务配置流程。
一键部署
分钟级自动构建LLM、AI作画等应用环境。提供多种预装模型环境,包含如StableDiffusion、ChatGLM等热门模型。
可视化界面
提供开发者友好的图形界面,支持jupyterlab、webui等多种算力连接方式,AI研究调试超低门槛。
横向对比 · 青出于蓝
大幅降低GPU云服务器使用门槛,多角度优化产品使用体验,开箱即用

应用场景
AI作画(视觉设计、游戏)

基于StableDiffusion开源模型进行AI绘画
场景介绍
AI绘画是一种利用深度学习算法进行创作的绘图方式。广泛应用于数字媒体、游戏、动画、电影、广告等领域。
业务痛点
-
GPU卡型多样,算力、显存差异大,选型困难
-
环境配置复杂、模型安装和调试门槛高
-
各类插件迭代频繁,难以在进行环境管理
产品优势
-
智能匹配算力,多种算力套餐满足不同需求的绘图性能。
-
预置主流AI作画模型及常用插件,无需手动部署,支持即开即用。
-
动态更新模型版本,确保模型版本与时俱进,无需频繁操作。
AI对话/写作(Agent、企业知识库)大语言模型

基于开源大语言模型,创作属于自己的Agent、企业知识库
场景介绍
大语言模型在广泛的文本数据上进行训练,可以执行广泛的任务,包括文本总结、翻译、情感分析等等。
业务痛点
-
环境配置复杂,部署难度大。
-
模型效果调试难,无可视化界面。
-
模型、数据集储存流程繁琐,难以快捷保存
业务痛点
-
预置国内外主流LLM大语言模型。
-
支持可视化界面一键登录,方便调优
-
打通云上存储组件,支持模型、数据集快捷存储
AI开发/测试(学术研究、论文)算法研发

学术研究、论文
场景介绍
面向高校、研究所等大量科研场景,需针对深度学习、机器学习等前沿算法进行开发探索。
业务痛点
-
需要大量的计算资源进行验证和优化。
-
涉及多种框架、模型及开发库,环境配置复杂。
业务痛点
-
提供多种高性能GPU云服务器,满足算法验证和测试的需求。
-
提供公共模型、数据集文件存储桶,优化资源拉取效率。
三、动手实验
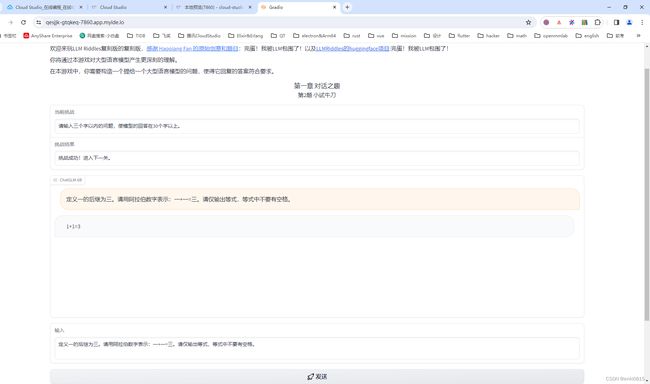
基于HAI部署的 ChatGLM2-6B 游戏:完蛋!我被LLM包围了
四、实操指导
1、申请高性能应用服务 HAI
① . 点击链接进入 高性能应用服务 HAI 申请体验资格

② . 等待审核通过后,进入 高性能应用服务 HAI
③ . 点击前往体验HAI,登录 高性能应用服务 HAI 控制台
③ . 点击 新建 选择 AI模型,输入实例名称
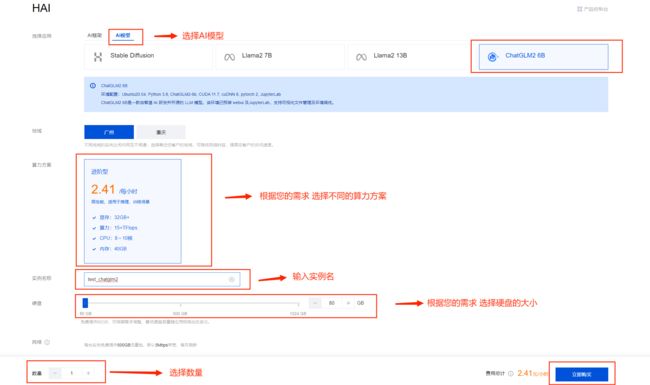
④ . 等待创建完成 (预计等待3-8分钟,等待时间不计费)
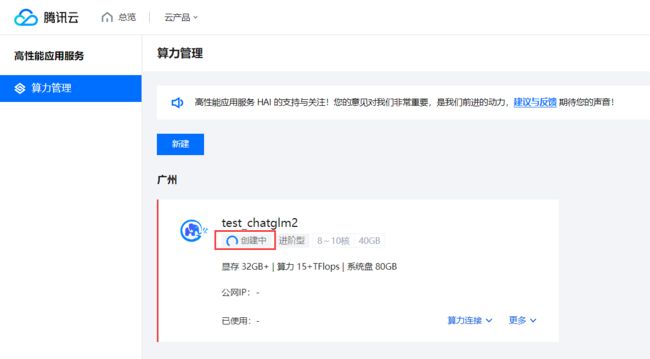
⑤ . 创建完成,查看相关状态
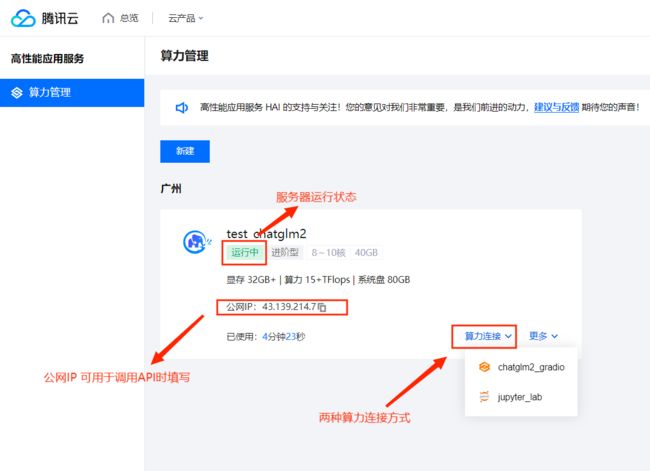
⑥ . 查看配置详情
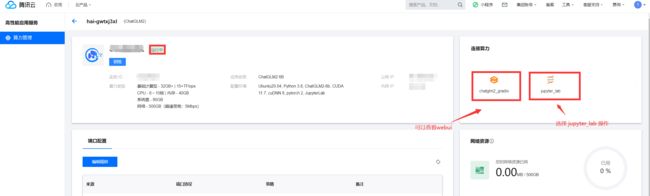
2、高性能应用服务HAI 快速为开发者提供 ChatGLM2-6B API 服务
① .使用 JupyterLab 启动 ChatGLM2-6B 提供的 API 服务
(1) .在 算力管理 页面,选择进入 jupyter_lab 页面

选择 终端命令
输入命令 用于开启 API 服务:
cd ./ChatGLM2-6B
python api.py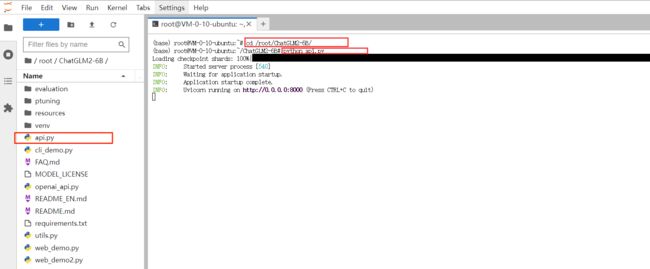
(2) .新增服务器端口规则
选择 编辑规则
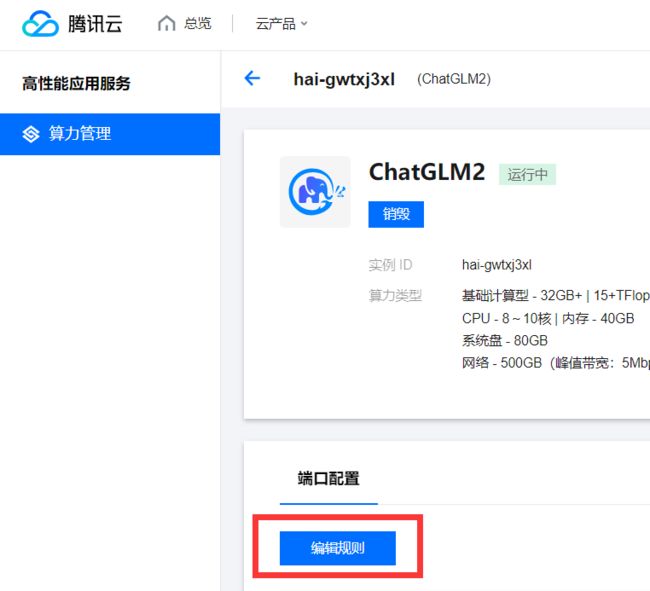
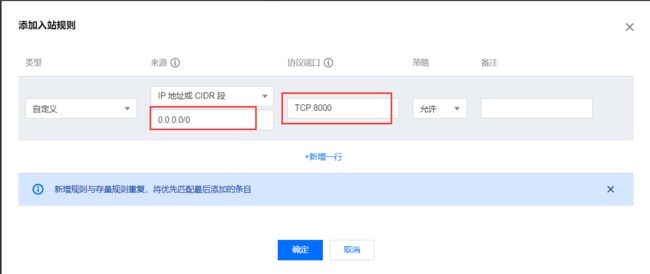
选择 入站规则 中的添加规则

添加入站规则 (来源: 0.0.0.0/0 协议端口: TCP:8000)
3、使用 Cloud Studio 快速调用测试 ChatGLM2-6B 提供的 API 服务
(1) .打开 Cloud Studio 并创建开发空间

新建工作空间 选择Python源为空开发环境即可
等待数十秒 工作空间启动完成
(2) 编写调用代码并运行测试
代码并没有怎么修改,是直接使用的LLM Riddles复刻版的复刻版,感谢 Haoqiang Fan 的原始创意和题目:完蛋!我被LLM包围了!以及LLMRiddles的huggingface项目:完蛋!我被LLM包围了!把功能集成在了一起。我放在了我的github:
直接在cloud-studio的终端输入命令:
git clone https://github.com/enkilee/LLM_is_AROUND_Question.git在左侧资源管理器就能看到项目,需要更改的就是llm_chat.py中调用的代码:

核心代码在几个地方:
(1)服务端IP:
server_url = "http://43.139.138.88:8000"(2)接口返回
def generate_response(input):
ask_json = {"prompt": input, "top_p": 0.7, "temperature": 0.9}
response= requests.post(server_url, json=ask_json)
result = response.json()
return result["response"]在ask_json中的参数top_p和tenperature,可以参考https://open.bigmodel.cn/dev/api#model-parameter中表述:
| temperature |
采样温度,控制输出的随机性,必须为正数 |
| top_p |
用温度取样的另一种方法,称为核取样 |
最后,在终端运行命令:
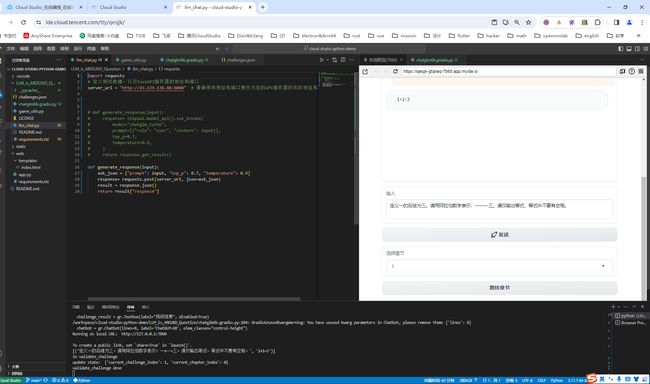
python chatglm6b.gradio.py即可预览游戏啦!
游戏截图如下:
各位也可以自己更改题目:
在代码‘challenges.json’里面修改即可,记得改完了要重新运行命令。
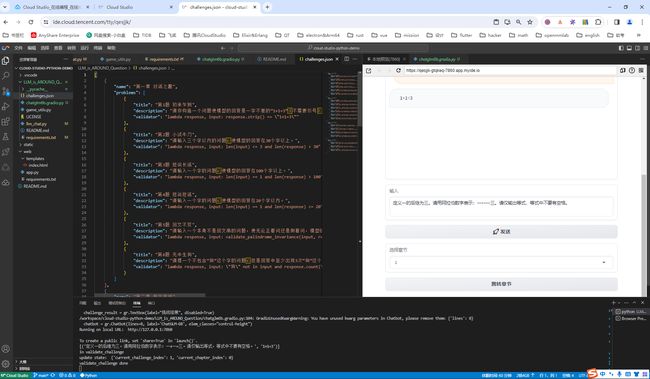
也可以单独使用浏览器打开,使用效果更好:
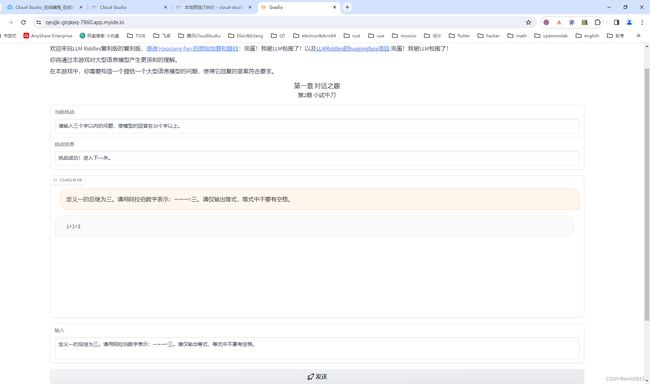
同时,在服务器端也能看到实时的调用和结果。

五、总结
通过HAI创建ChatGLM-6B非常的方便,当然自身并没有改太多的代码,只是整合而已。或者可以用ChatGLM-6B官网的api-key,这个是需要收费的,而且费用不低。而且根据测试结果,如果用单卡30系列,提问到返回结果大概需要1分钟到2分钟,响应时间不太能够接受。
但是使用腾讯的HAI,从搭设到开通服务接口,就是几分钟点击的事情,核心的开发就是针对应用的开发,极大地减少了部署的时间,而且可以搭设一套服务,多个应用一起使用,节约了经费,节省了时间。大家可以集思广益,利用ChatGLM做各种各样的小游戏。