Redis-核心数据结构
Redis安装
下载地址:Download | Redis
安装步骤:
# 1、安装gcc
apt-get install gcc
# 2、下载redis-7.0.3.tar.gz并解压
wget http://download.redis.io/releases/redis-7.0.3.tar.gz
tar xzf redis-7.0.3.tar.gz
cd redis-7.0.3
# 3、进入到解压好的redis‐7.0.3目录下,进行编译与安装
make
# 4、修改配置
daemonize yes #后台启动
protected‐mode no #关闭保护模式,开启的话,只有本机才可以访问redis
# 4.5、需要注释掉bind
# bind 127.0.0.1 -::1
# 5、启动服务
src/redis‐server redis.conf
# 6、验证启动是否成功
ps ‐ef | grep redis
# 7、进入redis客户端
src/redis‐cli
# 8、退出客户端
quit
# 9、退出redis服务:(亲测三种都可用)
(1)pkill redis‐server
(2)kill 进程号
(3)src/redis‐cli shutdown这里原计划是安装redis-5.0.3.tar.gz版本,但是安装解压后执行make命令时一直报错
错误信息:collect2.exe: error: ld returned 1 exit status
collect2 error ld returned 1 exit status提示出现之前,一般在上面几行都会有其他报错,而collect2 error ld returned 1 exit status所反映的只是其之前一共出现了多少个错误,真正的错误是在其上面出现的那些报错。比如,没有错误,会提示collect2 error ld returned 0 exit status;有两个报错,会提示collect2 error ld returned 2 exit status。所以,真正要解决的是在collect2 error ld returned 1 exit status提示出现之前的那些报错提醒
以上解决问题的思路参考文章:(已解决)报错:collect2 error ld returned 1 exit status_collect2: error: ld returned 1 exit status_间歇努力为了持续躺平的博客-CSDN博客
尝试过网上给出的多种方案,包括:
1、添加配置OPT=-O2 -march=i686
2、使用make MALLOC=libc命令替换make
3、删除解压包,重新安装
然而都没有解决问题,最后切换安装版本为redis-7.0.3.tar.gz解决问题,其他版本未测试
常见面试题:
1、什么是Redis?
Redis是基于C开发的高性能非关系型的键值对数据库,可以存储键和五种不同类型值之间的映射
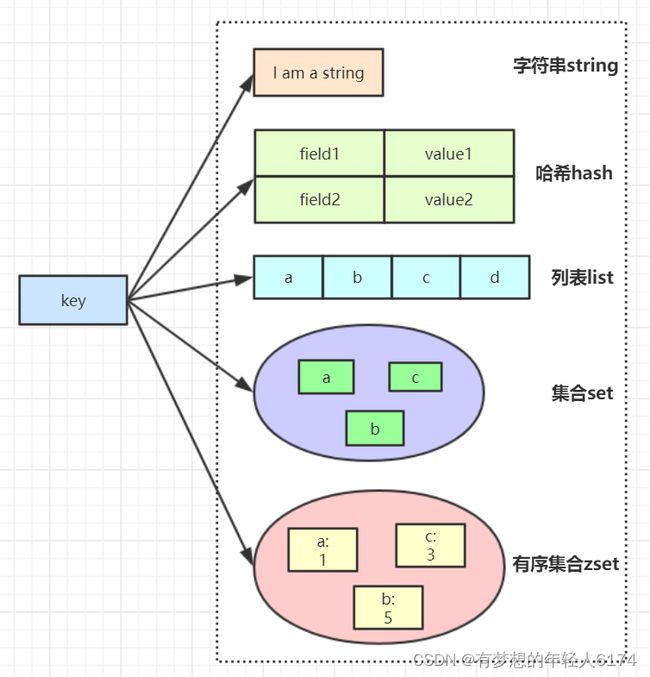
键的类型只能为字符串(SDS简单动态字符串,经过专门设计的),值支持五种数据类型:字符串String、列表List、集合Set、散列表Hash、有序集合ZSet
Redis数据是存储在内存中的,其读写数据的速度很快,每秒可以处理超过10万次的读写操作
Redis其他应用:分布式锁、事务、持久化、LUA脚本、多种集群方案等
2、Redis有哪些优缺点?
优点:
1、读写性能优异:读的速度为110000次/s,写的速度为81000次/s(简单命令测试结果,复杂操作降低些) 2、支持数据持久化:AOF、RDB两种持久化方式(还有混合两种的持久化) 3、支持事务:Redis的所有操作都是原子性的,同时Redis还支持对几个操作合并后的原子性执行(LUA脚本) 4、支持再次复制:主机会自动将数据同步到从机,实现读写分离(全量同步、增量同步)
缺点:
1、数据容量受到物理内存的限制,不能用作海量数据的高性能读写 2、Redis不具备自动容错和恢复功能,主机如果宕机会导致前端部分读写请求失败,需要等待机器重启或手动切换前端访问的IP才能恢复;此外如果部分数据未来得及同步给其他节点,即使手动切换IP还是会导致丢失一部分数据,降低系统的可用性。(为支持自动容错衍生出哨兵、集群模式)
3、Redis虽然支持在线扩容,但是集群容量达到上限时,在线扩容会变得很复杂,如果要避免这种问题,运维人员在系统上线时必须确保有足够的空间,这样就导致了对资源造成很大浪费
3、为什么要选择Redis,而不是map/guava做缓存?
用户第一次访问数据从数据库获取,慢一点没关系,读取后写入缓存,缓存失效前请求都是直接从缓存拿到数据,那速度就很快了(高性能)。另外缓存的抗压能力远远大于数据库,高并发下使用缓存优势明显(高并发)
好点的MySQL数据库每秒能抗住2000并发就不错了,Redis缓存动辄几万还有一系列优化手段
map和guava实现的本地缓存,特点是轻量和快速,生命周期随着JVM的销毁而结束,另外多例情况下每个实例各自保存一份缓存,显然缓存的一致性就很难保证了
Redis或memcached称为分布式缓存,多例情况下共用一份缓存,一致性有了保证,但缺点是需要保证高可用,复杂度也提高了
4、Redis为什么这么快?
Redis的操作都是基于内存的,非常快速,数据存在内存中,类似于HashMap、其查找和操作的时间复杂度都是O(1),而且结构简单,读数据操作也很简单,其次还采用单线程,避免了不必要的上下文切换和竞争关系,也不存在多线程切换消耗的CPU性能,且不用考虑各种锁的开销,除此外,其使用多路复用IO,非阻塞IO
Redis的数据结构也是经过专门设计的,包括缓存行优化、多种编码格式切换、快表、跳表等
5、Redis有哪些数据类型?
key键:SDS字符串;value类型:String、hash、list、set、zset
Redis五种数据类型的应用场景