K8S集群搭建(多master多node节点)
目录
一 部署环境
关闭防火墙
设置主机名hostname,管理节点设置主机名为 master
配置hosts主机名解析
配置免密登陆
关闭交换分区
配置内核参数,将桥接的IPv4流量传递到iptables的链
开启ipvs
二 配置软件源
升级centos系统内核
配置时间同步
安装docker服务以及K8S
查看docker服务和K8S服务是否起来
配置docker加速
三 通过keepalived+nginx 实现k8s apiserver节点高可用
安装nginx和keepalived主备
修改nginx配置文件,主备配置文件是一样的
keepalived配置 Master1
keepalived配置 Master2
查看IP地址 出现192.168.100.222/24虚拟VIP地址
ping 虚拟VIP地址 192.168.100.222
四 集群初始化
生成默认kubeadm-config.yaml 文件
传kubeadm-config.yaml 给其他master节点
所有Master节点提前下载镜像(master1和master2都要下载)
初始化集群
初始化成功以后,会产生Token值,用于其他节点加入时使用
配置环境变量
查看节点状态:
所有的系统组件均以容器的方式运行并且在kube-system命名空间内,此时可以查看Pod状态
在要加入集群的节点执行以下命令
添加其他主节点 master2,执行以下命令
如果遇到kubeadm init报错10248不健康
node节点加入集群执行以下命令
解决方式
node节点添加成功
添加完成查看结果
五 安装网络插件
查看节点状态
如果报错显示以下内容:
六 部署k8s的dashboard
执行yaml文件直接部署 k8s与dashboard 对应版本安装
查看dashboard运行状态,以deployment方式部署,运行2个pod及2个service
查看暴露的service,已修改为nodeport类型:
登录dashboard
创建登录用户 以及查看访问Dashboard的认证令牌
把获取到的Token复制到登录界面的Token输入框中,登陆成功
一 部署环境
多台运行着下列系统的机器:
CentOS 7.9 每台机器 2 GB 或更多的 RAM内存2 CPU 核或更多
集群中的所有机器的网络彼此均能相互连接(公网和内网都可以)节点之中不可以有重复的主机名,
| Hostname | ip地址 | 系统 |
| master1 | 192.168.100.10 | CentOS 7.9 |
| master2 | 192.168.100.11 | CentOS 7.9 |
| node1 | 192.168.100.13 | CentOS 7.9 |
| node2 | 192.168.100.14 | CentOS 7.9 |
| 虚拟vip | 192.168.100.222 | CentOS 7.9 |
docker 版本 v20.10.2
k8s 版本 v1.23.6
关闭防火墙
setenforce 0
sed -ri '/^[^#]*SELINUX=/s#=.+$#=disabled#' /etc/selinux/config
systemctl stop firewalld
systemctl disable firewalld
reboot 重启系统设置主机名hostname,管理节点设置主机名为 master
[root@localhost ~]# hostnamectl set-hostname master1 && bash
[root@localhost ~]# hostnamectl set-hostname master2 && bash
[root@localhost ~]# hostnamectl set-hostname node1 && bash
[root@localhost ~]# hostnamectl set-hostname node2 && bash
配置hosts主机名解析
cat <>/etc/hosts
192.168.100.10 master1
192.168.100.11 master2
192.168.100.13 node1
192.168.100.14 node2
192.168.100.222 k8s-vip
EOF 配置免密登陆
[root@master1 ~]# ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Created directory '/root/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:V5ewxAlLVa3ZTkuMwfZzelE4Dz40l9K7OHMRDlQ+ja8 root@master1
The key's randomart image is:
+---[RSA 2048]----+
| o+*+++.|
| . ooOB*=|
| . +o%%=|
| . o=@*|
| S . o=O|
| . +.=o|
| E. |
| |
| |
+----[SHA256]-----+
[root@master1 ~]# ls
将本地生成的秘钥文件和私钥文件拷贝到远程主机
[root@master1 ~]# ssh-copy-id master2
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
The authenticity of host 'master2 (192.168.100.11)' can't be established.
ECDSA key fingerprint is SHA256:QC+4rc9118CZXii4A+dD7e9IXryxnCFpXC1ZoGLO3QU.
ECDSA key fingerprint is MD5:f1:70:b0:c6:0a:77:d9:00:b1:41:79:c3:3b:1c:88:1d.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@master2's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'master2'"
and check to make sure that only the key(s) you wanted were added.
[root@master1 ~]#
[root@master1 ~]# ssh-copy-id node1
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
The authenticity of host 'node1 (192.168.100.13)' can't be established.
ECDSA key fingerprint is SHA256:QC+4rc9118CZXii4A+dD7e9IXryxnCFpXC1ZoGLO3QU.
ECDSA key fingerprint is MD5:f1:70:b0:c6:0a:77:d9:00:b1:41:79:c3:3b:1c:88:1d.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@node1's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'node1'"
and check to make sure that only the key(s) you wanted were added.
[root@master1 ~]# ssh-copy-id node2
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
The authenticity of host 'node2 (192.168.100.14)' can't be established.
ECDSA key fingerprint is SHA256:QC+4rc9118CZXii4A+dD7e9IXryxnCFpXC1ZoGLO3QU.
ECDSA key fingerprint is MD5:f1:70:b0:c6:0a:77:d9:00:b1:41:79:c3:3b:1c:88:1d.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@node2's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'node2'"
and check to make sure that only the key(s) you wanted were added.
[root@master1 ~]#
[root@master1 ~]# ssh node1 ##验证成功
Last login: Fri Dec 16 11:17:20 2022 from 192.168.100.1
[root@master1 ~]# ssh master2
Last login: Fri Dec 16 11:23:46 2022 from node2
[root@master2 ~]# exit
或者用
for i in master1 master2 node1 node2;do ssh-copy-id -i .ssh/id_rsa.pub $i;done
关闭交换分区
swapoff -a
sed -i 's/.*swap.*/#&/' /etc/fstab
swapoff -a #临时关闭
永久关闭,将/etc/fstab中的如下一行注释掉
#/dev/mapper/centos-swap swap swap defaults 0 0
同样的操作在master2和node1上也分别做一下。
为什么要关掉swap呢?
k8s在设计时就考虑要提升性能,不让使用swap,如果不关的话,初始化时将会提示错误。
配置内核参数,将桥接的IPv4流量传递到iptables的链
cat < /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
EOF
使配置生效
[root@master1 ~]# modprobe br_netfilter
[root@master1 ~]# sysctl --system
开启ipvs
开启ipvs
cat > /etc/sysconfig/modules/ipvs.modules < /dev/null 2>&1
if [ 0 -eq 0 ]; then
/sbin/modprobe ${kernel_module}
fi
done
END
chmod 755 /etc/sysconfig/modules/ipvs.modules
bash /etc/sysconfig/modules/ipvs.modules
二 配置软件源
mkdir -p /etc/yum.repos.d/repo.bak
mv /etc/yum.repos.d/*.repo /etc/yum.repo.d/repo.bak
cd /etc/yum.repos.d/
##安装epel源
rpm --imp ort https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
yum install -y https://www.elrepo.org/elrepo-release-7.el7.elrepo.noarch.rpm
curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo
##配置docker-ce的源
yum install -y yum-utils
yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
##安装k8syum源
cat <升级centos系统内核
yum update
查看内核版本并安装最新版本
yum list available --disablerepo=* --enablerepo=elrepo-kernel
安装最新lt内核版本
yum --disablerepo='*' --enablerepo=elrepo-kernel install kernel-lt -y
查看系统grub内核的启动列表,这里编号0的5.4.227的lt版本是我们新安装的
awk -F\' '$1=="menuentry " {print i++ " : " $2}' /etc/grub2.cfg
[root@master1 ~]# awk -F\' '$1=="menuentry " {print i++ " : " $2}' /etc/grub2.cfg
0 : CentOS Linux (5.4.227-1.el7.elrepo.x86_64) 7 (Core)
1 : CentOS Linux (3.10.0-1160.80.1.el7.x86_64) 7 (Core)
2 : CentOS Linux (3.10.0-1160.71.1.el7.x86_64) 7 (Core)
3 : CentOS Linux (0-rescue-46ef9765f6e049aab7416cf2a8a3042e) 7 (Core)
[root@master1 ~]#
指定以新安装的编号0的内核版本为默认启动内核
[root@master1 ~]# grub2-set-default 0
卸载旧内核版本
yum remove kernel -y
重启机器,以新内核版本加载启动
reboot
查看当前内核版本
[root@master1 ~]# uname -r
5.4.227-1.el7.elrepo.x86_64
配置时间同步
yum -y install chrony
$ vim /etc/chrony.conf
root@master1 ~]# cat /etc/chrony.conf
# Use public servers from the pool.ntp.org project.
# Please consider joining the pool (http://www.pool.ntp.org/join.html).
server ntp.aliyun.com iburst ##添加
server ntp.tencent.com iburst ###添加
#server 0.centos.pool.ntp.org iburst #注销
#server 1.centos.pool.ntp.org iburst #注销
#server 2.centos.pool.ntp.org iburst #注销
#server 3.centos.pool.ntp.org iburst #注销
#启动和配置自启动
systemctl enable chronyd
systemctl start chronyd
安装docker服务以及K8S
docker安装
yum -y install docker-ce-20.10.2
systemctl start docker && systemctl enable docker && systemctl status docker
kubernetes安装
yum install -y kubelet-1.23.6 kubeadm-1.23.6 kubectl-1.23.6 --disableexcludes=kubernetes
systemctl enable kubelet && systemctl start kubelet && systemctl status kubelet
查看docker服务和K8S服务是否起来
dockers服务起来
[root@master1 ~]#systemctl start docker && systemctl enable docker && systemctl status docker
Created symlink from /etc/systemd/system/multi-user.target.wants/docker.service to /usr/lib/systemd/system/docker.service.
● docker.service - Docker Application Container Engine
Loaded: loaded (/usr/lib/systemd/system/docker.service; enabled; vendor preset: disabled)
Active: active (running) since 五 2022-12-16 14:57:14 CST; 67ms ago
Docs: https://docs.docker.com
Main PID: 16544 (dockerd)
CGroup: /system.slice/docker.service
└─16544 /usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.s...
12月 16 14:57:13 master1 dockerd[16544]: time="2022-12-16T14:57:13.867503820+08:00"...pc
12月 16 14:57:13 master1 dockerd[16544]: time="2022-12-16T14:57:13.912388135+08:00"...t"
12月 16 14:57:13 master1 dockerd[16544]: time="2022-12-16T14:57:13.912414989+08:00"...e"
12月 16 14:57:13 master1 dockerd[16544]: time="2022-12-16T14:57:13.912622411+08:00"...."
12月 16 14:57:14 master1 dockerd[16544]: time="2022-12-16T14:57:14.009252102+08:00"...s"
12月 16 14:57:14 master1 dockerd[16544]: time="2022-12-16T14:57:14.067230875+08:00"...."
12月 16 14:57:14 master1 dockerd[16544]: time="2022-12-16T14:57:14.124998469+08:00"....7
12月 16 14:57:14 master1 dockerd[16544]: time="2022-12-16T14:57:14.125084166+08:00"...n"
12月 16 14:57:14 master1 systemd[1]: Started Docker Application Container Engine.
12月 16 14:57:14 master1 dockerd[16544]: time="2022-12-16T14:57:14.142287793+08:00"...k"
Hint: Some lines were ellipsized, use -l to show in full.kubelet服务启动成功
[root@master1 ~]# systemctl enable kubelet && systemctl start kubelet && systemctl status kubelet
Created symlink from /etc/systemd/system/multi-user.target.wants/kubelet.service to /usr/lib/systemd/system/kubelet.service.
● kubelet.service - kubelet: The Kubernetes Node Agent
Loaded: loaded (/usr/lib/systemd/system/kubelet.service; enabled; vendor preset: disabled)
Drop-In: /usr/lib/systemd/system/kubelet.service.d
└─10-kubeadm.conf
Active: active (running) since 五 2022-12-16 15:08:36 CST; 34ms ago
Docs: https://kubernetes.io/docs/
Main PID: 21511 (kubelet)
Tasks: 6
Memory: 9.9M
CGroup: /system.slice/kubelet.service
└─21511 /usr/bin/kubelet --bootstrap-kubeconfig=/etc/kubernetes/bootstrap-k...
12月 16 15:08:36 master1 systemd[1]: Started kubelet: The Kubernetes Node Agent.配置docker加速
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://82m9ar63.mirror.aliyuncs.com"],
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2"
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart docker注:以上操作4个节点系统都要做
三 通过keepalived+nginx 实现k8s apiserver节点高可用
安装nginx和keepalived主备
#在master1和master2上做nginx主备安装
安装nginx keepalived nginx-all-modules #这个如果不安装的话,启动nginx服务时会报错
yum install -y nginx keepalived nginx-all-modules
修改nginx配置文件,主备配置文件是一样的
从worker_connections 1024 之后 开始添加 (注:master1 2 都改)
#Master1和Master2上均做
cp /etc/nginx/nginx.conf /etc/nginx/nginx.conf.bak
vim /etc/nginx/nginx.conf
user nginx;
worker_processes auto;
error_log /var/log/nginx/error.log;
pid /run/nginx.pid;
include /usr/share/nginx/modules/*.conf;
events {
worker_connections 1024;
}
stream {
log_format main '$remote_addr $upstream_addr - [$time_local] $status $upstream_bytes_sent';
access_log /var/log/nginx/k8s-access.log main;
upstream k8s-apiserver {
server 192.168.100.10:6443; #Master1 APISERVER IP:PORT
server 192.168.100.11:6443; #Master2 APISERVER IP:PORT
}
server {
listen 16443; #由于nginx与master节点复用,这个监听端口不能是6443,否则会冲突
proxy_pass k8s-apiserver;
}
}
http {
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
tcp_nopush on;
tcp_nodelay on;
keepalive_timeout 65;
types_hash_max_size 4096;
include /etc/nginx/mime.types;
default_type application/octet-stream;
#include /etc/nginx/conf.d/*.conf;
server {
listen 80 default_server;
server_name _;
location = / {
}
}
}
启动nginx服务
systemctl enable nginx --now
keepalived配置 Master1
#Master1做成主
#vrrp_script:指定检查 nginx 工作状态脚本(根据 nginx 状态判断是否故障转移) #virtual_ipaddress:虚拟 IP(VIP)
cp /etc/keepalived/keepalived.conf /etc/keepalived/keepalived.conf.bak
vim /etc/keepalived/keepalived.conf
global_defs {
notification_email {
[email protected]
[email protected]
[email protected]
}
notification_email_from [email protected]
smtp_server 127.0.0.1 #修改
smtp_connect_timeout 30
router_id NGINX_MASTER #修改id
vrrp_skip_check_adv_addr
#vrrp_strict ##注销掉否则ping不通虚拟VIP地址
vrrp_garp_interval 0
vrrp_gna_interval 0
}
vrrp_script check_nginx {
script "/etc/keepalived/check_nginx.sh" #添加检查脚本
}
vrrp_instance VI_1 {
state MASTER
interface ens33 #修改为实际网卡名
virtual_router_id 51 #VRRP路由ID实例,每个实例是唯一的
priority 100 #优先级,备服务器设置90
advert_int 1 #指定VRRP心跳包通告间隔时间,默认1秒
authentication {
auth_type PASS
auth_pass 1111
}
#虚拟IP
virtual_ipaddress {
192.168.100.222/24 ##修改虚拟VIP地址
}
track_script {
check_nginx #添加检查nginx脚本
}
#脚本
#注:keepalived 根据脚本返回状态码(0 为工作不正常,非 0 正常)判断是否故障转移。
cat <> /etc/keepalived/check_nginx.sh
#!/bin/bash
count=$(ps -ef |grep nginx | grep sbin | egrep -cv "grep|$$")
if [ "$count" -eq 0 ];then
systemctl stop keepalived
fi
EOF
chmod a+x /etc/keepalived/check_nginx.sh
systemctl enable keepalived --now keepalived配置 Master2
#Master2做成备
#vrrp_script:指定检查 nginx 工作状态脚本(根据 nginx 状态判断是否故障转移) #virtual_ipaddress:虚拟 IP(VIP)
cp /etc/keepalived/keepalived.conf /etc/keepalived/keepalived.conf.bak
vim /etc/keepalived/keepalived.conf
global_defs {
notification_email {
[email protected]
[email protected]
[email protected]
}
notification_email_from [email protected]
smtp_server 127.0.0.1 #修改
smtp_connect_timeout 30
router_id NGINX_BACKUP #修改id
vrrp_skip_check_adv_addr
#vrrp_strict ##注销掉否则ping不通虚拟VIP地址
vrrp_garp_interval 0
vrrp_gna_interval 0
}
vrrp_script check_nginx {
script "/etc/keepalived/check_nginx.sh"
}
vrrp_instance VI_1 {
state BACKUP
interface ens33 #修改为实际网卡名
virtual_router_id 51 #VRRP路由ID实例,每个实例是唯一的
priority 90 #优先级,主服务器设置100
advert_int 1 #指定VRRP心跳包通告间隔时间,默认1秒
authentication {
auth_type PASS
auth_pass 1111
}
#虚拟IP
virtual_ipaddress {
192.168.100.222/24 #修改虚拟VIP地址
}
track_script {
check_nginx
}
}
#脚本
#注:keepalived 根据脚本返回状态码(0 为工作不正常,非 0 正常)判断是否故障转移。
cat <> /etc/keepalived/check_nginx.sh
#!/bin/bash
count=$(ps -ef |grep nginx | grep sbin | egrep -cv "grep|$$")
if [ "$count" -eq 0 ];then
systemctl stop keepalived
fi
EOF
chmod a+x /etc/keepalived/check_nginx.sh
systemctl enable keepalived --now
查看IP地址 出现192.168.100.222/24虚拟VIP地址
[root@master1 ~]# ip addr
1: lo: mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:b1:d6:6e brd ff:ff:ff:ff:ff:ff
inet 192.168.100.10/24 brd 192.168.100.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet 192.168.100.222/24 scope global secondary ens33
valid_lft forever preferred_lft forever
inet6 fe80::137d:5b9f:cc00:a088/64 scope link noprefixroute
valid_lft forever preferred_lft forever
3: docker0: mtu 1500 qdisc noqueue state DOWN group default
link/ether 02:42:c9:4d:2b:b7 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
ping 虚拟VIP地址 192.168.100.222
[root@master1 ~]# ping 192.168.100.222
PING 192.168.100.222 (192.168.100.222) 56(84) bytes of data.
64 bytes from 192.168.100.222: icmp_seq=1 ttl=64 time=0.049 ms
64 bytes from 192.168.100.222: icmp_seq=2 ttl=64 time=0.071 ms
停止master1的keepalived 看是否虚拟VPN IP地址会飘在master2上 (master2显示虚拟IP代表成功)
[root@master1 ~]# systemctl stop keepalived.service [root@master2 ~]# ip ad
1: lo: mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:d6:4e:c4 brd ff:ff:ff:ff:ff:ff
inet 192.168.100.11/24 brd 192.168.100.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet 192.168.100.222/24 scope global secondary ens33
valid_lft forever preferred_lft forever
inet6 fe80::137d:5b9f:cc00:a088/64 scope link tentative noprefixroute dadfailed
valid_lft forever preferred_lft forever
inet6 fe80::b7a5:7adc:7fdc:77af/64 scope link noprefixroute
valid_lft forever preferred_lft forever
3: docker0: mtu 1500 qdisc noqueue state DOWN group default
link/ether 02:42:62:5f:61:42 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
[root@master2 ~]#
四 集群初始化
生成默认kubeadm-config.yaml 文件
kubeadm config print init-defaults --kubeconfig ClusterConfiguration > kubeadm-config.yaml
[root@master1 ~]# kubeadm config print init-defaults --kubeconfig ClusterConfiguration > kubeadm-config.yaml
[root@master1 ~]# ls
anaconda-ks.cfg kubeadm-config.yaml
也可以自己创建kubeadm-config.yaml 文件,我这里选择自己创建kubeadm-config.yaml
[root@master1 ~]#cat kubeadm-config.yaml
apiVersion: kubeadm.k8s.io/v1beta2
kind: ClusterConfiguration
kubernetesVersion: v1.23.6 ##更改k8s版本号
imageRepository: registry.aliyuncs.com/google_containers ##更改国内镜像源
controlPlaneEndpoint: 192.168.100.222:16443 ##虚拟VIP地址+端口
apiServer:
certSANs:
- 192.168.100.222 ###添加虚拟VIP地址
networking:
podSubnet: 10.244.0.0/16 # pod 的网段
serviceSubnet: 10.10.0.0/16 #service网段
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: ipvs ##开启ipvs
传kubeadm-config.yaml 给其他master节点
[root@master1 ~]# scp kubeadm-config.yaml master2:~
kubeadm-config.yaml 100% 499 366.2KB/s 00:00
所有Master节点提前下载镜像(master1和master2都要下载)
[root@master1 ~]# kubeadm config images pull --config kubeadm-config.yaml
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-apiserver:v1.23.6
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-controller-manager:v1.23.6
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-scheduler:v1.23.6
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-proxy:v1.23.6
[config/images] Pulled registry.aliyuncs.com/google_containers/pause:3.6
[config/images] Pulled registry.aliyuncs.com/google_containers/etcd:3.5.1-0
[config/images] Pulled registry.aliyuncs.com/google_containers/coredns:v1.8.6
[root@master1 ~]#初始化集群
root@master1 ~]# kubeadm init --config kubeadm-config.yaml
[init] Using Kubernetes version: v1.23.6
[preflight] Running pre-flight checks
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "ca" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local master1] and IPs [10.10.0.1 192.168.100.10 192.168.100.222]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "front-proxy-ca" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "etcd/ca" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [localhost master1] and IPs [192.168.100.10 127.0.0.1 ::1]
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [localhost master1] and IPs [192.168.100.10 127.0.0.1 ::1]
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "sa" key and public key
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "admin.conf" kubeconfig file
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "kubelet.conf" kubeconfig file
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Starting the kubelet
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[apiclient] All control plane components are healthy after 24.637002 seconds
[upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config-1.23" in namespace kube-system with the configuration for the kubelets in the cluster
NOTE: The "kubelet-config-1.23" naming of the kubelet ConfigMap is deprecated. Once the UnversionedKubeletConfigMap feature gate graduates to Beta the default name will become just "kubelet-config". Kubeadm upgrade will handle this transition transparently.
[upload-certs] Skipping phase. Please see --upload-certs
[mark-control-plane] Marking the node master1 as control-plane by adding the labels: [node-role.kubernetes.io/master(deprecated) node-role.kubernetes.io/control-plane node.kubernetes.io/exclude-from-external-load-balancers]
[mark-control-plane] Marking the node master1 as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule]
[bootstrap-token] Using token: h2nq1b.g17bz2b8ofyemnxo
[bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to get nodes
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstrap-token] configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstrap-token] configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace
[kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key
[addons] Applied essential addon: CoreDNS
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of control-plane nodes by copying certificate authorities
and service account keys on each node and then running the following as root:
kubeadm join 192.168.100.222:16443 --token h2nq1b.g17bz2b8ofyemnxo \
--discovery-token-ca-cert-hash sha256:8e8791621a3ad873547facdc62c8de731b020dbcf28a8f841d12793979222ad3 \
--control-plane
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.100.222:16443 --token h2nq1b.g17bz2b8ofyemnxo \
--discovery-token-ca-cert-hash sha256:8e8791621a3ad873547facdc62c8de731b020dbcf28a8f841d12793979222ad3
初始化成功以后,会产生Token值,用于其他节点加入时使用
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of control-plane nodes by copying certificate authorities
and service account keys on each node and then running the following as root:
kubeadm join 192.168.100.222:16443 --token h2nq1b.g17bz2b8ofyemnxo \
--discovery-token-ca-cert-hash sha256:8e8791621a3ad873547facdc62c8de731b020dbcf28a8f841d12793979222ad3 \
--control-plane ##用于加入master2节点
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.100.222:16443 --token h2nq1b.g17bz2b8ofyemnxo \
--discovery-token-ca-cert-hash sha256:8e8791621a3ad873547facdc62c8de731b020dbcf28a8f841d12793979222ad3
##用于加入node节点
温馨提示如果出现集群初始化出错可重置再初始化
[root@master1 ~]# kubeadm reset -f ##重置k8s初始化
配置环境变量
[root@master1 ~]# mkdir -p $HOME/.kube
[root@master1 ~]# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@master1 ~]# sudo chown $(id -u):$(id -g) $HOME/.kube/config
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
source ~/.bash_profile
# 临时生效(退出当前窗口重连环境变量失效)
export KUBECONFIG=/etc/kubernetes/admin.conf
# 永久生效(推荐)
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
source ~/.bash_profile查看节点状态:
[root@master1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master1 NotReady control-plane,master 48m v1.23.6
[root@master1 ~]#
所有的系统组件均以容器的方式运行并且在kube-system命名空间内,此时可以查看Pod状态
[root@master1 ~]# kubectl get pods -n kube-system -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
coredns-6d8c4cb4d-hbtm5 0/1 Pending 0 49m
coredns-6d8c4cb4d-n5dcp 0/1 Pending 0 49m
etcd-master1 1/1 Running 0 49m 192.168.100.10 master1
kube-apiserver-master1 1/1 Running 0 49m 192.168.100.10 master1
kube-controller-manager-master1 1/1 Running 0 49m 192.168.100.10 master1
kube-proxy-9p7cq 1/1 Running 0 49m 192.168.100.10 master1
kube-scheduler-master1 1/1 Running 0 49m 192.168.100.10 master1
[root@master1 ~]#
在要加入集群的节点执行以下命令
在master2节点创建
[root@master2 ~]# mkdir -p /etc/kubernetes/pki/etcd
在master1主节点将证书传给其他主节点
[root@master1 ~]# scp /etc/kubernetes/pki/ca.* master2:/etc/kubernetes/pki/
ca.crt 100% 1099 509.4KB/s 00:00
ca.key 100% 1679 456.7KB/s 00:00
[root@master1 ~]# scp /etc/kubernetes/pki/sa.* master2:/etc/kubernetes/pki/
sa.key 100% 1679 728.6KB/s 00:00
sa.pub 100% 451 160.0KB/s 00:00
[root@master1 ~]# scp /etc/kubernetes/pki/front-proxy-ca.* master2:/etc/kubernetes/pki/
front-proxy-ca.crt 100% 1115 1.0MB/s 00:00
front-proxy-ca.key 100% 1675 685.3KB/s 00:00
[root@master1 ~]# scp /etc/kubernetes/pki/etcd/ca.* master2:/etc/kubernetes/pki/etcd/
ca.crt 100% 1086 804.4KB/s 00:00
ca.key 100% 1679 862.5KB/s 00:00
[root@master1 ~]# scp /etc/kubernetes/admin.conf master2:/etc/kubernetes/
admin.conf 100% 5644 2.1MB/s 00:00
[root@master1 ~]# scp /etc/kubernetes/admin.conf node1:/etc/kubernetes/
admin.conf 100% 5644 2.7MB/s 00:00
[root@master1 ~]#
添加其他主节点 master2,执行以下命令
[root@master2]# kubeadm join 192.168.100.222:16443 --token h2nq1b.g17bz2b8ofyemnxo --discovery-token-ca-cert-hash sha256:8e8791621a3ad873547facdc62c8de731b020dbcf28a8f841d12793979222ad3 --control-plane
[preflight] Running pre-flight checks
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
[preflight] Running pre-flight checks before initializing the new control plane instance
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local master2] and IPs [10.10.0.1 192.168.100.11 192.168.100.222]
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [localhost master2] and IPs [192.168.100.11 127.0.0.1 ::1]
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [localhost master2] and IPs [192.168.100.11 127.0.0.1 ::1]
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Valid certificates and keys now exist in "/etc/kubernetes/pki"
[certs] Using the existing "sa" key
[kubeconfig] Generating kubeconfig files
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Using existing kubeconfig file: "/etc/kubernetes/admin.conf"
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[check-etcd] Checking that the etcd cluster is healthy
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Starting the kubelet
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...
[etcd] Announced new etcd member joining to the existing etcd cluster
[etcd] Creating static Pod manifest for "etcd"
[etcd] Waiting for the new etcd member to join the cluster. This can take up to 40s
The 'update-status' phase is deprecated and will be removed in a future release. Currently it performs no operation
[mark-control-plane] Marking the node master2 as control-plane by adding the labels: [node-role.kubernetes.io/master(deprecated) node-role.kubernetes.io/control-plane node.kubernetes.io/exclude-from-external-load-balancers]
[mark-control-plane] Marking the node master2 as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule]
This node has joined the cluster and a new control plane instance was created:
* Certificate signing request was sent to apiserver and approval was received.
* The Kubelet was informed of the new secure connection details.
* Control plane (master) label and taint were applied to the new node.
* The Kubernetes control plane instances scaled up.
* A new etcd member was added to the local/stacked etcd cluster.
To start administering your cluster from this node, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Run 'kubectl get nodes' to see this node join the cluster.
[root@master2]#
如果遇到kubeadm init报错10248不健康
遇见这样问题
[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get "http://localhost:10248/healthz": dial tcp [::1]:10248: connect: connection refused.
[kubelet-check] It seems like the kubelet isn't running or healthy.
Docker是用yum安装的,docker的cgroup驱动程序默认设置为systemd。默认情况下Kubernetes cgroup为system,我们需要更改Docker cgroup驱动
解决方法
# 添加以下内容
vim /etc/docker/daemon.json
{
"exec-opts": ["native.cgroupdriver=systemd"]
}
# 重启docker
systemctl restart docker
# 重新初始化
kubeadm reset -f # 先重置
node节点加入集群执行以下命令
kubeadm join 192.168.100.222:16443 --token h2nq1b.g17bz2b8ofyemnxo \
--discovery-token-ca-cert-hash sha256:8e8791621a3ad873547facdc62c8de731b020dbcf28a8f841d12793979222ad3 但是,执行过程中出现了报错现象,控制台报错,内容如下:
error execution phase preflight: couldn't validate the identity of the API Server: invalid discovery token CA certificate hash: invalid hash "sha256:8e8791621a3ad873547facdc62c8de731b020dbcf28a8f841d22ad3", expected a 32 byte SHA-256 hash, found 27 bytes
通过分析得知,根本原因:Token信息过期
解决方式
在Master节点使用kubeadm生成新的token信息
kubeadm token create --print-join-command
[root@master1 ~]# kubeadm token create --print-join-command
kubeadm join 192.168.100.222:16443 --token rrf6hc.jr2o31u7xu84hctt --discovery-token-ca-cert-hash sha256:8e8791621a3ad873547facdc62c8de731b020dbcf28a8f841d12793979222ad3
node节点添加成功
[root@node1 ~]# kubeadm token create --print-join-command
kubeadm join 192.168.100.222:16443 --token 82121p.6n68y99mgmr8daps --discovery-token-ca-cert-hash sha256:8e8791621a3ad873547facdc62c8de731b020dbcf28a8f841d12793979222ad3
[root@node1 ~]# kubeadm join 192.168.100.222:16443 --token rrf6hc.jr2o31u7xu84hctt --discovery-token-ca-cert-hash sha256:8e8791621a3ad873547facdc62c8de731b020dbcf28a8f841d12793979222ad3
[preflight] Running pre-flight checks
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Starting the kubelet
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
添加完成查看结果
[root@master1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master1 NotReady control-plane,master 109m v1.23.6
master2 NotReady control-plane,master 25m v1.23.6
node1 NotReady 8m51s v1.23.6
node2 NotReady 8m40s v1.23.6 五 安装网络插件
[root@master1 ~]# kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
namespace/kube-flannel created
clusterrole.rbac.authorization.k8s.io/flannel created
clusterrolebinding.rbac.authorization.k8s.io/flannel created
serviceaccount/flannel created
configmap/kube-flannel-cfg created
daemonset.apps/kube-flannel-ds created
[root@master1 ~]#
查看节点状态
[root@master1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master1 Ready control-plane,master 115m v1.23.6
master2 Ready control-plane,master 31m v1.23.6
node1 Ready 15m v1.23.6
node2 Ready 16m v1.23.6
如果报错显示以下内容:
The connection to the server localhost:8080 was refused - did you specify the right host or port?
问题分析:
环境变量
原因:kubernetes master没有与本机绑定,集群初始化的时候没有绑定,此时设置在本机的环境变量即可解决问题。
问题解决方法
设置环境变量
具体根据情况,linux设置该环境变量
方式一:编辑文件设置
vim /etc/profile
在底部增加新的环境变量 export KUBECONFIG=/etc/kubernetes/admin.conf
方式二:直接追加文件内容
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> /etc/profile
使生效
source /etc/profile
[root@master2 ~]# kubectl get nodes
The connection to the server localhost:8080 was refused - did you specify the right host or port?
[root@master2 ~]# kubectl get pods -n kube-system -o wide
The connection to the server localhost:8080 was refused - did you specify the right host or port?
[root@master2 ~]#
[root@master2 ~]# echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> /etc/profile
[root@master2 ~]#
[root@master2 ~]# source /etc/profile
[root@master2 ~]#
[root@master2 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master1 Ready control-plane,master 120m v1.23.6
master2 Ready control-plane,master 36m v1.23.6
node1 Ready 20m v1.23.6
node2 Ready 22m v1.23.6
[root@master2 ~]#
六 部署k8s的dashboard
执行yaml文件直接部署 k8s与dashboard 对应版本安装
https://github.com/kubernetes/dashboard/releases?after=v2.0.0
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.5.0/aio/deploy/recommended.yaml
kubectl get pods -n kubernetes-dashboard
[root@master1 ~]# kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.5.0/aio/deploy/recommended.yaml
namespace/kubernetes-dashboard created
serviceaccount/kubernetes-dashboard created
service/kubernetes-dashboard created
secret/kubernetes-dashboard-certs created
secret/kubernetes-dashboard-csrf created
secret/kubernetes-dashboard-key-holder created
configmap/kubernetes-dashboard-settings created
role.rbac.authorization.k8s.io/kubernetes-dashboard created
clusterrole.rbac.authorization.k8s.io/kubernetes-dashboard created
rolebinding.rbac.authorization.k8s.io/kubernetes-dashboard created
clusterrolebinding.rbac.authorization.k8s.io/kubernetes-dashboard created
deployment.apps/kubernetes-dashboard created
service/dashboard-metrics-scraper created
deployment.apps/dashboard-metrics-scraper created
查看dashboard运行状态,以deployment方式部署,运行2个pod及2个service
[root@master1 ~]# kubectl -n kubernetes-dashboard get pods
NAME READY STATUS RESTARTS AGE
dashboard-metrics-scraper-79459f84f-w8dqt 1/1 Running 0 2m49s
kubernetes-dashboard-5bd89d988-vwjsz 1/1 Running 0 2m49s
[root@master1 ~]# kubectl -n kubernetes-dashboard get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
dashboard-metrics-scraper ClusterIP 10.10.41.17 8000/TCP 117s
kubernetes-dashboard NodePort 10.10.252.52 443/TCP 118s
使用nodeport方式将dashboard服务暴露在集群外,指定使用30443端口,可自定义:
[root@master1 ~]# kubectl patch svc kubernetes-dashboard -n kubernetes-dashboard \
> -p '{"spec":{"type":"NodePort","ports":[{"port":443,"targetPort":8443,"nodePort":30443}]}}'
service/kubernetes-dashboard patched
查看暴露的service,已修改为nodeport类型:
[root@master1 ~]# kubectl -n kubernetes-dashboard get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
dashboard-metrics-scraper ClusterIP 10.10.41.17 8000/TCP 14m
kubernetes-dashboard NodePort 10.10.252.52 443:30443/TCP 14m
[root@master1 ~]#
登录dashboard
浏览器访问dashboard:https://192.168.100.222:30443/#/login
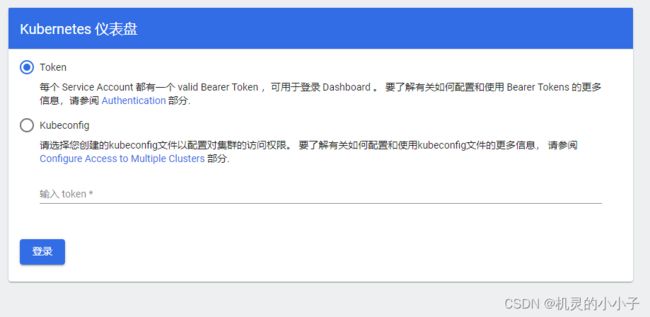
创建登录用户 以及查看访问Dashboard的认证令牌
[root@master1 ~]# kubectl create serviceaccount dashboard-admin -n kubernetes-dashboard
serviceaccount/dashboard-admin created
[root@master1 ~]#
[root@master1 ~]# kubectl create clusterrolebinding dashboard-admin --clusterrole=cluster-admin --serviceaccount=kubernetes-dashboard:dashboard-admin
clusterrolebinding.rbac.authorization.k8s.io/dashboard-admin created
[root@master1 ~]#
[root@master1 ~]# kubectl describe secrets -n kubernetes-dashboard $(kubectl -n kubernetes-dashboard get secret | awk '/dashboard-admin/{print $1}')
Name: dashboard-admin-token-x6sh8
Namespace: kubernetes-dashboard
Labels:
Annotations: kubernetes.io/service-account.name: dashboard-admin
kubernetes.io/service-account.uid: 76f21410-6c90-46da-8042-2da110a900cc
Type: kubernetes.io/service-account-token
Data
====
ca.crt: 1099 bytes
namespace: 20 bytes
token: eyJhbGciOiJSUzI1NiIsImtpZCI6ImZOZ1FKLWtFS3BHVE1Bc0xJX2Y2LTFBU0ZqNmMyZUotOGRJczFES0lWX00ifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJkYXNoYm9hcmQtYWRtaW4tdG9rZW4teDZzaDgiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoiZGFzaGJvYXJkLWFkbWluIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQudWlkIjoiNzZmMjE0MTAtNmM5MC00NmRhLTgwNDItMmRhMTEwYTkwMGNjIiwic3ViIjoic3lzdGVtOnNlcnZpY2VhY2NvdW50Omt1YmVybmV0ZXMtZGFzaGJvYXJkOmRhc2hib2FyZC1hZG1pbiJ9.HQ8nnCcMKyIM2XoSAbWiYhPkb9fWYG1bjY_hU8ngW82CuJKkcM36QfI7Z3nApYhkj4DE3BJP_pk97Ad9kG6-XW2B2OqoRBHoFXEeG0OqH6GUSlKORoOgG6ce_PVpjW7CP5tptiTimw1eogjfWtZt5L2SFjB3ZMXwz54iLg8INWT4AzXsaBn040Ms-VFYhJ73TGu_NZPL-jioxnNQv54tRZFjkFBQm3A4u_yFyZto8X64vS8DoA8ROkqf-pklWeQRWJJuTxesZwwERaLZPrYXKcCaJrmrIk7MB4ZRWtsWUL6wOq-k4KbZbQSSp7ydx5rXNHUeWvRa05WgkFIN-zdy0A
[root@master1 ~]#
把获取到的Token复制到登录界面的Token输入框中,登陆成功
