紫东太初:自动化所开源图-文-音三模态的预训练大模型
近日,中科院自动化所研发并开源了全球首个图文音(视觉-文本-语音)三模态预训练模型,兼具跨模态理解和生成能力,具有了在无监督情况下多任务联合学习、并快速迁移到不同领域数据的强大能力。自动化所构建了具有业界领先性能的中文预训练模型、语音预训练模型、视觉预训练模型,并开拓性地通过跨模态语义关联实现了视觉-文本-语音三模态统一表示,构建了三模态预训练大模型。
中文预训练模型
模型介绍
文本预训练模型使用条件语言模型作为自监督目标进行训练,和GPT一样,模型根据上文来预测当前词汇。中文预训练语言模型(Chinese-GPT)由40层transformer组成,隐藏层维度为2560,包含32个注意力头,共32亿参数。模型结构如下所示:
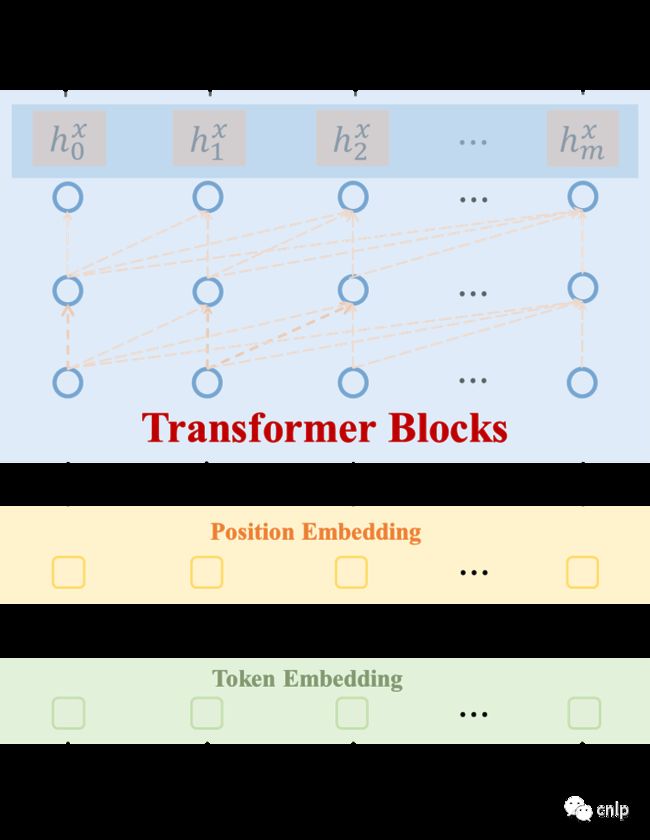
模型下载与使用示例地址:https://gitee.com/zidongtaichu/multi-modal-models/tree/master/text
应用示例
中文预训练模型基础上可以进行微调操作,充分利用少量有监督数据增强模型在下游任务上的表现,如文本分类,对话生成、古诗创作等。
1、文本续写

2、自动问答

视觉预训练模型
模型下载与使用示例地址:https://gitee.com/zidongtaichu/multi-modal-models/tree/master/vision
目标检测结果展示
语义分割结果展示
轻量化图文预训练模型
模型介绍
现有的图文预训练模型主要针对英文文本描述进行图像生成,自动化所开源的图文预训练模型可以根据中文文本描述实现图像生成,采用千万级训练数据进行自监督训练,并通过知识蒸馏算法实现了模型的大幅度压缩,在尽可能保留模型性能的同时,实现了预训练模型的轻量化。
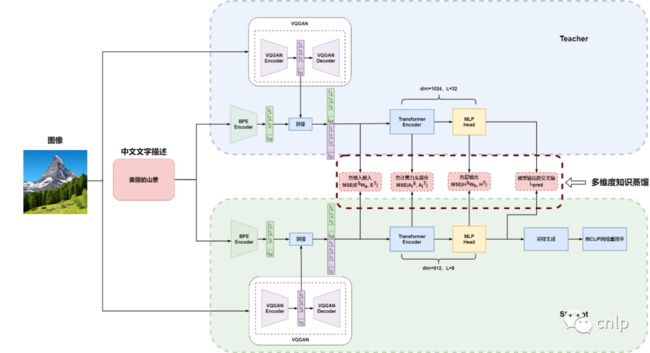
轻量化图文预训练模型由DALL-E和CLIP两个模型组成,DALL-E模型由8层Transformer组成,隐层维度为512,包含32个注意力头,约1亿参数;CLIP模型由6层Vision Transformer和3层Transformer组成,Vision Transformer的隐层维度为256,包含16个注意力头,Transformer的隐层维度为192,包含12个注意力头,约1700万参数。
模型下载与使用示例地址:https://gitee.com/zidongtaichu/multi-modal-models/tree/master/light_vision_text
图像检索
将三模态预训练大模型仓库克隆至本地:
git clone https://gitee.com/zidongtaichu/multi-modal-models.git
cd multi-modal-models下载 Light_CLIP 模型文件 model.pt 至 light_vision_text/Light_CLIP 文件夹下:
![]()
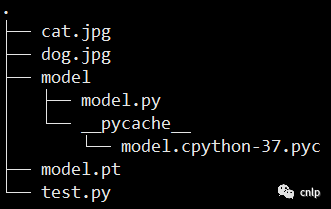
该示例中,待检索图像库一共有两张图片,分别是 dog.jpg 和 cat.jpg:


test.py 实现基于文本的图像检索:

输入文本为:一只可爱的狗狗在草地上奔跑,运行 python test.py,模型输出图像库中各个图片的概率值:
![]()
输入文本为:一只猫咪躺在沙发上睡觉,运行 python test.py,模型输出图像库中各个图片的概率值:
![]()
图像生成
(a) 下载 Light_VQGan_Dalle 模型文件dalle_small_model_pre_0924_lr1e-4_new_epoch7_data_point5761440.pt 至 light_vision_text/Light_VQGan_Dalle 文件夹下;
(b) 下载 vqgan 模型文件 vqgan_model.ckpt 至 light_vision_text/Light_VQGan_Dalle/vqgan 文件夹下;
(c) 将 Light_CLIP 模型文件 model.pt 下载至 light_vision_text/Light_VQGan_Dalle/clip 文件夹下。
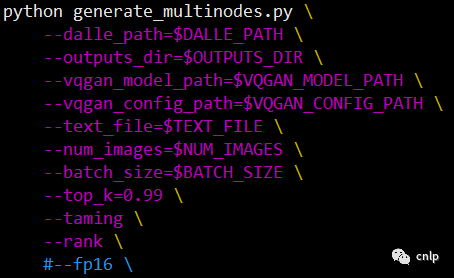
(d) 修改 light_vision_text/Light_VQGan_Dalle/clip 文件夹下的 rank_photo.py 文件,将41和42行修改为:
self.tokenizer = AutoTokenizer.from_pretrained(
'bert-base-chinese')(e) 修改 light_vision_text/Light_VQGan_Dalle 文件夹下的 generate.sh,将 --fp16 注释掉:
在 test_dalle.txt 中输入进行图像生成的中文文本内容:太阳落山了
运行:
# single-gpu testing
./generate.sh
# for example
./generate.sh ./dalle_small_model_pre_0924_lr1e-4_new_epoch7_data_point5761440.pt ./output_images 128 12 ./test_dalle.txt 生成的图像存储在
light_vision_text/Light_VQGan_Dalle/output_images 文件夹下:





往期精彩回顾
适合初学者入门人工智能的路线及资料下载机器学习及深度学习笔记等资料打印机器学习在线手册深度学习笔记专辑《统计学习方法》的代码复现专辑
AI基础下载黄海广老师《机器学习课程》视频课黄海广老师《机器学习课程》711页完整版课件本站qq群851320808,加入微信群请扫码:
