python爬虫
python 爬虫
————
————
模拟浏览器登录
cookie 和 session
会话(Session)跟踪是Web程序中常用的技术,用来跟踪用户的整个会话。常用的会话跟踪技术是Cookie与Session。Cookie通过在客户端记录信息确定用户身份,Session通过在服务器端记录信息确定用户身份。
cookie
理论上,一个用户的所有请求操作都应该属于同一个会话,而另一个用户的所有请求操作则应该属于另一个会话,二者不能混淆
Web应用程序是使用HTTP协议传输数据的。HTTP协议是无状态的协议。一旦数据交换完毕,客户端与服务器端的连接就会关闭,再次交换数据需要建立新的连接。这就意味着服务器无法从连接上跟踪会话。Cookie就是这样的一种机制。它可以弥补HTTP协议无状态的不足。在Session出现之前,基本上所有的网站都采用Cookie来跟踪会话。
由于HTTP是一种无状态的协议,服务器单从网络连接上无从知道客户身份。就给客户端们颁发一个通行证吧,每人一个,无论谁访问都必须携带自己通行证。这样服务器就能从通行证上确认客户身份了。这就是Cookie的工作原理。
Cookie实际上是一小段的文本信息。客户端请求服务器,如果服务器需要记录该用户状态,就使用response向客户端浏览器颁发一个Cookie。客户端浏览器会把Cookie保存起来。当浏览器再请求该网站时,浏览器把请求的网址连同该Cookie一同提交给服务器。服务器检查该Cookie,以此来辨认用户状态。服务器还可以根据需要修改Cookie的内容。

记录用户访问次数
Java中把Cookie封装成了javax.servlet.http.Cookie类。每个Cookie都是该Cookie类的对象。服务器通过操作Cookie类对象对客户端Cookie进行操作。通过request.getCookie()获取客户端提交的所有Cookie(以Cookie[]数组形式返回),通过response.addCookie(Cookiecookie)向客户端设置Cookie。
Cookie对象使用key-value属性对的形式保存用户状态,一个Cookie对象保存一个属性对,一个request或者response同时使用多个Cookie。因为Cookie类位于包javax.servlet.http.*下面,所以JSP中不需要import该类。
Cookie的不可跨域名性
Cookie具有不可跨域名性。根据Cookie规范,浏览器访问Google只会携带Google的Cookie,而不会携带Baidu的Cookie。Google也只能操作Google的Cookie,而不能操作Baidu的Cookie。Cookie在客户端是由浏览器来管理的。浏览器能够保证Google只会操作Google的Cookie而不会操作Baidu的Cookie,从而保证用户的隐私安全。浏览器判断一个网站是否能操作另一个网站Cookie的依据是域名。Google与Baidu的域名不一样,因此Google不能操作Baidu的Cookie。
Unicode编码:保存中文
Cookie中使用Unicode字符时需要对Unicode字符进行编码,否则会乱码。
提示:Cookie中保存中文只能编码。一般使用UTF-8编码即可
除了name与value之外,Cookie还具有其他几个常用的属性。每个属性对应一个getter方法与一个setter方法
| 属 性 名 | 描 述 |
|---|---|
| String name | 该Cookie的名称。Cookie一旦创建,名称便不可更改 |
| Object value | 该Cookie的值。如果值为Unicode字符,需要为字符编码。如果值为二进制数据,则需要使用BASE64编码 |
| int maxAge | 该Cookie失效的时间,单位秒。如果为正数,则该Cookie在maxAge秒之后失效。如果为负数,该Cookie为临时Cookie,关闭浏览器即失效,浏览器也不会以任何形式保存该Cookie。如果为0,表示删除该Cookie。默认为–1 |
| boolean secure | 该Cookie是否仅被使用安全协议传输。安全协议。安全协议有HTTPS,SSL等,在网络上传输数据之前先将数据加密。默认为false |
| String path | 该Cookie的使用路径。如果设置为“/sessionWeb/”,则只有contextPath为“/sessionWeb”的程序可以访问该Cookie。如果设置为“/”,则本域名下contextPath都可以访问该Cookie。注意最后一个字符必须为“/” |
| String domain | 可以访问该Cookie的域名。如果设置为“.google.com”,则所有以“google.com”结尾的域名都可以访问该Cookie。注意第一个字符必须为“.” |
| String comment | 该Cookie的用处说明。浏览器显示Cookie信息的时候显示该说明 |
| int version | 该Cookie使用的版本号。0表示遵循Netscape的Cookie规范,1表示遵循W3C的RFC 2109规范 |
Cookie的maxAge决定着Cookie的有效期,单位为秒(Second)。Cookie中通过getMaxAge()方法与setMaxAge(int maxAge)方法来读写maxAge属性。
如果maxAge属性为正数,则表示该Cookie会在maxAge秒之后自动失效。浏览器会将maxAge为正数的Cookie持久化,即写到对应的Cookie文件中。无论客户关闭了浏览器还是电脑,只要还在maxAge秒之前,登录网站时该Cookie仍然有效。下面代码中的Cookie信息将永远有效。
如果maxAge为负数,则表示该Cookie仅在本浏览器窗口以及本窗口打开的子窗口内有效,关闭窗口后该Cookie即失效。maxAge为负数的Cookie,为临时性Cookie,不会被持久化,不会被写到Cookie文件中。Cookie信息保存在浏览器内存中,因此关闭浏览器该Cookie就消失了。Cookie默认的maxAge值为–1。
如果maxAge为0,则表示删除该Cookie。Cookie机制没有提供删除Cookie的方法,因此通过设置该Cookie即时失效实现删除Cookie的效果。失效的Cookie会被浏览器从Cookie文件或者内存中删除
session
除了使用Cookie,Web应用程序中还经常使用Session来记录客户端状态。Session是服务器端使用的一种记录客户端状态的机制,使用上比Cookie简单一些,相应的也增加了服务器的存储压力
Session是另一种记录客户状态的机制,不同的是Cookie保存在客户端浏览器中,而Session保存在服务器上。客户端浏览器访问服务器的时候,服务器把客户端信息以某种形式记录在服务器上。这就是Session。客户端浏览器再次访问时只需要从该Session中查找该客户的状态就可以了。
如果说Cookie机制是通过检查客户身上的“通行证”来确定客户身份的话,那么Session机制就是通过检查服务器上的“客户明细表”来确认客户身份。Session相当于程序在服务器上建立的一份客户档案,客户来访的时候只需要查询客户档案表就可以了。
Session对应的类为javax.servlet.http.HttpSession类。每个来访者对应一个Session对象,所有该客户的状态信息都保存在这个Session对象里。Session对象是在客户端第一次请求服务器的时候创建的。Session也是一种key-value的属性对,通过getAttribute(Stringkey)和setAttribute(String key,Objectvalue)方法读写客户状态信息。Servlet里通过request.getSession()方法获取该客户的Session
request还可以使用getSession(boolean create)来获取Session。区别是如果该客户的Session不存在,request.getSession()方法会返回null,而getSession(true)会先创建Session再将Session返回。
当多个客户端执行程序时,服务器会保存多个客户端的Session。获取Session的时候也不需要声明获取谁的Session。Session机制决定了当前客户只会获取到自己的Session,而不会获取到别人的Session。各客户的Session也彼此独立,互不可见。
提示**:Session的使用比Cookie方便,但是过多的Session存储在服务器内存中,会对服务器造成压力。**
Session的生命周期
Session保存在服务器端。为了获得更高的存取速度,服务器一般把Session放在内存里。每个用户都会有一个独立的Session。如果Session内容过于复杂,当大量客户访问服务器时可能会导致内存溢出。因此,Session里的信息应该尽量精简。
Session在用户第一次访问服务器的时候自动创建。需要注意只有访问JSP、Servlet等程序时才会创建Session,只访问HTML、IMAGE等静态资源并不会创建Session。如果尚未生成Session,也可以使用request.getSession(true)强制生成Session。
Session生成后,只要用户继续访问,服务器就会更新Session的最后访问时间,并维护该Session。用户每访问服务器一次,无论是否读写Session,服务器都认为该用户的Session“活跃(active)”了一次。
由于会有越来越多的用户访问服务器,因此Session也会越来越多。为防止内存溢出,服务器会把长时间内没有活跃的Session从内存删除。这个时间就是Session的超时时间。如果超过了超时时间没访问过服务器,Session就自动失效了。
| 方 法 名 | 描 述 |
|---|---|
| void setAttribute(String attribute, Object value) | 设置Session属性。value参数可以为任何Java Object。通常为Java Bean。value信息不宜过大 |
| String getAttribute(String attribute) | 返回Session属性 |
| Enumeration getAttributeNames() | 返回Session中存在的属性名 |
| void removeAttribute(String attribute) | 移除Session属性 |
| String getId() | 返回Session的ID。该ID由服务器自动创建,不会重复 |
| long getCreationTime() | 返回Session的创建日期。返回类型为long,常被转化为Date类型,例如:Date createTime = new Date(session.get CreationTime()) |
| long getLastAccessedTime() | 返回Session的最后活跃时间。返回类型为long |
| int getMaxInactiveInterval() | 返回Session的超时时间。单位为秒。超过该时间没有访问,服务器认为该Session失效 |
| void setMaxInactiveInterval(int second) | 设置Session的超时时间。单位为秒 |
| void putValue(String attribute, Object value) | 不推荐的方法。已经被setAttribute(String attribute, Object Value)替代 |
| Object getValue(String attribute) | 不被推荐的方法。已经被getAttribute(String attr)替代 |
| boolean isNew() | 返回该Session是否是新创建的 |
| void invalidate() | 使该Session失效 |
虽然Session保存在服务器,对客户端是透明的,它的正常运行仍然需要客户端浏览器的支持。这是因为Session需要使用Cookie作为识别标志。HTTP协议是无状态的,Session不能依据HTTP连接来判断是否为同一客户,因此服务器向客户端浏览器发送一个名为JSESSIONID的Cookie,它的值为该Session的id(也就是HttpSession.getId()的返回值)。Session依据该Cookie来识别是否为同一用户。
该Cookie为服务器自动生成的,它的maxAge属性一般为–1,表示仅当前浏览器内有效,并且各浏览器窗口间不共享,关闭浏览器就会失效。
因此同一机器的两个浏览器窗口访问服务器时,会生成两个不同的Session。但是由浏览器窗口内的链接、脚本等打开的新窗口(也就是说不是双击桌面浏览器图标等打开的窗口)除外。这类子窗口会共享父窗口的Cookie,因此会共享一个Session。
注意:新开的浏览器窗口会生成新的Session,但子窗口除外。子窗口会共用父窗口的Session。例如,在链接上右击,在弹出的快捷菜单中选择“在新窗口中打开”时,子窗口便可以访问父窗口的Session。
cookie和session的区别
- cookie数据存放在客户的浏览器上,session数据放在服务器上.
- cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗考虑到安全应当使用session。
- 设置cookie时间可以使cookie过期。但是使用session-destory(),我们将会销毁会话。
- session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能考虑到减轻服务器性能方面,应当使用cookie。
- 单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie。(Session对象没有对存储的数据量的限制,其中可以保存更为复杂的数据类型)
两者最大的区别在于生存周期,一个是IE启动到IE关闭.(浏览器页面一关 ,session就消失了),一个是预先设置的生存周期,或永久的保存于本地的文件。(cookie)
直接使用已知的cookie访问
cookie保存在发起请求的客户端中,服务器利用cookie来区分不同的客户端。因为http是一种无状态的连接,当服务器一下子收到好几个请求时,是无法判断出哪些请求是同一个客户端发起的。而“访问登录后才能看到的页面”这一行为,恰恰需要客户端向服务器证明:“我是刚才登录过的那个客户端”。于是就需要cookie来标识客户端的身份,以存储它的信息(如登录状态)。
只要得到了别的客户端的cookie,我们就可以假冒成它来和服务器对话
具体步骤:
-
用浏览器登录,获取浏览器里的cookie字符串
network选项卡。在左边的Name一栏找到当前的网址,选择右边的Headers选项卡,查看Request Headers,这里包含了该网站颁发给浏览器的cookie
最好是在运行你的程序前再登录。如果太早登录,或是把浏览器关了,很可能复制的那个cookie就过期无效了。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zlRbPyeW-1677229209268)(C:\Users\00308559\AppData\Roaming\Typora\typora-user-images\image-20210922164713543.png)]```
import sys
import io
from urllib import request
def simulate_login():
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf8') # 改变标准输出的默认编码
# 登录后才能访问的网站
url = 'http://10.7.185.55:9000/'
# 浏览器登录后得到的cookie,也就是刚才复制的字符串
cookie_str = r"VTP_CODE=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJVc2VyRGV0YWlscyI6eyJVc2VybmFtZSI6IjEiLCJQYXNzd29yZCI6IiIsIkF1dGhvcml0aWVzIjoiIn0sIkNsaWVudERldGFpbHMiOnsiQ2xpZW50SWQiOiJaSzNZcEZ1Q1hHOUlZcGtZN0lodGhiYm1tbHhPRVNMTWl3dnZPZzU1Wk1JPSIsIkF1dGhvcml6ZWRHcmFudFR5cGVzIjoiIn0sImV4cCI6MTYzMjM0MjcxOSwiaXNzIjoidnRwIn0.OX-u7geGpdCTmV9g35peJ77fUXxaGxSZsYBJ0s20cxg"
# 登录后才能访问的网页
url = 'http://10.7.185.55:9000/#/plat'
req = request.Request(url)
# 设置cookie
req.add_header('cookie', cookie_str)
# 设置请求头
req.add_header('User-Agent',
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML"
", like Gecko) Chrome/89.0.4389.90 Safari/537.36")
resp = request.urlopen(req)
print(resp.read().decode('utf-8'))
if __name__=='__main__':
simulate_login()
模拟登陆后在携带得到的cookie 访问
先在程序中向网站发出登录请求,也就是提交包含登录信息的表单(用户名、密码等)。从响应中得到cookie,今后在访问其他页面时也带上这个cookie,就能得到只有登录后才能看到的页面。
具体步骤:
1.找出表单提交到的页面
2.找出要提交的数据
虽然你在浏览器里登陆时只填了用户名和密码,但表单里包含的数据可不只这些。从Form Data里就可以看到需要提交的所有数据。
import sys
import io
import urllib.request
import http.cookiejar
def simulate_login_1():
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf8') # 改变标准输出的默认编码
# 登录时需要POST的数据
data = {"dgfrety34#34d$g4d5g4344#43434t25&&534d":"ELcBlJ7CkFKvQgKmJPoo4d47zW+JUlnJpB5mUp9WT6ZlrwcaVNsT/FvOOwEVoKCEvix0f/l+VTepPO584SfBqymWCO/Z+zpOR3zALXE83xPLpUg13tW0gAoYbowScTxsioPaXa6mTg6+5MHUla+mqP6/VdUt9zsLwvmdBXcOXwf+pGJgFbpyl3Xhut4Z5wgYMCMwudPUsOzDl3pvMooK9FKTBa4XFiA2raa8vBT5npL8CrajxV2yqHBmieMacbQja7DQ70rU0VioTCu0DLn/WHfXkEo56E8w85fEtn1fjPGG3DcIq1TjmGui3otjau+6jlA16+cxCaKbWPH0kN8L2g==","t4dfgds5f*dsgas2#3dasr4ger434gdfs3g#3f":"WvfX7s3p7/QS9dQ/3AetOqqNUsDSB53T5+/hy3WTai3anr9IGbt4/9S/ALsMiMp5TZkWKRiUY99qaPUwiR8dW8haAUuZfw37Da03D6nX7R2uP2CTQyaUprlkcAQ2PuYA23fSpD56iJYAZXTh4rvWvOtd237ARPFtk50OyrlgBB39Ytz5CmpkVNvVGgBwLgWy8f3jCuWlh9oEuepqWPyjBh1cLTN/oiGT7TibQNcQWKy2K8wmkIwzmpwx4RlUHCzDB5sqExgfUmWFygpdiz5KeR56EY0RVH3Tw8KbOOBVET9X2E0rhHPMWXy0xpq4OHQbwds/Ic2IMgMDnKVCpoNwiQ==","code":"","key":""}
post_data = urllib.parse.urlencode(data).encode('utf-8')
# 设置请求头
headers = {
'User-agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML"
", like Gecko) Chrome/89.0.4389.90 Safari/537.36"}
# 登录时表单提交到的地址(用开发者工具可以看到)
login_url = 'http://10.7.185.55:9000/login'
# 构造登录请求
req = urllib.request.Request(login_url, headers=headers, data=post_data)
# 构造cookie
cookie = http.cookiejar.CookieJar()
# 由cookie构造opener
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cookie))
# 发送登录请求,此后这个opener就携带了cookie,以证明自己登录过
resp = opener.open(req)
# 登录后才能访问的网页
url = 'http://10.7.185.55:9000/#/plat'
# 构造访问请求
req = urllib.request.Request(url, headers=headers)
resp = opener.open(req)
code= resp.getcode()
head=resp.getheaders()
print(code)
print(head)
if __name__=='__main__':
simulate_login_1()
在Python处理Cookie,一般是通过cookiejar模块和 urllib模块的HTTPCookieProcessor处理器类一起使用。
cookiejar模块:主要作用是提供用于存储cookie的对象
HTTPCookieProcessor处理器:主要作用是处理这些cookie对象,并构建handler对象。
cookiejar 库:该模块主要的对象有CookieJar、FileCookieJar、MozillaCookieJar、LWPCookieJar。其实大多数情况下,我们只用CookieJar(),如果需要和本地文件交互,就用 MozillaCookjar()
模拟登录后用session保持登录状态
session是会话的意思。和cookie的相似之处在于,它也可以让服务器“认得”客户端。简单理解就是,把每一个客户端和服务器的互动当作一个“会话”。既然在同一个“会话”里,服务器自然就能知道这个客户端是否登录过。
session对象也是一个非常常用的对象,这个对象代表一次用户会话。一次用户会话的含义是:从客户端浏览器连接服务器开始,到客户端浏览器与服务器断开为止,这个过程就是一次会话。
session通常用于跟踪用户的会话信息,如判断用户是否登录系统,或者在购物车应用中,用于跟踪用户购买的商品等。
session范围内的属性可以在多个页面的跳转之间共享。一旦关闭浏览器,即session结束,session范围内的属性将全部丢失。
具体步骤:
1.找出表单提交到的页面
2.找出要提交的数据
import requests
import sys
import io
def simulate_login_2():
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf8') # 改变标准输出的默认编码
# 登录时需要POST的数据
data = {"dgfrety34#34d$g4d5g4344#43434t25&&534d":"ELcBlJ7CkFKvQgKmJPoo4d47zW+JUlnJpB5mUp9WT6ZlrwcaVNsT/FvOOwEVoKCEvix0f/l+VTepPO584SfBqymWCO/Z+zpOR3zALXE83xPLpUg13tW0gAoYbowScTxsioPaXa6mTg6+5MHUla+mqP6/VdUt9zsLwvmdBXcOXwf+pGJgFbpyl3Xhut4Z5wgYMCMwudPUsOzDl3pvMooK9FKTBa4XFiA2raa8vBT5npL8CrajxV2yqHBmieMacbQja7DQ70rU0VioTCu0DLn/WHfXkEo56E8w85fEtn1fjPGG3DcIq1TjmGui3otjau+6jlA16+cxCaKbWPH0kN8L2g==","t4dfgds5f*dsgas2#3dasr4ger434gdfs3g#3f":"WvfX7s3p7/QS9dQ/3AetOqqNUsDSB53T5+/hy3WTai3anr9IGbt4/9S/ALsMiMp5TZkWKRiUY99qaPUwiR8dW8haAUuZfw37Da03D6nX7R2uP2CTQyaUprlkcAQ2PuYA23fSpD56iJYAZXTh4rvWvOtd237ARPFtk50OyrlgBB39Ytz5CmpkVNvVGgBwLgWy8f3jCuWlh9oEuepqWPyjBh1cLTN/oiGT7TibQNcQWKy2K8wmkIwzmpwx4RlUHCzDB5sqExgfUmWFygpdiz5KeR56EY0RVH3Tw8KbOOBVET9X2E0rhHPMWXy0xpq4OHQbwds/Ic2IMgMDnKVCpoNwiQ==","code":"","key":""}
# 设置请求头
headers = {
'User-agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML"
", like Gecko) Chrome/89.0.4389.90 Safari/537.36"}
# 登录时表单提交到的地址(用开发者工具可以看到)
login_url = 'http://10.7.185.55:9000/login'
# 构造session
session = requests.Session()
# 在session中发送登录请求,此后这个session里就存储了cookie
# 可以用print(session.cookies.get_dict())查看
resp = session.post(login_url, data)
# 登录后才能访问的网页
url = 'http://10.7.185.55:9000/#/plat'
# 构造访问请求
resp = session.get(url)
print(resp.headers)
if __name__=='__main__':
simulate_login_2()
websocket接口测试
websocket简介


WebSocket 一种在单个 TCP 连接上进行全双工通讯的协议。使用ws或者wss统一的资源标识符,例如:ws://example.com/wsapi
WebSocket默认使用80端口,在TLS上默认使用443端口。
WebSocket 是独立的、创建在 TCP 上的协议,和 HTTP 的唯一关联是使用 HTTP 协议的101状态码进行协议切换,使用的 TCP 端口是80,可以用于绕过大多数防火墙的限制。
WebSocket 使得客户端和服务器之间的数据交换变得更加简单,允许服务端直接向客户端推送数据而不需要客户端进行请求,在 WebSocket API 中,浏览器和服务器只需要完成一次握手,两者之间就直接可以创建持久性的连接,并允许数据进行双向传送。
- 优点:
较小的控制开销,数据包大量减少;更强的实时性,服务器可以随时主动给客户端发送数据,
保持连接状态,更好的二进制支持
支持扩展,没有同源限制,可以发送文本,也可发送二进制数据… - 协议特点:
WebSocket是独立的、建立在TCP之上的协议,只需一次握手
WebSocket 是一种协议,是一种与 HTTP 同等的网络协议,两者都是应用层协议,都基于 TCP 协议。但是 WebSocket 是一种双向通信协议,在建立连接之后,WebSocket 的 server 与 client 都能主动向对方发送或接收数据。同时,WebSocket 在建立连接时需要借助 HTTP 协议,连接建立好了之后 client 与 server 之间的双向通信就与 HTTP 无关了。
一个例子
客户端发送请求:
GET / HTTP/1.1
Upgrade: websocket
Connection: Upgrade
Host: example.com
Origin: http://example.com
Sec-WebSocket-Key: sN9cRrP/n9NdMgdcy2VJFQ==
Sec-WebSocket-Version: 13
服务器响应:
HTTP/1.1 101 Switching Protocols
Upgrade: websocket
Connection: Upgrade
Sec-WebSocket-Accept: fFBooB7FAkLlXgRSz0BT3v4hq5s=
Sec-WebSocket-Location: ws://example.com/
Connection必须设置Upgrade,表示客户端希望连接升级
Upgrade字段必须设置Websocket,表示希望升级到Websocket协议。
Origin字段是可选的,通常用来表示在浏览器中发起此Websocket连接所在的页面,类似于Referer。但是,与Referer不同的是,Origin只包含了协议和主机名称。
Sec-WebSocket-Key是随机的字符串,服务器端会用这些数据来构造出一个SHA-1的信息摘要。把“Sec-WebSocket-Key”加上一个特殊字符串“258EAFA5-E914-47DA-95CA-C5AB0DC85B11”,然后计算SHA-1摘要,之后进行BASE-64编码,将结果做为“Sec-WebSocket-Accept”头的值,返回给客户端。如此操作,可以尽量避免普通HTTP请求被误认为Websocket协议。
其他一些定义在HTTP协议中的字段,如Cookie等,也可以在Websocket中使用。
做接口测试时,除了常见的http接口,还有一种比较多见,就是socket接口
import websocket
ws = websocket.WebSocket()
ws.connect("ws://example.com/websocket",
http_proxy_host="proxy_host_name",
http_proxy_port=3128)
创建一个websocket连接,这个模块支持通过http代理访问websocket。代理服务器允许使用connect方法连接到websocket端口。默认的squid设置是“只允许连接HTTPS端口”。
在websocket里,我们有常用的这几个方法:
on_message方法:
def on_message(ws, message):
print(message)
on_message是用来接受消息的,server发送的所有消息都可以用on_message这个方法来收取。
on_error方法:
def on_error(ws, error):
print(error)
这个方法是用来处理错误异常的,如果一旦socket的程序出现了通信的问题,就可以被这个方法捕捉到。
on_open方法:
def on_open(ws):
def run(*args):
for i in range(30):
# send the message, then wait
# so thread doesn't exit and socket
# isn't closed
ws.send("Hello %d" % i)
time.sleep(1)
time.sleep(1)
ws.close()
print("Thread terminating...")
Thread(target=run).start()
on_open方法是用来保持连接的,上面这样的一个例子,就是保持连接的一个过程,每隔一段时间就会来做一件事,他会在30s内一直发送hello。最后停止。
**on_close方法:**关闭socket连接
def on_close(ws):
print("### closed ###")
创建一个websocket应用
ws = websocket.WebSocketApp("wss://echo.websocket.org")
括号里面就是你要连接的socket的地址,在WebSocketApp这个实例化的方法里面还可以有其他参数,这些参数就是我们刚刚介绍的这些方法。
ws = websocket.WebSocketApp("ws://echo.websocket.org/",
on_message=on_message,
on_error=on_error,
on_close=on_close)
指定了这些参数之后就可以直接进行调用了,例如:
ws.on_open = on_open
如果我们想让我们的socket保持长连接,一直连接着,就可以使用run_forever方法:
ws.run_forever()
import websocket
from threading import Thread
import time
import sys
def on_message(ws, message):
print(message)
def on_error(ws, error):
print(error)
def on_close(ws):
print("### closed ###")
def on_open(ws):
def run(*args):
for i in range(3):
# send the message, then wait
# so thread doesn't exit and socket
# isn't closed
ws.send("Hello %d" % i)
time.sleep(1)
time.sleep(1)
ws.close()
print("Thread terminating...")
Thread(target=run).start()
if __name__ == "__main__":
websocket.enableTrace(True)
host = "ws://echo.websocket.org/"
ws = websocket.WebSocketApp(host,
on_message=on_message,
on_error=on_error,
on_close=on_close)
ws.on_open = on_open
ws.run_forever()
如果想要通信一条短消息,并在完成后立即断开连接,我们可以使用短连接:
from websocket import create_connection
ws = create_connection("ws://echo.websocket.org/")
print("Sending 'Hello, World'...")
ws.send("Hello, World")
print("Sent")
print("Receiving...")
result = ws.recv()
print("Received '%s'" % result)
ws.close()
Socket.IO框架
简介
简介:Socket.IO 本是一个面向实时 web 应用的 JavaScript 库,现在已成为拥有众多语言支持的Web即时通讯应用的框架。
Socket.IO 不等价于 WebSocket,WebSocket只是Socket.IO实现即时通讯的其中一种技术依赖
优点:Socket.IO 会自动选择合适双向通信协议,仅仅需要程序员对套接字的概念有所了解。
缺点:Socket.io要求客户端与服务器端均须使用该框架。
Socket.io不是Websocket,它只是将Websocket和轮询 (Polling)机制以及其它的实时通信方式封装成了通用的接口,并且在服务端实现了这些实时机制的相应代码。也就是说,Websocket仅仅是 Socket.io实现实时通信的一个子集。因此Websocket客户端连接不上Socket.io服务端,当然Socket.io客户端也连接不上Websocket服务端。
使用方法
-
创建服务器
# 安装 pip install python-socketio # 使用协程的方式运行socketio服务器 import evenlet eventlet.monkey_patch() import socketio import eventlet.wsgi # 打包称WSGI应用,使用WSGI服务器托管运行 sio = socketio.Server(async_mode='eventlet') # 指明启动模式 app = socketio.Middleware(sio) eventlet.wsgi.server(eventlet.listen(('', 8000)), app) -
事件处理
简介:不同于HTTP服务的编写方式,SocketIO服务编写不再以请求Request和响应Response来处理,而是对收发的数据以消息(message)来对待,收发的不同类别的消息数据又以事件(event)来区分。
""" 定义事件处理方法: connect 为特殊事件,当客户端连接后自动执行 disconnect 为特殊事件,当客户端断开连接后自动执行 connect、disconnect与自定义事件处理方法的函数传入参数不同 """ @sio.on('connect') def on_connect(sid, environ): """ 与客户端建立好连接后被执行 :param sid: string sid是socketio为当前连接客户端生成的识别id :param environ: dict 在连接握手时客户端发送的握手数据(HTTP报文解析之后的字典) """ pass @sio.on('disconnect') def on_disconnect(sid): """ 与客户端断开连接后被执行 :param sid: string sid是断开连接的客户端id """ pass # 以字符串的形式表示一个自定义事件,事件的定义由前后端约定 @sio.on('my custom event') def my_custom_event(sid, data): """ 自定义事件消息的处理方法 :param sid: string sid是发送此事件消息的客户端id :param data: data是客户端发送的消息数据 """ pass """ 发送事件消息 """ # 群发 sio.emit('my event', {'data': 'foobar'}) # 指定用户发送 sio.emit('my event', {'data': 'foobar'}, room=user_sid) # 给一组用户发送,提供room参数给用户分组 # 当客户端连接后,socketio会自动将客户端添加到以此客户端sid为名的room中 @sio.on('chat') def begin_chat(sid): sio.enter_room(sid, 'chat_users') # 将客户端从一个room中移除 @sio.on('exit_chat') def exit_chat(sid): sio.leave_room(sid, 'chat_users') # 查询sid客户端所在的所有房间 sio.rooms(sid) # 给一组用户发送消息的示例 @sio.on('my message') def message(sid, data): sio.emit('my reply', data, room='chat_users') # 发消息时跳过指定客户端 @sio.on('my message') def message(sid, data): sio.emit('my reply', data, room='chat_users', skip_sid=sid) # 对于'message'事件,可以使用send方法 sio.send({'data': 'foobar'}) sio.send({'data': 'foobar'}, room=user_sid) -
python客户端
import socketio
sio = socketio.Client()
@sio.on('connect')
def on_connect():
pass
@sio.on('event')
def on_event(data):
pass
sio.connect('http://10.211.55.7:8000')
sio.wait()
消息推送案例:
-
流程:
1.A关注B,写入数据库。
2.Web服务想消息队列中写入对B的通知消息
3.SocketIO服务从消息队列中取出推送的消息
4.B上线收到SocketIO推送的关注通知消息 -
中间件的选择
""" 使用Redis或者RabbitMQ作为消息中间件 """ mg = socketio.RedisManager('redis://0.0.0.0:8570') sio = socketio.Server(client_manager=mg) # 或者 pip install kombu mg = socketio.KombuManager('amqp://') sio = socketio.Server(client_manager=mg)
-
所有代码
""" 将IM服务单独设置为一个包 编写socketIO服务器启动代码project/im/main.py """ import eventlet eventlet.monkey_patch() import eventlet.wsgi import sys import os BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) sys.path.insert(0, os.path.join(BASE_DIR, 'common')) if len(sys.argv) < 2: print('Usage: python main.py [port]') exit(1) from server import app import chat import notify SERVER_ADDRESS = ('', port) sock = eventlet.listen(SERVER_ADDRESS) eventlet.wsgi.server(sock, app) """ 在project/im/server.py文件中补充消息队列rabbitmq的配置信息和jwt使用的秘钥 """ import socketio RABBITMQ = 'amqp://python:rabbitmqpwd@localhost:5672/project_demo' JWT_SECRET = 'TPmi4aLWRbyVq8zu9v82dWYW17/z+UvRnYTt4P6fAXA' mgr = socketio.KombuManager(RABBITMQ) sio = socketio.Server(async_mode='eventlet', client_manager=mgr) app = socketio.Middleware(sio) """ 在im目录中新建notify.py """ from server import sio, JWT_SECRET from werkzeug.wrappers import Request from utils.jwt_util import verify_jwt def check_jwt_token(environ): """ 检验jwt token :param environ: :return: """ request = Request(environ) token = request.args.get('token') if token: payload = verify_jwt(token, JWT_SECRET) if payload: user_id = payload.get('user_id') return user_id return None @sio.on('connect') def on_connect(sid, environ): """ 与客户端建立连接后执行 """ # 检验连接客户端的jwt token user_id = check_jwt_token(environ) print('user_id={}'.format(user_id)) # 若检验出user_id,将此客户端添加到user_id的room中 if user_id: sio.enter_room(sid, str(user_id)) @sio.on('disconnect') def on_disconnect(sid): """ 与客户端断开连接时执行 """ # 客户端离线时将客户端从所有房间中移除 rooms = sio.rooms(sid) for room in rooms: sio.leave_room(sid, room) """ 在project/app/src/user/following.py 添加用户关注的业务接口 """ class FollowingListResource(Resource): """ 关注用户 """ method_decorators = { 'post': [login_required], 'get': [login_required], } class FollowingListResource(Resource): """ 关注用户 """ method_decorators = { 'post': [login_required], 'get': [login_required], } def get(self): """ 获取粉丝列表 """ pass def post(self): """ 关注用户 """ json_parser = RequestParser() json_parser.add_argument('target', type=parser.user_id, required=True, location='json') args = json_parser.parse_args() target = args.target if target == g.user_id: return {'message': 'User cannot follow self.'}, 400 ret = 1 # 记录到数据库 try: follow = Relation(user_id=g.user_id, target_user_id=target, relation=Relation.RELATION.FOLLOW) db.session.add(follow) db.session.commit() except IntegrityError: db.session.rollback() ret = Relation.query.filter(Relation.user_id == g.user_id, Relation.target_user_id == target, Relation.relation != Relation.RELATION.FOLLOW)\ .update({'relation': Relation.RELATION.FOLLOW}) db.session.commit() if ret > 0: timestamp = time.time() cache_user.UserFollowingCache(g.user_id).update(target, timestamp) cache_user.UserFollowersCache(target).update(g.user_id, timestamp) cache_statistic.UserFollowingsCountStorage.incr(g.user_id) cache_statistic.UserFollowersCountStorage.incr(target) cache_user.UserRelationshipCache(g.user_id).clear() # 发送关注通知 _user = cache_user.UserProfileCache(g.user_id).get() _data = { 'user_id': g.user_id, 'user_name': _user['name'], 'user_photo': _user['photo'], 'timestamp': int(time.time()) } # 通过socketio提供的kombu管理对象 向rabbitmq中写入数据,记录需要由socketio服务器向客户端推送消息的任务 current_app.sio_mgr.emit('following notify', data=_data, room=str(target)) return {'target': target}, 201
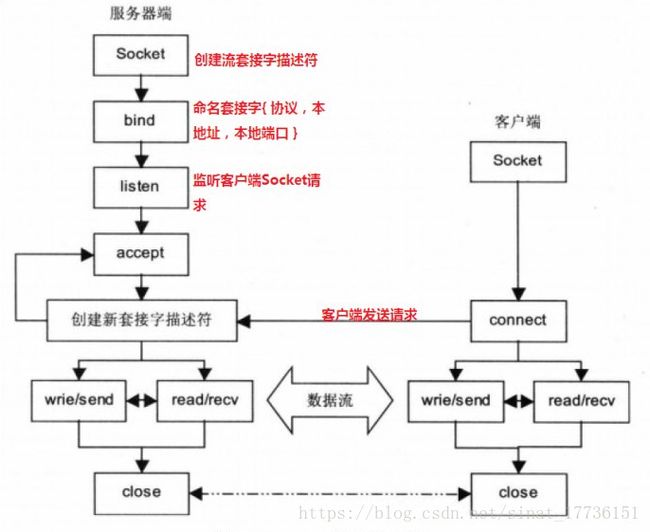
socket
网络应用中,两个应用程序同时需要向对方发送消息的能力(即全双工通信),所利用到的技术就是 socket,其能够提供端对端的通信。
WebSocekt 是 HTML5 规范中的一部分,其借鉴了 socket 的思想,为 client 和 server 之间提供了类似的双向通信机制。同时,WebSocket 又是一种新的应用层协议,包含一套标准的 API;而 socket 并不是一个协议,而是一组接口,其主要方便大家直接使用更底层的协议(比如 TCP 或 UDP)

1、 客户端Socket:首先调用Socket类的构造函数,以服务器的指定的IP地址或指定的主机名和指定的端口号为参数,创建一个Socket流,在创建Socket流的过程中包含了向服务器请求建立通讯连接的过程实现。
//创建Socket 客户端对象
Socket s = new Socket(“127.0.0.1”,6666);
2、服务器端Socket:服务器端套接字并不定位具体的客户端套接字,而是处于等待连接的状态,实时监控网络状态,等待客户端的连接请求。
//创建ServerSocket 服务器端对象。。
ServerSocket ss = new ServerSocket(6666);
3、监听服务器连接:
s = ss.accept();
4、 建立了客户端和服务器端通讯Socket后。就可以使用Socket的方法getInputStream()和getOutputStream()来创建输入/输出流。这样,使用Socket类后,网络输入输出也转化为使用流对象的过程。
5、 待通讯任务完毕后,我们用流对象的close()方法来关闭用于网络通讯的输入输出流,在用Socket对象的close()方法来关闭Socket。
TCP编程的服务器端一般步骤是:
1、创建一个socket,用函数socket();
2、设置socket属性,用函数setsockopt(); * 可选
3、绑定IP地址、端口等信息到socket上,用函数bind();
4、开启监听,用函数listen();
5、接收客户端上来的连接,用函数accept();
6、收发数据,用函数send()和recv(),或者read()和write();
7、关闭网络连接;
8、关闭监听;
struct sockaddr_in addr; 定义一个ip地址
TCP编程的客户端一般步骤是:
1、创建一个socket,用函数socket();
2、设置socket属性,用函数setsockopt();* 可选
3、绑定IP地址、端口等信息到socket上,用函数bind();* 可选
4、设置要连接的对方的IP地址和端口等属性;
5、连接服务器,用函数connect();
6、收发数据,用函数send()和recv(),或者read()和write();
7、关闭网络连接;
UDP编程的服务器端一般步骤是:
1、创建一个socket,用函数socket();
2、设置socket属性,用函数setsockopt();* 可选
3、绑定IP地址、端口等信息到socket上,用函数bind();
4、循环接收数据,用函数recvfrom();
5、关闭网络连接;
UDP编程的客户端一般步骤是:
1、创建一个socket,用函数socket();
2、设置socket属性,用函数setsockopt();* 可选
3、绑定IP地址、端口等信息到socket上,用函数bind();* 可选
4、设置对方的IP地址和端口等属性;
5、发送数据,用函数sendto();
6、关闭网络连接;
socketio模块
def start_background_task(self, target, *args, **kwargs):
"""Start a background task using the appropriate async model.
This is a utility function that applications can use to start a
background task using the method that is compatible with the
selected async mode.
:param target: the target function to execute.
:param args: arguments to pass to the function.
:param kwargs: keyword arguments to pass to the function.
This function returns an object compatible with the `Thread` class in
the Python standard library. The `start()` method on this object is
already called by this function.
"""
return self.eio.start_background_task(target, *args, **kwargs)
self.eio = self._engineio_client_class()(**engineio_options)
def _engineio_client_class(self):
return engineio.Client
def start_background_task(self, target, *args, **kwargs):
"""Start a background task.
This is a utility function that applications can use to start a
background task.
:param target: the target function to execute.
:param args: arguments to pass to the function.
:param kwargs: keyword arguments to pass to the function.
This function returns an object compatible with the `Thread` class in
the Python standard library. The `start()` method on this object is
already called by this function.
"""
th = threading.Thread(target=target, args=args, kwargs=kwargs)
th.start()
return th
socket、socketio、WebSocket的区别与联系
- socket 是通信的基础,并不是一个协议,Socket是应用层与TCP/IP协议族通信的中间软件抽象层,它是一组接口。在设计模式中,Socket其实就是一个门面模式,它把复杂的TCP/IP协议族和UDP协议族隐藏在Socket接口后面,对用户来说,一组简单的接口就是全部,让Socket去组织数据,以符合指定的协议。
- WebSocket 是html5新增加的一种通信协议,可以类比于http协议。常见的应用方式如弹幕、web在线游戏。
- socketio 是基于socket连接后(并没有自己实现socket的链接而是复用了web框架或gevent、eventlet中的socket)对网络输入输出流的处理,封装了send、emit、namespace、asyncio 、订阅等接口,同时扩展使用了redis、rabbitmq消息队列的方式与其他进程通信。
带星号*的参数
*元组
- 单个 星号*parameter是用来接受任意多个参数并将其放在一个元组中。
>>> def demo(*p):
print(p)
>>> demo(1,2,3)
(1, 2, 3)
- 函数在调用多个参数时,在列表、元组、集合、字典及其他可迭代对象作为实参,并在前面加 *
如 *(1,2,3)解释器将自动进行解包然后传递给多个单变量参数(参数个数要对应相等)。
>>> def d(a,b,c):
print(a,b,c)
>>> d(1,2,3)
1 2 3
>>> a=[1,2,3]
>>> b=[1,2,3]
>>> c=[1,2,3]
>>> d(a,b,c)
[1, 2, 3] [1, 2, 3] [1, 2, 3]
>>> d(a)
1 2 3
**字典
**parameter用于接收类似于关键参数一样赋值的形式的多个实参放入字典中(即把该函数的参数转换为字典)。
>>> def demo(**p):
for i in p.items():
print(i)
>>> demo(x=1,y=2)
('x', 1)
('y', 2)
接口测试
什么是接口
接口测试主要用于外部系统与系统之间以及内部各个子系统之间的交互点,定义特定的交互点,然后通过这些交互点,通过一些特殊的规则,即协议来进行数据之间的交互。
API:Application Programming Interface,即应用程序编程接口
我们常说的API就是接口的意思,现在常用的web项目,app项目的接口都是基于HTTP请求的,有些系统内部之间调用的接口不需要测试。
一个API中通常包含:
method:请求方法
URL:唯一资源定位符
params:参数
Authorization:认证方式
Headers:消息头
Body:消息体
常见的接口协议
1、HTTP 超文本传输协议
2、HTTPS 安全超文本传输协议
3、FTP 文件传输协议( Xshell的文件拖拽)
4、TCP 网络控制协议
5、IP 互联网协议
6、UDP 用户数据协议
接口的类型
接口一般分为2种:
- 程序内部的接口:方法与方法之间,模块与模块之间的交互,程序内部抛出的接口,比如登录模块和发帖模块,要发帖必须先登录,2个模块就要有交互。
2)系统对外的接口:比如要从别的网站/服务器上获取资源信息,别人不会把数据库共享给你,只能给你提供一个写好的方法来获取数据,引用他们提供的接口就能使用他写好的方法,
接口的分类:
webservice接口:走soap协议通过http传输,请求报文和返回报文都是xml格式的,在测试时通过工具才能进行调用,测试。
http api接口:走http协议,通过路径来区分调用的方法,请求报文都是key-value形式的,返回报文一般都是json串,有get和post等方法,这也是最常用的两种请求方式。
数据库访问接口:
数据库访问接口是走jdbc方式连接数据,对数据库进行增删改查操作,需要使用工具进行测试。
json是一种通用的数据类型,其本质是字符串,他与其他语言无关,只是可以经过稍稍加工可以转换成其他语言的数据类型,比如可以转换成Python中的字典,key-value的形式,可以转换成JavaScript中的原生对象,可以转换成java中的类对象等。
接口的本质和工作原理:
接口,可以简单的理解为URL,工作原理:URL通过get或者post请求向服务器发送一些东西,然后得到一些相应的返回值,本质就是:数据的传输与接收。
为什么接口测试?
-
越底层发现bug,它的修复成本是越低的。
-
前端随便变,接口测好了,后端不用变。
-
检查系统的安全性、稳定性,前端传参不可信,比如京东购物,前端价格不可能传入-1元,但是通过接口可以传入-1元。
-
如今的系统复杂度不断上升,传统的测试方法成本急剧增加且测试效率大幅下降,接口测试可以提供这种情况下的解决方案。
-
接口测试相对容易实现自动化持续集成,且相对UI自动化也比较稳定,可以减少人工回归测试人力成本与时间,缩短测试周期,支持后端快速发版需求。接口持续集成是为什么能低成本高收益的根源。
-
现在很多系统前后端架构是分离的,从安全层面来说:
只依赖前端进行限制已经完全不能满足系统的安全要求, 需要后端同样进行控制,在这种情况下就需要从接口层面进行验证。
前后端传输、日志打印等信息是否加密传输也是需要验证的,特别是涉及到用户的隐私信息,如×××,银行卡等
怎样做接口测试?
–由于项目前后端调用主要是基于http协议的接口,所以测试接口时主要是通过工具或代码模拟http请求的发送与接收。
工具有很多如:postman、jmeter、soupUI、java+httpclient、robotframework+httplibrary等。
也可以用 接口自动化来实现,就是用代码实现,框架和UI自动化差不多,发送请求用断言来判断。
接口测试需要掌握的知识?
①了解系统及内部各个组件之间的业务逻辑交互;
②了解接口的I/O(input/output:输入输出);
③了解协议的基本内容,包括:通信原理、三次握手、常用的协议类型、报文构成、数据传输方式、常见的状态码、URL构成等;
④常用的接口测试工具,比如:jmeter、loadrunner、postman、soapUI等;
⑤数据库基础操作命令(检查数据入库、提取测试数据等);
⑥常见的字符类型,比如:char、varchar、text、int、float、datatime、string等;
测试流程:
接口测试属于功能测试,也可以看作是需要了解部分代码的灰盒测试。
1)测试接口文档。
2)根据接口文档编写测试用例
3)执行测试,查看返回的数据是否正确(主要检测返回的是否和接口文档中定义的一样,还有根据条件查询数据库,检测返回的数据是否和数据库中的保持一致,)
基于HTTP协议的API接口测试
接口组成
请求+返回
接口请求 = 请求的URL + 请求头(User-Agent、Content-Type) + 请求方法(GET/POST/PUT/DELETE)+ 请求参数(拼接在URL 后面/请求的body中)
接口测试关注点


RESTful
REST 指的是一组架构约束条件和原则。" 如果一个架构符合 REST 的约束条件和原则,就称它为 RESTful 架构。隐藏在 RESTful 背后的理念就是使用 Web的现有特征和能力,更好地使用现有 Web 标准中的一些准则和约束。虽然 REST 本身受 Web技术的影响很深, 但是理论上 REST 架构风格并不是绑定在 HTTP 上,只不过目前 HTTP 是唯一与 REST 相关的实例。所以我们这里描述的 REST 也是通过 HTTP 实现的 REST。
资源与 URI
资源可以是实体(例如手机号码),也可以只是一个抽象概念(例如价值) 。下面是一些资源的例子:
某用户的手机号码
某用户的个人信息
URI(Uniform Resource Identifier)就是标识资源,并且是唯一标识。URI 既可以看成是资源的地址,也可以看成是资源的名称。如果某些信息没有使用 URI 来表示,那它就不能算是一个资源, 只能算是资源的一些信息而已。
定义了通用的URI语法:
URI = scheme “://” authority “/” path [ “?” query ][ “#” fragment ]
- scheme: 指底层用的协议,如http、https、ftp
- host: 服务器的IP地址或者域名
- port: 端口,http中默认80
- path: 访问资源的路径,就是咱们各种web 框架中定义的route路由
- query: 为发送给服务器的参数
- fragment: 锚点,定位到页面的资源,锚点为资源id
URL组成格式
Copy协议\\: 服务器地址:端口号\资源路径?参数1=值1&参数2=值2
如:https://www.sojson.com/open/api/weather/json.shtml?city=北京
注意:?号要使用英文?,不能使用中文?
URL编码
URL编码是一种浏览器用来打包请求参数及表单参数的格式, 参数和参数之间使用&分割,非ASCII码使用%加16进制编码替换
如:https://www.sojson.com/open/api/weather/json.shtml?city=北京
编码后为:https://www.sojson.com/open/api/weather/json.shtml?city=%E5%8C%97%E4%BA%AC
以 github 网站为例,给出一些还算不错的 URI:
https://github.com/git
https://github.com/git/git
https://github.com/git/git/blob/master/block-sha1/sha1.h
统一资源接口
RESTful 架构应该遵循统一接口原则,统一接口包含了一组受限的预定义的操作,不论什么样的资源,都是通过使用相同的接口进行资源的访问。如使用GET,PUT,POST,并遵循这些方法的语义。
RESTful 架构的主要原则
网络上的所有事物都被抽象为资源。
每个资源都有一个唯一的资源标识符。
同一个资源具有多种表现形式(xml,json 等)。
对资源的各种操作不会改变资源标识符。
所有的操作都是无状态。
符合 REST 原则的架构方式即可称为 RESTful。
REST 主要对以下两方面进行了规范
定位资源的URL风格,如
https://www.baidu.com/v/web/first/course
https://www.baidu.com/v/web/second/course
采用HTTP协议规定的GET、POST、PUT、DELETE动作处理资源的增删改查操作。
RESTful API 设计
API 与用户的通信协议,总是使用 HTTPs 协议。尽量将 API 部署在专用域名之下,https://api.example.com,如果API很简单,不会有进一步扩展,可以考虑放在主域名下。https://example.org/api/
版本
应该将 API 的版本号放入 URL。https://api.example.com/v1/
另一种做法是,将版本号放在 HTTP 头信息中,但不如放入 URL 方便和直观。Github 采用这种做法。
路径(Endpoint)
表示 API 的具体网址。在 RESTful 架构中,所用的名词往往与数据库的表格名对应。一般来说,数据库中的表都是同种记录的"集合"(collection)。
URL中不能有动词,结尾不应该包含斜杠“/”
在Restful架构中,每个网址代表的是一种资源,所以网址中不能有动词,只能有名词,动词由HTTP的 get、post、put、delete 四种方法来表示。这是作为URL路径中处理中最重要的规则之一,正斜杠(/)不会增加语义值,且可能导致混淆。REST API不允许一个尾部的斜杠,不应该将它们包含在提供给客户端的链接的结尾处。
正斜杠分隔符”/“必须用来指示层级关系
rul的路径中的正斜杠“/“字符用于指示资源之间的层次关系。
http://api.user.com/schools/grades/classes/boys
- 学校中所有的男生
http://api.college.com/students/3248234/courses
- 检索id为3248234的学生学习的所有课程的清单。
如通过API提供动物园信息,包括动物和雇员信息,则路径应该设计成如下:
https://api.example.com/v1/zoos
https://api.example.com/v1/animals
https://api.example.com/v1/employe
应该使用连字符”-“来提高URL的可读性,而不是使用下划线”_”
为了使URL容易让人们理解,请使用连字符”-“字符来提高长路径中名称的可读性。
一些文本查看器为了区分强调URI,常常会在URI下加上下划线。这样下划线”_”字符可能被文本查看器中默认的下划线部分地遮蔽或完全隐藏。
为避免这种混淆,请使用连字符”-“而不是下划线
URL路径中首选小写字母
RFC 3986将URI定义为区分大小写,但scheme 和 host components除外。
URL路径名词均为复数
为了保证url格式的一致性,建议使用复数形式
常用的 HTTP 动词
有下面五个(括号里是对应的 SQL 命令)。
GET(SELECT):从服务器取出资源(一项或多项)。
POST(CREATE):在服务器新建一个资源。
PUT(UPDATE):在服务器更新资源(客户端提供改变后的完整资源)。
PATCH(UPDATE):在服务器更新资源(客户端提供改变的属性)。
DELETE(DELETE):从服务器删除资源。
还有两个不常用的 HTTP 动词。
HEAD:获取资源的元数据。
OPTIONS:获取信息,关于资源的哪些属性是客户端可以改变的。
举例
GET /zoos:列出所有动物园
POST /zoos:新建一个动物园
GET /zoos/ID:获取某个指定动物园的信息
PUT /zoos/ID:更新某个指定动物园的信息(提供该动物园的全部信息)
PATCH /zoos/ID:更新某个指定动物园的信息(提供该动物园的部分信息)
DELETE /zoos/ID:删除某个动物园
GET /zoos/ID/animals:列出某个指定动物园的所有动物
DELETE /zoos/ID/animals/ID:删除某个指定动物园的指定动物
过滤信息(Filtering)
如果记录数量很多,服务器不可能都将它们返回给用户。API 应该提供参数,过滤返回结果。下面是一些常见的参数
?limit=10:指定返回记录的数量。
?offset=10:指定返回记录的开始位置。
?page=2&per_page=100:指定第几页,以及每页的记录数。
?sortby=name&order=asc:指定返回结果按照哪个属性排序,以及排序顺序。
?animal_type_id=1:指定筛选条件
允许 API 路径和 URL 参数偶尔有重复。比如,GET /zoo/ID/animals与 GET /animals?zoo_id=ID 的含义是相同的。
错误处理(Error handling)
如果状态码是 4xx,就应该向用户返回出错信息。一般来说,返回的信息中将 error 作为键名,出错信息作为键值即可。
{
error: “Invalid API key”
}
返回结果
针对不同操作,服务器向用户返回的结果应该符合以下规范。
GET /collection:返回资源对象的列表(数组)
GET /collection/resource:返回单个资源对象
POST /collection:返回新生成的资源对象
PUT /collection/resource:返回完整的资源对象
PATCH /collection/resource:返回完整的资源对象
DELETE /collection/resource:返回一个空文档
Hypermedia API
返回结果中提供链接,连向其他 API 方法,使得用户不查文档,也知道下一步应该做什么。当用户向 api.example.com 的根目录发出请求,会得到这样一个文档。
{ "link": {
"rel": "collection https://www.example.com/zoos",
"href": "https://api.example.com/zoos",
"title": "List of zoos",
"type": "application/vnd.yourformat+json"
}
}
link 属性,用户读取这个属性就知道下一步该调用什么 API 了。href 表示 API 的路径,title 表示 API 的标题,type 表示返回类型。
Hypermedia API 的设计被称为 HATEOAS。Github 的 API 就是这种设计,访问 api.github.com会得到一个所有可用 API 的网址列表。
{ "current_user_url": "https://api.github.com/user", "authorizations_url": "https://api.github.com/authorizations", // ... }
如果想获取当前用户的信息,应该去访问 api.github.com/user,然后就得到了下面结果。
{
"message": "Requires authentication",
"documentation_url": "https://developer.github.com/v3"
}
上面代码表示,服务器给出了提示信息,以及文档的网址。
(1) API 的身份认证应该使用 OAuth 2.0 框架。
(2) 服务器返回的数据格式,应该尽量使用 JSON,避免使用 XML。
多线程
后端性能指标
指标的基本概念
事务(Transaction)
在web性能测试中,一个事务表示一个“从用户发送请求->web server接受到请求,进行处理-> web server向DB获取数据->生成用户的object(页面),返回给用户”的过程,一般的响应时间都是针对事务而言的。
请求响应时间
请求响应时间指的是从客户端发起的一个请求开始,到客户端接收到从服务器端返回的响应结束,这个过程所耗费的时间,在某些工具中,响应通常会称为“TTLB”,即"Time To Last Byte",意思是从发起一个请求开始,到客户端接收到最后一个字节的响应所耗费的时间,响应时间的单位一般为“秒”或者“毫秒”。一个公式可以表示:响应时间=网络响应时间+应用程序响应时间。
(1)在1秒钟之内,页面给予用户响应并有所显示,可认为是“很不错的”;
(2)在1~2秒钟内,页面给予用户响应并有所显示,可认为是“好的”;
(3)在2~3秒钟内,页面给予用户响应并有所显示,可认为是“勉强接受的”;
(4)超过3秒就让人有点不耐烦了,用户很可能不会继续等待下去;
事务响应时间
事务可能由一系列请求组成,事务的响应时间主要是针对用户而言,属于宏观上的概念,是为了向用户说明业务响应时间而提出的.例如:跨行取款事务的响应时间就是由一系列的请求组成的.事务响应时间是直接衡量系统性能的参数.
并发用户数
并发一般分为2种情况。一种是严格意义上的并发,即所有的用户在同一时刻做同一件事情或者操作,
另外一种并发是广义范围的并发。多个用户对系统发出了请求或者进行了操作,但是这些请求或者操作可以是相同的,也可以是不同的。对整个系统而言,仍然是有很多用户同时对系统进行操作,因此也属于并发的范畴。
对于WEB性能测试而言,这2种并发情况一般都需要进行测试,通常做法是先进行严格意义上的并发测试
用户并发数量:关于用户并发的数量,有2种常见的错误观点。 一种错误观点是把并发用户数量理解为使用系统的全部用户的数量,理由是这些用户可能同时使用系统;还有一种比较接近正确的观点是把在线用户数量理解为并发用户数量。实际上在线用户也不一定会和其他用户发生并发,例如正在浏览网页的用户,对服务器没有任何影响,但是,在线用户数量是计算并发用户数量的主要依据之一。
吞吐量
指的是在一次性能测试过程中网络上传输的数据量的总和.吞吐量/传输时间,就是吞吐率.
TPS(transaction per second)
每秒钟系统能够处理的交易或者事务的数量.它是衡量系统处理能力的重要指标.
点击率
**每秒钟用户向WEB服务器提 交的HTTP请求数.**WEB应用是"请求-响应"模式,用户发出一次申请,服务器就要处理一次,所以点击是WEB应用能够处理的交易的最小单位.如果把每次点击定义为一个交易,点击率和TPS就是一个概念.容易看出,点击率越大,对服务器的压力越大.点击率只是一个性能参考指标,重要的是分析点击时产生的影响。
资源利用率
指的是对不同的系统资源的使用程度,例如服务器的CPU利用率,磁盘利用率等.资源利用率是分析系统性能指标进而改善性能的主要依据,因此是WEB性能测试工作的重点.
资源利用率主要针对WEB服务器,操作系统,数据库服务器,网络等,是测试和分析瓶颈的主要参考.在WEB性能测试中,更根据需要采集相应的参数进行分析
通用指标
Web服务器指标
http接口性能要求
Form data & Payload
FormData和Payload是浏览器传输给接口的两种格式,这两种方式浏览器是通过Content-Type来进行区分的,如果是 application/x-www-form-urlencoded的话,则为formdata方式,如果是application/json或multipart/form-data的话,则为 request payload
的方式。
application/x-www-form-urlencoded
- 最常见的POST提交数据方式。
- 原生form默认的提交方式(可以使用enctype指定提交数据类型)。
- jquery,zepto等默认post请求提交的方式。
application/x-www-form-urlencoded 是最常用的一种请求编码方式,支持GET/POST等方法,所有数据变成键值对的形式 key1=value1&key2=value2的形式,并且特殊字符需要转义成utf-8编号,如空格会变成 %20;
如果请求类型type是GET的话,那么格式化的字符串将直接拼接在url后发送到服务端; 如果请求类型是POST, 那么格式化的字符串将放在http body的Form Data中发送。
在http请求中,ContentType都是默认的值 application/x-www-form-urlencoded, 这种编码格式的特点是:name/value值对,
每组之间使用&连接,而name与value之间是使用 = 连接,比如 key=xxx&name=111&password=123456; 是很简单的json形式,比如如下:
{
a: 1,
b: 2
}
它会解析成 a=1&b=2这样的,但是在一些复杂的情况下,比如需要传一个复杂的json对象,也就是对象嵌套数组的情况下,比如如下代码:
{
obj: [
{
"name": 111,
"password": 22
}
]
}
application/x-www-form-urlencoded这种形式传递的话, 会被解析成 obj[0]['name']=111&obj[0].['password']=2这样的。
application/json
对于一些复制的数据对象,对象里面再嵌套数组的话,建议使用application/json传递比较好,通过json的形式将数据发送给服务器。
Python的字典的格式和JSON格式,稍有不同:
- 字典中的引号支持单引号和双引号,JSON格式只支持双引号
- 字典中的True/False首字母大写,JSON格式为true/false
- 字典中的空值为None, JSON格式为null
JSON格式操作方法
- 序列化(字典 -> 文本/文件句柄): json.dumps()/json.dump()
- 反序列化(文本/文件句柄 -> 字典) : json.loads()/json.load()
multipart/form-data
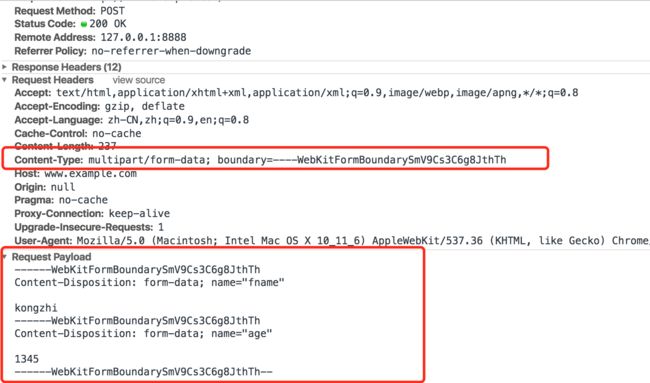
使用表单上传文件时,必须指定表单的 enctype属性值为 multipart/form-data. 请求体被分割成多部分,每部分使用 --boundary分割;
requests.elapsed
发送请求和响应到达之间经过的时间量(以时间增量表示)。此属性专门测量从发送请求的第一个字节到完成对标头的解析所花费的时间。因此,它不受响应内容或stream关键字参数值的影响。
elapsed里面几个方法介绍
- total_seconds 总时长,单位秒
- days 以天为单位
- microseconds (>= 0 and less than 1 second) 获取微秒部分,大于0小于1秒
- seconds Number of seconds (>= 0 and less than 1 day) 秒,大于0小于1天
- max = datetime.timedelta(999999999, 86399, 999999) 最大时间
- min = datetime.timedelta(-999999999) 最小时间
- resolution = datetime.timedelta(0, 0, 1) 最小时间单位
import requests
r = requests.get("http://www.cnblogs.com/yoyoketang/")
print(r.elapsed)
print(r.elapsed.total_seconds())
print(r.elapsed.microseconds)
print(r.elapsed.seconds)
print(r.elapsed.days)
print(r.elapsed.max)
print(r.elapsed.min)
print(r.elapsed.resolution)
}
]
}
application/x-www-form-urlencoded这种形式传递的话, 会被解析成` obj[0]['name']=111&obj[0].['password']=2`这样的。
### application/json
对于一些复制的数据对象,对象里面再嵌套数组的话,建议使用application/json传递比较好,通过json的形式将数据发送给服务器。
 Python的字典的格式和JSON格式,稍有不同:
- 字典中的引号支持单引号和双引号,JSON格式只支持双引号
- 字典中的True/False首字母大写,JSON格式为true/false
- 字典中的空值为None, JSON格式为null
JSON格式操作方法
- 序列化(字典 -> 文本/文件句柄): json.dumps()/json.dump()
- 反序列化(文本/文件句柄 -> 字典) : json.loads()/json.load()
### **multipart/form-data**
Python的字典的格式和JSON格式,稍有不同:
- 字典中的引号支持单引号和双引号,JSON格式只支持双引号
- 字典中的True/False首字母大写,JSON格式为true/false
- 字典中的空值为None, JSON格式为null
JSON格式操作方法
- 序列化(字典 -> 文本/文件句柄): json.dumps()/json.dump()
- 反序列化(文本/文件句柄 -> 字典) : json.loads()/json.load()
### **multipart/form-data**
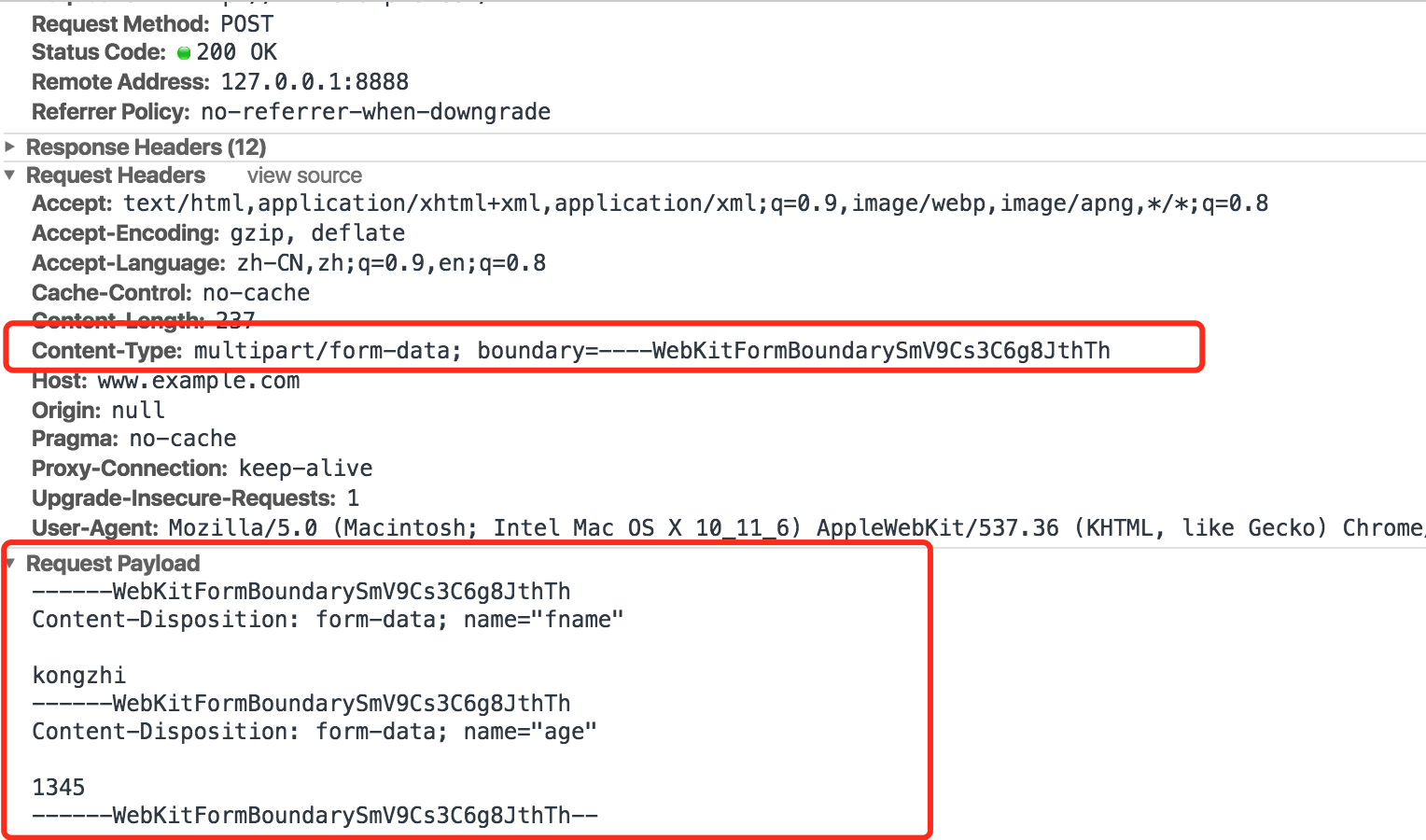 使用表单上传文件时,必须指定表单的 enctype属性值为 multipart/form-data. 请求体被分割成多部分,每部分使用 --boundary分割;
## requests.elapsed
发送请求和响应到达之间经过的时间量(以时间增量表示)。此属性专门测量从发送请求的第一个字节到完成对标头的解析所花费的时间。因此,它不受响应内容或stream关键字参数值的影响。
elapsed里面几个方法介绍
- total_seconds 总时长,单位秒
- days 以天为单位
- microseconds (>= 0 and less than 1 second) 获取微秒部分,大于0小于1秒
- seconds Number of seconds (>= 0 and less than 1 day) 秒,大于0小于1天
- max = datetime.timedelta(999999999, 86399, 999999) 最大时间
- min = datetime.timedelta(-999999999) 最小时间
- resolution = datetime.timedelta(0, 0, 1) 最小时间单位
```python
import requests
r = requests.get("http://www.cnblogs.com/yoyoketang/")
print(r.elapsed)
print(r.elapsed.total_seconds())
print(r.elapsed.microseconds)
print(r.elapsed.seconds)
print(r.elapsed.days)
print(r.elapsed.max)
print(r.elapsed.min)
print(r.elapsed.resolution)
使用表单上传文件时,必须指定表单的 enctype属性值为 multipart/form-data. 请求体被分割成多部分,每部分使用 --boundary分割;
## requests.elapsed
发送请求和响应到达之间经过的时间量(以时间增量表示)。此属性专门测量从发送请求的第一个字节到完成对标头的解析所花费的时间。因此,它不受响应内容或stream关键字参数值的影响。
elapsed里面几个方法介绍
- total_seconds 总时长,单位秒
- days 以天为单位
- microseconds (>= 0 and less than 1 second) 获取微秒部分,大于0小于1秒
- seconds Number of seconds (>= 0 and less than 1 day) 秒,大于0小于1天
- max = datetime.timedelta(999999999, 86399, 999999) 最大时间
- min = datetime.timedelta(-999999999) 最小时间
- resolution = datetime.timedelta(0, 0, 1) 最小时间单位
```python
import requests
r = requests.get("http://www.cnblogs.com/yoyoketang/")
print(r.elapsed)
print(r.elapsed.total_seconds())
print(r.elapsed.microseconds)
print(r.elapsed.seconds)
print(r.elapsed.days)
print(r.elapsed.max)
print(r.elapsed.min)
print(r.elapsed.resolution)