机器学习第11天:降维
文章目录
机器学习专栏
主要思想
主流方法
1.投影
二维投射到一维
三维投射到二维
2.流形学习
一、PCA主成分分析
介绍
代码
二、三内核PCA
具体代码
三、LLE
结语
机器学习专栏
机器学习_Nowl的博客-CSDN博客
主要思想
介绍:当一个任务有很多特征时,我们找到最主要的,剔除不重要的
主流方法
1.投影
投影是指找到一个比当前维度低的维度面(或线),这个维度面或线离当前所有点的距离最小,然后将当前维度投射到小维度上
二维投射到一维
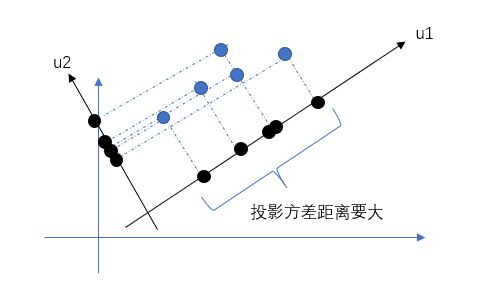
三维投射到二维

2.流形学习
当然,当数据集投影后在低纬度上有重叠的时候,我们应该考虑别的方法
我们来看看被称为瑞士卷数据集的三维图

经过两种降维数据的处理,我们得到下面两幅二维数据可视化图

我们可以看到,左边的数据 有很多重合的点,它使用的是投影技术,而右图就像将数据集一层层展开一样,这就是流形学习
我们接下来介绍三种常见的具体实现这些的降维方法
一、PCA主成分分析
介绍
pca主成分分析是一种投影降维方法
PCA主成分分析的思想就是:识别最靠近数据的超平面,然后将数据投影到上面
代码
这是一个最简单的示例,有一个两行三列的特征表x,我们将它降维到2个特征(n_components参数决定维度)
from sklearn.decomposition import PCA
x = [[1, 2, 3], [3, 4, 5]]
pca = PCA(n_components=2)
x2d = pca.fit_transform(x)
print(x)
print(x2d)运行结果

二、三内核PCA
内核可以将实例隐式地映射到高维空间,这有利于模型寻找到数据的特征(维度过低往往可能欠拟合),其他的思想与PCA相同
具体代码
1.线性内核
特点: 线性核对原始特征空间进行线性映射,相当于没有映射,直接在原始空间上进行PCA。适用于数据在原始空间中是线性可分的情况。
import matplotlib.pyplot as plt
from sklearn.datasets import make_swiss_roll
from sklearn.decomposition import KernelPCA
# 生成瑞士卷数据集
X, color = make_swiss_roll(n_samples=1000, noise=0.2, random_state=42)
# 使用内核PCA将数据降为二维
kpca = KernelPCA(n_components=2, kernel='linear', gamma=0.1)
X_kpca = kpca.fit_transform(X)
# 可视化降维后的数据
plt.scatter(X_kpca[:, 0], X_kpca[:, 1], c=color, cmap='viridis', edgecolor='k')
plt.title('Kernel PCA of Swiss Roll Dataset')
plt.show()

2.rbf内核
特点: RBF核是一种常用的非线性核函数,它对数据进行非线性映射,将数据映射到高维空间,使得在高维空间中更容易分离。gamma参数控制了映射的“尺度”或“平滑度”,较小的gamma值导致较远的点对结果有较大的贡献,产生更平滑的映射,而较大的gamma值使得映射更加局部化。
import matplotlib.pyplot as plt
from sklearn.datasets import make_swiss_roll
from sklearn.decomposition import KernelPCA
# 生成瑞士卷数据集
X, color = make_swiss_roll(n_samples=1000, noise=0.2, random_state=42)
# 使用内核PCA将数据降为二维
kpca = KernelPCA(n_components=2, kernel='rbf', gamma=0.04)
X_kpca = kpca.fit_transform(X)
# 可视化降维后的数据
plt.scatter(X_kpca[:, 0], X_kpca[:, 1], c=color, cmap='viridis', edgecolor='k')
plt.title('Kernel PCA of Swiss Roll Dataset')
plt.show()

3.sigmoid内核
特点: Sigmoid核也是一种非线性核函数,它在数据上执行类似于双曲正切(tanh)的非线性映射。它对数据进行映射,使其更容易在高维空间中分离。gamma参数和coef0参数分别控制了核函数的尺度和偏置。
import matplotlib.pyplot as plt
from sklearn.datasets import make_swiss_roll
from sklearn.decomposition import KernelPCA
# 生成瑞士卷数据集
X, color = make_swiss_roll(n_samples=1000, noise=0.2, random_state=42)
# 使用内核PCA将数据降为二维
kpca = KernelPCA(n_components=2, kernel='sigmoid', gamma=0.04)
X_kpca = kpca.fit_transform(X)
# 可视化降维后的数据
plt.scatter(X_kpca[:, 0], X_kpca[:, 1], c=color, cmap='viridis', edgecolor='k')
plt.title('Kernel PCA of Swiss Roll Dataset')
plt.show()

三、LLE
局部线性嵌入(Locally Linear Embedding,LLE)是一种非线性降维算法,用于保留数据流形结构。
以下是使用LLE展开瑞士卷数据集的代码
import matplotlib.pyplot as plt
from sklearn.datasets import make_swiss_roll
from sklearn.manifold import LocallyLinearEmbedding
# 生成瑞士卷数据集
X, color = make_swiss_roll(n_samples=1000, noise=0.2, random_state=42)
# 使用LLE将数据降为二维
lle = LocallyLinearEmbedding(n_neighbors=12, n_components=2, random_state=42)
X_lle = lle.fit_transform(X)
# 可视化降维后的数据
plt.scatter(X_lle[:, 0], X_lle[:, 1], c=color, cmap='viridis', edgecolor='k')
plt.title('LLE of Swiss Roll Dataset')
plt.show()

结语
降维的方法不止这几种,重要的是我们要理解为什么要降维——减少不重要的特征,同时也能加快模型的训练速度