hadoop3.x系列完全分布式集群部署(集群各节点设置与端口号的设置)
前言:hadoop集群为了满足高可用性与集群的高可靠性,选择对不同节点设置相应的权限与能力。用于达成平台的使用。
准备工作:
三台部署好hadoop与java的虚拟机。(三台虚拟机必须在同一网段)
详细配置信息请看hadoop3.x系列完全分布式集群部署(虚拟机网络连接、jdk安装、hadoop安装)_杂乱无章的我的博客-CSDN博客
一 :集群部署规划
NameNode与SecondaryNameNode不能部署在同一台服务器上。(因为SecondaryNameNode是防止NameNode挂掉时对其进行替换的。如果处于同一设备时,就不能在NameNode挂掉时对其进行取代了)
ResourceManager也很消耗内存,不要和NameNode、SecondaryNameNode配置在同一台机器上。
所以,我们对三台集群的设置如下所示
| hadoop130 | hadoop131 | hadoop132 | |
| HDFS | NameNode DataNode |
DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager |
NodeManager |
接下来对集群文件进行配置,使集群配置生效。
二 :文件设置
配置core-site.xml文件
首先进入配置文件文件夹
cd /opt/module/hadoop-3.1.3/etc/hadoop/
查看要进行修改的文件
vim core-site.xml进入文件内部,向文件内添加如下代码(注意你使用的用户或者用户ip与本文章不同,在使用时对应值进行修改)
fs.defaultFS
hdfs://hadoop130:8020
hadoop.tmp.dir
/opt/module/hadoop-3.1.3/data
hadoop.http.staticuser.user
hr

保存后退出。
配置hdfs-site.xml文件
查看要进行修改的文件
vim hdfs-site.xml向文件内添加如下代码(设置namenode与secondarynamenode的web端访问地址)
dfs.namenode.http-address
hadoop130:9870
dfs.namenode.secondary.http-address
hadoop132:9868

保存文件后退出
配置yarn-site.xml文件
查看要进行修改的文件
vim yarn-site.xml向文件内添加如下代码
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
hadoop131
yarn.nodemanager.env-whitelist
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME

保存文件后退出
配置mapred-site.xml文件
查看要进行修改的文件
vim mapred-site.xml向文件内添加如下代码
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
hadoop130:10020
mapreduce.jobhistory.webapp.address
hadoop130:19888

保存文件后退出。
配置集群workers
打开文件workers
cd /opt/module/hadoop-3.1.3/etc/hadoop/
vim workers向文件中添加如下内容(注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行)
hadoop130
hadoop131
hadoop132
保存后退出。
到此,所有hadoop文件配置完毕。接下来对集群进行初始化测试。
三 集群启动与测试
如果集群是第一次启动,需要在hadoop130节点格式化NameNode(注意:格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。如果集群在运行过程中报错,需要重新格式化NameNode的话,一定要先停止namenode和datanode进程,并且要删除所有机器的data和logs目录,然后再进行格式化。
(1)格式化命令:
hdfs namenode -format(2)启动HDFS
sbin/start-dfs.sh(3)在配置了ResourceManager的节点(hadoop131)启动YARN
sbin/start-yarn.sh(4)Web端查看HDFS的NameNode
浏览器中输入:http://hadoop:9870
(5)Web端查看YARN的ResourceManager
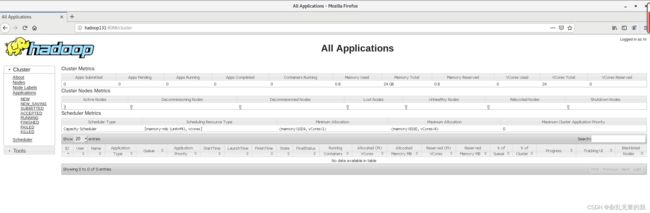
浏览器中输入:http://hadoop131:8088
结果如下图所示即配置成功

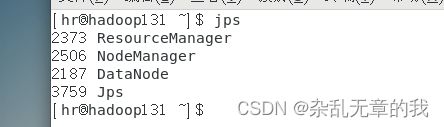
通过命令jps也可以查看对应节点上的部署情况
jps这是hadoop130的部署情况

这是hadoop131的部署情况
这是hadoop132的部署情况
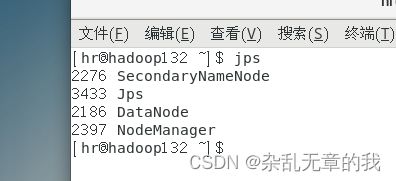
可以发现与我们设置的hadoop集群部署完全相同。
到此,hadoop完全分布式集群搭建完毕,对应节点设置也部署完毕。有相关问题欢迎评论区留言。对文章有任何意见也欢迎留言与私信。谢谢大家的观看。