预测模型的选择
预测模型通常为回归任务,但是也有一些是以标签类别为主的分类任务,分类任务常用的模型有逻辑回归、线性判别分析、knn近邻分类算法、朴素贝叶斯、决策树、支持向量机,我们有时并不知道哪个模型是最好,所以要进行比较。
# 导包
import numpy as np
import pandas as pd
from pandas.plotting import scatter_matrix
import matplotlib.pyplot as plt
from sklearn import model_selection
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
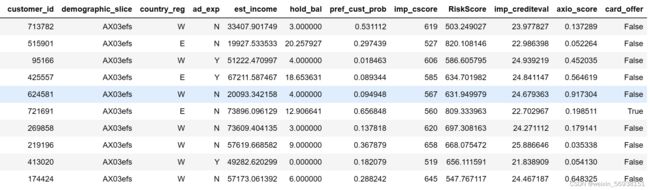
# 读取训练集数据(文末会提供数据链接进行下载数据)
train = pd.read_csv('.\cc\Test 1.csv',sep=',')
train.head(10)
运行结果:
# 将“card_offer”这一列的值进行替换
train.card_offer.replace([True, False], ['true', 'false'], inplace=True)
# 各变量之间的相关性
train.corr()
运行结果:

由于前四列数据与其他数据没有相关性,所以将前四列数据剔除。
# 查看是否有缺失值
print(train.isnull().any())
运行结果:

array = train.values
X = array[:,4:11]
Y = array[:,11]
validation_size = 0.20
seed = 7
X_train, X_validation, Y_train, Y_validation = model_selection.train_test_split(X, Y, test_size=validation_size, random_state=seed)
scoring = 'accuracy'
models = []
models.append(('LR', LogisticRegression()))
models.append(('LDA', LinearDiscriminantAnalysis()))
models.append(('KNN', KNeighborsClassifier()))
models.append(('CART', DecisionTreeClassifier()))
models.append(('NB', GaussianNB()))
models.append(('SVM', SVC()))
# evaluate each model in turn
results = []
names = []
for name, model in models:
kfold = model_selection.KFold(n_splits=10, random_state=seed)
cv_results = model_selection.cross_val_score(model, X_train, Y_train, cv=kfold, scoring=scoring)
results.append(cv_results)
names.append(name)
msg = "%s: %f (%f)" % (name, cv_results.mean(), cv_results.std())
print(msg)
运行结果:

fig = plt.figure()
fig.suptitle('Algorithm Comparison')
ax = fig.add_subplot(111)
plt.boxplot(results)
ax.set_xticklabels(names)
plt.show()
运行结果:

由于决策树分类器似乎给出了最准确的结果,我使用它对新数据集进行预测。
# 读取测试集数据(文末会提供数据链接进行下载数据)
test = pd.read_csv('.\cc\Test 2.csv',sep=',')
test.head()
# 分配参数并预测是否给用户提供信用卡
Xtest = test.values[:,4:11]
Ytest = dtc.predict(Xtest)
# 更新测试集中的预测值
test['card_offer']=Ytest
# 查看数据
test.head()
运行结果:

# 将card_offer字符串值替换为原始数据集中的布尔值
test.card_offer.replace(['true', 'false'], [True, False], inplace=True)
# 将数据进行保存
test.to_csv('ds4.csv', index=False)
本文数据:
链接:https://pan.baidu.com/s/1GHnob4o60uq_xVrLub59lQ
提取码:ovd8