气质结果重复性比较和pdf结果文件的批处理
顶空固相微萃取结合气相质谱(SPME-GC-MS)试验过程的自动化可能性
背景
最近一直在学院的色谱质谱实验 测定苹果果实的香气。发现测定过程非常复杂,由于仪器灵敏度很高,因此为了保障数据的一致性,需要及时进行报告结果的计算和校对。这意味着实验员的精力同时分散在平衡、吸附、上样、解析、数据导出和结果计算。毫无疑问,这是一个十分困难的任务。但由于每一针样之间时间间隔很长,而且不需要任何的电脑操作为自动化过程留下了空间和可能性。
另外,气质试验数据的导出整理,用常规方法也是一项浩大的工程。师姐的方法是,将GCMS结果文件qgd文件先逐一导出为PDF,再将数据从pdf转移到word表格,在化合物名称部分做一些修正后从word导出到excel。过程并不复杂,但是重复性和机械性很高,而且很耗时间。
假想自动化方案
1、qgd文件转化pdf文件过程
根据经验,在样品登录/等待的过程和上样点击开始(包括2.5min后拔针)后有很长一段电脑的闲置时间,因此可以编写一个自动化的脚本,在这个空隙将前一针已经结束的结果文件转化为pdf文件。
echo "还没写,而且好像肉动也没啥>.<!"
2、数据重复性检查
在一个样品的所有重复都已经测定完毕的情况下,需要检查样品数据的重复性。首先还是将结果文件导出为报告。下面是我的方案,供大家参考:
import pdfplumber as pr
import pandas as pd
import re
from io import StringIO
import numpy as np
import matplotlib.pyplot as plt
import os
import sys
#目标文件筛选函数
def data_filter(aromadir):
#判断路径是否存在
if os.path.exists(aromadir):
#列出路径下所有的子目录
pdf_reports = os.listdir(aromadir)
#筛选出所有文件后缀为pdf并且文件名包含“32_15_p”的文件
pdf_reports = [x for x in pdf_reports if x[-4:] == '.pdf' and "32_15_p" in x]
#如果筛选结果为空报错
if not pdf_reports:
raise Exception('the dir has no report file')
else:
#路径不存在报错
raise Exception('sorry, the dir is not exist!')
#初始化一个空的pandas数据框
result = temp = pd.DataFrame({})
#遍历筛选结果并且提取pdf信息
for report in pdf_reports:
temp = get_pdfinfo(aromadir+report)
#合并提取后的数据
result = pd.concat([result,temp],axis=1)
return result
#从pdf提取数据的函数
def get_pdfinfo(pdffile):
#在pdf报告文件可靠的情况下,这个异常捕获没必要,但压缩和转移的过程中很有可能导致pdf损坏,为了防止程序退出,加上了这个异常捕获
try:
with pr.open(pdffile) as pdf:
content = ''
#遍历所有页面,提取所有页面的文本
for i in range(len(pdf.pages)):
page = pdf.pages[i]
#去除每一页的底部的页码和顶部的页眉
page_content = '\n'.join(page.extract_text().split('\n')[2:-1])
#每一页的内容拼接到一起
content = content+page_content+'\n'
except Exception as e:
#如果出现pdf损坏,打印错误信息和当前文件名,并且返回一个空文件,程序继续进行
print(e)
print(pdffile)
os.system("rm -rf %s"%pdffile)
return pd.DataFrame({})
#正则提取物质含量表
temp = re.search('(峰表 TIC)(.*?)(谱库)', content, re.S)
#正则提取样品名
trial_name = re.search('(样品名 :)(.*?)(\n)', content, re.S)
temp = temp.group(2)
#把content写入字符串缓冲区
temp = StringIO(temp)
#利用连续的两个空格" "作为分隔符以csv文件格式导入pandas转化为数据框
df = pd.read_table(temp, sep=' ', header=None, skiprows=2, skipfooter=1, engine='python')
#化合物名称的处理,将控制转化为空字符串
df[10] = df[10].fillna('')
df[11] = df[11].fillna('')
#拼接化合物名称
df[10] = df[10]+df[11]
#删除临时产生的列(分割问题导致的)
df = df.drop(labels=[9,11], axis=1)
#加入样品名
df[9] = trial_name.group(2)
trial_name = trial_name.group(2)
#保留1、4、9、10列
df = df.loc[:, [1, 4,9, 10]]
#重命名列索引
df.columns = ['Rtime', 'area', 'sample_name', 'chemical_name']
#去除化合物名称两头的不可见字符
df['chemical_name'] = df['chemical_name'].apply(func = lambda x:x.strip())
#获取内标峰面积,为了防止样品质量差没有内标,加了个异常捕获
try:
#获取内标面积
ns_area = df.loc[df['chemical_name']=='3-Nonanone', ['area']].values[0]
except:
#无内标则打印出pdf结果文件名并返回空数据框
print("无内标:", pdffile)
return pd.DataFrame({})
#含量计算,峰面积比乘以内标的质量【总感觉这里好像错了(>.<)】
df[trial_name] = df['area']/ns_area*0.65928
#保留两位小数
df[trial_name] = df[trial_name].round(2)
#争议过程,由于在报告中会出现不同保留时间化学物质名称相同的情况,本方案的处理逻辑没办法消除这种影响,所以一竿子打死,对于重复值只保留第一次出现的项
if any(df.duplicated(subset="chemical_name")):
df.drop_duplicates(subset="chemical_name", inplace=True, keep="first")
#将去重后的化合物名称作为(行)索引(行索引必须唯一)
df.set_index("chemical_name", inplace=True)
#只保留化合物含量这一列数据
df = df[trial_name]
return df
#雷达图绘制函数
def draw_radar(result):
#数据归一化,把数据缩放到0-1
result = data_standard(result, 1)
# 雷达图标签
labels = result.index
# 标签数量
num_vars = len(labels)
# 将圆等分并且保存对应的角度
angles = np.linspace(0, 2 * np.pi, num_vars, endpoint=False).tolist()
# 使圆首尾相接
angles += angles[:1]
#matplotlib制订画布大小,并指定极坐标图方法
# ax = plt.subplot(polar=True)
fig, ax = plt.subplots(figsize=(15,15), subplot_kw=dict(polar=True))
# 绘制雷达图的辅助函数
def add_to_radar(sameple):
values = result[sample].tolist()
values += values[:1]
#绘制和填充
ax.plot(angles, values, linewidth=1, label=sample)
ax.fill(angles, values, alpha=0.25)
# 遍历所有的列
for sample in result.columns:
add_to_radar(sample)
#add_to_radar('peugeot 504 1979', '#429bf4')
#add_to_radar('ford granada 1977', '#d42cea')
# 设置顺时针排列并且从12点钟方向开始
ax.set_theta_offset(np.pi / 2)
ax.set_theta_direction(-1)
# 在对应角度摆放标签
ax.set_thetagrids(np.degrees(angles[:-1]), labels)
# 通过标签位置调整对应姿态
for label, angle in zip(ax.get_xticklabels(), angles):
if angle in (0, np.pi):
label.set_horizontalalignment('center')
elif 0 < angle < np.pi:
label.set_horizontalalignment('left')
else:
label.set_horizontalalignment('right')
# 设定y轴的
#ax.set_ylim(0, 100)
# 设定网格线
# ax.set_rgrids([20, 40, 60, 80, 100])
#标签位置
ax.set_rlabel_position(180 / num_vars)
# 设定刻度颜色
ax.tick_params(colors='#222222')
# 标签大小.
ax.tick_params(axis='y', labelsize=8)
# 网格线颜色
ax.grid(color='#AAAAAA')
#设置最外围网格的颜色.
ax.spines['polar'].set_color('#222222')
# 设置背景色.
ax.set_facecolor('#FAFAFA')
# 标题.
ax.set_title('apple aroma radar chart', y=1.08)
# 添加图例.
#ax.legend(loc='upper right', bbox_to_anchor=(1.3, 1.1))
#图例位置
ax.legend(loc='best')
#图片紧凑排布
plt.tight_layout()
#电脑plt.show()就OK,电脑坏了这是自创的termux的plt.show()方法
fig.savefig("radar.png")
os.system("termux-open radar.png")
#数据标准化函数
def data_standard(result, axis=0):
#苹果特征香气
want = [".alpha.-Farnesene", "1-Butanol, 2-methyl-", "1-Hexanol", "2-Hexenal, (E)-","Hexanal", "Acetic acid, butyl ester","Acetic acid, hexyl ester"]
#特征筛选
result = result.loc[want, :]
#判断数据排布的轴向
if axis:
for raw in result.index:
#标准化方法用数据除以最大值
result.loc[raw] = result.loc[raw]/(result.loc[raw].max())
else:
for col in result.columns:
result[col] = (result[col])/(result[col].max())
return result
if __name__=="__main__":
#pdf结果文件的存放路径
aromadir="../../bluetooth/aroma_report/"
#文件过滤
result=data_filter(aromadir)
#空值处理,空值替代为0
result.fillna(value=0, inplace=True)
#导出为csv/excel文件
#result.to_csv("aroma.csv", sep=",")
#绘制雷达图
draw_radar(result)
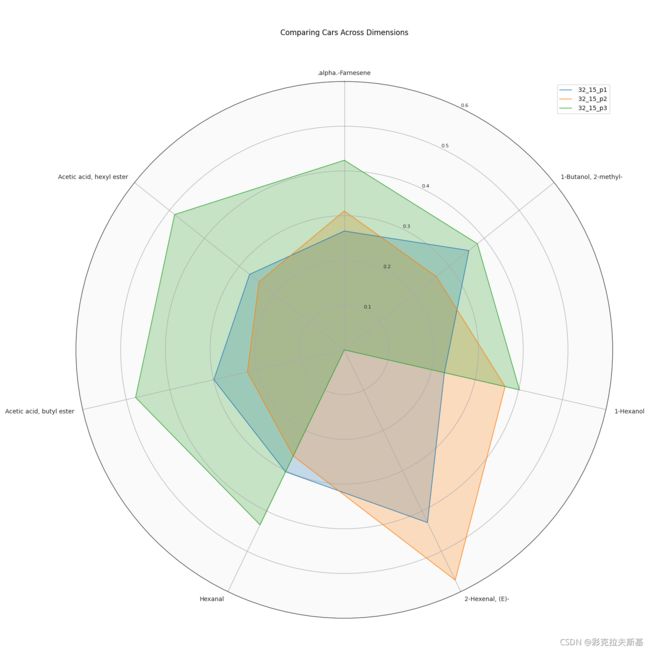
上图就是试验过程中三个生物学重复的香气物质雷达图,可见SPME-GC-MS方法的重复性还是比较差的,虽然这可能与样品不均质也有一定关系。
3、pdf结果文件数据的提取和整理
因为这个过程在绘制雷达图的过程中用到过,并且有对应的函数因此只放main后的部分,如下:
if __name__=="__main__":
#pdf结果文件的存放路径
aromadir="../../bluetooth/aroma_report/"
#文件过滤
result=data_filter(aromadir)
#空值处理,空值替代为0
result.fillna(value=0, inplace=True)
#导出为csv/excel文件
result.to_csv("aroma.csv", sep=",")
展示结果:
程序会运行的很慢,像卡住了一样。由于电脑坏了,我用平板跑的。荣耀V6,处理60个pdf文件导出结果大概花了15min,毕竟平板算力有限,用电脑应该会快很多。如果在程序中加入一个比如说ASCII动图之类的动态反馈使用感会好一点,但是我不想写(反正又没人用, 而且再写毕不了业了)。
从这里可以看到,背景中提到的问题都已经基本解决。但是实验室的电脑是一台古老的windows xp,可以运行的python版本非常低,而且很多库对于python并不支持。因此可以通过python自带的打包工具Pyinstaller打包成exe。如果是高版本windows之间的转递也可以用embeddable打包。
写在最后
其实最后是一个技术乞讨>.<。最近笔记本的屏幕坏了,被迫成为了一台远程电脑。但是我使用的内网穿透工具不怎么稳定,想问问大家有没有稳定并且提供http流量穿透(想搭个小网站)的内网穿透工具,最好是免费的(贫穷的成年人不想为没有金钱回报的玩物做任何投资)。