第十章:Cassandra监控--Cassandra:The Definitive Guide 2nd Edition
在本章中,您将学习如何使用各种工具来监视和了解Cassandra集群生命周期中的重要事件。我们将看一些简单的方法来查看正在发生的事情,例如更改日志记录级别和了解输出。
Cassandra还具有对Java Management Extensions(JMX)的内置支持,它提供了一种丰富的方式来监视您的Cassandra节点及其底层Java环境。通过JMX,我们可以看到数据库的健康状况和正在进行的事件,甚至可以远程与之交互以调整某些值。 JMX是Cassandra的重要组成部分,我们将花一些时间确保我们知道它是如何工作的,以及Cassandra用JMX监控和管理的确切内容。让我们开始吧!
记录
了解数据库中发生的事情的最简单方法是只更改日志记录级别以使输出更加详细。这对于开发和学习Cassandra在幕后所做的事情非常有用。
Cassandra使用Simple Logging Facade for Java(SLF4J)API进行日志记录,使用Logback作为实现。 SLF4J提供了各种日志框架的外观,例如Logback,Log4J和Java的内置记录器(java.util.logging)。您可以在http://logback.qos.ch/上了解有关Logback的更多信息。
默认情况下,Cassandra服务器日志级别设置为INFO,这不会为您提供有关Cassandra在任何给定时间正在执行的工作的详细信息。它只输出基本状态更新,如下所示:
INFO [main] 2015-09-19 09:40:20,215 CassandraDaemon.java:149 -
Hostname: Carp-iMac27.local
INFO [main] 2015-09-19 09:40:20,233 YamlConfigurationLoader.java:92 -
Loading settings from file:/Users/jeff/Cassandra/
apache-cassandra-2.1.8/conf/cassandra.yaml
INFO [main] 2015-09-19 09:40:20,333 YamlConfigurationLoader.java:135 -
Node configuration
...
当您在终端中启动Cassandra时,通过向程序传递-f标志来保持此输出在终端窗口中运行(以保持输出在终端窗口的前景中可见)。 但Cassandra也将这些日志写入物理文件供您稍后检查。
通过将日志记录级别更改为DEBUG,我们可以更清楚地看到服务器正在处理的活动,而不是仅查看这些阶段更新。
要更改日志记录级别,请打开文件 /conf/logback.xml并找到如下所示的部分:
<root level="INFO">
<appender-ref ref="FILE" />
<appender-ref ref="STDOUT" />
</root>
更改第一行,使其如下所示:
<root level="DEBUG">
完成此更改并保存文件后,Cassandra将很快开始打印DEBUG级别的日志记录语句。 这是因为默认日志记录配置为每分钟扫描一次配置文件,如下所示:
<configuration scan="true">
现在,随着Cassandra的工作,我们可以看到更多的活动。 这使您可以准确地了解Cassandra正在做什么以及何时做什么,这在故障排除方面非常有用。 但它也有助于简单地理解Cassandra为维持自身所做的工作。
当然,在生产中,您需要将日志记录级别调整回WARN或ERROR,因为详细输出会大大减慢速度。
默认情况下,Cassandra的日志文件存储在Cassandra安装目录下的logs目录中。
如果要更改logs目录的位置,只需在logback.xml文件中找到以下条目并选择其他文件名:
<file>${cassandra.logdir}/system.log</file>
如果在指定的位置中没有看到任何日志文件,请确保您是目录的所有者,或者至少设置了正确的读写权限。 Cassandra不会告诉你它是否不能写日志; 它只是不会写。 数据文件也是如此。
logback.xml文件中的其他设置支持滚动日志文件。 默认情况下,system.log文件在达到20 MB的大小时将滚动到存档。 每个日志文件存档都以zip格式压缩,并根据模式system.log.1.zip,system.log.2.zip等命名。
Tailing
您不需要使用前台开关启动Cassandra以查看滚动日志。 您也可以在没有-f选项的情况下启动它,然后拖尾日志。 拖尾不是Cassandra特有的; 它是Linux发行版中提供的一个小程序,用于查看打印到控制台的新值,因为它们会附加到文件中。
要拖尾日志,像这样启动Cassandra:
$ bin/cassandra
然后打开第二个控制台,输入tail命令,并将要传递给特定文件的位置传递给它,如下所示:
$ tail -f $CASSANDRA_HOME/logs/system.log
-f选项表示“跟随”,当Cassandra将信息输出到物理日志文件时,tail会将其输出到屏幕。 要停止拖尾,只需按Ctrl-C即可。
如果您使用的是Windows,则可以执行相同的操作,但Windows本身不包含尾部程序。 因此,要实现这一点,您需要下载并安装Cygwin,它是一个免费的开源Bash shell模拟器。 Cygwin允许您拥有Linux风格的界面并在Windows上使用各种Linux工具。
然后,您可以定期启动Cassandra并使用以下命令拖尾日志文件:
$ tail -f %CASSANDRA_HOME%\\logs\\system.log
这将以与预设相同的方式显示控制台中的输出。
检查日志文件
在启用调试日志记录的情况下运行服务器后,您可以看到在调试过程中可以提供更多帮助。 例如,在这里我们可以看到使用cqlsh将简单值写入数据库时的输出:
cqlsh> INSERT INTO hotel.hotels (id, name, phone, address)
... VALUES ( 'AZ123', 'Comfort Suites Old Town Scottsdale',
... '(480) 946-1111', { street : '3275 N. Drinkwater Blvd.',
... city : 'Scottsdale', state : 'AZ', zip_code : 85251 });
DEBUG [SharedPool-Worker-1] 2015-09-30 06:21:41,410 Message.java:506 -
Received: OPTIONS, v=4
DEBUG [SharedPool-Worker-1] 2015-09-30 06:21:41,410 Message.java:525 -
Responding: SUPPORTED {COMPRESSION=[snappy, lz4],
CQL_VERSION=[3.3.1]}, v=4
DEBUG [SharedPool-Worker-1] 2015-09-30 06:21:42,082 Message.java:506 -
Received: QUERY INSERT INTO hotel.hotels (id, name, phone, address)
VALUES ( 'AZ123', 'Comfort Suites Old Town Scottsdale',
'(480) 946-1111', { street : '3275 N. Drinkwater Blvd.',
city : 'Scottsdale', state : 'AZ', zip_code : 85251 });
[pageSize = 100], v=4
DEBUG [SharedPool-Worker-1] 2015-09-30 06:21:42,086
AbstractReplicationStrategy.java:87 - clearing cached endpoints
DEBUG [SharedPool-Worker-1] 2015-09-30 06:21:42,087 Tracing.java:155 -
request complete
DEBUG [SharedPool-Worker-1] 2015-09-30 06:21:42,087 Message.java:525 -
Responding: EMPTY RESULT, v=4
鉴于它在单个节点集群上运行,因此该特定输出的表现力不如其他情况。
如果我们然后通过一个简单的查询加载行:
cqlsh> SELECT * from hotel.hotels;
The server log records this query as follows:
DEBUG [SharedPool-Worker-1] 2015-09-30 06:27:27,392 Message.java:506 -
Received: QUERY SELECT * from hotel.hotels;[pageSize = 100], v=4
DEBUG [SharedPool-Worker-1] 2015-09-30 06:27:27,395
StorageProxy.java:2021 - Estimated result rows per range: 0.0;
requested rows: 100, ranges.size(): 257; concurrent range requests: 1
DEBUG [SharedPool-Worker-1] 2015-09-30 06:27:27,401
ReadCallback.java:141 - Read: 0 ms.
DEBUG [SharedPool-Worker-1] 2015-09-30 06:27:27,401 Tracing.java:155 -
request complete
DEBUG [SharedPool-Worker-1] 2015-09-30 06:27:27,401 Message.java:525 -
Responding: ROWS [id(hotel, hotels),
org.apache.cassandra.db.marshal.UUIDType][address(hotel, hotels),
org.apache.cassandra.db.marshal.UserType(hotel,61646472657373,
737472656574:org.apache.cassandra.db.marshal.UTF8Type,
63697479:org.apache.cassandra.db.marshal.UTF8Type,7374617465:
org.apache.cassandra.db.marshal.UTF8Type,7a69705f636f6465:
org.apache.cassandra.db.marshal.Int32Type)][name(hotel, hotels),
org.apache.cassandra.db.marshal.UTF8Type][phone(hotel, hotels),
org.apache.cassandra.db.marshal.UTF8Type][pois(hotel, hotels),
org.apache.cassandra.db.marshal.SetType(org.apache.cassandra.db.
marshal.UUIDType)]
| 452d27e1-804e-479b-aeaf-61d1fa31090f | 3275 N. Drinkwater Blvd.:
Scottsdale:AZ:85251 | Comfort Suites Old Town Scottsdale |
(480) 946-1111 | null
如您所见,服务器通过负责从磁盘格式编组数据的类加载我们请求的每个列。
DEBUG日志级别应该为您提供足够的信息以跟踪服务器在您工作时所执行的操作。
使用JMX监视Cassandra
在本节中,我们将探讨Cassandra如何利用Java Management Extensions(JMX)来实现服务器的远程管理。 JMX从Java规范请求(JSR)160开始,自5.0版以来一直是Java的核心部分。
您可以通过检查java.lang.management包来阅读有关Java中JMX实现的更多信息。
JMX是一种Java API,它以两种主要方式提供应用程序管理。首先,JMX允许您了解应用程序在内存,线程和CPU使用方面的运行状况和整体性能 - 这些内容通常适用于任何Java应用程序。其次,JMX允许您使用已经检测的应用程序的特定方面。
Instrumentation是指为应用程序代码提供一个包装器,该应用程序代码提供从应用程序到JVM的钩子,以便允许JVM收集外部工具可以使用的数据。此类工具包括监视代理程序,数据分析工具,分析程序等。 JMX不仅允许您查看此类数据,还可以在应用程序启用时通过更新值在运行时管理您的应用程序。
JMX通常用于各种应用程序控制操作,包括:
-
低可用内存检测,包括堆上每个生成空间的大小
-
线程信息,例如死锁检测,线程峰值数和当前活动线程
-
详细的类加载器跟踪
-
日志级别控制
-
一般信息,例如应用程序正常运行时间和活动类路径
许多流行的Java应用程序都使用JMX进行检测,包括JVM本身,Tomcat应用程序服务器和Cassandra。 JMX架构的描述如图10-1所示。
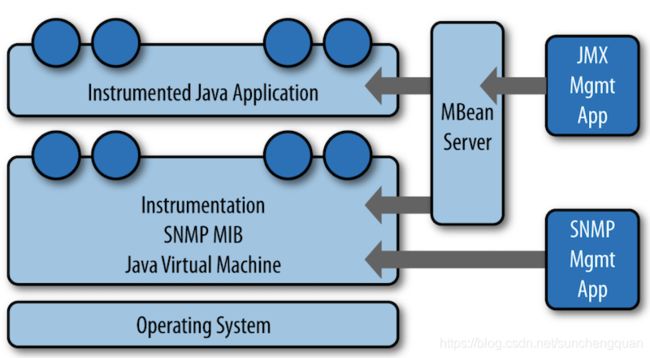
JMX架构很简单。 JVM从底层操作系统收集信息。 JVM本身是经过检测的,因此如前所述,它的许多功能都会被公开用于管理。一个带有检测的Java应用程序(例如Cassandra)在此基础上运行,并将其一些功能公开为可管理对象。 JDK包括一个MBean服务器,该服务器通过远程协议将检测的功能提供给JMX管理应用程序。 JVM还通过简单网络监视协议(SNMP)提供管理功能,如果您使用的是Nagios或Zenoss等SMTP监视工具,这可能很有用。
但是在给定的应用程序中,您只能管理应用程序开发人员可供您管理的内容。幸运的是,Cassandra开发人员已经对大部分数据库引擎进行了检测,通过JMX进行管理非常简单。
这个Java应用程序的工具是通过包装您希望JMX与托管bean挂钩的应用程序代码来执行的。
通过JConsole连接到Cassandra
jconsole工具随附标准Java Development Kit。它提供了一个用于处理MBean的图形用户界面客户端,可用于本地或远程管理。让我们使用JConsole在其JMX端口上连接到Cassandra。为此,请打开一个新终端并键入以下内容:
>jconsole
When you run jconsole, you’ll see a login screen similar to that in Figure 10-2.
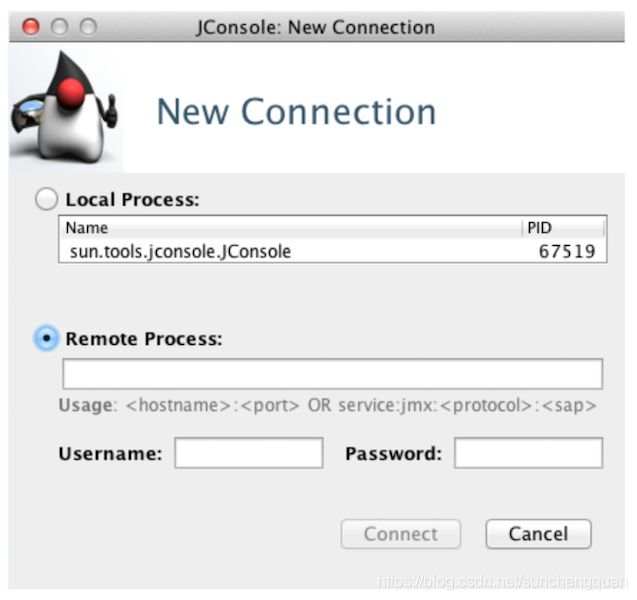
从这里,如果您正在监视同一台机器上的节点,只需双击“本地进程”部分下的值org.apache.cassandra.service.CassandraDaemon即可。 如果要监视其他计算机上的节点,请选中“远程进程”单选按钮,然后输入要连接的主机和端口。 默认情况下,Cassandra JMX在端口7199上广播,因此您可以输入类似于此处所示的值,然后点击Connect:
>lucky:7199
默认情况下,Cassandra仅在启用JMX以进行本地访问时运行。要启用远程访问,请编辑文件/cassandra-env.sh(或Windows上的cassandra.ps1)。搜索“JMX”以查找文件部分,其中包含用于控制JMX端口和其他本地/远程连接设置的选项。
连接到服务器后,默认视图包含有关服务器状态的四个主要类别,这些类别会不断更新:
- 堆内存使用情况
- 这显示了Cassandra程序可用的总内存,以及它现在使用的内存量。
- 主题
- 这是Cassandra正在使用的活线程数。
- 类
- Cassandra加载的类数。对于这样一个强大的程序,这个数字相对较小; Cassandra通常需要不到3000个课程。将其与Oracle WebLogic等程序进行比较,该程序通常会加载大约24,000个类。
- CPU使用率
- 这显示了Cassandra程序当前使用的处理器的百分比。
您可以使用选择器调整图表中显示的时间范围。
如果要查看Cassandra如何使用Java堆和非堆内存的更详细视图,请单击“内存”选项卡。通过更改下拉列表中的图表值,您可以详细查看Cassandra使用其内存的分级。如果您认为有必要,您也可以(尝试)强制进行垃圾收集。
您可以一次连接到多个JMX代理。只需选择文件→新建连接…并重复步骤以连接到另一个正在运行的Cassandra节点,以便一次查看多个服务器。
当您正在寻找JMX客户端时,JConsole是一个简单的选择,因为它易于使用并随JDK一起提供。但这只是一个可能的JMX客户端 - 还有很多其他客户端可用。以下是一些可能满足您需求的客户示例:
-
Oracle Java Mission Control和Visual VM
这些工具还随Oracle JDK一起提供,并为内存使用,线程,垃圾收集等提供更强大的指标,诊断和可视化。两者之间的主要比较是Visual VM是GNU许可下可用的开源项目,而Mission Control通过名为Flight Control的框架提供与Oracle JVM的更深层次的集成。
Java Mission Control可以通过命令$ JAVA_HOME / bin / jmc和Visual VM通过命令$ JAVA_HOME / bin / jvisualvm运行。两者都适用于开发和生产环境。
-
MX4J
Management Extensions for Java(MX4J)项目提供了JMX的开源实现,包括使用HTTP / HTML等工具,如JMX的嵌入式Web界面。这允许通过标准Web浏览器与JMX交互。
要将MX4J集成到Cassandra安装中,请下载mx4j_tools.jar库,将JAR文件保存在Cassandra安装的lib目录中,并在conf / cassandra-env.sh中配置MX4J_ADDRESS和MX4J_PORT选项。
-
Jmxterm
Jmxterm是一个命令行JMX客户端,允许在没有图形界面的情况下访问JMX服务器。 这在云环境中工作时尤其有用,因为图形工具通常更耗费资源。
Jmxterm是Cyclops Group提供的一个开源Java项目。
-
IDE集成
您还可以找到与流行的IDE集成的JMX客户端; 例如,eclipse-jmx。
MBean概述
托管bean或MBean是一种特殊类型的Java bean,它表示JVM中的单个可管理资源。 MBean与MBean服务器交互以使其功能远程可用。
图10-3中提供了JConsole的视图。
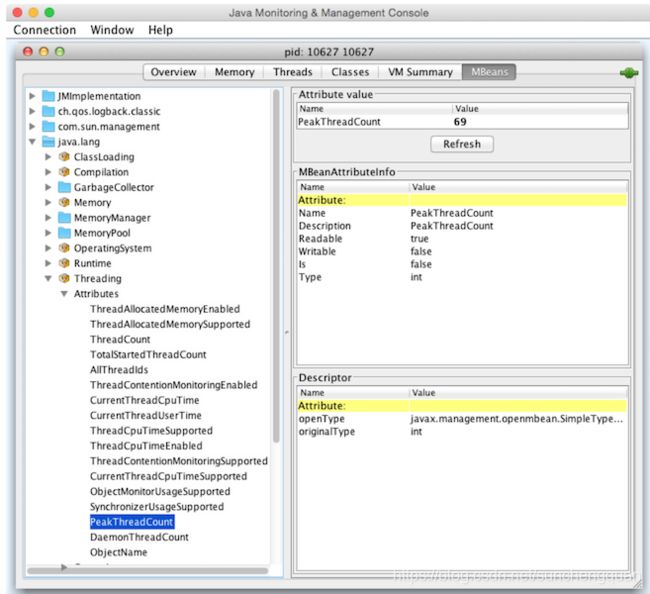
在此图中,您可以看到提供有关每个应用程序将具有的线程,内存和CPU的一般视图的选项卡式窗口,以及更详细的MBeans选项卡,该选项卡公开了与应用程序公开的MBean进行更详细交互的能力。例如,在图中,我们选择查看峰值线程计数值。您可以看到应用程序的许多其他检测方面也可用。
应用程序或JVM的许多方面都可以进行检测,但可能会被禁用。线程争用是JVM中默认关闭的可能有用的MBean的一个示例。这些方面对于调试非常有用,因此如果您看到一个MBean,您认为可以帮助您解决问题,请继续并启用它。但请记住,没有任何东西是免费的,并且最好在要启用的MBean上读取JavaDoc,以便了解对性能的潜在影响。例如,测量每个线程的CPU时间是一个有用但昂贵的MBean操作的示例。
向MBean服务器注册MBean时,它指定用于标识JMX客户端的MBean的对象名称。对象名称由一个域后跟一个键值对列表组成,其中至少有一个必须标识一个类型。典型的约定是选择一个类似于MBean的Java包名称的域名,并在MBean接口名称之后命名该类型(减去“MBean”),但这不是严格要求的。
例如,我们之前看到的线程属性出现在JConsole中的java.lang.Threading标题下,并由实现java.lang.management。ThreadMXBean接口的类公开,该接口使用对象名java注册MBean。 lang.type =线程。
在本章讨论各种MBean时,我们将识别MBean对象名称和界面,以帮助您在JMX客户端和Cassandra源代码之间导航。
应用程序中的一些简单值作为属性公开。一个例子是Threading> PeakThreadCount,它只报告MBean为应用程序在单个时间点使用的最大线程数存储的值。您可以刷新以查看最新值,但这几乎可以用它来完成。因为这样的值是在JVM内部维护的,所以在外部设置它是没有意义的(它是从实际事件派生的,而不是可配置的)。
但其他MBean是可配置的。它们使JMX代理可以使用操作,以便获取和设置值。您可以通过查看可写值来判断MBean是否允许您设置值。如果为false,您将看到一个标签,指示只读值;如果确实如此,您将看到一组用于添加新值的一个或多个字段以及一个用于更新它的按钮。这方面的一个例子是ch.qos.logback.classic.jmx.JMXConfigurator bean,如图10-4所示。
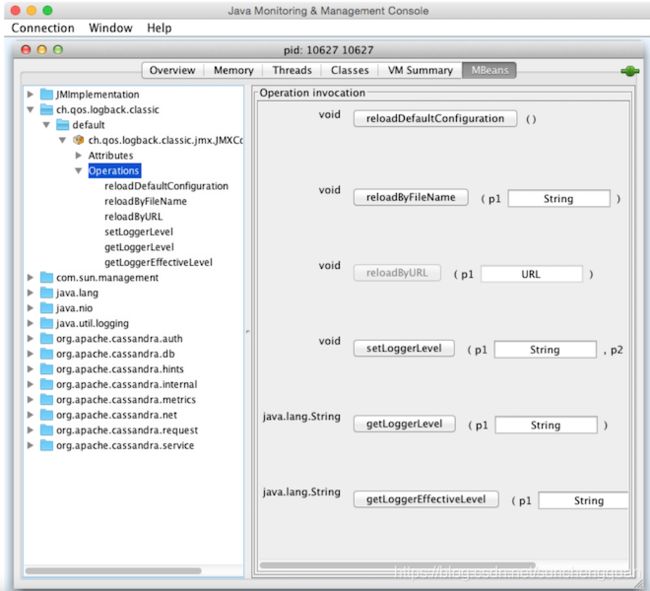
请注意,参数名称不可用于JMX代理程序;它们只是标记为p0,p1,依此类推。那是因为Java编译器在编译期间“擦除”了参数名称。因此,为了知道在操作上设置哪些参数,您需要查看您正在使用的特定MBean的JavaDoc。
对于JMXConfigurator,此类实现一个名为JMXConfiguratorMBean的接口,该接口将其包装以进行检测。要找出setLoggerLevel操作的正确参数,我们将检查此接口的JavaDoc,可从http://logback.qos.ch/apidocs/ch/qos/logback/classic/jmx/JMXConfiguratorMBean.html获取。查看文档,您将看到p0表示要更改的记录器的名称,p1描述了要将该记录器设置为的记录级别。
某些MBean返回javax.management.openmbean.CompositeDataSupport的属性值。这意味着这些不是可以在单个字段中显示的简单值,例如LoadedClassCount,而是多值。一个例子是Memory> HeapMemoryUsage,它提供了几个数据点,因此有自己的视图。
另一种类型的MBean操作不是简单地显示值或允许您设置值,而是允许您执行一些有用的操作。 dumpAllThreads和resetPeakThreadCount是两个这样的操作。
现在我们很快就会开始专门开始监控和管理Cassandra。
卡桑德拉的MBeans
一旦与JConsole等JMX代理连接,就可以使用它公开的MBean来管理Cassandra。为此,请单击MBeans选项卡。除了每个代理程序可用的标准Java项目之外,还有几个包含可管理bean的Cassandra程序包,这些bean由程序包名称组织,以org.apache.cassandra开头。我们不会在这里详细介绍所有这些内容,但有几个我们需要关注的兴趣。
Cassandra中的许多类都公开为MBean,这实际上意味着它们实现了一个自定义接口,该接口描述了需要实现的操作以及JMX代理将为其提供挂钩的操作。使任何MBean工作的步骤基本相同。如果您希望JMX启用尚未启用的功能,请按照此大纲修改源代码,您将开始营业。
例如,我们从org.apache.cassandra.db.compaction包中查看Cassandra的CompactionManager以及它如何使用MBean。 这是CompactionManagerMBean类的定义,为简洁起见省略了注释:
public interface CompactionManagerMBean
{
public List<Map<String, String>> getCompactions();
public List<String> getCompactionSummary();
public TabularData getCompactionHistory();
public void forceUserDefinedCompaction(String dataFiles);
public void stopCompaction(String type);
public void stopCompactionById(String compactionId);
public int getCoreCompactorThreads();
public void setCoreCompactorThreads(int number);
public int getMaximumCompactorThreads();
public void setMaximumCompactorThreads(int number);
public int getCoreValidationThreads();
public void setCoreValidationThreads(int number);
public int getMaximumValidatorThreads();
public void setMaximumValidatorThreads(int number);
}
正如您在MBean接口定义中所看到的那样,没有任何魔力可言。 这只是一个常规接口,用于定义将向CompMManager实现必须支持的JMX公开的操作集。 这通常意味着在常规操作完成其工作时维护其他元数据。
CompactionManager类实现此接口,并且必须执行直接支持JMX的工作。 CompactionManager类本身为MBean服务器注册和取消注册它在本地维护的JMX属性:
public static final String MBEAN_OBJECT_NAME =
"org.apache.cassandra.db:type=CompactionManager";
// ...
static
{
instance = new CompactionManager();
MBeanServer mbs = ManagementFactory.getPlatformMBeanServer();
try
{
mbs.registerMBean(instance,
new ObjectName(MBEAN_OBJECT_NAME));
}
catch (Exception e)
{
throw new RuntimeException(e);
}
}
请注意,MBean在域org.apache.cassandra.db中注册,其类型为CompactionManager。 此MBean公开的属性和操作显示在JMX客户端中的org.apache.cassandra.db> CompactionManager下。 该实现完成了它打算完成的所有工作,然后实现了只与MBean服务器通信所必需的方法。 例如,这是stopCompaction()操作的CompactionManager实现:
public void stopCompaction(String type)
{
OperationType operation = OperationType.valueOf(type);
for (Holder holder : CompactionMetrics.getCompactions())
{
if (holder.getCompactionInfo().getTaskType() == operation)
holder.stop();
}
}
CompactionManager迭代正在进行的压缩,停止每个具有指定类型的压缩。 Javadoc让我们知道有效类型是COMPACTION,VALIDATION,CLEANUP,SCRUB和INDEX_BUILD。
当我们在JConsole中查看CompactionManagerMBean时,我们可以选择操作并查看stopCompaction()操作,如图10-5所示。 我们可以输入上述类型之一并请求停止压缩。
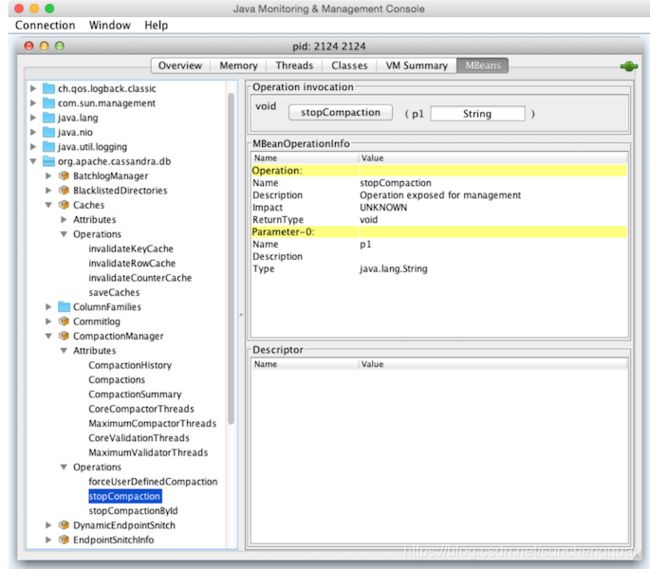
在以下部分中,我们将了解通过JMX可用于监视和管理的功能。
数据库MBean
这些是与核心数据库本身相关的Cassandra类,它们暴露给org.apache.cassandra.db域中的客户端。此域中有许多MBean,但我们将专注于与存储,缓存,提交日志和表存储相关的几个关键MBean。
存储服务MBean
因为Cassandra是一个数据库,它本质上是一个非常复杂的存储程序;因此,当您遇到问题时,您首先想要查看的地方之一是org.apache.cassandra.service.StorageServiceMBean。这允许您检查您的OperationMode,如果一切顺利(其他可能的状态是离开,加入,退役和客户端),则报告正常。
您还可以查看当前的活动节点集以及群集中无法访问的节点集。如果任何节点无法访问,Cassandra将在UnreachableNodes属性中告诉您IP地址。
如果要在不中断服务的情况下在运行时更改Cassandra的日志级别(正如我们在前面的示例中所见),您可以调用setLoggingLevel(String classQualifier,String level)方法。例如,假设您已将Cassandra的日志级别设置为DEBUG,因为您正在解决问题。您可以使用此处描述的某些方法来尝试帮助解决问题,然后您可能希望将日志级别更改为对系统不那么重要的事情。为此,请导航到JMX客户端(如JConsole)中的StorageService MBean。我们将改变一个特别健谈的类的价值:Gossiper。此操作的第一个参数是要为其设置日志级别的类的名称,第二个参数是您要将其设置为的级别。输入org.apache.cassandra.gms.Gossiper和INFO,然后单击标记为setLoggingLevel的按钮。您应该在日志中看到以下输出(假设您的级别已经调试):
INFO 03:08:20 set log level to INFO for classes under
'org.apache.cassandra.gms.Gossiper' (if the level doesn't look
like 'INFO' then the logger couldn't parse 'INFO')
在调用setLoggingLevel操作之后,我们获得INFO输出而不再有DEBUG级语句。
要了解每个节点上存储的数据量,可以使用getLoadMap()方法,该方法将返回带有IP地址密钥的Java Map,其中包含相应存储负载的值。您还可以使用effectiveOwnership(String keyspace)操作来访问每个节点拥有的键空间中的数据百分比。
如果要查找某个键,可以使用getNaturalEndpoints(String table,byte [] key)操作。将表名和要查找端点值的密钥传递给它,它将返回负责存储此密钥的IP地址列表。
您还可以使用getRangeToEndpointMap操作来获取描述环形拓扑的范围到端点的映射。
如果您感觉很勇敢,可以为给定键空间中的给定表调用truncate()操作。如果所有节点都可用,则此操作将删除表中的所有数据,但保留其定义不变。
StorageServiceMBean为您提供了许多标准维护操作,包括resumeBootstrap(),joinRing(),repairAsync(),drain(),removeNode(),decommission(),以及启动和停止八卦的操作,本机传输以及节俭(直到Thrift终于被删除)。了解可用的维护操作对于保持集群的健康状况非常重要,我们将在第11章中详细介绍。
存储代理MBean
正如我们在第6章中学到的,org.apache.cassandra.service.StorageProxy在StorageService之上提供了一个层来处理客户端请求和节点间通信。 StorageProxyMBean提供了检查和设置各种操作(包括读取和写入)的超时值的功能。
此MBean还提供对提示的切换设置的访问,例如存储提示的最大时间窗口。提示的切换统计信息包括getTotalHints()和getHintsInProgress()。您可以使用禁用HintsForDC()操作禁用特定节点的提示。
您还可以通过setHintedHandoffEnabled()打开或关闭此节点参与提示切换,或通过getHintedHandoffEnabled()检查当前状态。这些由nodetool的enablehandoff,disablehandoff和statushandoff命令分别使用。
reloadTriggerClasses()操作允许您安装新的触发器而无需重新启动节点。
ColumnFamilyStoreMBean
Cassandra为org.apache.cassandra.db> Tables(以前为ColumnFamilies)下的节点中存储的每个表注册org.apache.cassandra.db.ColumnFamily Store MBean的实例。
ColumnFamilyStoreMBean提供对每个表的压缩和压缩设置的访问。这允许您临时覆盖特定节点上的这些设置。重新启动节点时,这些值将重置为在表架构上配置的值。
MBean还公开了有关该表的节点在磁盘上的数据存储的大量信息。 getSSTableCountPerLevel()操作提供每个层中有多少个SStables的列表。 estimateKeys()操作提供对此节点上存储的分区数量的估计。总之,这些信息可以让您了解是否为此表调用forceMajorCompaction()操作可能有助于释放此节点上的空间并提高读取性能。
还有一个trueSnapshotsSize()操作,允许您确定不再处于活动状态的SSTable shapshots的大小。此处的较大值表示您可以考虑删除这些快照,可能是在制作存档副本之后。
由于Cassandra将索引存储为表,因此每个索引列还有一个ColumnFamilyStoreMBean实例,可在org.apache.cassandra.db> IndexTables(以前为IndexColumnFamilies)下使用,具有相同的属性和操作。
CacheServiceMBean
org.apache.cassandra.service.CacheServiceMBean提供对域org.apache.cassandra.db>缓存下的Cassandra密钥缓存,行缓存和计数器缓存的访问。每个缓存可用的信息包括缓存项目的最大大小和持续时间,以及使每个缓存无效的能力。
CommitLogMBean
org.apache.cassandra.db.commitlog.CommitLogMBean公开了允许您了解提交日志当前状态的属性和操作。 Commit LogMBean还公开了recover()操作,该操作可用于从存档的提交日志文件中恢复数据库状态。
控制提交日志恢复的默认设置在conf / commitlog_archiving.properties文件中指定,但可以通过MBean覆盖。我们将在第11章中了解有关数据恢复的更多信息。
压缩管理器MBean
我们已经在org.apache.cassandra.db.compaction.CompactionManagerMBean的源代码中查看了它与JMX的交互方式,但我们并没有真正谈论它的用途。这个MBean允许我们获取有关过去执行的压缩的统计信息,以及通过调用Compaction Manager类的forceUserDefinedCompaction方法强制压缩我们识别的特定SSTable文件的能力。这个MBean由nodetool命令利用,包括compact,compactionhistory和compactionstats。
Snitch MBeans
Cassandra提供两个MBean来监视和配置告密者的行为。 org.apache.cassandra.locator.EndpointSnitchInfoMBean提供给定主机的机架和数据中心的名称,以及正在使用的snitch的名称。
如果您正在使用DynamicEndpointSnitch,则会注册org.apache.cassandra.locator.FynamicEndpointSnitchMBean。此MBean公开了重置snitch用于将节点标记为脱机的不良阈值的功能,以及允许您查看各个节点的分数。
HintedHandoffManagerMBean
除了前面提到的StorageServiceMBean上的暗示切换操作之外,Cassandra还通过org.apache.cassandra.db.HintedHandOffManagerMBean提供了对提示切换的更精细控制。 MBean通过调用listEndpointsPendingHints()来公开列出存储提示的节点的能力。然后,您可以通过scheduleHintDelivery()强制将提示传递到节点,或者使用deleteHintsForEndpoint()删除为特定节点存储的提示。
此外,您可以使用pauseHint Delivery()暂停和恢复提示传递到所有节点,或使用truncateAllHints()操作删除所有节点的存储提示。这些由nodetool的pausehandoff,resumehandoff和truncatehints命令分别使用。
org.apache.cassandra.hints.HintsService在域org.apache.cassandra .hints> HintsService下公开HintsServiceMBean。此MBean提供暂停和恢复提示切换的操作,并删除为所有节点或由IP地址标识的特定节点存储的提示。
由于StorageService MBean,HintedHandOffManagerMBean和HintsServiceMBean之间存在大量重叠,因此在将来的版本中可能会对这些操作进行一些合并。
网络MBean
org.apache.cassandra.net域包含MBean,用于帮助管理Cassandra的网络相关活动,包括Phi故障检测和八卦,消息服务和流管理器。
FailureDetectorMBean
org.apache.cassandra.gms.FailureDetectorMBean提供描述其他节点的状态和Phi分数的属性,以及Phi定罪阈值。
GossiperMBean
org.apache.cassandra.gms.GossiperMBean提供对Gossiper工作的访问。
我们已经讨论过StorageServiceMBean如何报告哪些节点无法访问。根据该列表,您可以调用GossiperMBean上的getEndpointDowntime()操作来确定给定节点已关闭多长时间。停机时间是从我们正在检查的MBean的节点的角度来衡量的,当节点重新联机时该值会重置。 Cassandra在内部使用此操作来了解它可以等待多长时间来丢弃提示。
getCurrentGenerationNumber()操作返回与特定节点关联的世代号。生成号包含在节点之间交换的八卦消息中,用于区分节点的当前状态和重启之前的状态。节点处于活动状态时,世代号保持不变,并且每次节点重新启动时都会增加。它由Gossiper使用时间戳维护。
assassinateEndpoint()操作试图通过告诉其他节点该节点已被永久删除来从环中删除节点,类似于人类八卦中的“角色暗杀”概念。当无法正常从群集中删除节点时,暗杀节点是最后的维护步骤。 nodetool assassinate命令使用此操作。
StreamManagerMBean
org.apache.cassandra.streaming.StreamManagerMBean允许我们查看节点与其对等体之间发生的流活动。这里有两个基本思想:流源和流目的地。每个节点都可以将其数据流式传输到另一个节点以执行负载平衡,StreamManager类支持这些操作。 StreamManagerMBean为在集群中的节点之间移动的数据提供必要的视图。
StreamManagerMBean支持两种操作模式。 getCurrentStreams()操作提供当前传入和传出流的快照,MBean还发布与流状态更改相关的通知,例如初始化,完成或失败。您可以在JMX客户端中订阅这些通知,以便在流式传输操作发生时进行观察。
因此,与StorageServiceMBean结合使用时,如果您担心某个节点没有接收到应有的数据,或者某个节点是不平衡甚至是不合适的,那么这两个MBean一起工作可以让您深入了解您的确切发生的事情。簇。
Metrics MBeans
访问与应用程序性能,运行状况和关键活动相关的指标的能力已成为维护Web级应用程序的基本工具。幸运的是,Cassandra在自己的活动中收集了大量指标,以帮助我们了解行为。
Cassandra报告的指标包括以下内容:
- 描述Cassandra使用内存的缓冲池指标。
- CQL指标,包括准备和常规语句执行的数量。
- 缓存密钥,行和计数器缓存的度量标准,例如条目数与容量,以及命中率和未命中率。
- 客户端指标,包括已连接客户端的数量,以及有关客户端请求的信息,如延迟,故障和超时。
- 提交日志指标,包括提交日志大小和待处理和已完成任务的统计信息。
- 压缩指标,包括压缩的总字节数以及待处理和已完成压缩的统计数据。
- 群集中每个节点的连接指标,包括八卦。
- 丢弃的消息指标,用作nodetool tpstats的一部分。
- 阅读修复指标,描述随时间推移执行的后台修复与阻止读取修复的次数。
- 存储指标,包括正在进行的提示计数和总提示。
- 线程池度量标准,包括每个线程池的活动,已完成和已阻止的任务。
- 表格指标,包括缓存,memtables,SSTables和Bloom过滤器使用情况以及各种读写操作的延迟,以1分钟,5分钟和15分钟的间隔报告。
- Keyspace指标,用于聚合每个键空间中表的指标。
为了通过JMX访问这些指标,Cassandra使用Dropwizard Metrics开源Java库。 Cassandra使用Metrics库注册其度量标准,而Metrics库又将它们公开为org.apache.cassandra.metrics域中的MBean。
许多这些指标由nodetool命令使用,例如tpstats,表直方图和代理组合图。例如,tpstats只是线程池和已删除消息度量的表示。
线程MBeans
org.apache.cassandra.internal域包含MBean,允许您配置与Cassandra的分阶段事件驱动架构(SEDA)中的每个阶段关联的线程池。这些阶段包括AntiEntropyStage,GossipStage,InternalResponseStage,MigrationStage等。
由于历史原因,ReadRepairStage MBean位于org.apache.cassandra.request域下,而不是org.apache.cassandra.internal。
线程池是通过org.apache.cassandra .concurrent包中的JMXEnabledThreadPoolExecutor和JMXEnabledScheduledThreadPoolExecutor类实现的。每个阶段的MBean实现JMXEnabledScheduledThreadPoolExecutorMBean接口,该接口允许您查看和配置每个线程池中的核心线程数以及最大线程数。
服务MBean
GCInspectorMXBean公开单个操作getAndResetStats(),该操作检索并重置Cassandra在其JVM上收集的垃圾收集指标。此MBean出现在org.apache.cassandra.service域中。 nodetool gcstats命令可以访问此MBean。
安全MBean
org.apache.cassandra.auth域包含与安全相关的MBean,这些MBean根据相同的Java包名称进行分组。从3.0版本开始,它由一个MBean(PermissionsCacheMBean)组成,它以org.apache.cassandra.auth.PermissionsCache的形式向客户端公开。我们将在第13章讨论这个MBean。
使用nodetool进行监控
我们已经在之前的章节中探讨了nodetool提供的一些命令,但让我们借此机会正确介绍。
nodetool附带Cassandra,可以在 / bin中找到。这是一个命令行程序,它提供了丰富的方法来查看您的群集,了解其活动并对其进行修改。 nodetool允许您获得有关群集的有限统计信息,查看每个节点维护的范围,将数据从一个节点移动到另一个节点,停用节点,甚至修复有问题的节点。
nodetool中的许多任务与JMX接口中可用的功能重叠。这是因为,在幕后,nodetool使用名为org.apache .cassandra .tools.NodeProbe的帮助程序类调用JMX。因此JMX正在做实际工作,NodeProbe类用于连接到JMX代理并检索数据,NodeCmd类用于在交互式命令行界面中呈现它。
nodetool使用与Cassandra守护程序相同的环境设置:Unix上的bin / cassandra.in.sh和conf / cassandra-env.sh(或Windows上的bin / cassandra.in.bat和conf / cassandra-env.ps1)。日志记录设置位于conf / logback-tools.xml文件中;这些工作方式与conf / logback.xml中的Cassandra守护程序日志记录设置相同。
启动nodetool是一件轻而易举的事。只需打开终端,导航到,然后输入以下命令:
$ bin/nodetool help
这会导致程序打印一个可用命令列表,其中几个我们将暂时介绍。不带参数运行nodetool等同于help命令。您还可以使用特定命令的名称执行帮助以获取其他详细信息。
除help命令外,nodetool必须连接到Cassandra节点才能访问有关该节点或集群的信息。
您可以使用-h选项来标识要与nodetool连接的节点的IP地址。如果未指定IP地址,则该工具会尝试连接到本地计算机上的默认端口,这是本章中我们将采用的示例方法。
获取群集信息
您可以获得有关群集及其节点的各种信息,我们将在本节中介绍这些信息。您可以获得有关单个节点或参与环的所有节点的基本信息。
describecluster
describecluster命令打印出有关集群的基本信息,包括名称,告密者和分区器:
$ bin/nodetool describecluster
Cluster Information:
Name: Test Cluster
Snitch: org.apache.cassandra.locator.DynamicEndpointSnitch
Partitioner: org.apache.cassandra.dht.Murmur3Partitioner
Schema versions:
2d4043cb-2124-3589-b2d0-375759b9dd0a: [127.0.0.1, 127.0.0.2, 127.0.0.3]]
输出的最后一部分对于识别表定义中的任何不一致或节点之间的“模式”尤其重要。 当Cassandra通过集群传播模式更改时,通常会快速解决任何差异,因此任何延迟的模式差异通常表示需要重新启动的节点已关闭或无法访问。
状态
识别群集中节点以及它们所处状态的更直接方法是使用status命令:
$ bin/nodetool status
Datacenter: datacenter1
=======================
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns Host ID
UN 127.0.0.1 103.82 KB 256 ? 31d9042b-6603-4040-8aac-fef0a235570b
UN 127.0.0.2 110.9 KB 256 ? caad1573-4157-43d2-a9fa-88f79344683d
UN 127.0.0.3 109.6 KB 256 ? e78529c8-ee9f-46a4-8bc1-3479f99a1860
状态由数据中心和机架组织。 每个节点的状态由双字符代码标识,其中第一个字符指示节点是否已启动(当前可用并准备好查询)或向下,第二个字符指示节点的状态或操作模式。 load列表示每个节点持有的数据的字节数。
owns列指示节点拥有的令牌范围的有效百分比,并考虑复制。 因为我们没有指定键空间,并且此集群中的各种键空间具有不同的复制策略,所以nodetool无法计算有意义的所有权百分比。
信息
info命令告诉nodetool连接单个节点并获取有关其当前状态的基本数据。 只需将您想要信息的节点的地址传递给它:
$ bin/nodetool -h 192.168.2.7 info
ID : 197efa22-ecaa-40dc-a010-6c105819bf5e
Gossip active : true
Thrift active : false
Native Transport active: true
Load : 301.17 MB
Generation No : 1447444152
Uptime (seconds) : 1901668
Heap Memory (MB) : 395.03 / 989.88
Off Heap Memory (MB) : 2.94
Data Center : datacenter1
Rack : rack1
Exceptions : 0
Key Cache : entries 85, size 8.38 KB, capacity 49 MB,
47958 hits, 48038 requests, 0.998 recent hit rate, 14400 save
period in seconds
Row Cache : entries 0, size 0 bytes, capacity 0 bytes,
0 hits, 0 requests, NaN recent hit rate, 0 save period in seconds
Counter Cache : entries 0, size 0 bytes, capacity 24 MB,
0 hits, 0 requests, NaN recent hit rate, 7200 save period in seconds
Token : (invoke with -T/--tokens to see all 256 tokens)
报告的信息包括节点的内存和磁盘使用情况(“负载”)以及Cassandra提供的各种服务的状态。 您还可以通过nodetool命令statusgossip,statusthrift,statusbinary和statushandoff检查各个服务的状态(请注意,切换状态不是信息的一部分)。
环
要确定环中的节点以及它们所处的状态,请在nodetool上使用ring命令,如下所示:
$ bin/nodetool ring
Datacenter: datacenter1
==========
Address Rack Status State Load Owns Token
9208237582789476801
192.168.2.5 rack1 Up Normal 243.6 KB ? -9203905334627395805
192.168.2.6 rack1 Up Normal 243.6 KB ? -9145503818225306830
192.168.2.7 rack1 Up Normal 243.6 KB ? -9091015424710319286
此输出按vnodes组织。在这里,我们看到环中所有节点的IP地址。在这种情况下,我们有三个节点,所有节点都已启动(当前可用且已准备好进行查询)。 load列表示每个节点持有的数据的字节数。描述命令的输出类似,但是围绕令牌范围组织。
nodetool提供的其他有用状态命令包括:
- getLoggingLevels和setLoggingLevels命令允许使用我们之前讨论过的Logback JMXConfiguratorMBean动态配置日志记录级别。
- gossipinfo命令通过八卦将此节点与其自身通信的参数打印到其他节点。
- version命令打印此节点正在运行的Cassandra版本。
获取统计数据
nodetool还允许您在聚合级别以及特定键空间和表的级别收集有关服务器状态的统计信息。两个最常用的命令是tpstats和tablestats,我们现在都要检查它们。
使用tpstats
tpstats工具为我们提供了有关Cassandra维护的线程池的信息。 Cassandra高度并发,并针对多处理器/多核机器进行了优化。此外,Cassandra在内部采用了分阶段事件驱动架构(SEDA),因此了解线程池的行为和运行状况对于良好的Cassandra维护非常重要。
要查找有关线程池的统计信息,请使用tpstats命令执行nodetool:
$ bin/nodetool tpstats
Pool Name Active Pending Completed Blocked All time
blocked
ReadStage 0 0 216 0 0
MutationStage 1 0 3637 0 0
CounterMutationStage 0 0 0 0 0
ViewMutationStage 0 0 0 0 0
GossipStage 0 0 0 0 0
RequestResponseStage 0 0 0 0 0
AntiEntropyStage 0 0 0 0 0
MigrationStage 0 0 2 0 0
MiscStage 0 0 0 0 0
InternalResponseStage 0 0 2 0 0
ReadRepairStage 0 0 0 0 0
Message type Dropped
READ 0
RANGE_SLICE 0
_TRACE 0
HINT 0
MUTATION 0
COUNTER_MUTATION 0
BATCH_STORE 0
BATCH_REMOVE 0
REQUEST_RESPONSE 0
PAGED_RANGE 0
READ_REPAIR 0
输出的顶部显示了每个Cassandra线程池中的任务数据。您可以直接查看处于哪个阶段的操作数量,以及它们是处于活动状态,待处理状态还是已完成状态。在写入操作期间捕获此输出,因此显示MutationStage中存在活动任务。
输出的底部指示节点的已删除消息数。丢弃的消息是Cassandra减载实现的一个指标,当每个节点收到的请求超过它可以处理的数量时,每个节点都会使用它来保护自己。例如,节点接收但未在rpc_timeout内处理的节点间消息被丢弃而不是处理,因为协调节点将不再等待响应。
在输出中看到大量的零用于被阻止的任务和丢弃的消息意味着您在服务器上的活动非常少,或者Cassandra在保持负载方面做得非常出色。很多非零值表示Cassandra很难跟上的情况,并且可能表明需要第12章中描述的某些技术。
使用tablestats
要查看键空间和表的概述统计信息,可以使用tablestats命令。您也可以从之前的名称cfstats中识别此命令。以下是酒店键空间的示例输出:
$ bin/nodetool tablestats hotel
Keyspace: hotel
Read Count: 8
Read Latency: 0.617 ms.
Write Count: 13
Write Latency: 0.13330769230769232 ms.
Pending Flushes: 0
Table: hotels
SSTable count: 3
Space used (live): 16601
Space used (total): 16601
Space used by snapshots (total): 0
Off heap memory used (total): 140
SSTable Compression Ratio: 0.6277372262773723
Number of keys (estimate): 19
Memtable cell count: 8
Memtable data size: 792
Memtable off heap memory used: 0
Memtable switch count: 1
Local read count: 8
Local read latency: 0.680 ms
Local write count: 13
Local write latency: 0.148 ms
Pending flushes: 0
Bloom filter false positives: 0
Bloom filter false ratio: 0.00000
Bloom filter space used: 56
Bloom filter off heap memory used: 32
Index summary off heap memory used: 84
Compression metadata off heap memory used: 24
Compacted partition minimum bytes: 30
Compacted partition maximum bytes: 149
Compacted partition mean bytes: 87
Average live cells per slice (last five minutes): 1.0
Maximum live cells per slice (last five minutes): 1
Average tombstones per slice (last five minutes): 1.0
Maximum tombstones per slice (last five minutes): 1
这里我们省略了键空间中其他表的输出,因此我们可以专注于酒店表; 为每个表生成相同的统计信息。 我们可以在键空间和表级看到读写延迟和读写总数。 我们还可以看到有关Cassandra每个表的内部结构的详细信息,包括memtables,Bloom过滤器和SSTables。
总结
在本章中,我们介绍了监视和管理Cassandra集群的方法。 特别是,我们详细介绍了JMX,并了解了Cassandra为MBean服务器提供的各种操作。 我们了解了如何使用JConsole和nodetool来查看Cassandra集群中发生的情况。 您现在已准备好了解如何执行日常维护任务以帮助保持Cassandra集群的健康。