神经网络中的神经元和激活函数详解
在上一节,我们通过两个浅显易懂的例子表明,人工智能的根本目标就是在不同的数据集中找到他们的边界,依靠这条边界线,当有新的数据点到来时,只要判断这个点与边界线的相互位置就可以判断新数据点的归属。
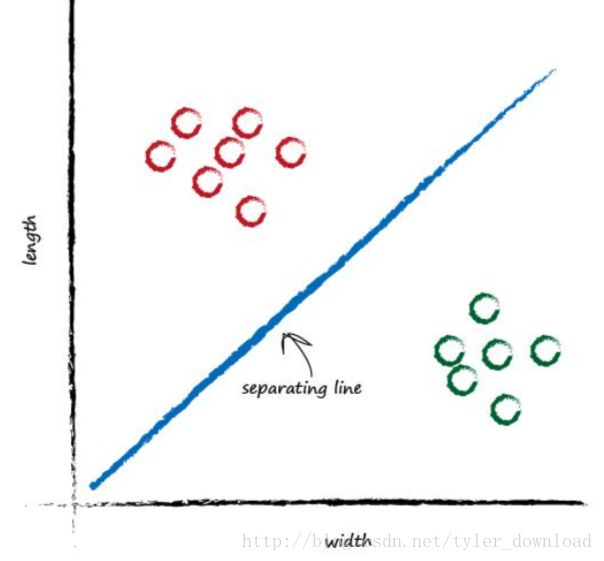
上一节我们举得例子中,数据集可以使用一条直线区分开。但对很多问题而言,单一直线是无法把数据点区分开的,例如亦或运算, 当两数的值不同时,亦或结果为1,相同时亦或运算结果为0,我们用 oxr 标记亦或运算,那么输入是0和1时,有以下几种情况:
1 xor 0 = 10 xor 1 = 11 xor 1 = 00 xor 0 = 0
- 1
我们把输入的四种情况绘制到坐标轴上看看:
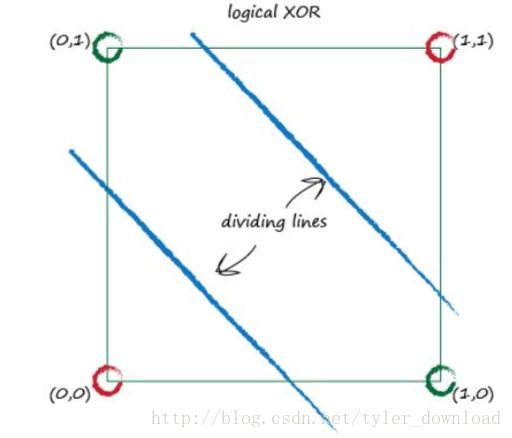
我们看到,两个绿色点属于同一集合,因为绿色点做亦或运算后结果都是1,红色点属于统一集合,因为他们做运算后结果都是0,然而面对这种情形,你根本无法用一根直线把两种集合点区分开来,你必须如上图所示,用两根直线才能区分,如果点在两根直线之间,那么他们属于同一集合,如果点处于两跟直线之外,那么他们属于另外一个集合。
如果你觉得这篇文章看起来稍微还有些吃力,或者想要系统地学习人工智能,那么推荐你去看床长人工智能教程。非常棒的大神之作,教程不仅通俗易懂,而且很风趣幽默。
所谓神经网络就是由很多个神经元组成的集合,我们可以认为一个神经元用于绘制一段分割线,复杂的数据分布需要很多条形状各异的线条才能组成合理的分界线,数据分布的情况越复杂,我们就需要越多个神经元来进行运算。
深度学习的神经网络借助了生物学对脑神经系统的研究成果。一个生物大脑神经元如下所示:
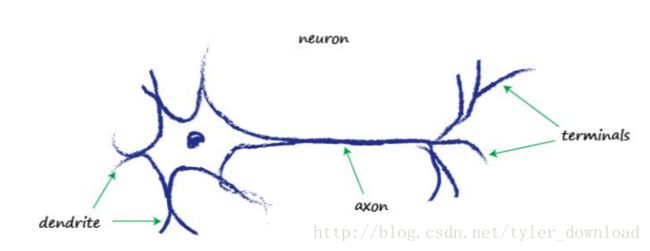
最左边的部分’dendrite‘叫突触,它用来接收外界输入的电信号,中间部分axon叫轴突,它把突触接收的信号进行整合处理,右边部分terminals叫终端输出,它把轴突整合后的信号切分成多部分,分别传送给其他神经元。下图是脑神经学家从鸽子脑子获取的神经元图像:

人的大脑大概有一千亿个神经元组成一个庞大的计算网络。苍蝇大脑只有十万个神经元,尽管如此,苍蝇就能够控制飞行,寻找食物,识别和躲避危险,这些很看似简单的动作操控就连现在最强大的计算机都无法实现。生物大脑其运算能力远逊于计算机,为何生物能轻而易举做到的事情计算机却做不到呢?大脑的运行机制目前人类还没有完全搞懂,但有一点可以肯定的是,生物大脑的运算运行存在“模糊性”,而电子计算机不行。
我们看一个神经元是如何工作的。神经元接收的是电信号,然后输出另一种电信号。如果输入电信号的强度不够大,那么神经元就不会做出任何反应,如果电信号的强度大于某个界限,那么神经元就会做出反应,向其他神经元传递电信号:
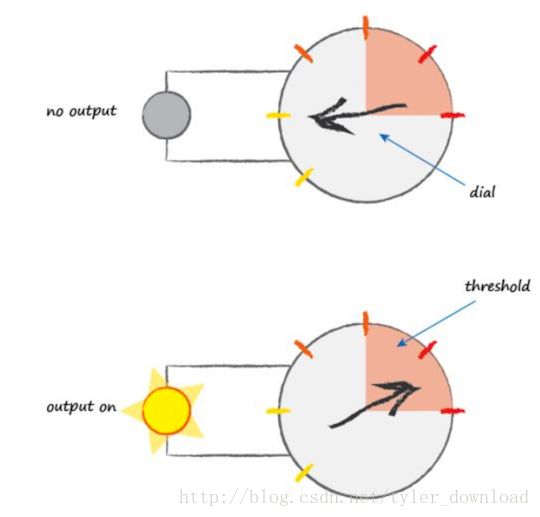
想象你把手指深入水中,如果水的温度不高,你不会感到疼痛,如果水的温度不断升高,当温度超过某个度数时,你会神经反射般的把手指抽出来,然后才感觉到疼痛,这就是输入神经元的电信号强度超过预定阈值后,神经元做出反应的结果。为了模拟神经元这种根据输入信号强弱做出反应的行为,在深度学习算法中,运用了多种函数来模拟这种特性,最常用的分布是步调函数和sigmoid函数,我们先看看步调函数的特性,我们通过以下代码来绘制步调函数:
import matplotlib.pyplot as pltx = [1,2,3,4]y = [0, 1, 2, 3]plt.step(x, y)plt.show()
- 1
- 2
- 3
- 4
- 5
- 1
上面代码运行后结果如下:
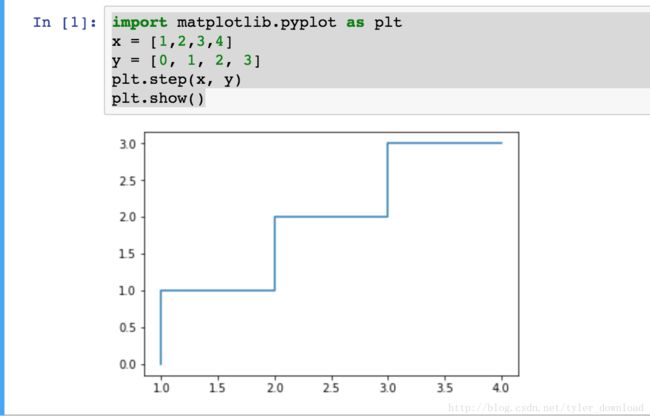
我们看到,这个函数的特点是,当输入的x小于1时,函数的输出一直都是零。当输入的x大于等于1时,输出一下子从零跃迁到1,当x输入处于1到2之间时,输出一直是1,当x增大到2以上时,输出一下子跃迁到2,以此类推。
第二种常用的模拟函数就是sigmoid,它的形状就像字母S,输入下面代码绘制sigmoid函数:
from matplotlib import pylabimport pylab as pltimport numpy as npdef sigmoid(x): return (1 / (1 + np.exp(-x)))mySamples = []mySigmoid = []x = plt.linspace(-10, 10, 10)y = plt.linspace(-10, 10, 100)plt.plot(x, sigmoid(x), 'r', label = 'linspace(-10, 10, 10)')plt.plot(y, sigmoid(y), 'r', label='linspace(-10, 10, 1000)')plt.grid()plt.title('Sigmoid function')plt.suptitle('Sigmoid')plt.legend(loc='lower right')plt.text(4, 0.8, r'$\sigma(x)=\frac{1}{1+e^(-x)}$', fontsize=15)plt.gca().xaxis.set_major_locator(plt.MultipleLocator(1))plt.gca().yaxis.set_major_locator(plt.MultipleLocator(0.1))plt.xlabel('X Axis')plt.ylabel('Y Axis')plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 1
上面代码执行后结果如下:
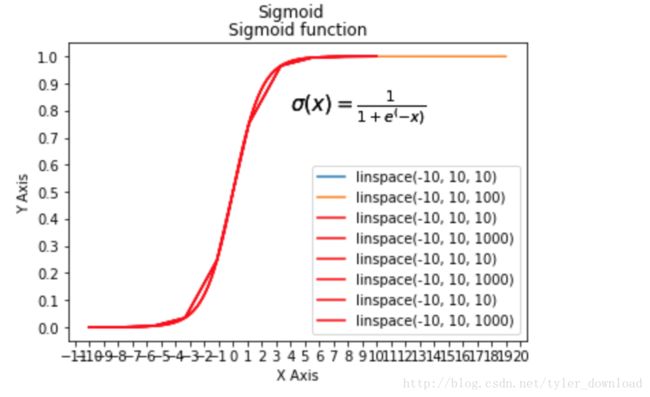
从函数图我们看到,当输入小于0时,函数的输出增长很缓慢,当输入大于0时,输出便极具增长,等到x大到一定程度后,输出保持在固定水准。sigmoid函数的代数式子如下:
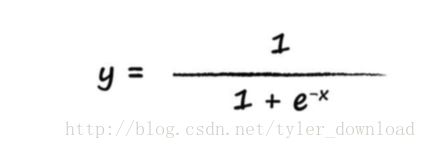
其中的字母e表示欧拉常数,它的值约为2.71828。以后面对更复杂的问题时,我们还得使用更复杂的模拟函数,所有这些模拟神经元对电信号进行反应的函数统称为激活函数。
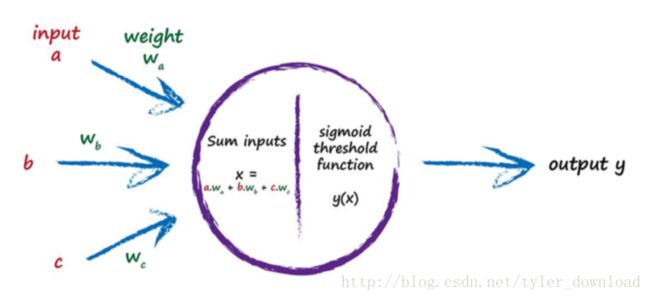
一个神经元会同时接收多个电信号,把这些电信号统一起来,用激活函数处理后再输出新的电信号,如下图:

神经网络算法中设计的神经元会同时接收多个输入参数,它把这些参数加总求和,然后代入用激活函数,产生的结果就是神经元输出的电信号。如果输入参数加总的值不大,那么输出的信号值就会很小,如果输入信号中,有某一个值很大其他的都很小,那么加总后值很大,输出的信号值就会变大,如果每个输入参数都不算太大,但加总后结果很大,于是输出的信号值就会很大,这种情况就使得运算具备一定的模糊性,这样就跟生物大脑的神经元运转方式很相像。
神经元不是各自为战,而是连成一个网络,并对电信号的处理形成一种链式反应:
前一个神经元接收输入信号,处理后会把输出信号分别传送给下一层的多个神经元。在神经网络算法上也会模拟这种特性,在算法设计中,我们会构造如下的数据结构:
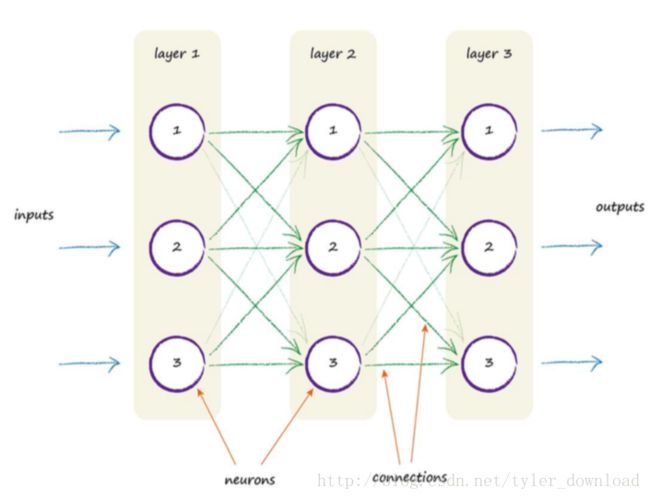
上面有三层节点,每层有三个节点,第一层的节点接收输入,进行运算后,把输出结果分别提交给下一层的三个节点,如此类推直到最后一层。现在问题是,这种结构如何像上一节我们举得例子那样,根据误差进行学习调整呢?事实上,在上一层的节点把处理后的电信号传达到下一层的节点时,输出信号会分成若干部分分别传给下一层的不同节点,每一部分都对应一个权值,如下图:
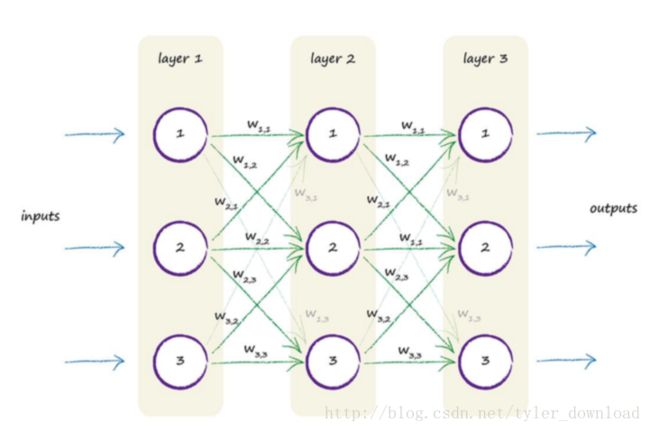
我们看到,第一层的节点1把输出信号传给第二层的节点1时,传递路径上有一个权值W(1,1),也就是节点1输出的电信号值乘以这个权值W(1,1)后,所得的结果才会提交给第二层的节点1,同理第一层节点1输出的信号要乘以W(1,2)这个权值后,所得结果才会传递给第二层节点2.
这些参数就对应于我们上一节例子中用于调整的参数,整个网络对输入进行运算后,在最外层产生输出,输出会跟结果进行比对,获取误差,然后网络再根据误差反过来调整这些层与层之间的传递参数,只不过参数调整的算法比我们前一节的例子要复杂不少。接下来我们看看一个具体的两层网络信号传递运算过程。
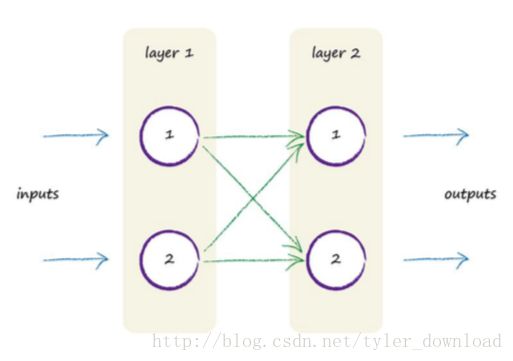
上图是一个两层网络,每个网络有两个节点,假设从第一次开始输入两个信号,分别是1,0.5:
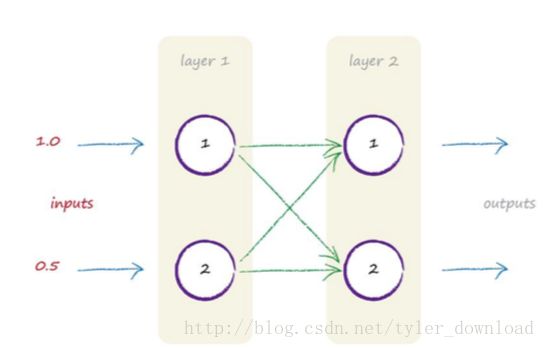
第一层神经元直接把输入加总后分发到第二层,第二层神经元使用的激活函数是sigmoid, 神经元之间的信号权值如下:
W(1,1) = 0.9; W(1,2) = 0.2W(2,1) = 0.3; W(2,2) = 0.8
- 1
- 2
- 1
就如上一节例子描述的,一开始每层节点间的权值是随机获取的。于是第一层神经元处理信号后把输出传递给第二层:
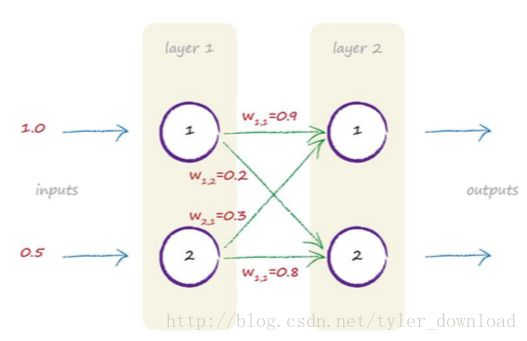
主要的运算发生在第二层的神经元节点。第二层的神经元要把第一层传来的信号值加总然后在传给sigmoid激活函数
从第一层第一个节点传给第二层第一个节点的信号值是 1.0 * 0.9 = 0.9; 第一层第二个节点传给第二层第一个节点的信号值是 0.5 * 0.3 = 0.15。第二层第一个节点把这些信号值加总后得 X = 0.9 + 0.15 = 1.05; 再把这个值传给sigmoid函数: 1 / (1 + exp(-x));也就是y = 1 / (1 + exp(-1.05)) = 0.7408;
第一层第一个节点传递给第二层第二个节点的信号值是 1.0 * 0.2 = 0.2; 第一层第二个节点传给第二层第二个节点的信号值是 0.5 * 0.8 = 0.4, 第二层第二个节点把这些信号值加总得 X = 0.2 + 0.4 = 0.6, 再将其传入激活函数得 y = 1 / (1 + exp(-0.6)) = 0.6457,最后我们得到神经网络的输出结果为: (0.7408, 0.6457)。
下一节我们将深入研究如何使用张量运算加快神经网络的运算,以及探讨如何通过误差调整网络中节点间的权值。