使用pytorch搭建ResNet并基于迁移学习训练
文章目录
- 1. ResNet网络结构、BN以及迁移学习介绍
- 2. ResNet网络及迁移学习-花分类实例
-
- model.py
- train.py
- predict.py
1. ResNet网络结构、BN以及迁移学习介绍
ResNet网络结构、BN以及迁移学习介绍传送门:ResNet网络结构、BN以及迁移学习介绍
ResNet网络参数列表

下图对应18、34层的网络残差结构
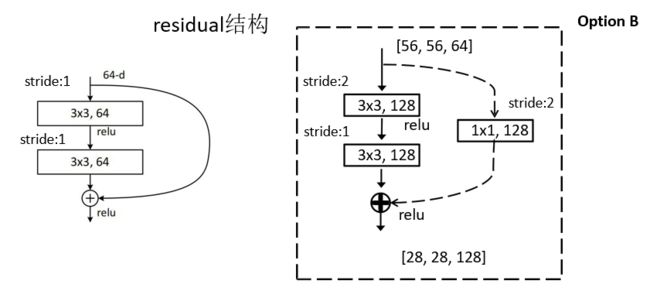
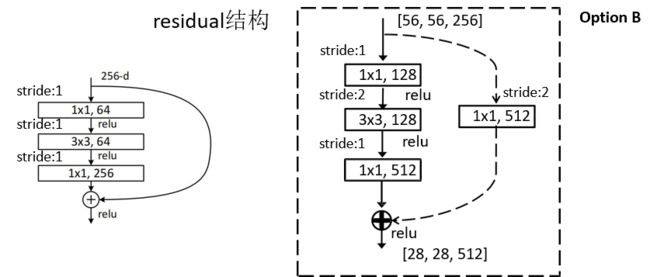
下图对应50、101、152层的网络残差结构
2. ResNet网络及迁移学习-花分类实例
model.py
import torch.nn as nn
import torch
class BasicBlock(nn.Module): # 针对18层和34层的残差结构
expansion = 1 # 对应残差结构主分支结构当中,同一卷积层 每层卷积核的个数是否发生改变
# 初始化函数,各参数依次为:输入特征矩阵深度、输出特征矩阵深度(对应主分支上卷积核的个数)
# downsample下采样参数(对应虚线的残差结构)
def __init__(self, in_channel, out_channel, stride=1, downsample=None):
super(BasicBlock, self).__init__()
# stride默认=1(表示实线残差结构)output=(input-3+2*1)/1+1=input
# 输出特征矩阵的高和宽未改变
#
# stride默认=2(表示虚线残差结构)output=(input-3+2*1)/2+1=input/2+0.5
# =input/2(向下取整)。输出特征矩阵的高和宽缩减为原来的一半
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
kernel_size=3, stride=stride, padding=1, bias=False)
# 使用BN时,将bias=False
# 将BN层放在卷积层conv和激活层relu之间
self.bn1 = nn.BatchNorm2d(out_channel)
self.relu = nn.ReLU()
# 接下来开始第二层卷积层,stride都=1
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel,
kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channel)
self.downsample = downsample # 定义下采样方法=传入的下采样参数
def forward(self, x): # 正向传播过程,x为输入的特征矩阵
identity = x # 将x赋值给分支identity
if self.downsample is not None: # =none没有输入下采样函数,对应实线残差结构,跳过此部分
# is not None输入了下采样函数,对应虚线残差结构,将输入特征矩阵输入下采样中,得到捷径分支identity的输出
identity = self.downsample(x)
# 主分支
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
# 主分支的输出+捷径分支的输出,再使用激活函数
out += identity
out = self.relu(out)
# 返回残差结构的最终输出
return out
class Bottleneck(nn.Module): # 针对更深层次的残差结构
# 以50层conv2_x为例,卷积层1、2的卷积核个数=64,而第三层卷积核个数=64*4=256,故expansion = 4
expansion = 4
def __init__(self, in_channel, out_channel, stride=1, downsample=None):
super(Bottleneck, self).__init__()
# 对于第一层卷积层,无论是实线残差结构还是虚线,stride都=1
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
kernel_size=1, stride=1, bias=False) # squeeze channels
self.bn1 = nn.BatchNorm2d(out_channel)
# 对于第二层卷积层,实线残差结构和虚线的stride是不同的,stride采用传入的方式
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel,
kernel_size=3, stride=stride, bias=False, padding=1)
self.bn2 = nn.BatchNorm2d(out_channel)
# -----------------------------------------
self.conv3 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel*self.expansion,
kernel_size=1, stride=1, bias=False) # unsqueeze channels
self.bn3 = nn.BatchNorm2d(out_channel*self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
# 正向传播过程
def forward(self, x):
identity = x
# self.downsample=none对应实线残差结构,否则为虚线残差结构
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x) # 卷积层
out = self.bn1(out) # BN层
out = self.relu(out) # 激活层
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out += identity
out = self.relu(out)
return out
class ResNet(nn.Module):
# 若选择浅层网络结构block=BasicBlock,否则=Bottleneck
# blocks_num所使用的残差结构的数目(是一个列表),若选择34层网络结构,blocks_num=[3,4,6,3]
# num_classes训练集的分类个数
# include_top参数便于在ResNet网络基础上搭建更复杂的网络
def __init__(self, block, blocks_num, num_classes=1000, include_top=True):
super(ResNet, self).__init__()
self.include_top = include_top
self.in_channel = 64 # 输入特征矩阵的深度(经过最大下采样层之后的)
# 第一个卷积层,对应表格中7*7的卷积层,输入特征矩阵的深度RGB图像,故第一个参数=3
self.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2,
padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(self.in_channel)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) # 对应3*3那个maxpooling
# conv2_x对应的残差结构,是通过_make_layer函数生成的
self.layer1 = self._make_layer(block, 64, blocks_num[0])
# conv3_x
self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2)
# conv4_x
self.layer3 = self._make_layer(block, 256, blocks_num[2], stride=2)
# conv5_x
self.layer4 = self._make_layer(block, 512, blocks_num[3], stride=2)
if self.include_top:
# 平均池化下采样层,AdaptiveAvgPool2d自适应的平均池化下采样操作,所得到特征矩阵的高和宽都是(1,1)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # output size = (1, 1)
# 全连接层(输出节点层)
self.fc = nn.Linear(512 * block.expansion, num_classes)
# 卷积层初始化操作
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
# block为BasicBlock或Bottleneck
# channel残差结构中所对应的第一层的卷积核的个数(值为64/128/256/512)
# block_num对应残差结构中每一个conv*_x卷积层的个数(该层一共包含了多少个残差结构)例:34层的conv2_x:block_num取值为3
def _make_layer(self, block, channel, block_num, stride=1):
downsample = None # 下采样赋值为none
# 对于18层、34层conv2_x不满足此if语句(不执行)
# 而50层、101层、152层网络结构的conv2_x的第一层也是虚线残差结构,需要调整特征矩阵的深度而高度和宽度不需要改变
# 但对于conv3_x、conv4_x、conv5_x不论ResNet为多少层,特征矩阵的高度、宽度、深度都需要调整(高和宽缩减为原来的一半)
if stride != 1 or self.in_channel != channel * block.expansion:
# 生成下采样函数
downsample = nn.Sequential(
nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(channel * block.expansion))
layers = [] # 定义一个空列表
# 参数依次为输入特征矩阵的深度,残差结构所对应主分支上第一个卷积层的卷积核个数
# 18层34层的conv2_x的layer1没有经过下采样函数那个if语句downsample=none
# conv2_x对应的残差结构,通过此函数_make_layer生成的时,没有传入stride参数,stride默认=1
layers.append(block(self.in_channel, channel, downsample=downsample, stride=stride))
self.in_channel = channel * block.expansion
# conv3_x、conv4_x、conv5_x的第一层都是虚线残差结构,
# 而从第二层开始都是实线残差结构了,直接压入统一处理
for _ in range(1, block_num): # 由于第一层已经搭建好,从1开始
# self.in_channel:输入特征矩阵的深度,channel:残差结构主分支第一层卷积的卷积核个数
layers.append(block(self.in_channel, channel))
# 通过非关键字参数的形式传入到nn.Sequential,nn.Sequential将所定义的一系列层结构组合在一起并返回
return nn.Sequential(*layers)
# 正向传播
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
if self.include_top:
x = self.avgpool(x) # 平均池化下采样
x = torch.flatten(x, 1) # 展平处理
x = self.fc(x) # 全连接
return x
def resnet18(num_classes=1000, include_top=True):
return ResNet(BasicBlock, [2, 2, 2, 2], num_classes=num_classes, include_top=include_top)
def resnet34(num_classes=1000, include_top=True):
return ResNet(BasicBlock, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)
def resnet50(num_classes=1000, include_top=True):
return ResNet(Bottleneck, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)
def resnet101(num_classes=1000, include_top=True):
return ResNet(Bottleneck, [3, 4, 23, 3], num_classes=num_classes, include_top=include_top)
def resnet152(num_classes=1000, include_top=True):
return ResNet(Bottleneck, [3, 8, 36, 3], num_classes=num_classes, include_top=include_top)
train.py
import torch
import torch.nn as nn
from torchvision import transforms, datasets
import json
import matplotlib.pyplot as plt
import os
import torch.optim as optim
from model import resnet34, resnet101
import torchvision.models.resnet
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
"val": transforms.Compose([transforms.Resize(256), # 长宽比例不变,将最小边缩放到256
transforms.CenterCrop(224), # 再中心裁减一个224*224大小的图片
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])}
data_root = os.path.abspath(os.path.join(os.getcwd(), "../..")) # get data root path
image_path = os.path.join(data_root, "data_set", "flower_data") # flower data set path
assert os.path.exists(image_path), "{} path does not exist.".format(image_path)
train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"),
transform=data_transform["train"])
train_num = len(train_dataset)
# {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}
flower_list = train_dataset.class_to_idx
cla_dict = dict((val, key) for key, val in flower_list.items())
# write dict into json file
json_str = json.dumps(cla_dict, indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
batch_size = 16
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
print('Using {} dataloader workers every process'.format(nw))
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size, shuffle=True,
num_workers=nw)
validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"),
transform=data_transform["val"])
val_num = len(validate_dataset)
validate_loader = torch.utils.data.DataLoader(validate_dataset,
batch_size=batch_size, shuffle=False,
num_workers=nw)
print("using {} images for training, {} images fot validation.".format(train_num,
val_num))
# 若不使用迁移学习的方法,注释掉61-69行,并net = resnet34(num_calsses参数)
net = resnet34() # 未传入参数,最后一个全连接层有1000个结点
# load pretrain weights
# download url: https://download.pytorch.org/models/resnet34-333f7ec4.pth
model_weight_path = "./resnet34-pre.pth"
assert os.path.exists(model_weight_path), "file {} does not exist.".format(model_weight_path)
# net.load_state_dict载入模型权重。torch.load(model_weight_path)载入到内存当中还未载入到模型当中
missing_keys, unexpected_keys = net.load_state_dict(torch.load(model_weight_path), strict=False)
# for param in net.parameters():
# param.requires_grad = False
# change fc layer structure
in_channel = net.fc.in_features # 输入特征矩阵的深度。net.fc是所定义网络的全连接层
# 类别个数
net.fc = nn.Linear(in_channel, 5) # 类别个数
net.to(device)
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.0001)
best_acc = 0.0
save_path = './resNet34.pth'
for epoch in range(3):
# train
net.train()
running_loss = 0.0
for step, data in enumerate(train_loader, start=0):
images, labels = data
optimizer.zero_grad()
logits = net(images.to(device))
loss = loss_function(logits, labels.to(device))
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
# print train process
rate = (step+1)/len(train_loader)
a = "*" * int(rate * 50)
b = "." * int((1 - rate) * 50)
print("\rtrain loss: {:^3.0f}%[{}->{}]{:.4f}".format(int(rate*100), a, b, loss), end="")
print()
# validate
net.eval() # 控制训练过程中的Batch normalization
acc = 0.0 # accumulate accurate number / epoch
with torch.no_grad():
for val_data in validate_loader:
val_images, val_labels = val_data
outputs = net(val_images.to(device)) # eval model only have last output layer
# loss = loss_function(outputs, test_labels)
predict_y = torch.max(outputs, dim=1)[1]
acc += (predict_y == val_labels.to(device)).sum().item()
val_accurate = acc / val_num
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)
print('[epoch %d] train_loss: %.3f test_accuracy: %.3f' %
(epoch + 1, running_loss / step, val_accurate))
print('Finished Training')
if __name__ == '__main__':
main()
predict.py
import torch
from model import resnet34
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
import json
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
data_transform = transforms.Compose(
[transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]) # 预处理
# load image
img = Image.open("../tulip.jpg")
plt.imshow(img)
# [N, C, H, W]
img = data_transform(img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0)
# read class_indict
try:
json_file = open('./class_indices.json', 'r')
class_indict = json.load(json_file)
except Exception as e:
print(e)
exit(-1)
# create model
model = resnet34(num_classes=5)
# load model weights
model_weight_path = "./resNet34.pth"
model.load_state_dict(torch.load(model_weight_path, map_location=device))
model.eval()
with torch.no_grad(): # 不对损失梯度进行跟踪
# predict class
output = torch.squeeze(model(img)) # 压缩batch维度
predict = torch.softmax(output, dim=0) # 得到概率分布
predict_cla = torch.argmax(predict).numpy() # argmax寻找最大值对应的索引
print(class_indict[str(predict_cla)], predict[predict_cla].numpy())
plt.show()
花分类数据集0积分下载