Kafka和Redis性能对比
Kafka和Redis性能对比
能力
关于卡夫卡
Kafka是一种分布式,分区和复制的提交日志服务,它提供消息传递功能以及独特的设计。我们可以在日志聚合过程中使用此功能。
Kafka使用的基本消息传递术语是:
主题:这些是发布消息的类别。
生产者:这是将消息发布到Kafka主题中的过程。
使用者:此过程订阅主题并处理消息。使用者是使用者组的一部分,该使用者组由许多使用者实例组成,以实现可伸缩性和容错能力。
代理:Kafka群集中的每个服务器都称为代理。
从不同来源获取的日志可以通过几个生产者流程输入到各种Kafka主题中,然后由消费者使用。
Kafka提供了多种将数据推送到主题的方法:
从命令行客户端:Kafka有一个命令行客户端,用于从特定文件或标准输入中获取输入,并将它们作为消息推送到Kafka集群中。
使用Kafka Connect:Kafka提供了一种工具,该工具使用连接器来实现自定义逻辑,以将数据导入/导出到集群。
通过编写自定义集成代码:最后一种方法是使用Java生产者API编写用于将数据源与Kafka集成的代码。
在Kafka中,每个主题都有由服务器管理的日志数据分区:
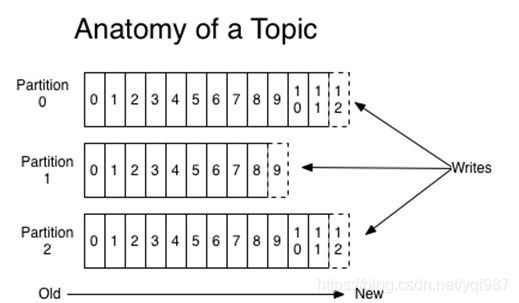
Kafka在一个分布式系统中的多个服务器之间分配分区日志。 每个分区都跨多个服务器复制,以实现容错功能。 由于采用了这种分区系统,Kafka在处理中提供了并行性。 一个消费者组中的一个以上消费者可以按照存储消息的相同顺序同时检索数据。
此外,Kafka允许使用所需数量的服务器。 它使用磁盘进行存储,因此加载可能会变慢。 但是,由于磁盘存储容量的原因,它可以存储大量数据(即以TB为单位),而保留时间更长。
关于Redis
Redis在存储和各种功能方面与Kafka有点不同。 Redis的核心是一个内存中的数据存储,可用作高性能数据库,缓存和消息代理。非常适合实时数据处理。
Redis支持的各种数据结构是字符串,哈希,列表,集合和排序集合。 Redis还具有以多种语言编写的各种客户端,可用于编写用于插入和检索数据的自定义程序。两者之间的主要相似之处在于它们都提供消息传递服务。但是出于日志聚合的目的,我们可以使用Redis的各种数据结构来更高效地进行操作。
性能
在测试Redis和Kafka的性能时,结果非常有趣。
卡夫卡
Kafka流行的消息队列系统经过Linkedin等主要公司的大量测试,实际上,其工程师实际上是在编写Kafka的第一版。 在他们的测试中,LinkedIn在群集模式下将Kafka与六台计算机一起使用,每台计算机均具有Intel Xeon 2.5 GHz处理器,六个内核,32 GB RAM和六个7200 RPM SATA驱动器。
生产者
对于第一个测试,创建了一个具有六个分区且没有复制的主题。 使用单个生产者在单个线程中生成了5000万条记录。 每个消息大小为100字节。使用此设置产生的峰值吞吐量超过800K记录/秒或78 MB /秒。 在不同的测试中,他们使用相同的基本设置,三个生产者在三台不同的计算机上运行。 在这种情况下,我们看到该峰值更高,大约为2,000条记录/秒或193.0 MB /秒。
异步复制与同步复制
第二批测试涉及复制方法。 使用相同数量的记录和消息大小,并且使用与先前测试相似的单个生成器,就有三个副本。 复制以异步方式进行,其吞吐量峰值约为766K记录/秒或75 MB /秒。
但是,当复制是同步的时-这意味着主服务器正在等待来自副本的确认-吞吐量峰值很低,约为420K记录/秒或40 MB /秒。 尽管这是一种可靠的设置,因为它可以确保所有消息都到达,但由于主服务器确认消息接收所花费的时间,因此吞吐量会大大降低。
消费者
在这种情况下,他们使用了完全相同的消息数量和大小以及6个分区和3个副本。 他们通过增加消费者数量来应用相同的方法。 在第一个使用单个使用者的测试中,最高吞吐量为940K记录/秒或89 MB /秒。 但是,不足为奇的是,当使用三个使用者时,吞吐量达到每秒处理2615K条记录或249.5 MB /秒。
Kafka的吞吐量性能基于生产者数量,使用者数量和复制方法的结合。 为此,其中的测试之一是单个生产者,单个使用者和异步模式下的三个副本。 该测试中达到的峰值是处理的795K记录/秒或75.8 MB /秒。
消息处理量
如下所示,随着记录大小的增加,我们可以预期每秒记录的减少:

消息大小与吞吐量(记录/秒)(源)
但是,正如我们在下图中所看到的,随着记录大小(以字节为单位)的增长,吞吐量也会随之增长。 较小的消息将导致低吞吐量。 这是由于排队消息的开销会影响计算机性能:
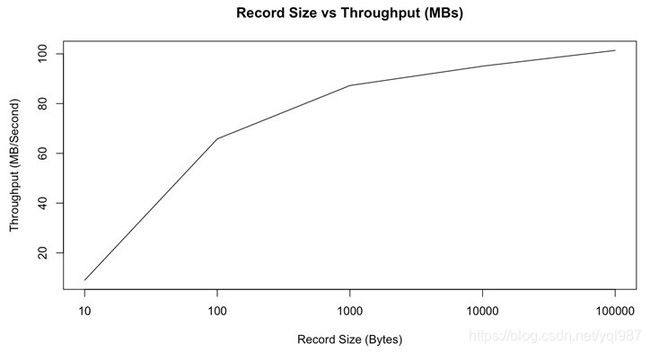
消息大小与吞吐量(MB /秒)(源)
另外,如下图所示,已使用的数据量不会影响Kafka的性能。
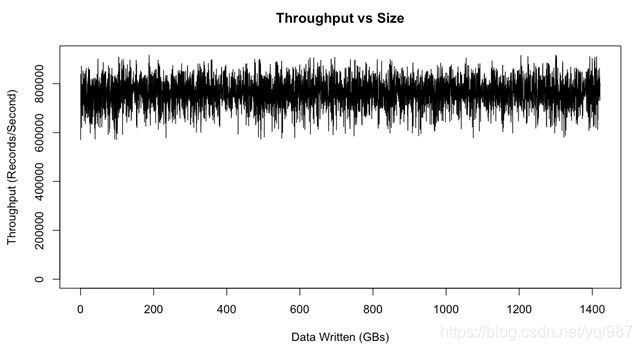
吞吐量与大小(来源)
Kafka严重依赖于机器内存(RAM)。 如上图所示,利用内存和存储是维持稳定吞吐量的最佳方法。 其性能取决于数据消耗率。 如果使用者没有足够快地使用数据,Kafka将不得不从磁盘而不是内存中读取数据,这会降低其性能。
Redis吞吐量
让我们检查一下Redis在消息处理速率方面的性能。 我们使用了非常基本的Redis命令来帮助我们评估其性能:SET,GET,LPUSH和LPOP。 这些是常用的Redis命令,用于存储和检索Redis值和列表。
在此测试中,我们生成了2M个请求。 密钥长度设置为0到999999之间,单个值大小为100字节。 使用Redis基准命令测试了Redis。
Redis管道
如下所示,在我们的第一个测试中,我们发现使用Redis流水线时在性能改进方面存在显着差异。 原因是,通过管道,我们可以将多个请求发送到服务器,而无需等待答复,最后一步即可检查答复。
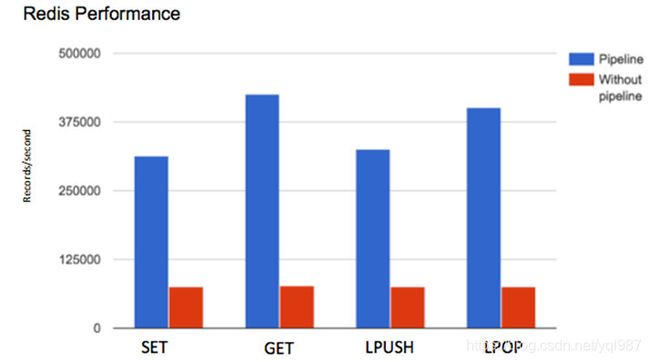
带或不带Redis管线(2.6 GHz Intel Core i5,8GB RAM)的吞吐量与命令
Redis上的数据大小可能会有所不同。 如您所见,下图显示了具有不同值(消息)大小的吞吐量。 在图表中,很容易看出,当消息大小增加时,吞吐量(以每秒的请求数表示)会降低。 如下所示,此行为与所有四个命令一致。
 吞吐量与不同消息大小(字节)
吞吐量与不同消息大小(字节)
另外,如下所示,我们以字节为单位测量了写入数据。 我们看到,随着记录数量的增加,Redis中的写入字节数也随之增加,这在某种程度上是直观的,与我们在Kafka中注意到的相同。

GET命令的吞吐量与值大小
Redis快照支持Redis持久性模式。 它会根据用户的喜好生成时间点快照,例如,包括从上次快照经过的时间或写入次数。 但是,例如,如果Redis实例重新启动或崩溃,则连续快照之间的所有数据都将丢失。 在这种情况下,Redis持久性不支持持久性,并且仅限于那些近期数据不重要的应用程序。
Kafka vs.Redis:摘要
如上所述,Redis是一个内存存储。这意味着它使用其主内存进行存储和处理,这使其比基于磁盘的Kafka快得多。 Redis内存中存储的唯一问题是我们不能长时间存储大量数据。
由于主内存小于磁盘,因此我们必须定期清除数据,方法是自动将数据从内存中移动到磁盘并为新数据腾出空间。 Redis是持久性的,它允许我们在必要时将数据集转储到磁盘中。 Redis也遵循主从架构,复制仅在主服务器中启用持久性时才有用。
此外,Redis不像Kafka那样具有并行性的概念,在并行性中,多个进程可以同时使用数据。
基于这两种工具的功能,尽管上述针对Kafka与Redis的测试并不完全相同,但我们仍然可以总结出,在以最小延迟处理实时消息处理时,您应该首先尝试Redis。但是,如果消息很大并且应该重用数据,则应首先考虑使用Kafka。
