【Linux】-进程间通信-匿名管道通信(以及模拟一个进程池)

作者:小树苗渴望变成参天大树
作者宣言:认真写好每一篇博客
作者gitee:gitee✨
作者专栏:C语言,数据结构初阶,Linux,C++ 动态规划算法
如 果 你 喜 欢 作 者 的 文 章 ,就 给 作 者 点 点 关 注 吧!
文章目录
- 前言
- 一、进程间通信的三个问题
-
- 1.1什么是进程间通信??
- 1.2 为什么要进程间通信??
- 1.3 怎么做到进程间通信??
- 二、管道的原理
- 三、接口的测试
- 四、编写代码进行通信
-
- 4.1管道的四种情况
- 4.2 管道的五大特性
- 五、基于管道设计一个简单的进程池
- 六、总结
讲解逻辑:
- 根据前面的知识来推测进程之间大致是怎么通信的
- 直接讲解基于文件级别的通信方式
- 关于进程间通信的接口。五大特征以及四种情况
- 谈谈应用场景
前言
今天我们开始讲解进程间通信,我们之前讲过进程具有独立性,那么有的时候进程还是需要进行一些数据性的交换,但是又不能破怪独立性,这两者看着自相矛盾,但又不冲突,博主就是来带大家去解决这个问题,从原理到模拟实现一个进程间通信的程序,需要大家对之前的进程创建,进程等待,尤其是文件系统那一章节熟悉,那今天的内容才容易理解,所以希望没有这些知识储备的小伙伴可以先看我前面的博客讲解,再来看这篇,效果会更好,接下来我们开始进入正文的讲解。
一、进程间通信的三个问题
1.1什么是进程间通信??
简单的来说就是两个或者多个进程实现数据层面的交互,因为进程独立性的存在,导致了进程间通信的成本比较高,所以在一会的讲解过程种,大家可能会觉得进程间的通信挺费劲的,这都是情理之中的。
1.2 为什么要进程间通信??
- 数据传输:一个进程需要将它的数据发送给另一个进程
- 资源共享:多个进程之间共享同样的资源。
- 通知事件:一个进程需要向另一个或一组进程发送消息,通知它(它们)发生了某种事件(如进程终止时要通知父进程)。
- 进程控制:有些进程希望完全控制另一个进程的执行(如Debug进程),此时控制进程希望能够拦截另一个进程的所有陷入和异常,并能够及时知道它的状态改变.这点一会会模拟实现一个类似于进程池的,让主进程控制子进程做任务。
1.3 怎么做到进程间通信??
以两个进程间通信为例:由于进程间是独立性的,想要实现通信,需要找一个公共的资源,让这两个进程看到同一份资源,但这份资源又不属于这两个进程的任意一个,这样就不会破坏两者的独立性。
(1)“资源”指的是什么??是一块特定的内存空间。
(2) 这个“资源”谁提供??一般情况下os提供。
为什么不是两个进程的其中一个,假设是其中一个,另一个读取这个数据或者修改,就对拥有这个资源的进程产生影响,破坏独立性,用反证法也可以论述我开头说的第一句话。
(3) 由上面两点我们得出结论,我们进程通过访问这个“资源”,也就是这一块内存空间,进行通信,本质就是在访问os,我们的进程是通过用户编写代码形成可执行程序,形成进程,运行在os上,所以可以间接认为进程代表的就是用户,既然是用户,os系统最不信任的其实就是用户,所以在进程间进行通信的过程,就是用户之间进程通信,中间os从创建这个‘’资源‘’,使用,释放一般(今天博主讲的方式是要通过系统接口去调用,但是其他方式可能不需要)都需要通过系统接口去调用,从底层设计,这些接口设计,都需要os独立去设计的,一般操作系统都会设计一个独立的通信模块(IPC通信模块),归属于文件系统。一会再来介绍为什么归属于文件系统,这些通信之间想要实现再任何一台主机,或者不同的主机上运行,就必须采取同一种方式,就是制定一套标准,再网络部分也有标准由了这些标准才有了我们现在的互联网。
上面的一切都是我们之前学过的知识来推测出来进程间通信会这样搞的,这也更好的衔接我们的知识,那我们有哪些标准,对于本机内部(system V),对于网络(posix)
system V:
- System V 消息队列
- System V 共享内存
- System V 信号量
posix:
- 消息队列
- 共享内存
- 信号量
- 互斥量
- 条件变量
- 读写锁
对于system V,只讲第二点,其余两种不介绍,对于posix我们等到讲解网络的时候再讲,现在知道我们有这两个标准就好了。
管道
还有一种通信方式就是管道,这种通信方式可以说非常的简单,因为他是基于文件级别的通信方式,目前也可以简单理解复用了文件的那一套。他的大致想法是,进程管理系统和文件系统这两者是独立的,进程之间打开相同的文件,只不过把这个文件的引用计数改变一下而已,这个文件不属于两个进程中的任意一个。通过对文件的读写来交换数据,这样就保证了进程之间是独立的。
但是里面的细节还是比较多,接下来我们开始进入下一个话题。
二、管道的原理
什么是管道:
管道是Unix中最古老的进程间通信的形式。
我们把从一个进程连接到另一个进程的一个数据流称为一个“管道
再我们命令行之前使用|来表示管道,每条命令就是一个进程
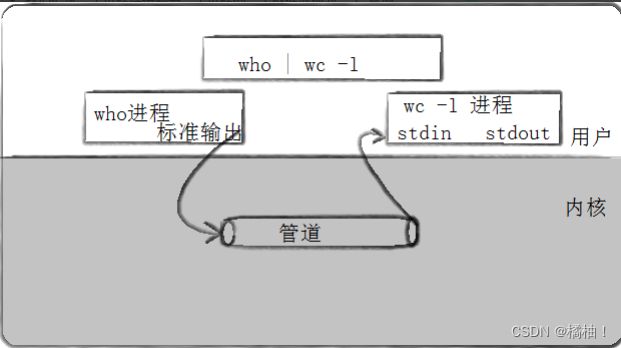
管道的特点就是一头进一头出,是单向的,一会介绍也是单向通信方式,下面介绍的是匿名管道
因为管道是基于文件级别的通信方式,我们刚讲解完文件系统没多久,所以大家能更好的理解。以父子进程为例:因为我们现在没有办法控制两个没有关系的进程,所以使用父子进程(这也是一个铺垫)。
我们先来讲解原理一:来看图解(解释是怎么让不同的进程看到同一份资源)

讲解原理二:来看图解(单向通信的设计)
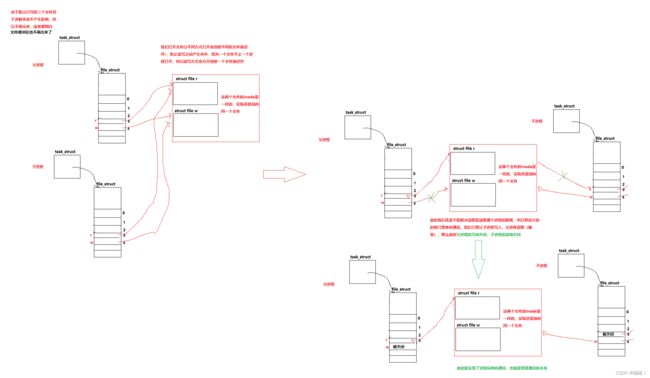
大家看到这里对于单向通信的原理应该理解了吧。
再来看一个生动的图:这里面的系统调用接口一会再介绍
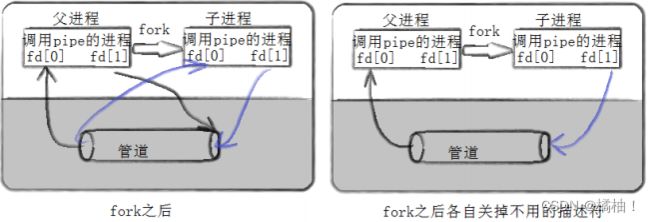
通过上面的原理介绍,我们还有问题:
- 怎么实现双向通信?? 建立多个管道
- 我们上面进程是父子关系,如果两个进程没有任何关系,可以这样去设计吗??不能,只有父子,兄弟,爷孙,有血缘关系的进程才可以,常用于父子间。
- 我们刚才的管道有名字吗??没有,因为是内存级文件,再内存中,要名字没啥意义,所以这就是匿名文件,也就是匿名管道。
- 那我们进程之间进行通信了吗??没有,我们知识建立了通信信道
- 为什么这么费劲?进程间具有独立性,通信是有成本的。
至此我们管道的原理就讲解完毕,接下来我们去使用一些接口来进行测试一下。
三、接口的测试
我们来认识一个系统调用接口pipe,来看文档:

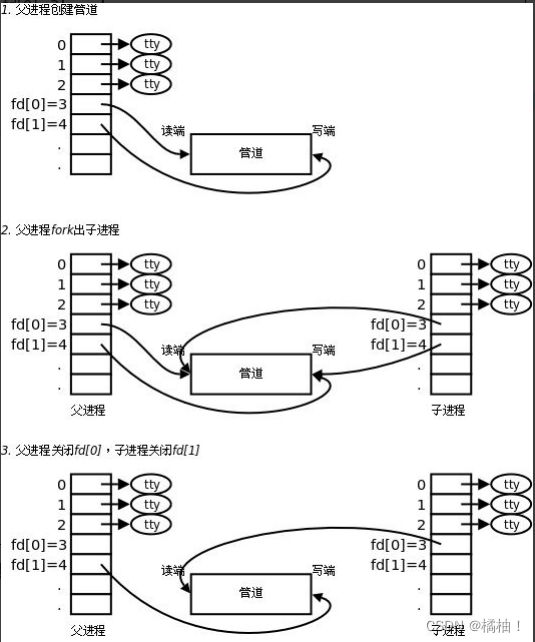
pipe就是建立进程间通信的,按照刚才的分析,自己写的程序出来默认打开的三个文件,就没有再打开其他文件,如果使用pipe建立信道,那么pipe会在内存给我们创建一个内存级文件,传进去的参数pipefd数组的返回就会带出两个文件描述符3和4,一会就来测试会不会出现这样的效果:
来看代码:
#include
我们看到结果我们分析原理的时候是一模一样的。接下来我将写一个程序来带大家实现父子进程间通信,也是为了更好介绍管道的四种情况。
为什么没有创建子进程就可以进程pipe呢??原因是我们的管道文件只要一个进成建立好。子进程拷贝父进程数据,增加一个执行那个就可以,就好比下面这个图:
pipefd[0]:读端
pipefd[1]:写端
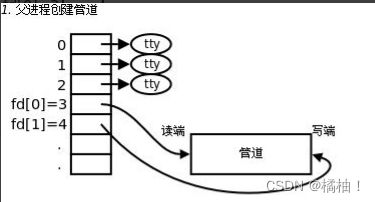
四、编写代码进行通信
#include
pid_t id=fork();//让子进程写,父进程读取
if(id<0)
{
perror("fork");
return 2;
}
else if(id==0)
{
//child;
//cout<<"pipefd[0]:"<
close(pipefd[0]);//子写关闭读端
//cout<<"pipefd[0]:"<
Writer(pipefd[1]);
close(pipefd[1]);
exit(0);
}
//father
close(pipefd[1]);//父读关闭写端
Reader(pipefd[0]);
int status=0;
pid_t ret=waitpid(id,&status,0);
if(ret==id)//等待成功
{
cout<<"child:"<<ret<<",exitcode:"<<((status>>8)&0xFF)<<",signlcode:"<<(status&0x7F)<<endl;
}
close(pipefd[0]);
sleep(5);
return 0;
}
我们来看结果一:我们通过子进程给父进程不断的发送一句话
写端一直写,读端就一直读
来看结果二:子进程只给父进程发送五次,每次发送一个字符
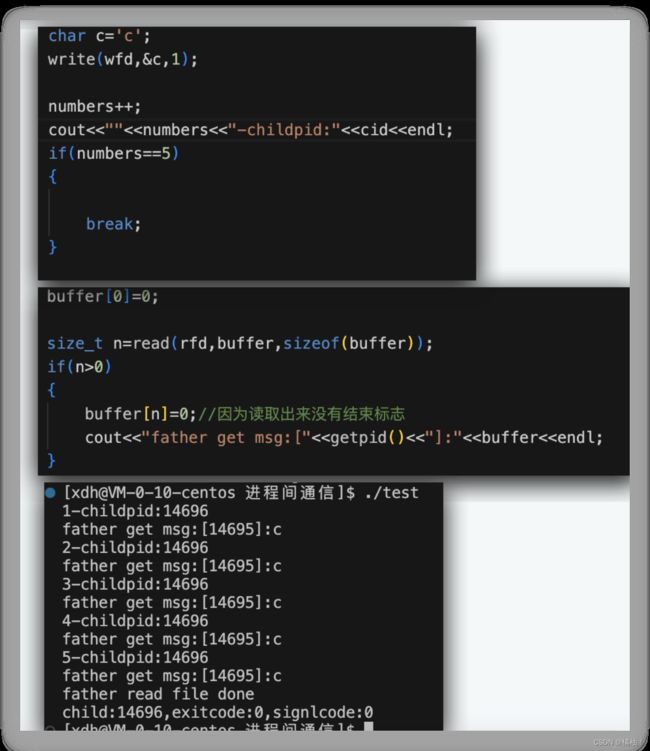
写入五次之后,放下管道里面为空,就读不到数据了。
4.1管道的四种情况
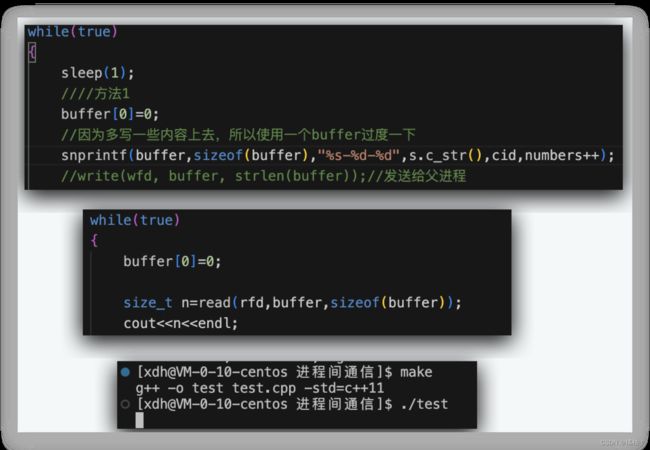
- 读写端正常,如果管道为空,读端就要被阻塞
我们来验证一下,我们将刚才的程序小改一下,把子进程的write函数注释掉,这样管道就是一直为空,而父进程的read不管读取成功还是失败都会返回一个值,把这个值打印出来,如果没打印出来,就说明read这个函数在等待读取,还没有返回值。为空为什么不结束,因为写端可能随时写数据进来,所以读端要阻塞等待。这个要和第三种情况区分开。
- 读写端正常,如果管道被写满,写端就要被阻塞。
我们的子进程一直往管道文件里面写入,一次写入一个字符,而父进程不读取,就会一直往管道文件里面写,写满了,就被阻塞了。使用一个变量记录写了多少次把管道文件写满,方便我们去计算管道文件的大小。

通过结果发现我们写到65536次就开始写端就开始阻塞了,因为我们是一次往管道里面写一个字符,所以我们的管道文件大小为65536/1024=64kb, 我们使用
ulimit -a来查看:cat /etc/redhat-release查看内核版本
在我这台机器的版本下,我们的管道文件大小居然是4kb与我们计算的不一样啊,这是为什么呢,我们来查看一下官方文档:man 7 page -> /page 跳转到这个文档。
前两点我们刚才已经认证过了,第三点提到了一个原子性,这是什么,给大家举个例子,假设子进程想给父进程写一句话hello,world,当刚写完hello,准备写world的时候,父进程看到管道里面有数据,直接就把hello读取走了,这样父进程就不是一起读到这个hello,world这个数据,所以在posix标准里面规定,写入的数据小雨这个pipe_buf大小的时候,即使管理里面有数据,父进程也不读取,这样就保证了原子性,我们可以理解为刚才看到的pipe size就是这个pipe_buf的大小,这个知识大家了解一下就可以了,主要记住管道文件是有固定大小的,看不同的内核版本,大家可以按照我上面的测试方法去计算一下自己的管道文件大小是多少。



- 读端正常读,写端被关闭,读端就会读到0,表明读到文件尾了,不会被阻塞。
我们子进程先给父进程给5次,父进程一直在读取,然后直接关闭自己的写端,前五次的写入已经被读取走了,所以当子进程关闭自己的写端,那么父进程此时就发现管道文件为空,就读取到文件结尾,read函数返回的是0,因为写端已经被关闭,里面不会有数据了,所以父进程的读端如果阻塞没有意义,还占资源,所以读端就直接读结束了。

我们的程序并没有想第一种情况一种在阻塞等待,而是直接结束了
- 写端正常写,读端被关闭,os就会直接杀掉正在写的进程
让子进程的写端不断的给父进程写数据,父进程读取五次后就关闭自己的读端,按照结论,子进程会被杀死,这就是之前的知识,进程进程,进程没运行完异常退出了,看退出码和系统信号。

我们看到我们的读端一旦关闭,子进程就被杀死退出,被父进程的waitpid获取到了,我们来看一下13号信号是什么:
就是管道信号,符合我们的测试。这也是博主为什么设计出父进程读,子进程写的目的,就是为了第四种情况了做实验的,等到讲解一个简单的进程池的时候,反过来让读者去感受一下

4.2 管道的五大特性
通过上面的四种情况以及管道的原理,我们很清楚的知道你名管道具有下面的五点特性
- 匿名管道是具有血缘关系的进程间进行通信。
- 只能进行单向通信
- 管道是基于文件操作的,而文件的生命周期是随进程的,后面介绍的有名还有共享内存都不是随着进程的生命周期的
- 通过管道的前两种情况,匿名管道是具有同步互斥机制的,而后面说的共享内存不具有。
- 管道是面向字节流的,这个后面说到多线程的时候再讲。
总结:
对于上面的情况,都是基于最上面的代码进行修改去测试的,每种情况要修改那部分博主也截出来了,大家先把我一开始写的程序理解了,然后在测试这些情况,不然很摸不清楚头脑。
五、基于管道设计一个简单的进程池
大家还记得我们的内存吃,他的见到理解就是,我们如果想要100mb的空间,我们不需要一次申请10mb,申请十次,这样会增加消耗,所以一次申请100mb,放到内存池里面,和自己打交道总比和内存打交道省事,我们的进程池也是类似的道理,先创建对歌子进程,然后想要哪个进程做事就直接分配,不需要在创建进程了,就好比公司,先做人才储备,需要的时候上,如果没有人才储备,到时候在要人就来不及了,让我们一起来看看这个进程池怎么去实现吧。
test.cpp
#include
// write(cls[which]._fd,&cmdcode,sizeof(int));//发送任务
// sleep(1);//每隔一秒发送一次任务给子进程
// }
//这是轮转的给子进程发任务
// int which=0;//这是选择哪一个进程
// while(true)//一直给子进程发送任务,如果想控制次数,再循环里面操作break即可
// {
// //随机得出子进程所在数组的下标
// int cmdcode=rand()%_task.size()+1;//因为任务也是数组存储起来的,所以父进程给子进程发一个存储任务数组的下标消息就可以了
// cout<<"father say:"<<"cmdcode:"<
// write(cls[which]._fd,&cmdcode,sizeof(int));//发送任务
// sleep(1);//每隔一秒发送一次任务给子进程
// which++;
// which%=cls.size();
// }
//自己制作一个菜单给子进程发送任务
menu();
while(true)
{
int which=rand()%cls.size();//随机得出子进程所在数组的下标
cout<<"请输入你的选择:";
int cmdcode=0;
cin>>cmdcode;
if(cmdcode<=0||cmdcode>4)
{
break;
}
cout<<"father say:"<<"cmdcode:"<<cmdcode<<"already sento"<<cls[which]._id<<" processname:"<<cls[which]._processname<<endl;
write(cls[which]._fd,&cmdcode,sizeof(int));//发送任务
sleep(1);//每隔一秒发送一次任务给子进
}
}
void quitprocess(const vector<channls>& cls)
{
for(const auto& e:cls) close(e._fd);//子进程读端被关闭,就会被信号杀掉,等着父进程回收
for(const auto& e:cls) waitpid(e._id,NULL,0);
}
int main()
{
LoadTask(&_task);
srand(time(nullptr)^getpid()^1023);//种一个随机数种子
vector<channls> cls;//就类似于进程池
cout<<getpid()<<endl;
Initprocess(cls);//初始化
ctrlSlaver(cls);//父进程开始控制子进程
quitprocess(cls);
return 0;
}
test.hpp:声明和定义可以在一起的头文件,再模板那一节应该提到过
#include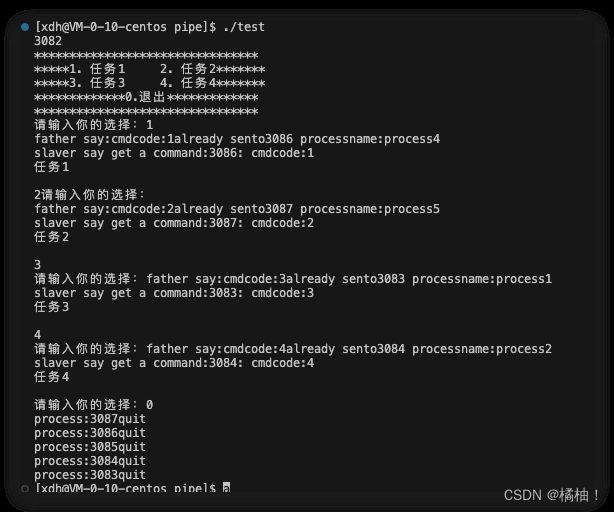
通过这个程序大家应该感觉有点意思了,这个代码的所有注释都写了,大家下去好好研究一下。
上面程序的bug
上面的程序有一个隐藏的bug,但是影响不大,大家有没有发现博主的退出进程的函数,两个循环是分成写,为什么不一起写,例如下面这样:
void quitprocess(const vector<channls>& cls)
{
for(const auto& e:cls)
{
close(e._fd);
waitpid(e._id,NULL,0);
}
}
给大家画个图:

因为我们是循环创建子进程,这样就导致,后面创建子进程的时候,父进程和上一个子进程的写端还没有关闭,就被继承下来了,这样就导致,我们的父子进程之间不是只有一个写端和一个读端的单向通信了,我们的子进程之间也可以进行互相通信,如果按照一个循环的方式去写,目的是想让写端关闭,读端就会读到文件尾,符合第三种情况,但是我们的第一个进程不止一个写端,所以一个循环是解决不了的。
但是我们的最后一个进程的管道是只有一个写端和一个读端的,我们先把这个写端关闭,这个进程就会终止,他上面继承下来的写端就会关闭,导致在他创建进程的前面的所有子进程的管道的写端指向都少一个,这样关闭释放到最后一个子进程的时候,也是只有一个写端了。
void quitprocess(const vector<channls>& cls)
{
int last=cls.size()-1;
for(int i=last;i>=0;i--)//从后往前释放,根据进程中指,对应的写端下标也就没有了。
{
close(cls[i]._fd);
waitpid(cls[i]._id,NULL,0);
}
}
但是我们的bug还是没有解决,因为还是存在子进程之间互相通信的可能,所以我们想要解决这个问题,我们就要使用一个数组讲父进程的写端下标保存起来,在子进程里面遍历数组将其关闭即可。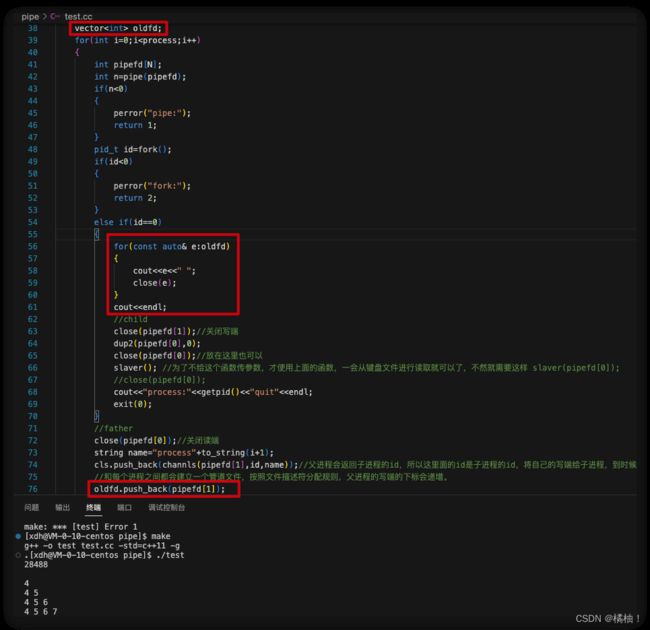
加这三处代码也可以解决这个问题,该说不说这个bug藏的挺身,但是对这个程序影响不大,也是通过这个bug让大家可以更好的理解父子进程间通信的原理,博主认为,人只要一学过难一点的知识,前面那些一开始认为难的也会变得简单容易理解多了,这也是为什么要坚持下去的原因,只有坚持到后面,理解东西的成本就会越低,这样学起来才更有信心。
六、总结
今天讲的知识,是匿名管道,他的原理不难理解,我们要明白进程间通信的本质是什么,让不同的进程看到同一份资源,这个在后面讲解命名管道和共享内存的时候都会讲,所以希望大家好好的理解这篇的知识点,尤其要好好理解进程池这个代码,我们下篇再见