【NLP】培训LLM的不同方式
在大型语言模型(LLM)领域,存在多种具有不同手段、要求和目标的培训机制。由于它们有不同的用途,因此重要的是不要将它们相互混淆并了解它们适用的不同场景。
在本文中,我想概述一些最重要的训练机制,包括预训练、微调、人类反馈强化学习 (RLHF)和适配器。此外,我将讨论提示的作用,提示本身不被认为是一种学习机制,并阐明提示调整的概念,它在提示和实际训练之间架起了一座桥梁。
预训练

预训练是最基本的训练方式,与您所知道的其他机器学习领域的训练相同。在这里,您从未经训练的模型(即具有随机初始化权重的模型)开始,并训练以在给定一系列先前标记的情况下预测下一个标记。为此,从各种来源收集大量句子,并将其分成小块提供给模型。
这里采用的训练模式称为自我监督。从正在训练的模型的角度来看,我们可以说是监督学习方法,因为模型在做出预测后总是得到正确的答案。例如,给定序列“我喜欢冰”……模型可能会预测“锥体”作为下一个单词,然后可能会被告知答案是错误的,因为实际的下一个单词是“奶油”。最终,可以计算损失并调整模型权重以更好地预测下一次。称之为自监督(而不是简单的监督)的原因是,不需要预先通过昂贵的过程收集标签,但它们已经包含在数据中。给定句子“我喜欢冰淇淋”,我们可以自动将其拆分为“我喜欢冰”作为输入, “奶油”作为标签,这不需要人工干预。尽管这不是模型本身,但它仍然由机器自动执行,因此人工智能在学习过程中自我监督的想法。
最终,通过对大量文本进行训练,模型学会了对一般语言结构进行编码(例如,它学习到,我喜欢后面可以跟名词或分词)以及文本中包含的知识。锯。例如,据了解, “乔·拜登是……”这句话后面经常跟着美国总统,因此代表了该知识。
其他人已经完成了这种预训练,您可以使用开箱即用的模型,例如 GPT。但是,为什么要训练类似的模型呢?如果您使用的数据具有类似于语言的属性,但它本身不是通用语言,那么从头开始训练模型就变得很有必要。乐谱就是一个例子,它的结构有点像语言。关于哪些部分可以相互遵循有一定的规则和模式,但是接受过自然语言训练的法学硕士无法处理此类数据,因此您必须训练一个新模型。然而,由于乐谱和自然语言之间有许多相似之处,法学硕士的架构可能是合适的。
微调

尽管预训练的 LLM 由于其编码的知识而能够执行各种数量的任务,但它有两个主要缺点,即其输出的结构以及缺乏未编码在数据中的知识首先。
如您所知,LLM 总是根据之前给定的标记序列来预测下一个标记。对于继续给定的故事可能没问题,但在其他情况下这不是您想要的。如果您需要不同的输出结构,有两种主要方法可以实现。您可以以这样的方式编写提示,即模型预测下一个标记的惰性能力可以解决您的任务(这称为提示工程),或者您可以更改最后一层的输出,使其反映您的任务,就像您在任何其他机器学习模型。考虑一个分类任务,其中有N个类。通过即时工程,您可以指示模型始终在给定输入后输出分类标签。通过微调,您可以将最后一层更改为具有N 个输出神经元,并从具有最高激活的神经元导出预测类别。
LLM的另一个限制在于其训练数据。由于数据源相当丰富,最著名的法学硕士编码了大量的常识。因此,他们可以告诉您有关美国总统、贝多芬的主要著作、量子物理学的基础知识以及西格蒙德·弗洛伊德的主要理论等信息。然而,有些领域是模型不了解的,如果您需要使用这些领域,微调可能与您相关。
微调的想法是采用已经预训练的模型并使用不同的数据继续训练,并在训练过程中仅更改最后一层的权重。这仅需要初始训练所需资源的一小部分,因此可以更快地执行。另一方面,模型在预训练期间学习的结构仍然被编码在第一层中并且可以被利用。假设您想向模型传授您最喜欢的但鲜为人知的奇幻小说,这些小说尚未成为训练数据的一部分。通过微调,您可以利用模型有关自然语言的知识来使其理解奇幻小说的新领域。
RLHF 微调

微调模型的一个特殊情况是根据人类反馈进行强化学习 (RLHF),这是 GPT 模型和 Chat-GPT 等聊天机器人之间的主要区别之一。通过这种微调,模型被训练为产生人类在与模型对话中最有用的输出。
主要思想如下:给定任意提示,为该提示生成模型的多个输出。人们根据他们认为这些输出的有用性或适当性对这些输出进行排名。给定四个样本 A、B、C 和 D,人们可能会认为 C 是最佳输出,B 稍差但等于 D,A 是该提示的最差输出。这将导致顺序 C > B = D > A。接下来,该数据用于训练奖励模型。这是一个全新的模型,它通过给予反映人类偏好的奖励来学习对法学硕士的输出进行评分。一旦奖励模型经过训练,它就可以替代该产品中的人类。现在,模型的输出由奖励模型进行评级,并且该奖励作为反馈提供给 LLM,然后进行调整以最大化奖励;与 GAN 的想法非常相似。
正如您所看到的,这种训练需要人工标记的数据,这需要相当多的努力。然而,所需的数据量是有限的,因为奖励模型的想法是从该数据中进行概括,以便一旦它了解了自己的部分,就可以自行对 llm 进行评分。RLHF 通常用于使 LLM 输出更像对话或避免不良行为,例如模型刻薄、侵入性或侮辱性。
Adapters
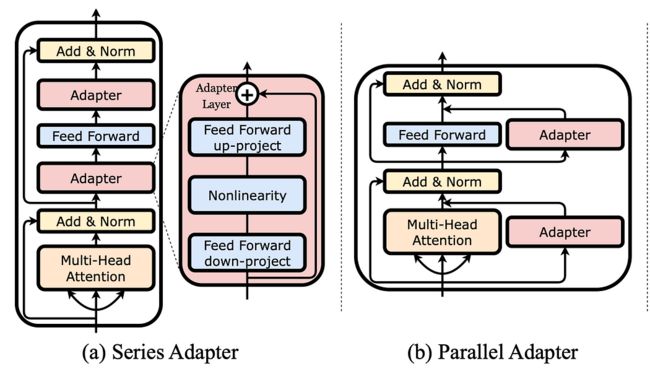
两种适配器可插入现有网络。图片取自https://arxiv.org/pdf/2304.01933.pdf。
在前面提到的微调中,我们在最后一层中调整了模型的一些参数,而前面层中的其他参数保持不变。不过,还有一种替代方案,即通过较少数量的训练所需参数来保证更高的效率,这称为dapters。
使用适配器意味着向已经训练的模型添加额外的层。在微调过程中,仅训练那些适配器,而模型的其余参数根本不改变。然而,这些层比模型附带的层小得多,这使得调整它们变得更容易。此外,它们可以插入到模型中的不同位置,而不仅仅是最后。在上图中您可以看到两个示例;一种是适配器以串行方式添加为一层,另一种是并行添加到现有层。
Prompting

您可能想知道提示是否算作训练模型的另一种方式。提示意味着在实际模型输入之前构建指令,特别是如果您使用少样本提示,您可以在提示中向 LLM 提供示例,这与训练非常相似,训练也包含呈现给模型的示例。模型。然而,提示不同于训练模型是有原因的。首先,从简单的定义来看,我们只在权重更新时才谈论训练,而在提示期间不会这样做。创建提示时,您不会更改任何模型,不会更改权重,不会生成新模型,也不会更改模型中编码的知识或表示。提示应该被视为指导法学硕士并告诉它你想从中得到什么的一种方式。以以下提示为例:
"""Classify a given text regarding its sentiment.
Text: I like ice cream.
Sentiment: negative
Text: I really hate the new AirPods.
Sentiment: positive
Text: Donald is the biggest jerk on earth. I hate him so much!
Sentiment: neutral
Text: {user_input}
Sentiment:"""我指示模型进行情感分类,并且您可能已经注意到,我给模型提供的示例都是错误的!如果使用此类数据训练模型,它会混淆积极、消极和中性的标签。如果我要求模型对我的示例中的“我喜欢冰淇淋”这句话进行分类,现在会发生什么?有趣的是,它将其分类为Positive,这与提示相反,但在语义层面上是正确的。这是因为提示没有训练模型,也没有改变其所学内容的表示。提示只是告知模型我期望的结构,即我期望情感标签(可以是Positive、Negative或Neutral)跟随在冒号之后。
Prompt tuning

虽然提示本身并不是对llm的训练,但是有一种称为提示调优(也称为软提示)的机制,它与提示有关,可以看作是一种训练。
在前面的示例中,我们将提示视为提供给模型的自然语言文本,以便告诉模型要做什么,并且该提示位于实际输入之前。也就是说,模型输入变为
提示调整的一大优点是,您可以为不同的任务训练多个提示,但仍然将它们用于相同的模型。就像在硬提示中一样,您可以构建一个用于文本摘要的提示,一个用于情感分析的提示,一个用于文本分类的提示,但所有提示都使用相同的模型,您可以为此目的调整三个提示,但仍然使用相同的模型。相反,如果您使用微调,您最终会得到三个模型,每个模型仅服务于其特定任务。
概括
刚才我们看到了各种不同的训练机制,所以最后我们做一个简短的总结。
- 预训练法学硕士意味着教它以自我监督的方式预测下一个标记。
- 微调是调整最后一层中预训练的 LLM 的权重,可用于使模型适应特定的上下文。
- RLHF 旨在调整模型的行为以符合人类的期望,并且需要额外的标记工作。
- 由于添加到预训练的 LLM 中的小层,适配器允许更有效的微调方式。
- 提示本身不被视为训练,因为它不会改变模型的内部表示。
- 提示调整是一种调整权重的技术,它会产生提示,但不会影响模型权重本身。
当然,还有更多的培训机制,而且每天都会有新的培训机制被发明出来。法学硕士可以做的不仅仅是预测文本,教他们这样做需要多种技能和技巧,其中一些我刚刚向大家介绍过。
进一步阅读
Instruct-GPT 是 RLHF 最著名的例子之一:
- Aligning language models to follow instructions
常见适配器形式的概述可以在 LLM-Adapters 项目中找到:
- GitHub - AGI-Edgerunners/LLM-Adapters: Code for our EMNLP 2023 Paper: "LLM-Adapters: An Adapter Family for Parameter-Efficient Fine-Tuning of Large Language Models"
可以在这里找到一些关于提示调整的很好的解释:
- https://huggingface.co/docs/peft/conceptual_guides/prompting
- https://ai.googleblog.com/2022/02/guiding-frozen-language-models-with.html