This week, we introduce the core idea of teaching a computer to learn concepts using data(用数据教电脑学习概念)—without being explicitly programmed(不显性的编程).
Linear regression(线性回归) predicts a real-valued output based on an input value. We discuss the application of linear regression to housing price prediction, present the notion of a cost function(代价函数), and introduce the gradient descent method(梯度下降方法) for learning.
Basic understanding of linear algebra(线性代数) is necessary for the rest of the course, especially as we begin to cover models with multiple variables(多变量回归问题).
课程信息
机器学习是一门研究在非特定编程条件下让计算机采取行动的学科。最近二十年,机器学习为我们带来了自动驾驶汽车、实用的语音识别、高效的网络搜索,让我们对人类基因的解读能力大大提高。当今机器学习技术已经非常普遍,您很可能在毫无察觉情况下每天使用几十次。许多研究者还认为机器学习是人工智能(AI)取得进展的最有效途径。在本课程中,您将学习最高效的机器学习技术,了解如何使用这些技术,并自己动手实践这些技术。更重要的是,您将不仅将学习理论知识,还将学习如何实践,如何快速使用强大的技术来解决新问题。最后,您将了解在硅谷企业如何在机器学习和AI领域进行创新。
本课程将广泛介绍机器学习、数据挖掘和统计模式识别(Pattern Recognition)。相关主题包括:
- (i) 监督式学习(参数和非参数算法、支持向量机、核函数和神经网络)。
- (ii) 无监督学习(集群、降维、推荐系统和深度学习)。
- (iii) 机器学习实例(偏见/方差理论;机器学习和AI领域的创新)。
课程将引用很多案例和应用,您还需要学习如何在不同领域应用学习算法,例如智能机器人(感知和控制)、文本理解(网络搜索和垃圾邮件过滤)、计算机视觉、医学信息学、音频、数据库挖掘等领域。
附注:什么是模式识别? 模式识别-百科
随着计算机技术的发展,人类有可能研究复杂的信息处理过程。信息处理过程的一个重要形式是生命体对环境及客体的识别。对人类来说,特别重要的是对光学信息(通过视觉器官来获得)和声学信息(通过听觉器官来获得)的识别。
授课大纲
第 1 周
Introduction 简介
Linear Regression with One Variable 单变量线性回归
Linear Algebra Review 线性代数复习
第 2 周
Linear Regression with Multiple Variables 多变量线性回归
Octave/Matlab Tutorial
第 3 周
Logistic Regression 逻辑回归
Regularization 正则化
第 4 周
Neural Networks: Representation 神经网络表示
第 5 周
Neural Networks: Learning 神经网络学习
第 6 周
Advice for Applying Machine Learning
Machine Learning System Design 机器学习系统设计
第 7 周
Support Vector Machines 支持向量机
第 8 周
Unsupervised Learning 无监督学习
Dimensionality Reduction 降维
第 9 周
Anomaly Detection 异常检测
Recommender Systems 推荐系统
第 10 周
Large Scale Machine Learning 大规模机器学习
第 11 周
Application Example: Photo OCR 应用实例
Introduction
Welcome
欢迎来到这门关于机器学习的免费网络课程
机器学习是近年来最激动人心的技术之一 在这门课中 你不仅可以了解机器学习的原理 更有机会进行实践操作 并且亲自运用所学的算法
在生活中 每天你都可能在不知不觉中使用了各种各样的机器学习算法 比如 当你每一次使用像诸如谷歌 (Google)或必应 (Bing) 的搜索引擎时 它们运作得如此之好的原因之一便是 由Google或微软实现的一种学习算法可以“学会”如何对网页进行排名 每当你使用脸书 (Facebook)或苹果 (Apple) 的照片处理应用时 它们都能自动识别出你朋友的照片 这也是机器学习的一种 每当你阅读电子邮件时 你的垃圾邮件过滤器帮你免受大量垃圾邮件的困扰 这也是通过一种学习算法实现的
还有一个让我兴奋的理由 是一个关于人工智能的梦想 有朝一日 我们能创造出像你我一样聪明的机器 尽管我们离这个目标仍有很长的距离 但许多的人工智能专家相信 实现这一目标最好的途径是通过学习算法 来模拟人类大脑的学习方式 关于这点 我也会在这门课程中有所提及
在这门课中你将会掌握机器学习的前沿原理 但是 仅仅了解其中的算法和数学是不够的 尤其是如果你并不知道如何将所学的理论知识用到你的实际问题上时 因此 我们也将花费大量时间来让大家进行编程练习 帮助你实现所学的算法 并体验到它们究竟是怎么运作的
话说 为什么机器学习在当今如此流行呢?
- 机器学习发源于人工智能领域 我们希望能够创造出具有智慧的机器 我们通过编程来让机器完成一些基础的工作 比如如何找到从A到B的最短路径
- 但在大多数情况下 我们并不知道如何显式地编写人工智能程序 来做一些更有趣的任务 比如网页搜索 标记照片和拦截垃圾邮件等 人们意识到唯一能够达成这些目标的方法 就是让机器自己学会如何去做 因而 机器学习已经发展成为计算机的一项新能力 并且与工业界和基础科学界有着紧密的联系
身处机器学习领域 我常常会在短短一周中与形形色色的人打交道 如直升机飞行员、生物学家、还有许多计算机系统专家 比如我在斯坦福的同事们 同时平均每周我还会数次收到来自硅谷的业界人士的email 咨询我是否有兴趣将机器学习算法应用到他们所遇到的实际问题中 以上的例子都彰显了机器学习所能处理的问题范围之广
在硅谷 机器学习引导着大量的课题 如自主机器人、计算生物学等 机器学习的实例还有很多
1.比如数据库挖掘 机器学习变得如此流行的原因之一 便是网络和自动化算法的爆炸性增长 这意味着我们掌握了比以往多得多的数据集 举例来说
- 当今有数不胜数的硅谷企业 在收集有关网络点击的数据 (Clickstream Data) 并试图在这些数据上运用机器学习的算法来更好的理解和服务用户 这在硅谷已经成为了一项巨大的产业
- 随着电子自动化的发展 我们现在拥有了电子医疗记录 如果我们能够将这些记录转变为医学知识 那我们就能对各种疾病了解的更深入
- 同时 计算生物学也在电子自动化的辅助下快速发展 生物学家收集了大量有关基因序列以及DNA序列的数据 通过对其应用机器学习的算法来帮助我们跟深入地理解人类基因组 及其对我们人类的意义
- 几乎工程界的所有领域 都在使用机器学习算法来分析日益增长的海量数据集
2.有些机器应用我们并不能够通过手工编程来实现
- 比如说 我个人对自动直升机有着许多年的研究 想要写出一个能让直升机自主飞行的程序几乎是不可能的任务 唯一可行的解决方案就是让一台计算机能够自主地学会如何让直升机飞行
- 再比如手写识别 如今将大量的邮件 按地址分类寄送到全美甚至全球的代价大大降低 其中重要的理由之一便是每当你写下这样一封信时 一个机器学习的算法 已经学会如何读懂你的笔迹并自动地 将你的信件发往它的目的地 所以邮寄跨越上万里的信件的费用也很低
- 你也许曾经接触过自然语言处理和计算机视觉 事实上 这些领域都是试图通过人工智能来 理解人类的语言和图像 如今大多数的自然语言处理和计算机视觉都是对机器学习的一种应用
3.机器学习算法也在用户自定制化程序(self-customizing program)中有着广泛的应用
每当你使用亚马逊 Netflix或iTunes Genius的服务时 都会收到它们为你量身推荐的电影或产品 这就是通过学习算法来实现的 可以相信 这些应用都有着上千万的用户 而针对这些海量的用户 编写千万个不同的程序显然是不可能的 唯一有效的解决方案就是开发出能够自我学习 定制出符合你喜好的并据此进行推荐的软件
4.最后 机器学习算法已经被应用于探究 人类的学习方式 并试图理解人类的大脑 我们也将会了解到研究者是如何运用机器学习的工具 来一步步实现人工智能的梦想
就在几个月前我的一位学生给我看了一篇文章 文中列举了当今12个最主要的IT技能 这些技术可以让信息技术行业的招聘官无法拒绝你 虽然这是一篇略显老旧的文章 但所有技能中最重要的便是机器学习 在斯坦福 向我咨询有没有即将毕业的研究机器学习学生的雇主 远远多于我们这儿每年毕业的机器学习的学生 因而我觉得对机器学习这一技能的需求仍有着巨大的缺口 而现在正是学习它的绝佳机会 我希望你们能在这门课中收获良多
在接下来的视频中 我将更正式地定义什么是机器学习 也会讨论机器学习主要面对的几类问题和相关算法 你也会学习一些主要的机器学习术语 并对不同的算法和其适用的场景 有初步的了解
Supervised Learning(监督式学习)
在本视频中,我将介绍一种也许是最常见的机器学习问题。 即监督学习。后面将给出监督学习更正式的定义, 现在最好以示例来说明什么是监督学习。 之后再给出正式的定义。
回归问题
假设你想预测房价(无比需要啊!), 之前,某学生已经从某地收集了数据集(不是中国的,囧) 其中一个数据集是这样的。 这是横坐标,即不同房子的面积,单位平方脚(^-^) 纵轴上是房价,单位 千美元。 根据给定数据,假设你朋友有栋房子,750平尺(70平米) 想知道这房子能卖多少,好卖掉。
那么,学习算法怎么帮你呢?学习算法可以: 绘出一条直线,让直线尽可能匹配到所有数据。 基于此,看上去,那个房子应该、可能、也许、大概 卖到15万美元(一平米两千刀!)。但这不是唯一的学习算法。 可能还有更好的。比如不用直线了, 可能平方函数会更好, 即二次多项式更符合数据集。如果你这样做, 预测结果就应该是20万刀(一平三千刀,涨价好快)。 后面我们会介绍到如何选择 是选择直线还是平方函数来拟合。 没有明确的选择,就不知哪个能给你的朋友 更好的卖房建议。只是这些每个都是很好的学习算法例子。 也是监督学习的例子。
术语:监督学习,意指给出一个算法, 需要部分数据集已经有正确答案。比如给定房价数据集, 对于里面每个数据,算法都知道对应的正确房价, 即这房子实际卖出的价格。算法的结果就是 算出更多的正确价格,比如那个新房子, 你朋友想卖的那个。
用更术语的方式来定义, 监督学习又叫回归问题,(应该是回归属于监督中的一种) 意指要预测一个连续值的输出,比如房价。 虽然从技术上,一般把房价记到美分单位。 所以实际还是个离散值,但通常把它看作实际数字, 是一个标量值,一个连续值的数,而术语回归, 意味着要预测这类连续值属性的种类。
分类问题
另一个监督学习的例子,我和一些朋友 之前研究的领域。让我们来看医学记录, 并预测胸部肿瘤是恶性良性。 如果某人发现有胸部肿瘤,恶性肿瘤有害又危险, 良性肿瘤则是少害。 显然人们很关注这个。让我们看一个收集好的数据集, 假设在数据集中,横轴表示肿瘤的大小, 纵轴我打算圈上0或1,是或否, 即肿瘤是恶性的还是良性的。
所以如图所示,可以看到这个大小的肿瘤块 是良性的,还有这些大小的都是良性的。 不幸地是也看到一些恶性肿瘤,比如这些大小的肿瘤。 所以,有5个良性块,在这一块, 还有5个恶性的,它们纵轴值为1. 现在假设某人杯具地得胸部肿瘤了, 大小大概是这么大。 对应的机器学习问题就是,你能否估算出一个概率, 即肿瘤为恶或为良的概率?
专业地说,这是个分类问题。 分类是要预测一个离散值输出。 这里是0或1,恶性或良性。事实证明, 在分类问题中,有时会有超过两个的值, 输出的值可能超过两种。举个具体例子, 胸部肿瘤可能有三种类型,所以要预测离散值0,1,2,3 0就是良性肿瘤,没有癌症。 1 表示1号癌症,假设总共有三种癌症。 2 是2号癌症,3 就是3号癌症。 这同样是个分类问题,因为它的输出的离散值集合 分别对应于无癌,1号,2号,3号癌症
我再露一小手,在分类问题中,还有另一种作图方式 来描述数据。我画你猜。要用到些许不同的符号集合 来描绘数据。如果肿瘤大小作为唯一属性, 被用于预测恶性良性,可以把数据作图成这样。 使用不同的符号来表示良性和 恶性,即阴性和阳性。所以,不再统一画叉叉了, 改用圈圈来代表良性肿瘤,就像这样。 仍沿用X(叉叉)代表恶性肿瘤。希望你能明白。 我所做的就是,把在上面的数据, 映射下来。再用不同的符号, 圈和叉来分别代表良性和恶性。
在上例中,只使用了一个特征属性,即肿瘤块大小, 来预测肿瘤是恶性良性。在其它机器学习问题里, 有着不只一个的特征和属性。
例子,现在不只是知道肿瘤大小, 病人年龄和肿瘤大小都知道了。这种情况下, 数据集如表图所示,有些病人,年龄、肿瘤已知, 不同的病人,会有一点不一样, 肿瘤恶性,则用叉来代表。所以,假设 有一朋友得了肿瘤。肿瘤大小和年龄 落在此处。那么依据这个给定的数据集,学习算法 所做的就是画一条直线,分开 恶性肿瘤和良性肿瘤,所以学习算法会 画条直线,像这样,把两类肿瘤分开。 然后你就能判断你朋友的肿瘤是...了 如果它在那边,学习算法就说 你朋友的肿瘤在良性一边,因此更可能 是良性的。好,本例中,总共有两个特征, 即病人年龄和肿瘤大小。在别的ML问题中, 经常会用到更多特征,我朋友研究这个问题时, 通常使用这些特征:比如块的厚度,即胸部肿瘤的厚度 肿瘤细胞大小和形状的一致性, 等等。
它表明, 最有趣的学习算法(本课中将学到) 能够处理,无穷多个特征。不是3到5个这么少。 在这张幻灯片中,我已经列举了总共5个不同的特征。 但对于一些学习问题, 真要用到的不只是三五个特征, 要用到无数多个特征,非常多的属性, 所以,你的学习算法要使用很多的属性 或特征、线索来进行预测。那么,你如何处理 无限多特征呢?甚至你如何存储无数的东西 进电脑里,又要避免内存不足?
事实上,等我们介绍一种叫支持向量机的算法时, 就知道存在一个简洁的数学方法,能让电脑处理无限多的特征。 想像下,我不是这边写两个特征, 右边写三个特征。而是,写一个无限长的特征表, 不停地写特征,似乎是个无限长的特征的表。 但是,我们也有能力设计一个算法来处理这个问题。
所以再从头复述一遍。本课中,我们介绍监督学习。 其基本思想是,监督学习中,对于数据集中的每个数据, 都有相应的正确答案,(训练集) 算法就是基于这些来做出预测。(就我理解,就是需要先输入正确的数据进行练习(模型拟合),然后输入新的数据进行预测。)
就像那个房价, 或肿瘤的性质。后面介绍了回归问题。 即通过回归来预测一个连续值输出。 我们还谈到了分类问题, 目标是预测离散值输出。
下面是个小测验题目: 假设你有家公司,希望研究相应的学习算法去 解决两个问题。第一个问题,你有一堆货物的清单。 假设一些货物有几千件可卖, 你想预测出,你能在未来三个月卖出多少货物。 第二个问题,你有很多用户, 你打算写程序来检查每个用户的帐目。 对每个用户的帐目, 判断这个帐目是否被黑过(hacked or compromised)。 请问,这两个问题是分类问题,还是回归问题? 当视频暂停时,请用你的鼠标进行选择, 四选一,选择你认为正确的答案。 好,希望你刚才答对了。问题一是个回归问题 因为如果我有几千件货物, 可能只好把它当作一个实际的值,一个连续的值。 也把卖出的数量当作连续值。 第二个问题,则是分类问题,因为可以把 我想预测的一个值设为0,来表示账目没有被hacked 另一个设为1,表示已经被hacked。 就像乳癌例子中,0表示良性,1表示恶性。 所以这个值为0或1,取决于是否被hacked, 有算法能预测出是这两个离散值中的哪个。 因为只有少量的离散值,所以这个就是个分类问题。
这就是监督学习,下个视频将会介绍 无监督学习,学习算法的另一主要类型。
Unsupervised Learning(无监督学习)
在这段视频中 我们要讲 第二种主要的机器学习问题 叫做无监督学习 在上一节视频中 我们已经讲过了监督学习
回想起上次的数据集 每个样本 都已经被标明为 正样本或者负样本 即良性或恶性肿瘤 因此 对于监督学习中的每一个样本 我们已经被清楚地告知了 什么是所谓的正确答案(数据已经被标记) 即它们是良性还是恶性
在无监督学习中 我们用的数据会和监督学习里的看起来有些不一样 在无监督学习中 没有属性或标签这一概念 也就是说所有的数据 都是一样的 没有区别 所以在无监督学习中 我们只有一个数据集 没人告诉我们该怎么做 我们也不知道 每个数据点究竟是什么意思 相反 它只告诉我们 现在有一个数据集 你能在其中找到某种结构吗?
聚类问题
对于给定的数据集 无监督学习算法可能判定 该数据集包含两个不同的聚类 你看 这是第一个聚类 然后这是另一个聚类 你猜对了 无监督学习算法 会把这些数据分成两个不同的聚类 所以这就是所谓的聚类算法
实际上它被用在许多地方 我们来举一个聚类算法的栗子
Google 新闻的例子 如果你还没见过这个页面的话 你可以到这个URL news.google.com 去看看 谷歌新闻每天都在干什么呢? 他们每天会去收集 成千上万的 网络上的新闻 然后将他们分组 组成一个个新闻专题 比如 让我们来看看这里 这里的URL链接 连接着不同的 有关BP油井事故的报道 所以 让我们点击 这些URL中的一个 恩 让我们点一个 然后我们会来到这样一个网页 这是一篇来自华尔街日报的 有关……你懂的 有关BP油井泄漏事故的报道 标题为《BP杀死了Macondo》 Macondo 是个地名 就是那个漏油事故的地方 如果你从这个组里点击一个不同的URL 那么你可能会得到不同的新闻 这里是一则CNN的新闻 是一个有关BP石油泄漏的视频 如果你再点击第三个链接 又会出现不同的新闻 这边是英国卫报的报道 也是关于BP石油泄漏 所以 谷歌新闻所做的就是 去搜索成千上万条新闻 然后自动的将他们聚合在一起 因此 有关同一主题的 新闻被显示在一起
实际上 聚类算法和无监督学习算法 也可以被用于许多其他的问题 这里我们举个它在基因组学中的应用 下面是一个关于基因芯片的例子 基本的思想是 给定一组不同的个体 对于每个个体 检测它们是否拥有某个特定的基因 也就是说,你要去分析有多少基因显现出来了 因此 这些颜色 红 绿 灰 等等 它们 展示了这些不同的个体 是否拥有一个特定基因 的不同程度 然后你能做的就是 运行一个聚类算法 把不同的个体归入不同的类 或归为不同类型的人 这就是无监督学习 我们没有提前告知这个算法 这些是第一类的人 这些是第二类的人 这些是第三类的人等等 相反我们只是告诉算法 你看 这儿有一堆数据 我不知道这个数据是什么东东 我不知道里面都有些什么类型 叫什么名字 我甚至不知道都有哪些类型 但是 请问你可以自动的找到这些数据中的类型吗? 然后自动的 按得到的类型把这些个体分类 虽然事先我并不知道哪些类型 因为对于这些数据样本来说 我们没有给算法一个 正确答案 所以 这就是无监督学习
无监督学习或聚类算法在其他领域也有着大量的应用
- 它被用来组织大型的计算机集群 我有一些朋友在管理 大型数据中心 也就是 大型计算机集群 并试图 找出哪些机器趋向于 协同工作 如果你把这些机器放在一起 你就可以让你的数据中心更高效地工作
- 第二种应用是用于社交网络的分析 所以 如果可以得知 哪些朋友你用email联系的最多 或者知道你的Facebook好友 或者你Google+里的朋友 知道了这些之后 我们是否可以自动识别 哪些是很要好的朋友组 哪些仅仅是互相认识的朋友组
- 还有在市场分割中的应用 许多公司拥有庞大的客户信息数据库 那么 给你一个 客户数据集 你能否 自动找出不同的市场分割 并自动将你的客户分到不同的 细分市场中 从而有助于我在 不同的细分市场中 进行更有效的销售 这也是无监督学习 我们现在有 这些客户数据 但我们预先并不知道 有哪些细分市场 而且 对于我们数据集的某个客户 我们也不能预先知道 谁属于细分市场一 谁又属于细分市场二等等 但我们必须让这个算法自己去从数据中发现这一切
- 最后 事实上无监督学习也被用于 天文数据分析 通过这些聚类算法 我们发现了许多 惊人的、有趣的 以及实用的 关于星系是如何诞生的理论 所有这些都是聚类算法的例子 而聚类只是无监督学习的一种
鸡尾酒宴问题
现在让我来告诉你另一种 我先来介绍一下鸡尾酒宴问题 恩 我想你参加过鸡尾酒会的 是吧? 嗯 想象一下 有一个宴会 有一屋子的人 大家都坐在一起 而且在同时说话 有许多声音混杂在一起 因为每个人都是在同一时间说话的 在这种情况下你很难听清楚你面前的人说的话 因此 比如有这样一个场景 宴会上只有两个人 两个人 同时说话 恩 这是个很小的鸡尾酒宴会
我们准备好了两个麦克风 把它们放在房间里 然后 因为这两个麦克风距离这两个人 的距离是不同的 每个麦克风都记录下了 来自两个人的声音的不同组合 也许A的声音 在第一个麦克风里的声音会响一点 也许B的声音 在第二个麦克风里会比较响一些 因为2个麦克风 的位置相对于 2个说话者的位置是不同的 但每个麦克风都会录到 来自两个说话者的重叠部分的声音 这里有一个 来自一个研究员录下的两个说话者的声音 让我先放给你听第一个 这是第一个麦克风录到的录音: 一 (UNO) 二 (DOS) 三 (TRES) 四 (CUATRO) 五 (CINCO) 六 (SEIS) 七 (SIETE) 八 (ocho) 九 (NUEVE) 十 (Y DIEZ) 好吧 这大概不是什么有趣的酒会…… ……在这个酒会上 有两个人 各自从1数到10 但用的是两种不同语言 你刚才听到的是 第一个麦克风的录音 这里是第二个的: 一 (UNO) 二 (DOS) 三 (TRES) 四 (CUATRO) 五 (CINCO) 六 (SEIS) 七 (SIETE) 八 (ocho) 九 (NUEVE) 十 (Y DIEZ)
所以 我们能做的就是把 这两个录音输入 一种无监督学习算法中 称为“鸡尾酒会算法” 让这个算法 帮你找出其中蕴含的分类 然后这个算法 就会去听这些 录音 并且你知道 这听起来像 两个音频录音 被叠加在一起 所以我们才能听到这样的效果 此外 这个算法 还会分离出 这两个被 叠加到一起的 音频源 事实上 这是我们的鸡尾酒会算法的第一个输出 一 二 三 四 五 六 七 八 九 十 所以我在一个录音中 分离出了英文声音 这是第二个输出 Uno dos tres quatro cinco seis siete ocho nueve y diez 听起来不错嘛 再举一个例子 这是另一个录音 也是在一个类似的场景下 这是第一个麦克风的录音: 一 二 三 四 五 六 七 八 九 十 OK 这个可怜的家伙从 鸡尾酒会回家了 他现在独自一人坐在屋里 对着录音机自言自语 这是第二个麦克风的录音 一 二 三 四 五 六 七 八 九 十 当你把这两个麦克风录音 送给与刚刚相同的算法处理 它所做的还是 告诉你 这听起来有 两种音频源 并且 算法说 这里是我找到的第一个音频源 一 二 三 四 五 六 七 八 九 十 恩 不是太完美 提取到了人声 但还有一点音乐没有剔除掉 这是算法的第二个输出 还好 在第二个输出中 它设法剔除掉了整个人声 只是清理了下音乐 剔除了从一到十的计数
所以 你可以看到 像这样的无监督学习算法 也许你想问 要实现这样的算法 很复杂吧? 看起来 为了 构建这个应用程序 做这个音频处理 似乎需要写好多代码啊 或者需要链接到 一堆处理音频的Java库 貌似需要一个 非常复杂的程序 分离出音频等
实际上 要实现你刚刚听到的效果 只需要一行代码就可以了 写在这里呢 当然 研究人员 花了很长时间才想出这行代码的 ^-^ 我不是说这是一个简单的问题
但事实上 如果你 使用正确的编程环境 许多学习 算法是用很短的代码写出来的 所以这也是为什么在 这门课中我们要 使用Octave的编程环境 Octave是一个免费的 开放源码的软件 使用Octave或Matlab这类的工具 许多学习算法 都可以用几行代码就可以实现 在后续课程中 我会教你如何使用Octave 你会学到 如何在Octave中实现这些算法 或者 如果你有Matlab 你可以用它 事实上 在硅谷 很多的机器学习算法 我们都是先用Octave 写一个程序原型 因为在Octave中实现这些 学习算法的速度快得让你无法想象 在这里 每一个函数 例如 SVD 意思是奇异值分解 但这其实是解线性方程 的一个惯例 它被内置在Octave软件中了 如果你试图 在C + +或Java中做这个 将需要写N多代码 并且还要连接复杂的C + +或Java库 所以 你可以在C++或 Java或Python中 实现这个算法 只是会 更加复杂而已
在教授机器学习 将近10年后 我得出的一个经验就是 如果你使用Octave的话 会学的更快 并且如果你用 Octave作为你的学习工具 和开发原型的工具 你的学习和开发过程 会变得更快 而事实上在硅谷 很多人会这样做 他们会先用Octave 来实现这样一个学习算法原型 只有在确定 这个算法可以工作后 才开始迁移到 C++ Java或其它编译环境 事实证明 这样做 实现的算法 比你一开始就用C++ 实现的算法要快多了 所以 我知道 作为一个老师 我不能老是念叨: “在这个问题上相信我“ 但对于 那些从来没有用过这种 类似Octave的编程环境的童鞋 我还是要请你 相信我这一次 我认为 你的时间 研发时间 是你最宝贵的资源之一 当见过很多的人这样做以后 我觉得如果你也这样做 作为一个机器学习的 研究者和开发者 你会更有效率 如果你学会先用Octave开发原型 而不是先用其他的编程语言来开发
最后总结一下 我们谈到了无监督学习 它是一种学习机制 你给算法大量的数据 要求它找出数据中蕴含的类型结构
以下的四个例子中 哪一个 您认为是 无监督学习算法 而不是监督学习问题 对于每一个选项 在左边的复选框 选中你认为 属于无监督学习的 选项 然后按一下右下角的按钮 提交你的答案 所以 当视频暂停时 请回答幻灯片上的这个问题 恩 没忘记垃圾邮件文件夹问题吧? 如果你已经标记过数据 那么就有垃圾邮件和 非垃圾邮件的区别 我们会将此视为一个监督学习问题 新闻故事的例子 正是我们在本课中讲到的 谷歌新闻的例子 我们介绍了你可以如何使用 聚类算法这些文章聚合在一起 所以这是无监督学习问题 市场细分的例子 我之前有说过 这也是一个无监督学习问题 因为我是要 拿到数据 然后要求 它自动发现细分市场 最后一个例子 糖尿病 这实际上就像我们 上节课讲到的乳腺癌的例子 只不过这里不是 好的或坏的癌细胞 良性或恶性肿瘤我们 现在是有糖尿病或 没有糖尿病 所以这是 有监督的学习问题 像处理那个乳腺癌的问题一样 我们会把它作为一个 有监督的学习问题来处理
好了 关于无监督学习问题 就讲这么多了 下一节课中我们 会涉及到更具体的学习算法 并开始讨论 这些算法是如何工作的 以及我们如何来实现它们。
Linear Regression with One Variable单变量线性回归
Model and Cost Function模型和代价函数
Model Representation模型表示
- 监督学习中回归和分类的区别
- 一些基本的符号
- 模型是什么?假设函数是什么?线性回归的假设函数怎么写?
我们的第一个学习算法是线性回归算法 在这段视频中 你会看到这个算法的概况 更重要的是你将会了解 监督学习过程完整的流程
让我们通过一个例子来开始 这个例子是预测住房价格的 我们要使用一个数据集 数据集包含俄勒冈州波特兰市的住房价格 在这里 我要根据不同房屋尺寸所售出的价格 画出我的数据集 比方说 我们来看这个数据集 你有一个朋友正想出售自己的房子 如果你朋友的房子是1250平方尺大小 你要告诉他们 这房子能卖多少钱 那么 你可以做的一件事就是 构建一个模型 也许是条直线 从这个数据模型上来看 也许你可以告诉你的朋友 他能以大约220000(美元)左右的价格 卖掉这个房子
那么这就是监督学习算法的一个例子 它被称作监督学习是因为对于每个数据来说 我们给出了 “正确的答案” 即告诉我们 根据我们的数据来说 房子实际的价格是多少
而且 更具体来说 这是一个回归问题 回归一词指的是我们根据之前的数据预测出一个准确的输出值 对于这个例子就是价格
同时 还有另一种最常见的监督学习方式 叫做分类问题 当我们想要预测离散的输出值 例如 如果我们正在寻找 癌症肿瘤并想要确定 肿瘤是良性的还是恶性的 这就是0/1离散输出的问题
更进一步来说 在监督学习中我们有一个数据集 这个数据集被称训练集 因此对于房价的例子 我们有一个训练集 包含不同的房屋价格 我们的任务就是从这个数据中学习预测房屋价格
现在我们给出这门课中经常使用的一些符号定义 我们要定义颇多符号 不过没关系 现在你记不住所有的符号也没关系 随着课程的进展 你会发现记住这些符号会很有用
(请牢记以下 公式 和 符号,不然后面的课程完全不知所云)
我将在整个课程中用小写的m 来表示训练样本的数目 因此 在这个数据集中 如果表中有47行 那么我们就有47组训练样本 m就等于47
- 让我用小写字母x来表示输入变量 往往也被称为特征量 这就是用x表示输入的特征
- 并且我们将用y来表示输出变量或者目标变量 也就是我的预测结果 那么这就是第二列
- 在这里 我要使用(x, y)来表示一个训练样本 所以 在这个表格中的单独的一行对应于一个训练样本
- 为了表示某个训练样本 我将使用x上标(i)与y上标(i)来表示 并且用这个表示第i个训练样本 所以这个上标 i 看这里 这不是求幂运算 这个(x(i), y(i)) 括号里的上标i 只是一个索引 表示我的训练集里的第i行 这里不是x的i和y的i次方 仅仅是指(x(i), y(i))是在此表中的第 i 行
m #训练集样本的数目 x #输入变量的特征值 y #输出变量或目标变量
(x, y) #一个训练样本
举个例子 x(1) 指的是 第一个训练集里值为2104的输入值 这个就是第一行里的x x(2) 等于1416吧? 这是第二个x y(1) 等于460 这是我第一个训练集样本的y值 这就是(1)所代表的含义 像之前一样 我会问你一个问题 需要几秒的时间 检查一下你的理解程度 在这个视频片段中 有时会有视频选择题弹出 当它弹出的时候 请使用鼠标来选择你认为正确的答案
这就是一个监督学习算法的工作方式
我们可以看到这里有我们的训练集里房屋价格 我们把它喂给我们的学习算法 这就是学习算法的工作了 然后输出一个函数 按照惯例 通常表示为小写h h代表hypothesis(假设), h表示一个函数 输入是房屋尺寸大小 就像你朋友想出售的房屋 因此 h 根据输入的 x 值来得出 y 值 y值对应房子的价格
因此 h是一个从x到y的函数映射 人们经常问我为什么这个函数被称作假设(hypothesis) 你们中有些人可能知道hypothesis的意思 从字典或者其它什么方式可以查到 其实在机器学习中 这是一个在早期被用于机器学习的名称 它有点绕口 对这类函数来说 这可能不是一个很恰当的名字 对表示从房屋的大小到价格的函数映射 我认为这个词"hypothesis" 可能不是最好的名称 但是这是人们在机器学习中使用的标准术语 所以不用太纠结人们为什么这么叫它
当设计学习算法的时候 我们接下来需要去思考的是 怎样得到这个假设h 对于这一点在接下来的几个视频中 我将选择最初的使用规则 h代表hypothesis 我们将会这么写 hθ(x)=θ0+θ1*x 为了方便 有时非书面形式也可以这么写 hθ(x) 我就写成h(x) 这是缩写方式 但一般来说我会保留这个下标θ 从这个图片中 所有这一切意味着我们要预测一个关于x的 线性函数 y 对吧? 所以这就是数据集和函数的作用 用来预测 这里是y关于x的线性函数 hθ(x)=θ0+θ1*x 那么为什么是一个线性函数呢? 有时候 我们会有更复杂的函数 也许是非线性函数 但是 由于线性方程是简单的形式 我们将先从线性方程的例子入手
hθ(x)=θ0+θ1*x
当然 最终我们将会建立更复杂的模型 以及更复杂的学习算法 (讲出了机器学习的核心思路)
好吧 让我们也给这模型 起一个名字 这个模型被称为线性回归(linear regression)模型 另外 这实际上是关于单个变量的线性回归 这个变量就是x 根据x来预测所有的价格函数 同时 对于这种模型有另外一个名称 称作单变量线性回归 单变量是对一个变量的一种 特别的表述方式
总而言之 这就是线性回归 在接下来的视频中 我们将开始讨论如何去实现这种模型
Cost Function代价函数
- 模型参数是什么?
- 如何引出的代价函数J(θ0,θ1)?得到最优的模型参数
- 什么是代价函数?代价函数作用?(策略,即如何选择假设空间中的函数)
在这段视频中我们将定义代价函数的概念 这有助于我们 弄清楚如何把最有可能的直线与我们的数据相拟合(如何选出唯一模型)
在线性回归中我们有一个像这样的训练集 记住 M代表了训练样本的数量 所以 比如 M = 47 而我们的假设函数 也就是用来进行预测的函数 是这样的线性函数形式
接下来我们会引入一些术语 这些θ0和θ1 这些θi我把它们称为模型参数 在这个视频中 我们要做的就是谈谈如何选择这两个参数值θ0和θ1 选择不同的参数θ0和θ1 我们会得到不同的假设 不同的假设函数 我知道你们中的有些人可能已经知道我在这张幻灯片上要讲的
θi #模型参数
但我们还是用这几个例子来复习回顾一下 如果θ0是1.5 θ1是0 那么假设函数会看起来是这样 是吧 因为你的假设函数是h(x)=1.5+0*x 是这样一个常数函数 恒等于1.5 如果θ0=0并且θ1=0.5 那么假设会看起来像这样 它会通过点(2,1) 这样你又得到了h(x) 或者hθ(x) 但是有时我们为了简洁会省略θ 因此 h(x)将等于0.5倍的x 就像这样 最后 如果θ0=1并且θ1=0.5 我们最后得到的假设会看起来像这样 让我们来看看 它应该通过点(2,2) 这是我的新的h(x)或者写作hθ(x) 对吧? 你还记得之前我们提到过hθ(x)的 但作为简写 我们通常只把它写作h(x)
在线性回归中 我们有一个训练集 可能就像我在这里绘制的 我们要做的就是 得出θ0 θ1这两个参数的值 来让假设函数表示的直线 尽量地与这些数据点很好的拟合 也许就像这里的这条线一样
那么我们如何得出θ0 θ1的值 来使它很好地拟合数据的呢?我们的想法是 我们要选择 能使h(x) 也就是 输入x时我们预测的值 最接近该样本对应的y值的参数θ0 θ1 所以 在我们的训练集中我们会得到一定数量的样本 我们知道x表示卖出哪所房子 并且知道这所房子的实际价格 所以 我们要尽量选择参数值 使得 在训练集中 给出训练集中的x值 我们能合理准确地预测y的值
让我们给出标准的定义 在线性回归中 我们要解决的是一个最小化问题 所以我要写出关于θ0 θ1的最小化 而且 我希望这个式子极其小 是吧 我想要h(x)和y之间的差异要小 我要做的事情是尽量减少假设的输出与房子真实价格 之间的差的平方 明白吗?
接下来我会详细的阐述 别忘了 我用符号( x(i),y(i) )代表第i个样本 所以我想要做的是对所有训练样本进行一个求和 对i=1到i=M的样本 将对假设进行预测得到的结果 此时的输入是第i号房子的面积 对吧 将第i号对应的预测结果 减去第i号房子的实际价格 所得的差的平方相加得到总和 而我希望尽量减小这个值 也就是预测值和实际值的差的平方误差和 或者说预测价格和 实际卖出价格的差的平方 我说了这里的m指的是训练集的样本容量 对吧 这个井号是训练样本“个数”的缩写 对吧 而为了让表达式的数学意义 变得容易理解一点 我们实际上考虑的是 这个数的1/m 因此我们要尝试尽量减少我们的平均误差 也就是尽量减少其1/2m(why?) 通常是这个数的一半 前面的这些只是为了使数学更直白一点 因此对这个求和值的二分之一求最小值 应该得出相同的θ0值和相同的θ1值来 请大家一定弄清楚这个道理 没问题吧?在这里hθ(x)的这种表达 这是我们的假设 它等于θ0加上θ1与x(i)的乘积 而这个表达 表示关于θ0和θ1的最小化过程 这意味着我们要找到θ0和θ1 的值来使这个表达式的值最小 这个表达式因θ0和θ1的变化而变化对吧?
因此 简单地说 我们正在把这个问题变成 找到能使 我的训练集中预测值和真实值的差的平方的和 的1/2M最小的θ0和θ1的值
公式

因此 这将是我的线性回归的整体目标函数 为了使它更明确一点 我们要改写这个函数 按照惯例 我要定义一个代价函数 正如屏幕中所示 这里的这个公式 我们想要做的就是关于θ0和θ1 对函数J(θ0,θ1)求最小值 这就是我的代价函数 代价函数也被称作平方误差函数 有时也被称为 平方误差代价函数 事实上 我们之所以要求出 误差的平方和 是因为误差平方代价函数 对于大多数问题 特别是回归问题 都是一个合理的选择
还有其他的代价函数也能很好地发挥作用 但是平方误差代价函数可能是解决回归问题最常用的手段了
在后续课程中 我们还会谈论其他的代价函数 但我们刚刚讲的选择是对于大多数线性回归问题非常合理的 好吧 所以这是代价函数 到目前为止 我们已经 介绍了代价函数的数学定义 也许这个函数J(θ0,θ1)有点抽象 可能你仍然不知道它的内涵 在接下来的几个视频里 我们要更进一步解释 代价函数J的工作原理 并尝试更直观地解释它在计算什么 以及我们使用它的目的
Cost Function - Intuition I 直观感受I
- 直观理解假设函数和代价函数的运作机理(简化的代价函数)
在上一个视频中 我们给了代价函数一个数学上的定义 在这个视频里 让我们通过一些例子来获取一些直观的感受 看看代价函数到底是在干什么
回顾一下 这是我们上次所讲过的内容 我们想找一条直线来拟合我们的数据 所以我们用 θ0 θ1 等参数 得到了这个假设 而且通过选择不同的参数 我们会得到不同的直线拟合 所以拟合出的数据就像这样 然后我们还有一个代价函数 这就是我们的优化目标
在这个视频里 为了更好地 将代价函数可视化 我将使用一个简化的假设函数 就是右边这个函数 然后我将会用这个简化的假设 也就是 θ1*x 我们可以将这个函数看成是 把 θ0 设为0 所以我只有一个参数 也就是 θ1 代价函数看起来与之前的很像 唯一的区别是现在 h(x) 等于 θ1*x 只有一个参数 θ1 所以我的 优化目标是将 J(θ1) 最小化 用图形来表示就是 如果 θ0 等于零 也就意味这我们选择的假设函数 会经过原点 也就是经过坐标 (0,0)
直观的理解假设函数与代价函数的运作机理
通过利用简化的假设得到的代价函数 我们可以试着更好地理解 代价函数这个概念 我们要理解的是这两个重要的函数
- 第一个是假设函数
- 第二个是代价函数
(随机选定一个参数,就可以计算出代价函数值,可以通过作图找到最小的代价函数值,此时的参数就是模型的最优参数)
(以后会通过梯度下降法来正式确定模型参数)
注意这个假设函数 h(x) 对于一个固定的 θ1 这是一个关于 x 的函数 所以这个假设函数就是一个关于 x 这个房子大小的函数 与此不同的是 代价函数 J 是一个关于参数 θ1 的函数 而 θ1 控制着这条直线的斜率
现在我们把这写函数都画出来 试着更好地理解它们 我们从假设函数开始 比如说这里是我的训练样本 它包含了三个点 (1,1) (2,2) 和 (3,3) 现在我们选择一个值 θ1 所以当 θ1 等于1 如果这是我选择的 θ1 那么我的假设函数看起来就会像是这条直线 我将要指出的是 当我描绘出我的假设函数 X轴 我的横轴被标定为X轴 X轴是表示房子大小的量 现在暂时把 θ1 定为1 我想要做的就是 算出在 θ1 等于 1 的时候 J(θ1) 等于多少 所以我们 按照这个思路来计算代价函数的大小 和之前一样
代价函数定义如下 是吧 对这个误差平方项进行求和 这就等于 这样一个形式 简化以后就等于 三个0的平方和 当然还是0 现在 在代价函数里 我们发现所有这些值都等于0 因为对于我所选定的这三个训练样本 ( 1 ,1 ) (2,2) 和 (3,3) 如果 θ1 等于 1 那么 h(x(i)) 就会正好等于 y(i) 让我把这个写得好一点 对吧 所以 h(x) - y 所有的这些值都会等于零 这也就是为什么 J(1) 等于零 所以 我们现在知道了 J(1) 是0 让我把这个画出来 我将要在屏幕右边画出我的代价函数 J 要注意的是 因为我的代价函数是关于参数 θ1 的函数 当我描绘我的代价函数时 X轴就是 θ1 现在我有 J(1) 等于零 让我们继续把函数画出来 结果我们会得到这样一个点 现在我们来看其它一些样本 θ1 可以被设定为 某个范围内各种可能的取值 所以 θ1 可以取负数 0 或者正数 所以如果 θ1 等于0.5会发生什么呢 继续把它画出来 现在要把 θ1 设为0.5 在这个条件下 我的假设函数看起来就是这样 这条线的斜率等于0.5 现在让我们计算 J(0.5) 所以这将会等于1除以2m 乘以那一块 其实我们不难发现后面的求和 就是这条线段的高度的平方 加上这条线段高度的平方 再加上这条线段高度的平方 三者求和 对吗? 就是 y(i) 与预测值 h(x(i)) 的差 对吗 所以第一个样本将会是0.5减去1的平方 因为我的假设函数预测的值是0.5 而实际值则是1 第二个样本 我得到的是1减去2的平方 因为我的假设函数预测的值是1 但是实际房价是2 最后 加上 1.5减去3的平方 那么这就等于1除以2乘以3 因为训练样本有三个点所以 m 等于3 对吧 然后乘以括号里的内容 简化后就是3.5 所以这就等于3.5除以6 也就约等于0.68 让我们把这个点画出来 不好意思 有一个计算错误 这实际上该是0.58 所以我们把点画出来 大约会是在这里 对吗 现在 让我们再多做一个点 让我们试试θ1等于0 J(0) 会等于多少呢 如果θ1等于0 那么 h(x) 就会等于一条水平的线 对了 就会像这样是水平的 所以 测出这些误差 我们将会得到 J(0) 等于 1除以 2m 乘以1的平方 加上2的平方 加上3的平方 也就是 1除以6乘以14 也就是2.3左右 所以让我们接着把这个点也画出来 所以这个点最后是2.3 当然我们可以接着设定 θ1 等于别的值 进行计算 你也可以把 θ1 设定成一个负数 所以如果 θ1 是负数 那么 h(x) 将会等于 打个比方说 -0.5 乘以x 然后 θ1 就是 -0.5 那么这将会 对应着一个斜率为-0.5的假设函数 而且你可以 继续计算这些误差 结果你会发现 对于0.5 结果会是非常大的误差 最后会得到一个较大的数值 类似于5.25 等等 对于不同的 θ1 你可以计算出这些对应的值 对吗 结果你会发现 你算出来的这些值 你得到一条这样的曲线 通过计算这些值 你可以慢慢地得到这条线 这就是 J(θ) 的样子了
我们来回顾一下 任何一个 θ1 的取值对应着一个不同的 假设函数 或者说对应着左边一条不同的拟合直线 对于任意的θ1 你可以算出一个不同的 J(θ1) 的取值 举个例子 你知道的 θ1 等于1时对应着穿过这些数据的这条直线 当 θ1 等于0.5 也就是这个玫红色的点 也许对应着这条线 然后 θ1 等于0 也就是蓝色的这个点 对应着 这条水平的线 对吧 所以对于任意一个 θ1 的取值 我们会得到 一个不同的 J(θ1) 而且我们可以利用这些来描出右边的这条曲线 现在你还记得 学习算法的优化目标 是我们想找到一个 θ1 的值 来将 J(θ1) 最小化 对吗 这是我们线性回归的目标函数 嗯 看这条曲线 让 J(θ1) 最小化的值 是 θ1 等于1 然后你看 这个确实就对应着最佳的通过了数据点的拟合直线 这条直线就是由 θ1=1 的设定而得到的 然后 对于这个特定的训练样本 我们最后能够完美地拟合 这就是为什么最小化 J(θ1) 对应着寻找一个最佳拟合直线的目标
总结一下 在这个视频里 我们看到了一些图形 来理解代价函数 要做到这个 我们简化了算法 让这个函数只有一个参数 θ1 也就是说我们把 θ0 设定为0
在下一个视频里 我们将回到原来的问题的公式 然后看一些 带有 θ0 和 θ1 的图形 也就是说不把 θ0 设置为0了 希望这会让你更好地理解在原来的线性回归公式里 代价函数 J 的意义
Cost Function - Intuition II 直观感受II
- 轮廓图是什么?
这节课中 我们将更深入地学习代价函数的作用 这段视频的内容假设你已经认识轮廓图 如果你对轮廓图不太熟悉的话 这段视频中的某些内容你可能会听不懂 但不要紧 如果你跳过这段视频的话 也没什么关系 不听这节课对后续课程理解影响不大
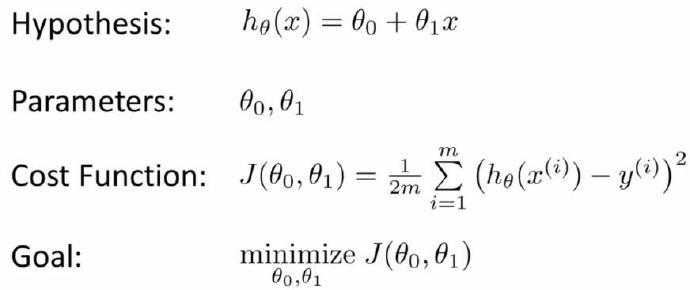
和之前一样 这是我们的几个重要公式 包括了
- 假设h
- 参数θ
- 代价函数J
- 优化目标
跟前一节视频不同的是 我还是把θ写成θ0、θ1的形式(两个自变量,一个因变量,图形必然是三维的) 便于这里我们要对代价函数进行的可视化 和上次一样 首先来理解假设h和代价函数J 这是房价数据组成的训练集数据
让我们来构建某种假设 就像这条线一样 很显然这不是一个很好的假设 但不管怎样 如果我假设θ0等于50 θ1等于0.06的话 那么我将得到这样一个假设函数 对应于这条直线 给出θ0和θ1的值 我们要在右边画出代价函数的图像 上一次 我们是只有一个θ1 也就是说 画出的代价函数是关于θ1的函数 但现在我们有两个参数 θ0和θ1 因此图像就会复杂一些了 当只有一个参数θ1的时候 我们画出来是这样一个弓形函数 而现在我们有了两个参数 那么代价函数 仍然呈现类似的某种弓形 实际上这取决于训练样本 你可能会得到这样的图形 因此这是一个三维曲面图 两个轴分别表示θ0和θ1 随着你改变θ0和θ1的大小 你便会得到不同的代价函数 J(θ0,θ1) 对于某个特定的点 (θ0,θ1) 这个曲面的高度 也就是竖直方向的高度 就表示代价函数 J(θ0,θ1) 的值 不难发现这是一个弓形曲面

我们来看看三维图 这是这个曲面的三维图 水平轴是θ0、θ1 竖直方向表示 J(θ0,θ1) 旋转一下这个图 你就更能理解这个弓形曲面所表示的代价函数了
在这段视频的后半部分 为了描述方便 我将不再像这样给你用三维曲面图的方式解释代价函数J 而还是用轮廓图来表示 contour plot 或 contour figure 意思一样 右边就是一个轮廓图 两个轴分别表示 θ0 和 θ1 而这些一圈一圈的椭圆形 每一个圈就表示 J(θ0,θ1) 相同的所有点的集合 具体举例来说 我们选三个点出来 这三个桃红色的点 都表示相同的 J(θ0,θ1) 的值 对吧 横纵坐标分别是θ0 θ1 这三个点的 J(θ0,θ1) 值是相同的 如果你之前没怎么接触轮廓图的话 你就这么想 你就想象一个弓形的函数从屏幕里冒出来 因此最小值 也就是这个弓形的最低点就是这个点 对吧 也就是这一系列同心椭圆的中心点 想象一下这个弓形从屏幕里冒出来
所以这些椭圆形 都从我的屏幕上冒出相同的高度 弓形的最小值点是这个位置 因此轮廓图是一种很方便的方法 能够直观地观察 代价函数J

接下来让我们看几个例子 在这里有一点 这个点表示θ0等于800 θ1大概等于-0.15 那么这个红色的点 代表了某个 (θ0,θ1) 组成的数值组 而这个点也对应于左边这样一条线 对吧 θ0等于800 也就是跟纵轴相交于大约800 斜率大概是-0.15 当然 这条线并不能很好地拟合数据 对吧 以这组 θ0 θ1 为参数的这个假设 h(x) 并不是数据的较好拟合 并且你也发现了 这个代价值 就是这里的这个值 距离最小值点还很远 也就是说这个代价值还是算比较大的 因此不能很好拟合数据
让我们再来看几个例子 这是另一个假设 你不难发现 这依然不是一个好的拟合 但比刚才稍微好一点 这是我的 θ0 θ1 点 这是 θ0 的值 大约为360 θ1 的值为0 我们把它写下来 θ0=360 θ1=0 因此这组θ值对应的假设是 这条水平的直线 也就是h(x) = 360 + 0 × x 这就是假设 这个假设同样也有某个代价值 而这个代价值就对应于这个代价函数在这一点的高度 让我们再来看一些例子 这是另一个例子 这个点这组 θ0 和 θ1 对应这样一条假设h(x) 同样地 还是对数据拟合不好 离最小值更远了
最后一个例子 这个点其实不是最小值 但已经非常靠近最小值点了 这个点对数据的拟合就很不错 它对应这样两个θ0 和 θ1 的值 同时也对应这样一个 h(x) 这个点虽然不在最小值点 但非常接近了 因此误差平方和 或者说 训练样本和假设的距离的平方和 这个距离值的平方和 非常接近于最小值 尽管它还不是最小值 好的 通过这些图形 我希望你能更好地 理解这些代价函数 J 所表达的值 它们是什么样的 它们对应的假设是什么样的 以及什么样的假设对应的点 更接近于代价函数J的最小值
当然 我们真正需要的是一种有效的算法 能够自动地找出这些使代价函数J取最小值的参数θ0和θ1(就是后面的梯度下降法) 对吧 我想我们也不希望编个程序 把这些点画出来 然后人工的方法来读出这些点的数值 这很明显不是一个好办法 事实上 我们后面就会学到 我们会遇到更复杂、更高维度、更多参数的情况 这在我们在后面的视频中很快就会遇到 而这些情况是很难画出图的 因此更无法将其可视化(维数高于3就无法可视化) 因此我们真正需要的 是编写程序来找出这些最小化代价函数的θ0和θ1的值
在下一节视频中 我们将介绍一种算法 能够自动地找出能使代价函数 J 最小化的参数θ0和θ1的值
我的总结:
方法=模型+策略+算法(来自李航的统计学习方法)(前面讲了模型和策略,下面就要开始讲算法)
这里,我们的模型是单变量线性回归模型,为了引入学习算法,我们学习了代价函数,学习算法的目标就是找出最优的参数,使得代价函数最小化。下面,就是我们的学习算法:梯度下降算法。
Parameter Learning参数学习
Gradient Descent梯度下降法
- 算法层次
- 如何将代价函数J最小化?
- 梯度下降法的核心思想?设置初始值,同步改变参数使得代价函数减小,直至找到局部最优解
我们已经定义了代价函数J(就是差的平方和)(要达到看一眼就能立马想到并写出公式的程度) 而在这段视频中 我想向你们介绍梯度下降这种算法 (其实也很简单:连续改变 和 学习速率 * 偏微分斜率)
这种算法可以将代价函数J最小化 梯度下降是很常用的算法 它不仅被用在线性回归上 它实际上被广泛的应用于机器学习领域中的众多领域 在后面课程中 为了解决其他线性回归问题 我们也将使用梯度下降法 最小化其他函数 而不仅仅是只用在本节课的代价函数J
因此在这个视频中 我将讲解用梯度下降算法最小化函数 J 在后面的视频中 我们还会将此算法应用于具体的 代价函数J中来解决线性回归问题

下面是问题概述 在这里 我们有一个函数J(θ0, θ1) (来源的模型可能有很多)也许这是一个线性回归的代价函数 也许是一些其他函数 要使其最小化 我们需要用一个算法 来最小化函数J(θ0, θ1) 就像刚才说的 事实证明 梯度下降算法可应用于 多种多样的函数求解 所以想象一下如果你有一个函数 J(θ0, θ1, θ2, ...,θn ) (可以推广到更多)你希望可以通过最小化 θ0到θn 来最小化此代价函数J(θ0 到θn) 用n个θ是为了证明梯度下降算法可以解决更一般的问题 但为了简洁起见 为了简化符号 在接下来的视频中 我只用两个参数
下面就是关于梯度下降的构想
我们要做的是 我们要开始对θ0和θ1 进行一些初步猜测 它们到底是什么其实并不重要 但通常的选择是将 θ0设为0 将θ1也设为0 将它们都初始化为0 我们在梯度下降算法中要做的 就是不停地一点点地改变 θ0和θ1 试图通过这种改变使得J(θ0, θ1)变小 直到我们找到 J 的最小值 或许是局部最小值

让我们通过一些图片来看看梯度下降法是如何工作的 我在试图让这个函数值最小 注意坐标轴 θ0和θ1在水平轴上 而函数 J在垂直坐标轴上 图形表面高度则是 J的值 我们希望最小化这个函数 所以我们从 θ0和θ1的某个值出发 所以想象一下 对 θ0和θ1赋以某个初值 也就是对应于从这个函数表面上的某个起始点出发 对吧 所以不管 θ0和θ1的取值是多少 我将它们初始化为0 但有时你也可把它初始化为其他值
现在我希望大家把这个图像想象为一座山 想像类似这样的景色 公园中有两座山 想象一下你正站立在山的这一点上 站立在你想象的公园这座红色山上 在梯度下降算法中 我们要做的就是旋转360度 看看我们的周围 并问自己 我要在某个方向上 用小碎步尽快下山 如果我想要下山 如果我想尽快走下山 这些小碎步需要朝什么方向? 如果我们站在山坡上的这一点 你看一下周围 你会发现最佳的下山方向 大约是那个方向 好的 现在你在山上的新起点上 你再看看周围 然后再一次想想 我应该从什么方向迈着小碎步下山? 然后你按照自己的判断又迈出一步 往那个方向走了一步 然后重复上面的步骤 从这个新的点 你环顾四周 并决定从什么方向将会最快下山 然后又迈进了一小步 又是一小步 并依此类推 直到你接近这里 直到局部最低点的位置
此外 这种下降有一个有趣的特点 第一次我们是从这个点开始进行梯度下降算法的 是吧 在这一点上从这里开始 现在想象一下 我们在刚才的右边一些的位置 对梯度下降进行初始化 想象我们在右边高一些的这个点 开始使用梯度下降 如果你重复上述步骤 停留在该点 并环顾四周 往下降最快的方向迈出一小步 然后环顾四周 又迈出一步 然后如此往复 如果你从右边不远处开始 梯度下降算法将会带你来到 这个右边的第二个局部最优处 如果从刚才的第一个点出发 你会得到这个局部最优解 但如果你的起始点偏移了一些 起始点的位置略有不同 你会得到一个 非常不同的局部最优解 这就是梯度下降算法的一个特点 我们会在之后继续探讨这个问题 好的 这是我们从图中得到的直观感受

看看这个图 这是梯度下降算法的定义 我们将会反复做这些 直到收敛 我们要更新参数 θj 方法是 用 θj 减去 α乘以这一部分
:= #表示赋值
让我们来看看 这个公式有很多细节问题 我来详细讲解一下 首先 注意这个符号:= 我们使用 := 表示赋值 这是一个赋值运算符 具体地说 如果我写 a:= b 在计算机专业内 这意味着不管 a的值是什么 取 b的值 并将其赋给a 这意味着我们让 a等于b的值 这就是赋值 我也可以做 a:= a+1 这意味着 取出a值 并将其增加1 与此不同的是 如果我使用等号 = 并且写出a=b 那么这是一个判断为真的声明 如果我写 a=b 就是在断言 a的值是等于 b的值的 在左边这里 这是计算机运算 将一个值赋给 a 而在右边这里 这是声明 声明 a的值 与b的值相同 因此 我可以写 a:=a+1 这意味着 将 a的值再加上1 但我不会写 a=a+1 因为这本来就是错误的 a 和 a+1 永远不会是同一个值 这是这个定义的第一个部分
这里的α 是一个数字 被称为学习速率 什么是α呢? 在梯度下降算法中 它控制了 我们下山时会迈出多大的步子 因此如果 α值很大 那么相应的梯度下降过程中 我们会试图用大步子下山 如果α值很小 那么我们会迈着很小的小碎步下山 关于如何设置 α的值等内容 在之后的课程中 我会回到这里并且详细说明
最后 是公式的这一部分 这是一个微分项 我现在不想谈论它 但我会推导出这个微分项 并告诉你到底这要如何计算 你们中有人大概比较熟悉微积分 但即使你不熟悉微积分 也不用担心 我会告诉你 对这一项 你最后需要做什么 现在 在梯度下降算法中 还有一个更微妙的问题 在梯度下降中 我们要更新 θ0和θ1 当 j=0 和 j=1 时 会产生更新 所以你将更新 J θ0还有θ1
实现梯度下降算法的微妙之处是 在这个表达式中 如果你要更新这个等式 你需要同时更新 θ0和θ1 我的意思是在这个等式中 我们要这样更新 θ0:=θ0 - 一些东西 并更新 θ1:=θ1 - 一些东西 实现方法是 你应该计算公式右边的部分 通过那一部分计算出θ0和θ1的值 然后同时更新 θ0和θ1 让我进一步阐述这个过程 在梯度下降算法中 这是正确实现同时更新的方法 我要设 temp0等于这些 设temp1等于那些 所以首先计算出公式右边这一部分 然后将计算出的结果 一起存入 temp0和 temp1 之中 然后同时更新 θ0和θ1(一起更新) 因为这才是正确的实现方法
与此相反 下面是不正确的实现方法 因为它没有做到同步更新 在这种不正确的实现方法中 我们计算 temp0 然后我们更新θ0 然后我们计算 temp1 然后我们将 temp1 赋给θ1 右边的方法和左边的区别是 让我们看这里 就是这一步 如果这个时候你已经更新了θ0 那么你会使用 θ0的新的值来计算这个微分项 所以由于你已经在这个公式中使用了新的 θ0的值 那么这会产生一个与左边不同的 temp1的值 所以右边并不是正确地实现梯度下降的做法 我不打算解释为什么你需要同时更新
同时更新是梯度下降中的一种常用方法 我们之后会讲到 实际上同步更新是更自然的实现方法 当人们谈到梯度下降时 他们的意思就是同步更新 如果用非同步更新去实现算法 代码可能也会正确工作 但是右边的方法并不是人们所指的那个梯度下降算法 而是具有不同性质的其他算法 由于各种原因 这其中会表现出微小的差别 你应该做的是 在梯度下降中真正实现同时更新 这些就是梯度下降算法的梗概
在接下来的视频中 我们要进入这个微分项的细节之中 我已经写了出来但没有真正定义 如果你已经修过微积分课程 如果你熟悉偏导数和导数 这其实就是这个微分项 如果你不熟悉微积分 不用担心 即使你之前没有看过微积分 或者没有接触过偏导数
在接下来的视频中 你会得到一切你需要知道的 如何计算这个微分项的知识 下一个视频中 希望我们能够给出 实现梯度下降算法的所有知识
Gradient Descent Intuition 梯度下降法直观感受
- 直观理解梯度下降算法
- 学习速率
- 偏导数项
在之前的视频中 我们给出了一个数学上关于梯度下降的定义 本次视频我们更深入研究一下 更直观地感受一下这个 算法是做什么的 以及梯度下降算法的更新过程有什么意义
这是我们上次视频中看到的梯度下降算法 提醒一下 这个参数 α 术语称为学习速率 它控制我们以多大的幅度更新这个参数θj. 第二部分是导数项 而我在这个视频中要做的就是 给你一个更直观的认识 这两部分有什么用 以及 为什么当把 这两部分放一起时 整个更新过程是有意义的
为了更好地让你明白 我要做是用一个稍微简单的例子 比如我们想最小化的那个 函数只有一个参数的情形 所以 假如我们有一个代价函数J 只有一个参数 θ1 就像我们前几次视频中讲的 θ1是一个实数 对吧?那么我们可以画出一维的曲线 看起来很简单 让我们试着去理解 为什么梯度下降法 会在这个函数上起作用
所以 假如这是我的函数 关于θ1的函数J θ1是一个实数 对吧? 现在我们已经对这个点上用于梯度下降法的θ1 进行了初始化 想象一下在我的函数图像上 从那个点出发 那么梯度下降 要做的事情是不断更新 θ1等于θ1减α倍的 d/dθ1J(θ1)这个项 对吧?
哦 顺便插一句 你知道 这个微分项是吧?可能你想问为什么我改变了符号 之前用的是偏导数的符号 如果你不知道偏导数的符号 和d/dθ之间的区别是什么 不用担心 从技术上讲 在数学中 我们称这是一个偏导数 这是一个导数 这取决于函数J的参数数量 但是这是一个 数学上的区别 就本课的目标而言 可以默认为 这些偏导数符号 和d/dθ1是完全一样的东西 不用担心 是否存在任何差异 我会尽量使用数学上的 精确的符号 但就我们的目的而言 这些符号是没有区别的 好的 那么我们来看这个方程 我们要计算 这个导数 我不确定之前你是否在微积分中学过导数 但对于这个问题 求导的目的 基本上可以说 取这一点的切线 就是这样一条红色的直线 刚好与函数相切于这一点 让我们看看这条红色直线的斜率 其实这就是导数 也就是说 直线的斜率 也就是这条 刚好与函数曲线相切的这条直线 这条直线的斜率正好是 这个高度除以这个水平长度 现在 这条线有 一个正斜率 也就是说它有正导数 因此 我得到的新的θ θ1更新后等于θ1减去一个正数乘以α. α 也就是学习速率也是一个正数 所以 我要使θ1减去一个东西 所以相当于我将θ1向左移 使θ1变小了 我们可以看到 这么做是对的 因为实际上我往这个方向移动 确实让我更接近那边的最低点 所以 梯度下降到目前为止似乎 是在做正确的事
让我们来看看另一个例子 让我们用同样的函数J 同样再画出函数J(θ1)的图像 而这次 我们把参数初始化到左边这点 所以θ1在这里 同样把这点对应到曲线上 现在 导数项d/dθ1 J(θ1) 在这点上计算时 看上去会是这样 这条线的斜率 这个导数是这条线的斜率 但是这条线向下倾斜 所以这条线具有负斜率 对吧? 或者说 这个函数有负导数 也就意味着在那一点上有负斜率 因此 这个导数项小于等于零 所以 当我更新θ时 θ被更新为θ减去α乘以一个负数 因此我是在用 θ1减去一个负数 这意味着我实际上是在增加θ1 对不对?因为这是减去一个负数 意味着给θ加上一个数 这就意味着最后我实际上增加了θ的值 因此 我们将 从这里开始 增加θ 似乎这也是我希望得到的 也就是 让我更接近最小值了 所以 我希望这样很直观地给你解释了 导数项的意义

让我们接下来再看一看学习速率α 我们来研究一下它有什么用 这就是我梯度下降法的 更新规则 就是这个等式 让我们来看看如果α 太小或 α 太大 会出现什么情况
这第一个例子 α太小会发生什么呢 这是我的函数J(θ) 就从这里开始 如果α太小了 那么我要做的是要去 用一个比较小的数乘以更新的值 所以最终 它就像一个小宝宝的步伐 这是一步 然后从这个新的起点开始 迈出另一步 但是由于α 太小 因此只能迈出另一个 小碎步 所以如果我的学习速率太小 结果就是 只能这样像小宝宝一样一点点地挪动 去努力接近最低点 这样就需要很多步才能到达最低点 所以如果α 太小的话 可能会很慢 因为它会一点点挪动 它会需要 很多步才能到达全局最低点
那么如果α 太大又会怎样呢 这是我的函数J(θ) 如果α 太大 那么梯度下降法可能会越过最低点 甚至可能无法收敛 我的意思是 比如我们从这个点开始 实际上这个点已经接近最低点 因此导数指向右侧 但如果α 太大的话 我会迈出很大一步 也许像这样巨大的一步 对吧?所以我最终迈出了一大步 现在 我的代价函数变得更糟 因为离这个最低点越来越远 现在我的导数指向左侧 实际上在减小θ 但是你看 如果我的学习速率过大 我会移动一大步 从这点一下子又到那点了 对吗?如果我的学习率太大 下一次迭代 又移动了一大步 越过一次 又越过一次 一次次越过最低点 直到你发现 实际上 离最低点越来越远 所以 如果α太大 它会导致无法收敛 甚至发散
现在 我还有一个问题 这问题挺狡猾的 当我第一次学习这个地方时 我花了很长一段时间才理解这个问题 如果我们预先把θ1 放在一个局部的最低点 你认为下一步梯度下降法会怎样工作? 所以假设你将θ1初始化在局部最低点 假设这是你的θ1的初始值 在这儿 它已经在一个局部的 最优处或局部最低点 结果是局部最优点的导数 将等于零 因为它是那条切线的斜率 而这条线的斜率将等于零 因此 此导数项等于0 因此 在你的梯度下降更新过程中 你有一个θ1 然后用θ1 减α 乘以0来更新θ1 所以这意味着什么 这意味着你已经在局部最优点 它使得θ1不再改变 也就是新的θ1等于原来的θ1 因此 如果你的参数已经处于 局部最低点 那么梯度下降法更新其实什么都没做 它不会改变参数的值 这也正是你想要的 因为它使你的解始终保持在 局部最优点 这也解释了为什么即使学习速率α 保持不变时 梯度下降也可以收敛到局部最低点 我想说的是这个意思
我们来看一个例子 这是代价函数J(θ) 我想找到它的最小值 首先初始化我的梯度下降算法 在那个品红色的点初始化 如果我更新一步梯度下降 也许它会带我到这个点 因为这个点的导数是相当陡的 现在 在这个绿色的点 如果我再更新一步 你会发现我的导数 也即斜率 是没那么陡的 相比于在品红点 对吧?因为随着我接近最低点 我的导数越来越接近零 所以 梯度下降一步后 新的导数会变小一点点 然后我想再梯度下降一步 在这个绿点我自然会用一个稍微 跟刚才在那个品红点时比 再小一点的一步 现在到了新的点 红色点 更接近全局最低点了 因此这点的导数会比在绿点时更小 所以 我再进行一步梯度下降时 我的导数项是更小的 θ1更新的幅度就会更小 所以你会移动更小的一步 像这样 随着梯度下降法的运行 你移动的幅度会自动变得越来越小 直到最终移动幅度非常小 你会发现 已经收敛到局部极小值
所以回顾一下 在梯度下降法中 当我们接近局部最低点时 梯度下降法会自动采取 更小的幅度 这是因为当我们接近局部最低点时 很显然在局部最低时导数等于零 所以当我们 接近局部最低时 导数值会自动变得越来越小 所以梯度下降将自动采取较小的幅度 这就是梯度下降的做法 所以实际上没有必要再另外减小α 这就是梯度下降算法 你可以用它来最小化 最小化任何代价函数J 不只是线性回归中的代价函数J
在接下来的视频中 我们要用代价函数J 回到它的本质 线性回归中的代价函数 也就是我们前面得出的平方误差函数 结合梯度下降法 以及平方代价函数 我们会得出第一个机器学习算法 即线性回归算法
Gradient Descent For Linear Regression 线性回归的梯度下降模型
- 专属于线性回归的梯度下降函数
在以前的视频中我们谈到 关于梯度下降算法 梯度下降是很常用的算法 它不仅被用在线性回归上 和线性回归模型、平方误差代价函数
在这段视频中 我们要 将梯度下降 和代价函数结合 在后面的视频中 我们将用到此算法 并将其应用于 具体的拟合直线的线性回归算法里

这就是 我们在之前的课程里所做的工作 这是梯度下降法(连续赋值 学习速率 偏微分) 这个算法你应该很熟悉 这是线性回归模型(最简单的函数) 还有线性假设和平方误差代价函数(差的平方之和)
我们将要做的就是 用梯度下降的方法 来最小化平方误差代价函数 为了 使梯度下降
具体计算线性回归模型下的偏导数项
为了 写这段代码 我们需要的关键项 是这里这个微分项 (需要代入才能求解)
所以.我们需要弄清楚 这个偏导数项是什么 并结合这里的 代价函数J 的定义 就是这样 一个求和项 代价函数就是 这个误差平方项 我这样做 只是 把定义好的代价函数 插入了这个微分式
再简化一下 这等于是 这一个求和项 θ0 + θ1x(1) - y(i) θ0 + θ1x(1) - y(i) 这一项其实就是 我的假设的定义 然后把这一项放进去 实际上我们需要 弄清楚这两个 偏导数项是什么 这两项分别是 j=0 和j=1的情况 因此我们要弄清楚 θ0 和 θ1 对应的 偏导数项是什么 我只把答案写出来 事实上 第一项可简化为 1 / m 乘以求和式 对所有训练样本求和 求和项是 h(x(i))-y(i) 而这一项 对θ(1)的微分项 得到的是这样一项 对吧 计算出这些 偏导数项 从这个等式 到下面的等式 计算这些偏导数项需要一些多元微积分 如果你掌握了微积分 你可以随便自己推导这些 然后你检查你的微分 你实际上会得到我给出的答案 但如果你 不太熟悉微积分 别担心 你可以直接用这些 已经算出来的结果 你不需要掌握微积分 或者别的东西 来完成作业 你只需要会用梯度下降就可以

(牢记偏微分的求导结果,其实很简单,平方消失了,2没了,θ1多了x(i))
在定义这些以后 在我们算出 这些微分项以后 这些微分项 实际上就是代价函数J的斜率 现在可以将它们放回 我们的梯度下降算法 所以这就是专用于 线性回归的梯度下降 反复执行括号中的式子直到收敛 θ0和θ1不断被更新 都是加上一个-α/m 乘上后面的求和项 所以这里这一项 所以这就是我们的线性回归算法 这里的第一项 当然 这一项就是关于θ0的偏导数 在上一张幻灯片中推出的 而第二项 这一项是刚刚的推导出的 关于θ1的 偏导数项 提醒一下 执行梯度下降时 有一个细节要注意 就是必须要 同时更新θ0和θ1
(要会自动脑补梯度下降法工作机理:一个二维的山地图、一个拟合图和轮廓图)
所以 让我们来看看梯度下降是如何工作的 我们用梯度下降解决问题的 一个原因是 它更容易得到局部最优值 当我第一次解释梯度下降时 我展示过这幅图 在表面上 不断下降 并且我们知道了 根据你的初始化 你会得到不同的局部最优解 你知道.你可以结束了.在这里或这里。
但是 事实证明 用于线性回归的 代价函数 总是这样一个 弓形的样子 这个函数的专业术语是 这是一个凸函数 我不打算在这门课中 给出凸函数的定义 凸函数(convex function) 但不正式的说法是 它就是一个弓形的函数 因此 这个函数 没有任何局部最优解 只有一个全局最优解 并且无论什么时候 你对这种代价函数 使用线性回归 梯度下降法得到的结果 总是收敛到全局最优值 因为没有全局最优以外的其他局部最优点
现在 让我们来看看这个算法的执行过程 像往常一样 这是假设函数的图 还有代价函数J的图 让我们来看看如何 初始化参数的值 通常来说 初始化参数为零 θ0和θ1都在零 但为了展示需要 在这个梯度下降的实现中 我把θ0初始化为-900 θ1初始化为-0.1 这对应的假设 就应该是这样 h(x)是等于-900减0.1x 这对应我们的代价函数 现在 如果我们进行 一次梯度下降 从这个点开始 在这里.一点点 向左下方移动了一小步 这就得到了第二个点 而且你注意到这条线改变了一点点 然后我再进行 一步梯度下降 左边这条线又变一点 对吧 同样地 我又移到代价函数上的另一个点 再进行一步梯度下降 我觉得我的代价项 应该开始下降了 所以我的参数是 跟随着这个轨迹 再看左边这个图 这个表示的是假设函数h(x) 它变得好像 越来越拟合数据 直到它渐渐地 收敛到全局最小值 这个全局最小值 对应的假设函数 给出了最拟合数据的解 这就是梯度下降法 我们刚刚运行了一遍 并且最终得到了 房价数据的最好拟合结果 现在你可以用它来预测 比如说 假如你有个朋友 他有一套房子 面积1250平方英尺(约116平米) 现在你可以通过这个数据 然后告诉他们 也许他的房子 可以卖到35万美元
最后 我想再给出 另一个名字 实际上 我们 刚刚使用的算法 有时也称为批量梯度下降 实际上 在机器学习中 我们这些搞机器学习的人 通常不太会 给算法起名字 但这个名字"批量梯度下降" 指的是 在梯度下降的 每一步中 我们都用到了所有的训练样本 在梯度下降中 在计算微分求导项时 我们需要进行求和运算 所以 在每一个单独的 梯度下降中 我们最终 都要计算这样一个东西 这个项需要对所有m个训练样本求和 因此 批量梯度下降法 这个名字 说明了 我们需要考虑 所有这一"批"训练样本 这确实不是一个 很好听的名字 但是搞机器学习的人就是这么称呼的
而事实上 有时也有其他类型的 梯度下降法 不是这种"批量"型的 不考虑整个的训练集 而是每次只关注 训练集中的一些小的子集 在后面的课程中 我们也将介绍这些方法 但就目前而言 应用刚刚学到的算法 你应该已经掌握了批量梯度算法 并且能把它应用到 线性回归中了
这就是用于线性回归的梯度下降法 如果你之前学过线性代数 有些同学之前 可能已经学过 高等线性代数 你应该知道 有一种计算 代价函数J最小值的 数值解法 不需要梯度下降这种迭代算法 在后面的课程中 我们也会谈到这个方法 它可以在不需要 多步梯度下降的情况下 也能解出代价函数J的最小值 这是另一种称为正规方程(normal equations)的方法 可能你之前已经 听说过这种方法 实际上在数据量较大的情况下 梯度下降法比正规方程 要更适用一些 现在我们已经 掌握了梯度下降 我们可以在不同的环境中 使用梯度下降法 我们还将在不同的机器学习问题中大量地使用它
所以 祝贺大家成功 学会你的第一个机器学习算法 我们稍后将有一些练习 这些练习会要求你 实现梯度下降 希望大家能让这些算法真正地为你工作 但在此之前 我还想先 在下一组视频中 告诉你 泛化的梯度下降 算法 这将使 梯度下降更加强大 在下一段视频中我将介绍这一问题。
Linear Algebra Review线性代数知识回顾
Matrices and Vectors矩阵和向量
我们先复习一下线性代数的知识 在这段视频中 我会向大家介绍矩阵和向量的概念
矩阵是指 由数字组成的矩形阵列 并写在方括号中间
例如 屏幕中所示的一个矩阵 先写一个左括号 然后是一些数字 这些数字可能是 机器学习问题的特征值 也可能表示其他意思 不过现在不用管具体的数字 然后我用右方括号将其括起来 这样就得到了一个矩阵 接下来 看一下其他矩阵的例子 依次写下1 2 3 4 5 6 因此实际上矩阵 可以说是二维数组的 另一个名字 另外 我们还需要知道的是 矩阵的维度 应该写作 矩阵的行数乘以列数
具体到这个例子 看左边 包括1 2 3 4共4行 以及2列 因此 这个例子是一个 4 × 2的矩阵 即行数乘以列数 4行乘2列
右边的矩阵有两行 这是第一行 这是第二行 此外包括三列 这是第一列 第二列 第三列 因此 我们把 这个矩阵称为一个 2 × 3维的矩阵 所以我们说这个矩阵的维度是2 × 3维
有时候大家会发现 书写有些不同 比如左边的矩阵 写成了R4 × 2 具体而言 大家会将该矩阵称作 是集合R4×2的元素 因此 也就是说 这个矩阵 R4×2代表所有4×2的矩阵的集合
而右边的这个矩阵 有时候也写作一个R2×3的矩阵 因此 如果你看到2×3 如果你看到 有些地方表达为 4×2的或者2×3的 一般都是指 一个特定维度的矩阵
接下来 让我们来谈谈如何 表达矩阵的某个特定元素 这里我说矩阵元素 而不是矩阵 我的意思是 矩阵的条目数 也就是矩阵内部的某个数 所以 标准的表达是 如果A是 这个矩阵 那么A下标 ij 表示的是 i j对应的那个数字 意思是矩阵的第i行和第j列 对应的那个数 因此 例如 A11 表示的是第1行 第1列所对应的那个元素 所以这是 第一行和第一列 因此A11 就等于 1402 另一个例子 A12 表示的是 第一行第二列 对应的那个数 所以A12 将等于191 再看一个简单的例子 让我们来看看 比如说A32 表达的是 第3行第2列 对应的那个数 是吧 因为这是3 2 所以这等于1437 最后 A41 应该等于 第四行第一列 对应的数 所以是等于 147 我希望你不会犯下面的错误 但如果你这么写的话 如果你写出了A43 这应该表示的是 第四行第三列 而你知道 这个矩阵没有第三列 因此这是未定义的 或者你可以认为这是一个错误 根本就没有什么A43 对应的元素 所以 你不能写A43
因此 矩阵 提供了一种很好的方式 让你快速整理 索引和访问大量数据
可能你觉得 我似乎是 介绍了很多概念 很多新的符号 我讲得很快 你不需要 把这些都记住 但在课程网站上 我们已经发布了讲义 所有这些定义都写在讲义里 所以 你可以随时参考 包括这些幻灯片 你可以随时回来观看视频 如果你忘了A41到底是表示什么? 哪一行 哪一列是什么? 所以现在不要担心记忆问题 你可以随时回来参考 课程网站上的材料 所以 这就是矩阵的定义
接下来 让我们来谈谈什么是向量
一个向量是一种特殊的矩阵 向量是只有一列的 矩阵 所以 你有一个 n×1 矩阵 还记得吗 N是行数 而这里的1 表示的是列数 所以 只有一列的矩阵 就是我们所说的向量
因此 这里是一个向量的 例子 比如说 我有 n = 4 个元素 所以我们也把这个称为 另一个术语是 这是一个四维的 向量 也就意味着 这是一个含有 4个元素的向量 而且 前面我们讲 矩阵的时候提到过 这个符号R3×2 表示的是一个3行2列的矩阵 而对于这个向量 我们也同样可以 表示为集合R4 因此 这个R4是指 一个四维向量的集合
接下来让我们来谈谈如何引用向量的元素 我们将使用符号 yi来代表 向量y的第i个元素 所以 如果这个向量是y 那么y下标i 则表示它的第i个元素 所以y1表示第一个元素 460 y2表示第二个元素 232 这是第二个元素 还有y3等于 315 等等 只有y1至y4是有意义的 因为这定义的是一个四维向量
此外 事实上 有两种方法来表达 某个向量中某个索引 是这两种 有时候 人们会使用 1-索引 有时候用0-索引 因此 左边这个例子 是一个1-索引向量 它的元素写作 y1 y2 y3 y4 而右边这个向量 是0-索引的一个例子 我们的索引 从下标0开始 因此 元素从y0至y3 这有点像 一些初级语言中的数组 数组是从1开始 排序的 数组的第一个元素 一般时从y1开始 这是表示序列的符号 有时是从0开始排序 这取决于你用什么编程语言
所以 事实上 在数学中 1-索引的情况比较多 而对于很多 机器学习的应用问题来说 0-索引向量为我们提供了一个更方便的符号表达 所以你通常应该 做的是 除非特别指定 你应该默认我们使用的是1-索引法表示向量
在本课程的后面所有 关于线性代数的视频中 我都将使用1-索引法表示向量 但你要明白 当我们谈论到机器学习的 应用问题时 如果我们需要使用0-索引向量的话 我会明确地告诉你 我们什么时候换成 使用0-索引表达
最后 按照惯例 通常在书写矩阵和向量时 大多数人会使用大写字母 来表示矩阵 因此 我们要使用 大写字母 如 A B C X 来表示矩阵 而通常我们会使用小写字母 像a b x y 来表示数字 或是原始的数字 或标量 或向量 这是实际的使用习惯 我们也经常看到 使用小写字母y 来表示向量 但我们平时 是用大写字母来表示矩阵 所以 你现在知道了什么是矩阵和向量 接下来 我们将继续讨论关于它们一些内容
Addition and Scalar Multiplication加法和标量乘法
Matrix Vector Multiplication矩阵与向量的乘法
Matrix Matrix Multiplication矩阵与矩阵的乘法
Matrix Multiplication Properties矩阵乘法性质
Inverse and Transpose矩阵的逆运算和转置运算
接下来 运用这些所学的工具 在接下来的几段视频中 我们将介绍 非常重要的线性回归 我们会看到更多的数据 更多的特征 以及更多的训练样本 再往后 在介绍线性回归之后 我们还将继续使用这些线代工具 来推导一些 更加强大的学习算法