《第一行代码(第三版)》kotlin开发Android,学习笔记(进行中ing)
文章目录
- 第2章 快速入门Kotlin编程
-
- 2.1 kotlin取代Java成为Android第一开发语言的原因
- 2.2 如何运行Kotlin代码
- 2.3 编程之本: 变量和函数
-
- 2.3.1 变量
- 2.3.2 函数
- 2.4 程序的逻辑控制
-
- 2.4.1 if语句
- 2.4.2 when条件语句
- 2.4.3 循环语句
- 2.5 面向对象编程
-
- 2.5.1 类与对象
- 2.5.2 继承与构造函数
-
- kotlin继承重点:
- 2.5.3 接口
- 补充: Java和Kotlin 函数可见性修饰符对照表
- 2.5.4 数据类与单例类
- 2.6 Lambda编程
-
- 2.6.1 集合的创建与遍历
- 2.6.2 集合的函数式API(这部分看看原文)
- 2.7 空指针检查
-
- 2.7.1 可空类型系统
- 2.7.2 判空辅助工具
- 2.8 Kotlin中的小魔术
-
- 2.8.1 字符串内嵌表达式
- 2.8.2 函数的参数默认值
- 第3章 Activity
-
- 3.7 kotlin:标准函数与静态方法
-
- 3.7.1 标准函数with、run、apply
- 3.7.2 定义静态方法
- 第4章 软件也要拼脸蛋,UI开发的点点滴滴
-
- 4.8 Kotlin: 延迟初始化和密封类
-
- 4.8.1 关键字lateinit: 对变量进延迟初始化
- 4.8.2 使用密封类优化代码
- 第5章 手机平板要兼顾,探索Fragment
-
- 5.6 Kotlin: 扩展函数和运算符重载
-
- 5.6.1 大有用途的扩展函数
- 第6章 全局大喇叭,详解广播机制
-
- 6.5 Koltin: 高阶函数
-
- 6.5.1 定义高阶函数
- 6.5.2 内联函数的作用——inline关键字
- 6.5.3 noinline与crossinline
- 第7章 数据存储方案,详解持久化技术
- 第8章
-
- 8.5 Kotlin课堂:泛型和委托
-
- 8.5.1 泛型的基本用法
- 8.5.2 类委托和委托属性
- 11.7 Kotlin课程: 使用协程编写高效的并发程序
- 第13章 高级程序开发组件,探究Jetpack
-
- 13.1 Jetpack简介
- 13.2 ViewModel
- kotlin与Java的不同之处
Android是以前学习的知识,本人非常热爱android开发,所以即使现在也偶尔看看相关技术。了解到Android现在多用Kotlin开发,故利用闲暇看看《第一行代码》(第3版)kotlin版。
本博客记录一下在Android开发中,Kotlin和Java不同之处,如有不当,还请各位指出。
第2章 快速入门Kotlin编程
2.1 kotlin取代Java成为Android第一开发语言的原因
(1)Kotlin语法简洁,同样功能,kotlin可能会比java减少50%的代码量;
(2)语法更加高级,使开发效率提升;
(3)kotlin在语言安全性上下了工夫,几乎杜绝了空指针这个全球崩溃率最高的异常;
(4)与Java100%兼容,使得Kotlin可以直接调用Java编写的代码,可以无缝使用Java三方库。
2.2 如何运行Kotlin代码
注:在线kotlin编程网址
https://try.kotlinlang.org
2.3 编程之本: 变量和函数
2.3.1 变量
(1)val: 申明一个不可变的变量,这种变量在初始赋值后就不能重新赋值了,对应Java中的final变量;
(2)var: 申明一个可变的变量。
(3)Kotlin的推导机制与显示声明类型
推导机制:
fun main() {
val a = 10 //会自动推导a为Int型
println("a = " + a)
}
但如果先申明变量,后面再来赋值,则要进行显示声明类型,如:
val a: Int = 10
(4)Java与Kotlin基本类型对照表
如果你学过Java 并且足够细心的话,你可能发现了Kotlin中Int的首字母是大写的,而Java 中int的首字母是小写的。不要小看这一个字母大小写的差距,这表示Kotlin完全抛弃了Java 中的基本数据类型,全部使用了对象数据类型。在Java 中int是关键字,而在Kotlin中Int变成了一
个类,它拥有自己的方法和继承结构。

2.3.2 函数
函数的申明如下:
fun largerNumber(num1: Int, num2: Int): Int {
return max(num1, num2)
}
另:
当一个函数中只有一行代码时,Kotlin允许我们不必编写函数体,可以直接将唯一的一行代码写在函数定义的尾部,中间用等号连接即可。比如我们刚才编写的largerNumber()函数就只有一行代码,于是可以将代码简化成如下形式:
fun largerNumber(num1: Int, num2: Int): Int = max(num1, num2)
由于max()函数返回的是一个Int值,而我们在largerNumber()函数的尾部又使用等号连接了max()函数,因此Kotlin可以推导出largerNumber()函数返回的必然也是一个Int值,这样就不用再显式地声明返回值类型了,代码可以进一步简化成如下形式:
fun largerNumber(num1: Int, num2: Int) = max(num1, num2)
2.4 程序的逻辑控制
2.4.1 if语句
Kotli n中的if语句和Java 中的if语句几乎没有任何区别,但kotlin中可以通过语法糖进行简化,如:
fun largerNumber(num1: Int, num2: Int): Int {
var value = 0
if (num1 > num2) {
value = num1
} else {
value = num2
}
return value
}
可以简化为:
val value = if (num1 > num2) {
num1
} else {
num2
}
return value
}
进一步简化:
fun largerNumber(num1: Int, num2: Int) = if (num1 > num2) {
num1
} else {
num2
}
再进一步:
fun largerNumber(num1: Int, num2: Int) = if (num1 > num2) num1 else num2
2.4.2 when条件语句
Kotlin中的when语句有点类似于Java 中的switch语句,但它又远
比switch语句强大得多。
输入一个学生的姓名,返回该学生考试的分数, 如果用if语句写,如下:
fun getScore(name: String) = if (name == "Tom") {
86
} else if (name == "Jim") {
77
} else if (name == "Jack") {
95
} else if (name == "Lily") {
100
} else {
0
}
使用when写,更简单,如下:
fun getScore(name: String) = when (name) {
"Tom" -> 86
"Jim" -> 77
"Jack" -> 95
"Lily" -> 100
else -> 0
}
也可以写成无参数形式:
fun getScore(name: String) = when {
name.startsWith("Tom") -> 86
name == "Jim" -> 77
else -> 0
}
注意,Kotlin中判断字符串或对象是否相等可以直接使用==关键字,而不用像Java 那样调用equals()方法。
when的特点:
(1)when语句和if语句一样,也是可以有返回值的,因此我们仍然可以使用单行代码函数的语法糖;
(2)when语句允许传入一个任意类型的参数,然后可以在when的结构体中定义一系列的条件,格式是:
匹配值 -> { 执行逻辑 }
(3)除了精确匹配之外,when语句还允许进行类型匹配,如下:
fun checkNumber(num: Number) {
when (num) {
is Int -> println("number is Int")
is Double -> println("number is Double")
else -> println("number not support")
}
}
2.4.3 循环语句
(1)while循环
其中while循环不管是在语法还是使用技巧上都和Java 中的while循环没有任何区别。
(2)for循环
a. 区间概念
val range = 0..10 // 表示[0, 10]区间
val range = 0 until 10 // 表示[0, 10)
有了区间后,就可以通过for循环进行遍历了,如下:
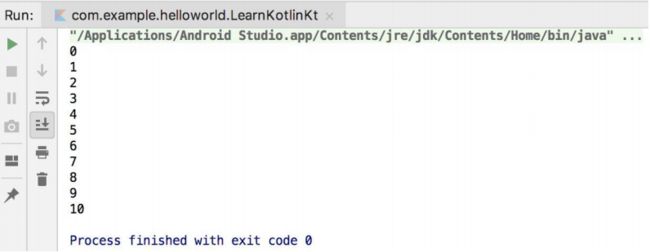
fun main() {
for (i in 0..10) {
println(i)
}
}
结果:
b. step递增
step 2 //在for-in循环中表示递增2,即 i = i+2
如:
fun main() {
for (i in 0 until 10 step 2) {
println(i)
}
}
结果:

c. downTo 递减
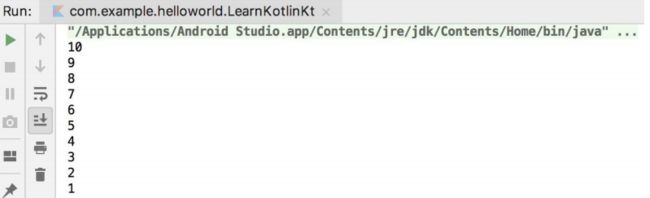
fun main() {
for (i in 10 downTo 1) { //相当于 [10, 1]的降序空间
println(i)
}
}
结果:
2.5 面向对象编程
和很多现代高级语言一样,Kotlin也是面向对象的。
面向对象编程的三大特性:
(1)封装
(2)继承
(3)多态
2.5.1 类与对象
(1)类的创建
类的创建感觉和Java差不多,如图:
class Person {
var name = ""
var age = 0
fun eat() {
println(name + " is eating. He is " + age + " years old.")
}
}
(2)类的实例化
不用关键字new了,直接使用类名:
fun main() {
val p = Person() //不需要关键字即可进行类的实例化
p.name = "Jack"
p.age = 19
p.eat()
}
2.5.2 继承与构造函数
使用Student类,继承上面的Person类。
(1)kotlin与java在继承上的不同设计
有Java 编程经验的人知道,一个类本身不就是可以被继承的吗?为什么还要使Person类可以被继承呢?这就是Kotlin不同的地方,在Kotlin中任何一个非抽象类默认都是不可以被继承的,相当于Java 中给类声明了final关键字。之所以这么设计,其实和val关键字的原因是差不多的,因为类和变量一样,最好都是不可变的,而一个类允许被继承的话,它无法预知子类会如何实现,因此可能就会存在一些未知的风险。Effective Java 这本书中明确提到,如果一个类不是专门为继承而设计的,那么就应该主动将它加上final声明,禁止它可以被继承。
很明显,Kotlin在设计的时候遵循了这条编程规范,默认所有非抽象类都是不可以被继承的。之所以这里一直在说非抽象类,是因为抽象类本身是无法创建实例的,一定要由子类去继承它才能创建实例,因此抽象类必须可以被继承才行,要不然就没有意义了。
由于Kotlin中的抽象类和Java 中并无区别,这里我就不再多讲了。
(2)Student类继承自Person类
Step1: 给Person类添加open关键字,使其可以被继承
open class Person {
...
}
加上open关键字之后,我们就是在主动告诉Kotlin编译器,Person这个类是专门为继承而设计的,这样Person类就允许被继承了。
Step2: Student类使用冒号继承Person类
在Java 中继承的关键字是extends,而在Kotlin中变成了一个冒号,写法如下:
class Student : Person() {
var sno = ""
var grade = 0
}
kotlin继承重点:
a. 主构造函数
继承的写法如果只是替换一下关键字倒也挺简单的,但是为什么Person类的后面要加上一对括号呢?Java 中继承的时候好像并不需要括号。对于初学Kotlin的人来讲,这对括号确实挺难理解的,也可能是Kotlin在这方面设计得太复杂了,因为它还涉及主构造函数、次构造函数等方面的知识,这里我尽量尝试用最简单易懂的讲述来让你理解这对括号的意义和作用,同时顺便学习一下Kotlin中的主构造函数和次构造函数。
任何一个面向对象的编程语言都会有构造函数的概念,Kotlin中也有,但是Kotlin将构造函数分成了两种:主构造函数和次构造函数。
主构造函数将会是你最常用的构造函数,每个类默认都会有一个不带参数的主构造函数,当然你也可以显式地给它指明参数。主构造函数的特点是没有函数体,直接定义在类名的后面即可。比如下面这种写法:
class Student(val sno: String, val grade: Int) : Person() {
}
这里我们将学号和年级这两个字段都放到了主构造函数当中,这就表明在对Student类进行实例化的时候,必须传入构造函数中要求的所有参数。比如:
val student = Student("a123", 5)
这样我们就创建了一个Student的对象,同时指定该学生的学号是a123 ,年级是5。另外,由于构造函数中的参数是在创建实例的时候传入的,不像之前的写法那样还得重新赋值,因此我们可以将参数全部声明成val。
你可能会问,主构造函数没有函数体,如果我想在主构造函数中编写一些逻辑,该怎么办呢?Kotlin给我们提供了一个init结构体,所有主构造函数中的逻辑都可以写在里面:
class Student(val sno: String, val grade: Int) : Person() {
init { //写主构造函数的逻辑
println("sno is " + sno)
println("grade is " + grade)
}
}
到这里为止都还挺好理解的吧?但是这和那对括号又有什么关系呢?这就涉及了Java 继承特性中的一个规定,子类中的构造函数必须调用父类中的构造函数,这个规定在Kotlin中也要遵守。
那么回头看一下Student类,现在我们声明了一个主构造函数,根据继承特性的规定,子类的构造函数必须调用父类的构造函数,可是主构造函数并没有函数体,我们怎样去调用父类的构造函数呢?你可能会说,在init结构体中去调用不就好了。这或许是一种办法,但绝对不是一种好办法,因为在绝大多数的场景下,我们是不需要编写init结构体的。
Kotlin当然没有采用这种设计,而是用了另外一种简单但是可能不太好理解的设计方式:括号。子类的主构造函数调用父类中的哪个构造函数,在继承的时候通过括号来指定。因此再来看一遍这段代码,你应该就能理解了吧。
class Student(val sno: String, val grade: Int) : Person() { //这里通过空括号来调用Person类的无参构造函数
}
在这里,Person类后面的一对空括号表示Student类的主构造函数在初始化的时候会调用Person类的无参数构造函数,即使在无参数的情况下,这对括号也不能省略。
而如果我们将Person改造一下,将姓名和年龄都放到主构造函数当中,如下所示:
open class Person(val name: String, val age: Int) {
...
}
此时,Student类继承Person类时,必须给Person类的构造函数传入name和age字段,可是Student类中也没有这两个字段呀。很简单,没有就加呗。我们可以在Student类的主构造函数中加上name和age这两个参数,再将这两个参数传给Person类的构造函数,代码如下所示:
class Student(val sno: String, val grade: Int, name: String, age: Int) : Person(name, age) {
...
}
注意,我们在Student类的主构造函数中增加name和age这两个字段时,不能再将它们声明成val,因为在主构造函数中声明成val或者var的参数将自动成为该类的字段,这就会导致和父类中同名的name和age字段造成冲突。因此,这里的name和age参数前面我们不用加任何关键字,让它的作用域仅限定在主构造函数当中即可。
现在就可以通过如下代码来创建一个Student类的实例:
val student = Student("a123", 5, "Jack", 19)
b. 次构造函数
Kotlin在括号这个问题上的复杂度并不仅限于此,因为我们还没涉及Kotlin构造函数中的另一个组成部分——次构造函数。
任何一个类只能有一个主构造函数,但是可以有多个次构造函数。次构造函数也可以用于实例化一个类,这一点和主构造函数没有什么不同,只不过它是有函数体的。
Kotlin规定,当一个类既有主构造函数又有次构造函数时,所有的次构造函数都必须调用主构造函数(包括间接调用)。这里我通过一个具体的例子就能简单阐明,代码如下:
class Student(val sno: String, val grade: Int, name: String, age: Int) : Person(name, age) {
// 第一个次构造函数接收name和age参数,然后它又通过this关键字调用了主构造函数,并将sno和grade这两个参数赋值成初始值
constructor(name: String, age: Int) : this("", 0, name, age) {
}
// 第二个次构造函数不接收任何参数,它通过this关键字调用了我们刚才定义的第一个次构造函数,并将name和age参数也赋值成初始值,由于第二个次构造函数间接调用了主构造函数,因此这仍然是合法的
constructor() : this("", 0) {
}
}
次构造函数是通过constructor关键字来定义的,这里我们定义了两个次构造函数:第一个次构造函数接收name和age参数,然后它又通过this关键字调用了主构造函数,并将sno和grade这两个参数赋值成初始值;第二个次构造函数不接收任何参数,它通过this关键字调用了我们刚才定义的第一个次构造函数,并将name和age参数也赋值成初始值,由于第二个次构造函数间接调用了主构造函数,因此这仍然是合法的。
那么现在我们就拥有了3种方式来对Student类进行实体化,分别是通过不带参数的构造函数、通过带两个参数的构造函数和通过带4个参数的构造函数,对应代码如下所示:
val student3 = Student("a123", 5, "Jack", 19) // 使用主构造函数
val student2 = Student("Jack", 19) // 使用第1个次构造函数
val student1 = Student() // 使用第2个次构造函数
那么接下来我们就再来看一种非常特殊的情况:类中只有次构造函数,没有主构造函数。这种情况真的十分少见,但在Kotlin中是允许的。当一个类没有显式地定义主构造函数且定义了次构造函数时,它就是没有主构造函数的。我们结合代码来看一下:
class Student : Person {
constructor(name: String, age: Int) : super(name, age) {
}
}
注意这里的代码变化,首先Student类的后面没有显式地定义主构造函数,同时又因为定义了次构造函数,所以现在Student类是没有主构造函数的。那么既然没有主构造函数,继承Person类的时候也就不需要再加上括号了。其实原因就是这么简单,只是很多人在刚开始学习Kotlin的时候没能理解这对括号的意义和规则,因此总感觉继承的写法有时候要加上括号,有时候又不要加,搞得晕头转向的,而在你真正理解了规则之后,就会发现其实还是很好懂的。
另外,由于没有主构造函数,次构造函数只能直接调用父类的构造函数,上述代码也是将this关键字换成了super关键字,这部分就很好理解了,因为和Java 比较像,我也就不再多说了。
2.5.3 接口
(1)Kotlin中的接口部分和Java 几乎是完全一致的
Java 中继承使用的关键字是extends,实现接口使用的关键字是implements,而Kotlin中统一使用冒号,中间用逗号进行分隔。
例如:
interface Study {
fun readBooks()
fun doHomework()
}
继承:
class Student(name: String, age: Int) : Person(name, age), Study {
override fun readBooks() {
println(name + " is reading.")
}
override fun doHomework() {
println(name + " is doing homework.")
}
}
(2)Kotlin还增加了一个额外的功能:允许对接口中定义的函数进行默认实现
实例:
interface Study {
fun readBooks()
fun doHomework() {
println("do homework default implementation.")
}
}
如果接口中的一个函数拥有了函数体,这个函数体中的内容就是它的默认实现。现在当一个类去实现Study接口时,只会强制要求实现readBooks()函数,而doHomework()函数则可以自由选择实现或者不实现,不实现时就会自动使用默认的实现逻辑。
补充: Java和Kotlin 函数可见性修饰符对照表
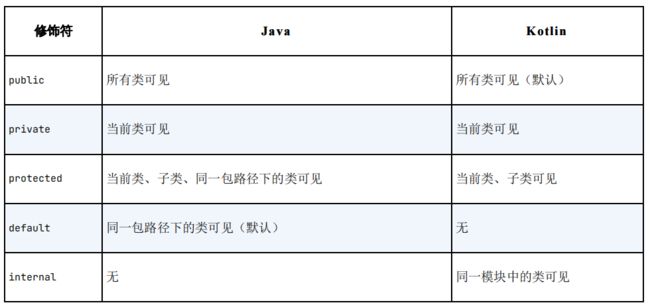
首先private修饰符在两种语言中的作用是一模一样的,都表示只对当前类内部可见。public修饰符的作用虽然也是一致的,表示对所有类都可见,但是在Kotlin中public修饰符是默认项,而在Java 中default才是默认项。前面我们定义了那么多的函数,都没有加任何的修饰符,所以它们默认都是public的。protected关键字在Java 中表示对当前类、子类和同一包路径下的类可见,在Kotlin中则表示只对当前类和子类可见。Kotlin抛弃了Java 中的default可见性(同一包路径下的类可见),引入了一种新的可见性概念,只对同一模块中的类可见,使用的是internal修饰符。比如我们开发了一个模块给别人使用,但是有一些函数只允许在模块内部调用,不想暴露给外部,就可以将这些函数声明成internal。
2.5.4 数据类与单例类
(1)数据类——data关键字
数据类通常需要重写equals()、hashCode()、toString()这几个方法。其中,equals()
方法用于判断两个数据类是否相等。hashCode()方法作为equals()的配套方法,也需要一起重写,否则会导致HashMap、HashSet等hash相关的系统类无法正常工作。toString()方法用于提供更清晰的输入日志,否则一个数据类默认打印出来的就是一行内存地址。
这里我们新构建一个手机数据类,字段就简单一点,只有品牌和价格这两个字段。如果使用Java 来实现这样一个数据类,代码就需要这样写:
public class Cellphone {
String brand;
double price;
public Cellphone(String brand, double price) {
this.brand = brand;
this.price = price;
}
@Override
public boolean equals(Object obj) {
if (obj instanceof Cellphone) {
Cellphone other = (Cellphone) obj;
return other.brand.equals(brand) && other.price == price;
}
return false;
}
@Override
public int hashCode() {
return brand.hashCode() + (int) price;
}
@Override
public String toString() {
return "Cellphone(brand=" + brand + ", price=" + price + ")";
}
}
若使用Kotlin,创建手机类,如下:
data class Cellphone(val brand: String, val price: Double)
只需要一行代码就可以实现了!神奇的地方就在于data这个关键字,当在一个类前
面声明了data关键字时,就表明你希望这个类是一个数据类,Kotlin会根据主构造函数中的参数帮你将equals()、hashCode()、toString()等固定且无实际逻辑意义的方法自动生成,从而大大减少了开发的工作量。
另外,当一个类中没有任何代码时,还可以将尾部的大括号省略。
(2)单例类——object关键字
想必你一定听说过单例模式吧,这是最常用、最基础的设计模式之一,它可以用于避免创建重复的对象。比如我们希望某个类在全局最多只能拥有一个实例,这时就可以使用单例模式。当然单例模式也有很多种写法,这里就演示一种最常见的Java 写法吧:
public class Singleton {
private static Singleton instance;
private Singleton() {}
public synchronized static Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
public void singletonTest() {
System.out.println("singletonTest is called.");
}
}
在Kotlin中创建一个单例类的方式极其简单,只需要将class关键字改成object关键字即可。现在我们尝试创建一个Kotlin版的Singleton单例类,右击com.example.helloworld 包→New→Kotlin File/Class,在弹出的对话框中输入“Singleton” ,创建类型选择“Object” ,点击“OK”完成创建,初始代码如下所示:
object Singleton {
}
现在Singleton就已经是一个单例类了,我们可以直接在这个类中编写需要的函数,比如加入一个singletonTest()函数:
object Singleton {
fun singletonTest() {
println("singletonTest is called.")
}
}
可以看到,在Kotlin中我们不需要私有化构造函数,也不需要提供getInstance()这样的静态方法,只需要把class关键字改成object关键字,一个单例类就创建完成了。而调用单例类中的函数也很简单,比较类似于Java 中静态方法的调用方式:
Singleton.singletonTest()
这种写法虽然看上去像是静态方法的调用,但其实Kotlin在背后自动帮我们创建了一个Singleton类的实例,并且保证全局只会存在一个Singleton实例。
2.6 Lambda编程
Lambda编程非常重要,作者甚至认为是Kotlin的核心
2.6.1 集合的创建与遍历
传统意义上的集合主要就是List和Set,再广泛一点的话,像Map这样的键值对数据结构也可以包含进来。List、Set和Map在Java 中都是接口,List的主要实现类是ArrayList和LinkedList,Set的主要实现类是HashSet,Map的主要实现类是HashMap。
1. List集合
(1)不可变集合:listOf()
listOf()函数创建的是一个不可变的集合。不可变的集合指的就是该集合只能用于读取,我们无法对集合进行添加、修改或删除操作。

(2)可变集合:mutableListOf()
使用mutableListOf()函数创建一个可变的集合, 即,可以对集合进行增删改查。
2. Set集合
Set集合和List集合用法差不多,也分为:setOf() 和mutableSetOf(),代码如下:
println("----------Set集合------------")
val set = setOf("zhao", "qian", "sun") // 不可变set
for (xing in set){
println(xing)
}
val mutableSet = mutableSetOf("li", "zhou") // 可变set
mutableSet.add("wu")
mutableSet.remove("li")
for(x in mutableSet){
println(x)
}
结果:

需要注意:Set集合中是不可以存放重复元素的,如果放了多个相同的元素,只会保留一份。
这就是和List集合最大的不同之处
3. Map集合
Map是一种键值对形式的数据结构,因此在用法上和List、Set集合有较大的不同。传统的Map用法是先创建一个HashMap的实例,然后将一个个键值对数据添加到Map中,如:

kotlin还有更加简单的方法,如下:
val map = mapOf("Apple" to 1, "Pear" to 2) // 不可变map
for ((fruit, number) in map){
println("fruit is " + fruit + ", number is " + number)
}
val mutableMap = mutableMapOf("chen" to 3, "liao" to 4) // 可变map
mutableMap["cai"] = 5
for ((x, number) in mutableMap){
println("xing is " + x + ", number is " + number)
}
结果:

2.6.2 集合的函数式API(这部分看看原文)
2.7 空指针检查
2.7.1 可空类型系统
kotlin在函数传参时,默认不能未空;如果允许未空,可在参数类型后加一个"?",如:
fun test(a: Int, b:String?){ // 参数不能为空,参数b可以未空
println(b)
}
2.7.2 判空辅助工具
(1)?.操作符
假设a是一个对象,可将:
if( a != null ){
a.doSomething()
}
等价于:
a?.doSomething()
(2)?:操作符
这个操作符的左右两边都接收一个表达式,如果左边表达式的结果不为空就返回左边表达式的结果,否则就返回右边表达式的结果。
如:
val c = if (a ! = null) {
a
} else {
b
}
等价于:
val c = a?: b
上述两者结合,可将一些非常复杂的代码简化,如:
fun getTextLength(text: String?): Int {
if (text != null) {
return text.length
}
return 0
}
等价于:
fun getTextLength(text: String?) = text?.length ?: 0
(3)let
let既不是操作符,也不是什么关键字,而是一个函数。这个函数提供了函数式API的编程接口,并将原始调用对象作为参数传递到Lambda 表达式中。示例代码如下:
obj.let { obj2 ->
// 编写具体的业务逻辑
}
可以看到,这里调用了obj对象的let函数,然后Lambda 表达式中的代码就会立即执行,并且这个obj对象本身还会作为参数传递到Lambda 表达式中。不过,为了防止变量重名,这里我将参数名改成了obj2,但实际上它们是同一个对象,这就是let函数的作用。
let的使用:
下面这串代码:
fun doStudy(study: Study?) {
study?.readBooks()
study?.doHomework()
}
翻译成Java就是:
fun doStudy(study: Study?) {
if (study != null) {
study.readBooks()
}
if (study != null) {
study.doHomework()
}
}
就使用了两个if判断语句,但完全可以对study进行一次判空,就可以调用后面两个方法的,怎么改进呢,使用let如下:
fun doStudy(study: Study?) {
study?.let { stu ->
stu.readBooks()
stu.doHomework()
}
}
针对上述代码的解释:
(1)?.操作符表示对象为空时什么都不做,对象不为空时就调用let函数,
(2)let函数会将study对象本身作为参数传递到Lambda 表达式中,此时的study对象肯定不为空了,我们就能放心地调用它的任意方法了.
同时,因为Lambda的语法特性:
当Lambda 表达式的参数列表中只有一个参数时,可以不用声明参数名,直接使用it关键字来代替即可,那么代码就可以进一步简化成:
fun doStudy(study: Study?){
study?.let{
it.readBooks()
it.doHomeWork()
}
}
2.8 Kotlin中的小魔术
2.8.1 字符串内嵌表达式
kotlin中可以使用${obj}在字符串中内嵌表达式,当表达式中仅有一个变量的时候,还可以将两边的大括号省略,如:
val brand = "Samsung"
val price = 1299.99
println("Cellphone(brand=$brand, price=$price)")
2.8.2 函数的参数默认值
kotlin中允许函数的参数提供默认值,并在调用的使用可以使用参数名,如:
fun printParams(num: Int, str: String = "hello") {
println("num is $num , str is $str")
}
fun main() {
printParams(str = "world")
}
第3章 Activity
3.7 kotlin:标准函数与静态方法
3.7.1 标准函数with、run、apply
(1) with函数
with函数接收两个参数:第一个参数可以是一个任意类型的对象,第二个参数是一个Lambda 表达式。with函数会在Lambda 表达式中提供第一个参数对象的上下文,并使用Lambda 表达式中的最后一行代码作为返回值返回.
如下示例:
原代码:
val list = listOf("Apple", "Banana", "Orange", "Pear", "Grape")
val builder = StringBuilder()
builder.append("Start eating fruits.\n")
for (fruit in list) {
builder.append(fruit).append("\n")
}
builder.append("Ate all fruits.")
val result = builder.toString()
println(result)
这段代码的逻辑很简单,就是使用StringBuilder来构建吃水果的字符串,最后将结果打印出来。仔细观察上述代码,你会发现我们连续调用了很多次builder对象的方法。其实这个时候就可以考虑使用with函数来让代码变得更加精简,如下所示:
使用with函数:
val list = listOf("Apple", "Banana", "Orange", "Pear", "Grape")
val result = with(StringBuilder()) {
append("Start eating fruits.\n")
for (fruit in list) {
append(fruit).append("\n")
}
append("Ate all fruits.")
toString()
}
println(result)
分析:
这段代码乍一看可能有点迷惑性,其实很好理解。首先我们给with函数的第一个参数传入了一个StringBuilder对象,那么接下来整个Lambda 表达式的上下文就会是这个StringBuilder对象。于是我们在Lambda 表达式中就不用再像刚才那样调用builder.append()和builder.toString()方法了,而是可以直接调用append()和toString()方法。Lambda 表达式的最后一行代码会作为with函数的返回值返回,最终我们将结果打印出来。
(2)run函数
run函数的用法和使用场景其实和with函数是非常类似的,只是稍微做了一些语法改动而已。
首先run函数通常不会直接调用,而是要在某个对象的基础上调用;
其次run函数只接收一个Lambda 参数,并且会在Lambda 表达式中提供调用对象的上下文。
其他方面和with函数是一样的,包括也会使用Lambda 表达式中的最后一行代码作为返回值返回。
如上代码使用run函数:
val list = listOf("Apple", "Banana", "Orange", "Pear", "Grape")
val result = StringBuilder().run {
append("Start eating fruits.\n")
for (fruit in list) {
append(fruit).append("\n")
}
append("Ate all fruits.")
toString()
}
println(result)
总体来说变化非常小,只是将调用with函数并传入StringBuilder对象改成了调用
StringBuilder对象的run方法,其他都没有任何区别,这两段代码最终的执行结果是完全相同的。
(3)apply函数
apply函数和run函数也是极其类似的,都要在某个对象上调用,并且只接收一个Lambda 参数,也会在Lambda 表达式中提供调用对象的上下文,但是apply函数无法指定返回值,而是会自动返回调用对象本身。
如上代码使用apply函数:
val list = listOf("Apple", "Banana", "Orange", "Pear", "Grape")
val result = StringBuilder().apply {
append("Start eating fruits.\n")
for (fruit in list) {
append(fruit).append("\n")
}
append("Ate all fruits.")
}
println(result.toString())
注意这里的代码变化,由于apply函数无法指定返回值,只能返回调用对象本身,因此这里的result实际上是一个StringBuilder对象,所以我们在最后打印的时候还要再调用它的toString()方法才行。
3.7.2 定义静态方法
Kotlin 却极度弱化了静态方法这个概念,想要在Kotlin中定义一个静态方法反倒不是一件容易的事。但有很多方案可以实现静态方法的效果,如下:
(1)使用单例类
那么Kotlin 为什么要这样设计呢?因为Kotlin 提供了比静态方法更好用的语法特性,并且我们在上一节中已经学习过了,那就是单例类。像工具类这种功能,在Kotlin 中就非常推荐使用单例类的方式来实现,比如上述的Util工具类,如果使用Kotlin 来实现的话就可以这样写:
object Util {
fun doAction() {
println("do action")
}
}
(2)使用companion object
如:
class Util {
fun doAction1() {
println("do action1")
}
companion object {
fun doAction2() {
println("do action2")
}
}
}
这里首先我们将Util从单例类改成了一个普通类,然后在类中直接定义了一个doAction1()方法,又在companion object中定义了一个doAction2()方法。现在这两个方法就有了本质的区别,因为doAction1()方法是一定要先创建Util类的实例才能调用的,而doAction2()方法可以直接使用Util.doAction2()的方式调用。
不过,doAction2()方法其实也并不是静态方法,companion object这个关键字实际上会在Util类的内部创建一个伴生类,而doAction2()方法就是定义在这个伴生类里面的实例方法。只是Kotlin 会保证Util类始终只会存在一个伴生类对象,因此调用Util.doAction2()方法实际上就是调用了Util类中伴生对象的doAction2()方法。
由此可以看出,Kotlin 确实没有直接定义静态方法的关键字,但是提供了一些语法特性来支持类似于静态方法调用的写法,这些语法特性基本可以满足我们平时的开发需求了。
(3)真正实现静态方法的两种方式: @JvmStatic和顶层方法
1)使用注解@JvmStatic
先来看注解,前面使用的单例类和companion object都只是在语法的形式上模仿了静态方法的调用方式,实际上它们都不是真正的静态方法。因此如果你在Java 代码中以静态方法的形式去调用的话,你会发现这些方法并不存在。而如果我们给单例类或companion object中的方法加上@JvmStatic注解,那么Kotlin 编译器就会将这些方法编译成真正的静态方法,如下所示:
class Util {
fun doAction1() {
println("do action1")
}
companion object {
@JvmStatic
fun doAction2() {
println("do action2")
}
}
}
注意,@JvmStatic注解只能加在单例类或companion object中的方法上,如果你尝试加在一个普通方法上,会直接提示语法错误。
由于doAction2()方法已经成为了真正的静态方法,那么现在不管是在Kotlin 中还是在Java中,都可以使用Util.doAction2()的写法来调用了。
2)顶层方法
顶层方法指的是那些没有定义在任何类中的方法,比如我们在上一节中编写main()方法。Kotlin 编译器会将所有的顶层方法全部编译成静态方法,因此只要你定义了一个顶层方法,那么它就一定是静态方法。
怎样定义一个顶层方法:

第4章 软件也要拼脸蛋,UI开发的点点滴滴
4.8 Kotlin: 延迟初始化和密封类
4.8.1 关键字lateinit: 对变量进延迟初始化
如果不加lateinit关键字,对一个不能提前赋值的全局变量只能允许未空,这样后面就要做非空判断,非常麻烦,如:
private var adapter: MsgAdapter? = null
加了lateinit关键字后,就可以使全局变量的类型不为空,也能使其在后面进行赋值:
private var adapter: MsgAdapter
这样在后面就不需要进行很多判空操作了,前提是一定要记得在使用变量之前初始化它。
4.8.2 使用密封类优化代码
去看下对应资料
第5章 手机平板要兼顾,探索Fragment
5.6 Kotlin: 扩展函数和运算符重载
5.6.1 大有用途的扩展函数
扩展函数表示即使在不修改某个类的源码的情况下,仍然可以打开这个类,向该类添加新的函数。
为了帮助你更好地理解,我们先来思考一个功能。一段字符串中可能包含字母、数字和特殊符号等字符,现在我们希望统计字符串中字母的数量,你要怎么实现这个功能呢?如果按照一般的编程思维,可能大多数人会很自然地写出如下函数:
object StringUtil {
fun lettersCount(str: String): Int {
var count = 0
for (char in str) {
if (char.isLetter()) {
count++
}
}
return count
}
}
但使用扩展函数的话,就可以直接对某个类,如:String类,进行添加扩展函数,如:
扩展函数的语法如下:
fun ClassName.methodName(param1: Int, param2: Int): Int {
return 0
}
相比于定义一个普通的函数,定义扩展函数只需要在函数名的前面加上一个ClassName.的语法结构,就表示将该函数添加到指定类当中了。
接下来实现上面的功能,
新建一个String.kt文件,在里面添加函数:
fun String.lettersCount(): Int {
var count = 0
for (char in this) {
if (char.isLetter()) {
count++
}
}
return count
}
注意这里的代码变化,现在我们将lettersCount()方法定义成了String类的扩展函数,那么函数中就自动拥有了String实例的上下文。因此lettersCount()函数就不再需要接收一个字符串参数了,而是直接遍历this即可,因为现在this就代表着字符串本身。
调用如下:
val count = "ABC123xyz!@#".lettersCount()
第6章 全局大喇叭,详解广播机制
6.5 Koltin: 高阶函数
6.5.1 定义高阶函数
如果一个函数接收另一个函数作为参数,或者返回值的类型是另一个函数,那么该函数就称为高阶函数。
使用过程,看下例子就明白了:

6.5.2 内联函数的作用——inline关键字
对Lambda底层的逻辑的分析:
我们一直使用的Lambda表达式在底层被转换成了匿名类的实现方式,这就表明,我们每调用一次Lambda表达式,都会创建一个新的匿名类实例,所以就会带来额外的内存和性能开销。
解决方案:
为解决上述问题,Kotlin提供了内敛函数的功能,它可以将使用Lambda表达式带来的运行时开销完全消除。
实际做法:
只需要在定义高阶函数时加上inline关键字即可,如下所示:
inline fun num1AndNum2(num1: Int, num2: Int, operation: (Int, Int) -> Int): Int {
val result = operation(num1, num2)
return result
}
这样后面再使用在高阶函数中使用lambda调用方式(如下代码),就不会造成额外的开销了:
fun main() {
val num1 = 100
val num2 = 80
val result1 = num1AndNum2(num1, num2) { n1, n2 -> // 使用lambda方式调用函数
n1 + n2
}
val result2 = num1AndNum2(num1, num2) { n1, n2 ->
n1 - n2
}
println("result1 is $result1")
println("result2 is $result2")
}
内联函数的工作原理:
就是Kotlin编译器会将内敛函数中的代码在编译的时候自动替换到调用它的地方,这样就不存在运行时开销了。
另外:

这种非内联函数中的函数返回是局部返回,输入结果如下:

而内联函数则是全局返回,如下所示:

输出如下:
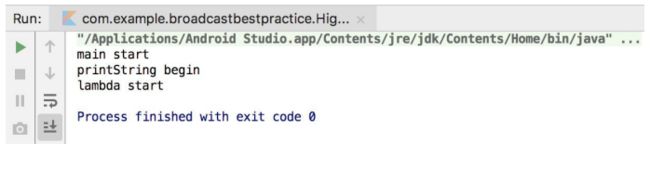
6.5.3 noinline与crossinline
(1)noinline
若一个高阶函数中如果接收了两个或者更多函数类型的参数,这时我们给函数加上了inline关键字,那么Kotlin 编译器会自动将所有引用的Lambda 表达式全部进行内联。
但是,如果我们只想内联其中的一个Lambda 表达式该怎么办呢?这时就可以使用noinline关键字了,如下所示:
inline fun inlineTest(block: () -> Unit, noinline block2:() -> Unit){
}
前面我们已经解释了内联函数的好处,那么为什么Kotlin 还要提供一个noinline关键字来排除内联功能呢?这是因为内联的函数类型参数在编译的时候会被进行代码替换,因此它没有真正的参数属性。非内联的函数类型参数可以自由地传递给其他任何函数,因为它就是一个真实的参数,而内联的函数类型参数只允许传递给另外一个内联函数,这也是它最大的局限性。
(2)crossinline


第7章 数据存储方案,详解持久化技术
第8章
8.5 Kotlin课堂:泛型和委托
8.5.1 泛型的基本用法
定义泛型类:
class MyClass{
fun method(param: T): T{
return param
}
}
使用泛型类:
val myClass = MyClass()
val result = myClass.method(123)
如果不想定义一个泛型类,只想定义一个泛型方法,应该怎样写?也很简单,只需要将定义泛型的语法结构写在方法上面就可以了,如下所示:
class MyClass {
fun method(param: T): T {
return param
}
}
调用如下:
val myClass = MyClass()
val result = myClass.method(123)
另外,Kotlin 还拥有非常出色的类型推导机制,例如我们传入了一个Int类型的参数,它能够自动推导出泛型的类型就是Int型,因此这里也可以直接省略泛型的指定:
val myClass = MyClass()
val result = myClass.method(123)
8.5.2 类委托和委托属性
11.7 Kotlin课程: 使用协程编写高效的并发程序
什么是协程:
协程和线程有点类似,可以简单地将它理解成一种轻量级线程。
我们之前所学习的线程是非常重量级的,它需要依靠操作系统的调度才能实现不同线程之间的切换。而使用协程却可以仅在编程语言的层面就能实现不同协程之间的切换,从而大大提升了并发编程的运行效率。
你已经知道,协程是一种轻量级的线程的概念,因此很多传统编程情况下需要开启多线程执行的并发任务,现在只需要在一个线程下开启多个协程来执行就可以了。 但是这并不意味着我们就永远不需要开启线程了,比如说Andr oid 中要求网络请求必须在子线程中进行,即使你开启了协程去执行网络请求,假如它是主线程当中的协程,那么程序仍然会出错。 这个时候我们就应该通过线程参数给协程指定一个具体的运行线程。
线程参数主要有以下3种值可选:Dispatchers.Default、Dispatchers.IO和
Dispatchers.Main。
(1)Dispatchers.Default表示会使用一种默认低并发的线程策略,当你要执行的代码属于计算密集型任务时 ,开启过高的并发反而可能会影响任务的运行效率,此时就可以使用Dispatchers.Default。(2)Dispatchers.IO表示会使用一种较高并发的线程策略,当你要执行的代码大多数时间是在阻塞和等待中,比如说执行网络请求时,为了能够支持更高的并发数量,此时就可以使用Dispatchers.IO。
(3)Dispatchers.Main则表示不会开启子线程,而是在Andr oid 主线程中执行代码,但是这个值只能在Android 项目中使用,纯Kotlin程序使用这种类型的线程参数会出现错误。
第13章 高级程序开发组件,探究Jetpack
13.1 Jetpack简介
Jetpack 是一个开发组件工具集,它的主要目的是帮助我们编写出更加简洁的代码,并简化我们的开发过程。Jetpack 中的组件有一个特点,它们大部分不依赖于任何Andr oid 系统版本,这意味着这些组件通常是定义在Andr oidX库当中的,并且拥有非常好的向下兼容性。

13.2 ViewModel
ViewModel 应该可以算是Jetpack 中最重要的组件之一了。
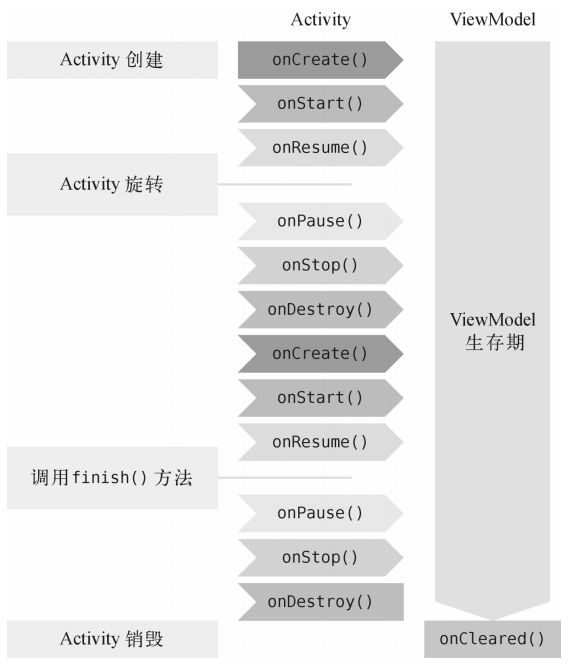
而ViewModel 的一个重要作用就是可以帮助Activity 分担一部分工作,它是专门用于存放与界面相关的数据的。也就是说,只要是界面上能看得到的数据,它的相关变量都应该存放在ViewModel 中,而不是Activity 中,这样可以在一定程度上减少Activity 中的逻辑。
另外,ViewModel 还有一个非常重要的特性。我们都知道,当手机发生横竖屏旋转的时候,Activity 会被重新创建,同时存放在Activity 中的数据也会丢失。而ViewModel 的生命周期和Activity 不同,它可以保证在手机屏幕发生旋转的时候不会被重新创建,只有当Activity 退出的时候才会跟着Activity 一起销毁。因此,将与界面相关的变量存放在ViewModel 当中,这样即使旋转手机屏幕,界面上显示的数据也不会丢失。ViewModel 的生命周期如图13.2 所示。