深入了解Redis(底层实现)源码 (第一篇)
Redis源码全景图

Deps目录:

第三方依赖库,那么为啥要引进第三方呢?因为Redis作为一个用C语言写的用户态程序,它的不少功能是依赖标准的glibc库提供的,比如内存分配、行读写、文件读写、子进程/线程创建等。但是,glibc库提供的某些功能实现,效率并不高。
我举个简单的例子,glibc 库中实现的内存分配器的性能就不是很高,它的内存碎片化情况也比较严重。因此为了避免对系统性能产生影响,Redis 使用了 jemalloc 库替换了 glibc 库的内存分配器。可是,jemalloc 库本身又不属于 Redis 系统自身的功能,把它和 Redis 功能源码放在一个目录下并不合适,所以,Redis 使用了专门的 deps 目录来保存这部分代码。
总而言之,对于 deps 目录来说,你只需要记住它主要存放了三类代码:一是 Redis 依赖的、实现更加高效的功能库,如内存分配;二是独立于 Redis 开发演进的代码,如客户端;三是 lua 脚本代码。后续完成功能的设计实现时,就可以在 deps 目录找到它们。
src 目录
这个目录里面包含了 Redis 所有功能模块的代码文件,也是 Redis 源码的重要组成部分。
tests 目录
在软件产品的开发过程中,除了第三方依赖库和功能模块源码以外,我们通常还需要在系统源码中,添加用于功能模块测试和单元测试的代码。而在 Redis 的代码目录中,就将这部分代码用一个 tests 目录统一管理了起来。
Redis 实现的测试代码可以分成四部分,分别是单元测试(对应 unit 子目录),Redis Cluster 功能测试(对应 cluster 子目录)、哨兵功能测试(对应 sentinel 子目录)、主从复制功能测试(对应 integration 子目录)。这些子目录中的测试代码使用了 Tcl 语言(通用的脚本语言)进行编写,主要目的就是方便进行测试。
不过在 tests 目录中,除了有针对特定功能模块的测试代码外,还有一些代码是用来支撑测试功能的,这些代码在 assets、helpers、modules、support 四个目录中。这里我画了这张图,展示了 tests 目录下的代码结构和层次,你可以参考下。

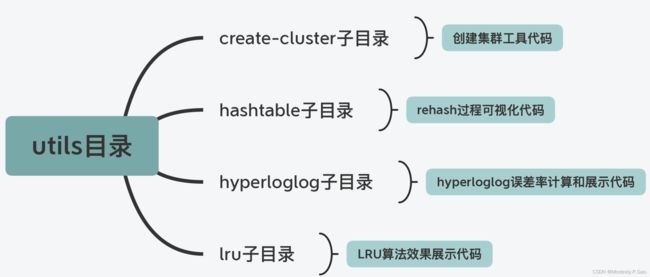
utils 目录
在 Redis 开发过程中,还有一些功能属于辅助性功能,包括用于创建 Redis Cluster 的脚本、用于测试 LRU 算法效果的程序,以及可视化 rehash 过程的程序。在 Redis 代码结构中,这些功能代码都被归类到了 utils 目录中统一管理。下图展示了 utils 目录下的主要子目录,你可以看下。
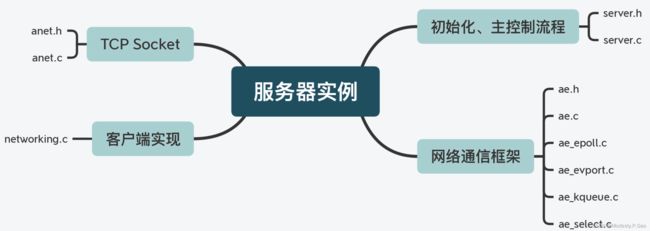
服务器实例
首先我们知道,Redis 在运行时是一个网络服务器实例,因此相应地就需要有代码实现服务器实例的初始化和主体控制流程,而这是由 server.h/server.c 实现的,Redis 整个代码的 main 入口函数也是在 server.c 中。如果你想了解 Redis 是如何开始运行的,那么就可以从 server.c 的 main 函数开始看起。
当然,对于一个网络服务器来说,它还需要提供网络通信功能。Redis 使用了基于事件驱动机制的网络通信框架,涉及的代码文件包括 ae.h/ae.c,ae_epoll.c,ae_evport.c,ae_kqueue.c,ae_select.c。而除了事件驱动网络框架以外,与网络通信相关的功能还包括底层 TCP 网络通信和客户端实现。
Redis 对 TCP 网络通信的 Socket 连接、设置等操作进行了封装,这些封装后的函数实现在 anet.h/anet.c 中。这些函数在 Redis Cluster 创建和主从复制的过程中,会被调用并用于建立 TCP 连接。除此之外,客户端在 Redis 的运行过程中也会被广泛使用,比如实例返回读取的数据、主从复制时在主从库间传输数据、Redis Cluster 的切片实例通信等,都会用到客户端。Redis 将客户端的创建、消息回复等功能,实现在了 networking.c 文件中,如果你想了解客户端的设计与实现,可以重点看下这个代码文件。
除了 deps、src、tests、utils 四个子目录以外,Redis 源码总目录下其实还包含了两个重要的配置文件,一个是 Redis 实例的配置文件 redis.conf,另一个是哨兵的配置文件 sentinel.conf。当你需要查找或修改 Redis 实例或哨兵的配置时,就可以直接定位到源码总目录下。
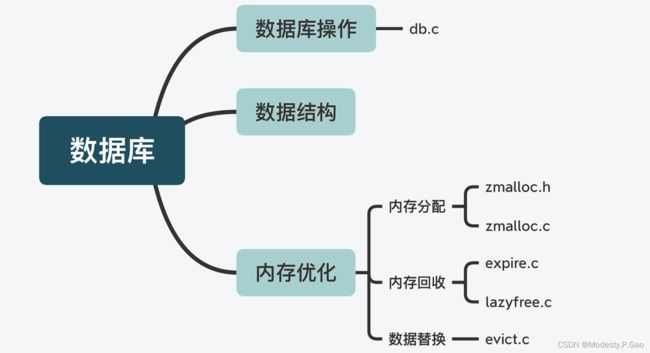
数据库数据类型与操作
Redis 数据库提供了丰富的键值对类型,其中包括了 String、List、Hash、Set 和 Sorted Set 这五种基本键值类型。此外,Redis 还支持位图、HyperLogLog、Geo 等扩展数据类型。
而为了支持这些数据类型,Redis 就使用了多种数据结构来作为这些类型的底层结构。比如,String 类型的底层数据结构是 SDS,而 Hash 类型的底层数据结构包括哈希表和压缩列表。

除了实现了诸多的数据类型以外,Redis 作为数据库,还实现了对键值对的新增、查询、修改和删除等操作接口,这部分功能是在 db.c 文件实现的
Redis 是如何优化内存使用的呢?
实际上,Redis是从三个方面来优化内存使用的,分别是内存分配、内存回收、以及数据替换
首先,在内存分配方面,Redis 支持使用不同的内存分配器,包括 glibc 库提供的默认分配器 tcmalloc、第三方库提供的 jemalloc。Redis 把对内存分配器的封装实现在了 zmalloc.h/zmalloc.c。
其次,在内存回收上,Redis 支持设置过期 key,并针对过期 key 可以使用不同删除策略,这部分代码实现在 expire.c 文件中。同时,为了避免大量 key 删除回收内存,会对系统性能产生影响,Redis 在 lazyfree.c 中实现了异步删除的功能,所以这样,我们就可以使用后台 IO 线程来完成删除,以避免对 Redis 主线程的影响。
最后,针对数据替换,如果内存满了,Redis 还会按照一定规则清除不需要的数据,这也是 Redis 可以作为缓存使用的原因。Redis 实现的数据替换策略有很多种,包括 LRU、LFU 等经典算法。这部分的代码实现在了 evict.c 中。
高可靠性和高可扩展性
首先,虽然 Redis 一般是作为内存数据库来使用的,但是它也提供了可靠性保证,这主要体现在 Redis 可以对数据做持久化保存,并且它还实现了主从复制机制,从而可以提供故障恢复的功能。这部分的代码实现比较集中,主要包括以下两个部分。
数据持久化实现
Redis 的数据持久化实现有两种方式:内存快照 RDB 和 AOF 日志,分别实现在了 rdb.h/rdb.c 和 aof.c 中。
注意,在使用 RDB 或 AOF 对数据库进行恢复时,RDB 和 AOF 文件可能会因为 Redis 实例所在服务器宕机,而未能完整保存,进而会影响到数据库恢复。因此针对这一问题,Redis 还实现了对这两类文件的检查功能,对应的代码文件分别是 redis-check-rdb.c 和 redis-check-aof.c。
主从复制功能实现
Redis 把主从复制功能实现在了 replication.c 文件中。另外你还需要知道的是,Redis 的主从集群在进行恢复时,主要是依赖于哨兵机制,而这部分功能则直接实现在了 sentinel.c 文件中。
其次,与 Redis 实现高可靠性保证的功能类似,Redis 高可扩展性保证的功能,是通过 Redis Cluster 来实现的,这部分代码也非常集中,就是在 cluster.h/cluster.c 代码文件中。
总结
数据类型:
- String(t_string.c、sds.c、bitops.c)
- List(t_list.c、ziplist.c)
- Hash(t_hash.c、ziplist.c、dict.c)
- Set(t_set.c、intset.c)
- Sorted Set(t_zset.c、ziplist.c、dict.c)
- HyperLogLog(hyperloglog.c)
- Geo(geo.c、geohash.c、geohash_helper.c)
- Stream(t_stream.c、rax.c、listpack.c)
全局:
- Server(server.c、anet.c)
- Object(object.c)
- 键值对(db.c)
- 事件驱动(ae.c、ae_epoll.c、ae_kqueue.c、ae_evport.c、ae_select.c、networking.c)
- 内存回收(expire.c、lazyfree.c)
- 数据替换(evict.c)
- 后台线程(bio.c)
- 事务(multi.c)
- PubSub(pubsub.c)
- 内存分配(zmalloc.c)
- 双向链表(adlist.c)
高可用&集群:
- 持久化:RDB(rdb.c、redis-check-rdb.c)、AOF(aof.c、redis-check-aof.c)
- 主从复制(replication.c)
- 哨兵(sentinel.c)
- 集群(cluster.c)
辅助功能:
- 延迟统计(latency.c)
- 慢日志(slowlog.c)
- 通知(notify.c)
- 基准性能(redis-benchmark.c)