开源中文大语言模型整理列表
中文大语言模型整理
Large Language Model (LLM) 即大规模语言模型,是一种基于深度学习的自然语言处理模型,它能够学习到自然语言的语法和语义,从而可以生成人类可读的文本。
所谓"语言模型",就是只用来处理语言文字(或者符号体系)的 AI 模型,发现其中的规律,可以根据提示 (prompt),自动生成符合这些规律的内容。
LLM 通常基于神经网络模型,使用大规模的语料库进行训练,比如使用互联网上的海量文本数据。这些模型通常拥有数十亿到数万亿个参数,能够处理各种自然语言处理任务,如自然语言生成、文本分类、文本摘要、机器翻译、语音识别等。

开源中文 LLM
ChatGLM-6B —— 双语对话语言模型
ChatGLM-6B 是一个开源的、支持中英双语问答的对话语言模型,并针对中文进行了优化。该模型基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。
ChatGLM-6B 使用了和 ChatGLM 相同的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 虽然规模不及千亿模型,但大大降低了推理成本,提升了效率,并且已经能生成相当符合人类偏好的回答。
VisualGLM-6B —— 多模态对话语言模型
VisualGLM-6B 是一个开源的,支持图像、中文和英文的多模态对话语言模型,语言模型基于 ChatGLM-6B,具有 62 亿参数;图像部分通过训练 BLIP2-Qformer 构建起视觉模型与语言模型的桥梁,整体模型共78亿参数。
MOSS —— 支持中英双语的对话大语言模型
MOSS 是一个支持中英双语和多种插件的开源对话语言模型, moss-moon 系列模型具有 160 亿参数,在 FP16 精度下可在单张 A100/A800 或两张 3090 显卡运行,在 INT4/8 精度下可在单张 3090 显卡运行。
MOSS 基座语言模型在约七千亿中英文以及代码单词上预训练得到,后续经过对话指令微调、插件增强学习和人类偏好训练具备多轮对话能力及使用多种插件的能力。
伶荔 (Linly) —— 大规模中文语言模型
相比已有的中文开源模型,伶荔模型具有以下优势:
-
在 32*A100 GPU 上训练了不同量级和功能的中文模型,对模型充分训练并提供强大的 baseline。据知,33B 的 Linly-Chinese-LLAMA 是目前最大的中文 LLaMA 模型。
-
公开所有训练数据、代码、参数细节以及实验结果,确保项目的可复现性,用户可以选择合适的资源直接用于自己的流程中。
-
项目具有高兼容性和易用性,提供可用于 CUDA 和 CPU 的量化推理框架,并支持 Huggingface 格式。
目前公开可用的模型有:
-
Linly-Chinese-LLaMA:中文基础模型,基于 LLaMA 在高质量中文语料上增量训练强化中文语言能力,现已开放 7B、13B 和 33B 量级,65B 正在训练中。
-
Linly-ChatFlow:中文对话模型,在 400 万指令数据集合上对中文基础模型指令精调,现已开放 7B、13B 对话模型。
-
Linly-ChatFlow-int4 :ChatFlow 4-bit 量化版本,用于在 CPU 上部署模型推理。
进行中的项目:
- Linly-Chinese-BLOOM:基于 BLOOM 中文增量训练的中文基础模型,包含 7B 和 175B 模型量级,可用于商业场景。
Chinese-Vicuna —— 基于 LLaMA 的中文大语言模型
Chinese-Vicuna 是一个中文低资源的 LLaMA+Lora 方案。
项目包括
- finetune 模型的代码
- 推理的代码
- 仅使用 CPU 推理的代码 (使用 C++)
- 下载 / 转换 / 量化 Facebook llama.ckpt 的工具
- 其他应用
Chinese-LLaMA-Alpaca —— 中文 LLaMA & Alpaca 大模型
Chinese-LLaMA-Alpaca 包含中文 LLaMA 模型和经过指令微调的 Alpaca 大型模型。
这些模型在原始 LLaMA 的基础上,扩展了中文词汇表并使用中文数据进行二次预训练,从而进一步提高了对中文基本语义理解的能力。同时,中文 Alpaca 模型还进一步利用中文指令数据进行微调,明显提高了模型对指令理解和执行的能力。
ChatYuan —— 对话语言大模型
ChatYuan 是一个支持中英双语的功能型对话语言大模型。ChatYuan-large-v2 使用了和 v1 版本相同的技术方案,在微调数据、人类反馈强化学习、思维链等方面进行了优化。
ChatYuan-large-v2 是 ChatYuan 系列中以轻量化实现高质量效果的模型之一,用户可以在消费级显卡、 PC 甚至手机上进行推理(INT4 最低只需 400M )。
华驼 (HuaTuo) —— 基于中文医学知识的 LLaMA 微调模型
华驼 (HuaTuo) 是基于中文医学知识的 LLaMA 微调模型。
此项目开源了经过中文医学指令精调 / 指令微调 (Instruct-tuning) 的 LLaMA-7B 模型。通过医学知识图谱和 GPT3.5 API 构建了中文医学指令数据集,并在此基础上对 LLaMA 进行了指令微调,提高了 LLaMA 在医疗领域的问答效果。
鹏程·盘古α —— 中文预训练语言模型
「鹏程·盘古α」是业界首个 2000 亿参数以中文为核心的预训练生成语言模型,目前开源了两个版本:鹏程·盘古α和鹏程·盘古α增强版,并支持NPU和GPU两个版本,支持丰富的场景应用,在知识问答、知识检索、知识推理、阅读理解等文本生成领域表现突出,具备较强的少样本学习的能力。
基于盘古系列大模型提供大模型应用落地技术帮助用户高效的落地超大预训练模型到实际场景。整个框架特点如下:
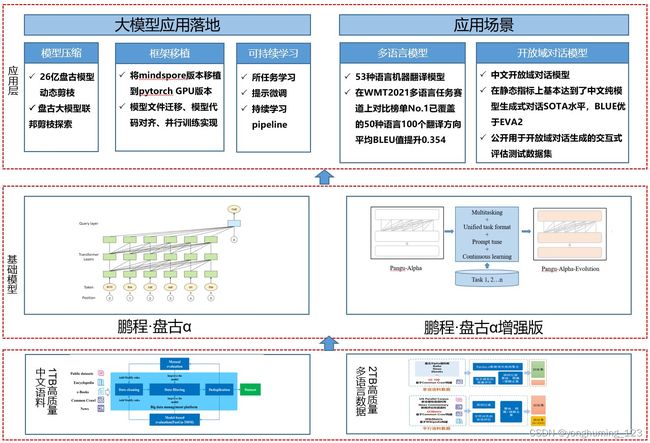
主要有如下几个核心模块:
-
数据集:从开源开放数据集、common crawl 数据集、电子书等收集近 80TB 原始语料,构建了约 1.1TB 的高质量中文语料数据集、53 种语种高质量单、双语数据集 2TB。
-
基础模块:提供预训练模型库,支持常用的中文预训练模型,包括鹏程・盘古 α、鹏程・盘古 α 增强版等。
-
应用层:支持常见的 NLP 应用比如多语言翻译、开放域对话等,支持预训练模型落地工具,包括模型压缩、框架移植、可持续学习,助力大模型快速落地。
鹏程·盘古对话生成大模型
鹏程・盘古对话生成大模型 (PanGu-Dialog)。
PanGu-Dialog 是以大数据和大模型为显著特征的大规模开放域对话生成模型,充分利用大规模预训练语言模型的知识和语言能力,构建可控、可靠可信、有智慧的自然人机对话模型。主要特性如下:
- 首次提出对话智慧度以探索对话模型的逻辑推理、数据计算、联想、创作等方面的能力。
- 构建了覆盖领域最广 (据我们所知) 的开放域交互式对话评估数据集 PGCED,12 个领域,并在知识性、安全性、智慧程度等方面制作了针对性的评测数据。
- 基于预训练 + 持续微调的学习策略融合大规模普通文本和多种对话数据训练而成,充分利用训练语言模型语言能力和知识,高效构建强大的对话模型。
- 在各项指标上达到了中文纯模型生成式对话 SOTA 水平,在知识性和信息量方面优势明显,但安全性、可靠、可信、可控、智慧等方面的提升并不明显。
- 目前生成式对话仍处于较低水平,与人类对话能力存在明显的差距,后续将在现有基础上针对不同的维度不断优化迭代,不断进步。
悟道 —— 双语多模态大语言模型
“悟道” 是双语多模态预训练模型,规模达到 1.75 万亿参数。项目现有 7 个开源模型成果。
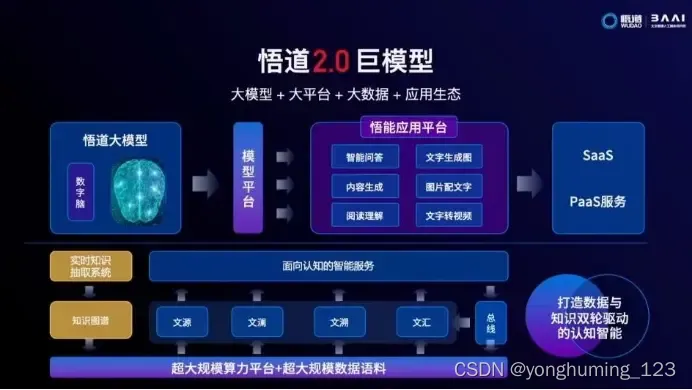
图文类
-
CogView
CogView 参数量为 40 亿,模型可实现文本生成图像,经过微调后可实现国画、油画、水彩画、轮廓画等图像生成。目前在公认 MS COCO 文生图任务上取得了超过 OpenAI DALL・E 的成绩,获得世界第一。
-
BriVL
BriVL (Bridging Vision and Language Model) 是首个中文通用图文多模态大规模预训练模型。BriVL 模型在图文检索任务上有着优异的效果,超过了同期其他常见的多模态预训练模型(例如 UNITER、CLIP)。
文本类
-
GLM
GLM 是以英文为核心的预训练语言模型系列,基于新的预训练范式实现单一模型在语言理解和生成任务方面取得了最佳结果,并且超过了在相同数据量进行训练的常见预训练模型(例如 BERT,RoBERTa 和 T5),目前已开源 1.1 亿、3.35 亿、4.10 亿、5.15 亿、100 亿参数规模的模型。
-
CPM
CPM 系列模型是兼顾理解与生成能力的预训练语言模型系列,涵盖中文、中英双语多类模型,目前已开源 26 亿、110 亿和 1980 亿参数规模的模型。
-
Transformer-XL
Transformer-XL 是以中文为核心的预训练语言生成模型,参数规模为 29 亿,目前可支持包括文章生成、智能作诗、评论 / 摘要生成等主流 NLG 任务。
-
EVA
EVA 是一个开放领域的中文对话预训练模型,是目前最大的汉语对话模型,参数量达到 28 亿,并且在包括不同领域 14 亿汉语的悟道对话数据集(WDC)上进行预训练。
-
Lawformer
Lawformer 是世界首创法律领域长文本中文预训练模型,参数规模达到 1 亿。
蛋白质类
-
ProtTrans
ProtTrans 是国内最大的蛋白质预训练模型,参数总量达到 30 亿。
BBT-2 —— 120 亿参数大语言模型
BBT-2 是包含 120 亿参数的通用大语言模型,在 BBT-2 的基础上训练出了代码,金融,文生图等专业模型。基于 BBT-2 的系列模型包括:
-
BBT-2-12B-Text:120 亿参数的中文基础模型
-
BBT-2.5-13B-Text: 130 亿参数的中文+英文双语基础模型
-
BBT-2-12B-TC-001-SFT 经过指令微调的代码模型,可以进行对话
-
BBT-2-12B-TF-001 在 120 亿模型上训练的金融模型,用于解决金融领域任务
-
BBT-2-12B-Fig:文生图模型
-
BBT-2-12B-Science 科学论文模型
BELLE —— 开源中文对话大模型
BELLE: Be Everyone’s Large Language model Engine(开源中文对话大模型)
本项目目标是促进中文对话大模型开源社区的发展,愿景做能帮到每一个人的 LLM Engine。现阶段本项目基于一些开源预训练大语言模型(如 BLOOM),针对中文做了优化,模型调优仅使用由 ChatGPT 生产的数据(不包含任何其他数据)。