关于 djangorestframework记录一篇:Serializer序列化、反序列化
码云https://gitee.com/white_bone_dreamer/drf0.git学习过程
一、django drf快速入门:django项目创建+project独立虚拟环境创建
#----------------------pycharm 打开一个新建的文件夹
#----------------------安装依赖包virtualenv:创建虚拟环境的工具包
pip install virtualenv
#----------------------创建一个virtualenv来隔离我们本地的包依赖关系
virtualenv venv
#----------------------windows下激活(即:使用)虚拟环境
venv\Scripts\activate #在linux中,source env/bin/activate
#----------------------在创建的虚拟环境中安装Django 和 Django REST framework
#备注“在虚拟环境中”的标识:Terminal里面project目录前显示类似:(venv)
pip install Django
pip install djangorestframework
#----------------------创建一个新项目和一个单个应用
#注意后面的:.#加点不加点主要区别在于工程目录下会否有一个同名文件
django-admin.py startprojct quickstart .
django-admin.py startapp app01
#----------------------setting配置
#关于 djangorestframework,相比于django,还需要在settings.py文件中的INSTALLED_APPS中,添加:
'rest_framework',
即:
INSTALLED_APPS = [
……
'rest_framework',
……
]同步数据库:前提:关于django连接mysql以及需要修改的配置、报错解决等
python manage.py makemigrations
python manage.py migrate创建一个初始用户-超级管理员admin-xxx,密码为 123456
python manage.py createsuperuser二、Serializers.py创建序列化器
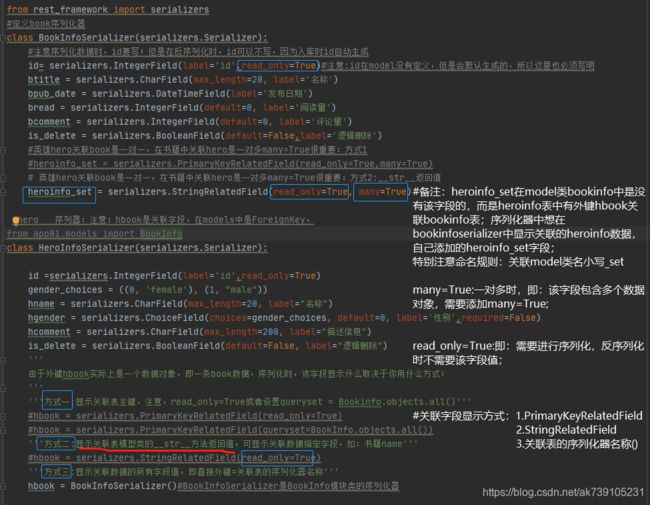
注明:Serializers序列化器是基于model的,model中一个class对应数据库一个表,同时也对应一个Serializers(序列化器);定义序列化器原则:
定义序列化器:
0,规范命名:Model类名拼接Serializer(eg:有一个model类:BookInfo,其序列化器命名:BookInfoSerializer)
1,定义序列化器类,继承自Serializer或者ModelSerializer等
2,和model类的字段名称一样
3,和mode类的字段类型一样
4,和model类的字段选项一样(备注:在models中字段的选项verbose_name在serializers中使用label替代)注意:
1.model类中可能不含id字段(主键),如果序列化字段需要包含ID字段,需要加上read_only=True项;
2.model类之间(或者说表与表之间)有外键关联关系(具体数据可能是一对一、也可是一对多、或多对一);如果是一对多,需要在对应序列化器字段上加上mang=True项;
3.表与表之间关联,对应外键的序列化,有三种显示方式:(1.显示主键;2.显示model类中__str__函数的返回值;3.显示关联数据的所有字段值)
4.write_only=True,read_only=True用来修饰某一字段时;分别表示反序列化要写但序列化不包含该字段、只可序列化但反序列化不用传该字段;截图:
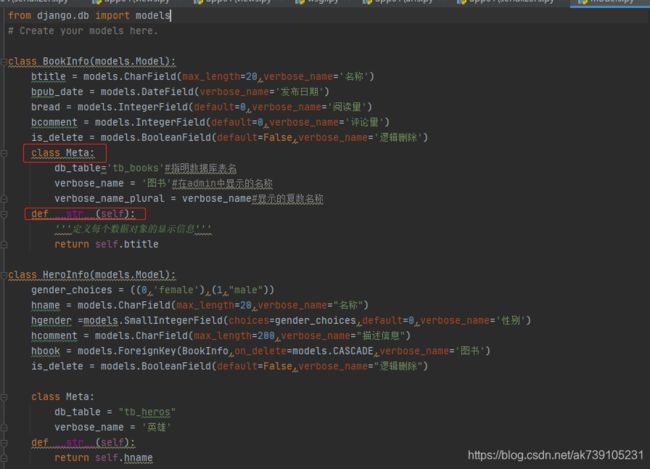
附带model中,关于模型类的Meta()、__str__()截图:
三、序列化
DRF序列化:将数据对象转换为json格式(或dict)数据,关键字:instance和many=True;
补充:下面是在view.py中的class,继承View
from django.views import View使用class继承View,在urls.py中,也需要相应变化:

下面是序列化截图:

四、反序列化(校验+入库)
DRF反序列化:将json格式(或dict)的数据转换为model数据对象,即方便入库,入库又需要校验字段。关键字:data
4.1 数据校验
字段校验包括:数据类型、数据最大值、数据最小值、数据长度等,即校验通过数据是绝对满足model定义的字段限制的,即可以入库;
views.py文件中,使用类似如下代码时(is_valid()),会根据serializers.py文件(4.2;4.3)的校验方式对数据字段进行校验;
from app03.serializers import BookInfoSerializer
#1.准备数据
book_dict ={
"btitle": "冷凝娇",
"bpub_date": "2020-11-17",
"bread": 100110,
"bcomment": 100
}
#2.创建序列化器,校验
serializer=BookInfoSerializer(data=book_dict)#注意反序列化与序列化不同,序列化参数是instance,反序列化是data,如果是修改一条数据则需要instance、data都传入;instance表示要修改的数据,data表示修改成的内容;
#serializer.is_valid()
serializer.is_valid(raise_exception=True)#传入raise_exception=True后,校验不通过直接报错告知你哪里报错
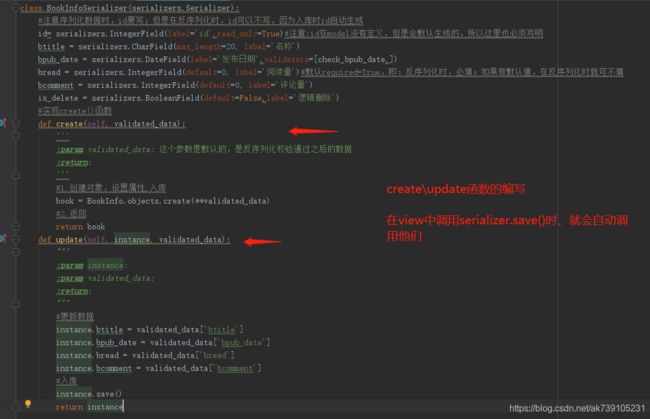
#3.入库-------》数据入库save()方法的使用,必须是serializers中对应序列化class中编写了create()函数
serializer.save()
******************************************************************************************
from app04.serializers import BookInfoSerializer
from app04.models import BookInfo
from django.views import View
# #1.准备数据
# book_dict ={
# "btitle": "天下无敌",
# "bpub_date": "2020-11-17",
# "bread": 888110,
# "bcomment": 8888
# }
# book = BookInfo.objects.get(id=9)
# #2.创建序列化器,校验
# serializer=BookInfoSerializer(instance=book,data=book_dict)#注意:这里instance是序列化目标,data是外界传入的,需要反序列化;
# #这里同时传入instance,data 表示:你即将更新数据,下面的save就会找到update函数,并执行
#
# #serializer.is_valid()
# serializer.is_valid(raise_exception=True)
#
# #3.入库-------》数据入库save()方法的使用,必须是serializers中对应序列化class中编写了update()函数
# serializer.save()4.2 对单一字段的校验
#格式固定:
def validate_要验证字段(self,value):
'''
校验内容
'''
********************************************************************
eg:serializers.py文件中
class BookInfoSerializer(serializers.Serializer):
id= serializers.IntegerField(label='id',read_only=True)
btitle = serializers.CharField(max_length=20, label='名称')
bpub_date = serializers.DateField(label='发布日期',validators=[check_bpub_date,])
bread = serializers.IntegerField(default=0, label='阅读量')
bcomment = serializers.IntegerField(default=0, label='评论量')
is_delete = serializers.BooleanField(default=False,label='逻辑删除')
def validate_btitle(self, value):#value就是函数validate_btitle对应字段btitle
if "冷" not in value:
raise serializers.ValidationError("书籍名不包含冷")
return value
validate_btitle校验函数是校验字段btitle,且该函数是写在BookInfoSerializer序列化类中的;4.3 对多字段的校验
#格式固定:
def validate(self,attrs):
'''
1.获取attrs中的需要校验的字段的值
2.校验内容
'''
****************************************************************
eg:serializers.py文件中
class BookInfoSerializer(serializers.Serializer):
id= serializers.IntegerField(label='id',read_only=True)
btitle = serializers.CharField(max_length=20, label='名称')
bpub_date = serializers.DateField(label='发布日期',validators=[check_bpub_date,])
bread = serializers.IntegerField(default=0, label='阅读量')
bcomment = serializers.IntegerField(default=0, label='评论量')
is_delete = serializers.BooleanField(default=False,label='逻辑删除')
def validate(self, attrs):#attrs就是外界传入的json
#1.获取阅读量,评论量
bread = attrs['bread']
bcomment = attrs['bcomment']
#2.判断
if bcomment > bread:
raise serializers.ValidationError("评论量大于了阅读量")
#3.返回
return attrs
validate函数是对attrs数据中的多字段的验证,attrs就是即将反序列化的json数据,该函数是写在序列化器内的4.4 自定义校验

4.5 create\update函数的创建