缓存淘汰算法
序言
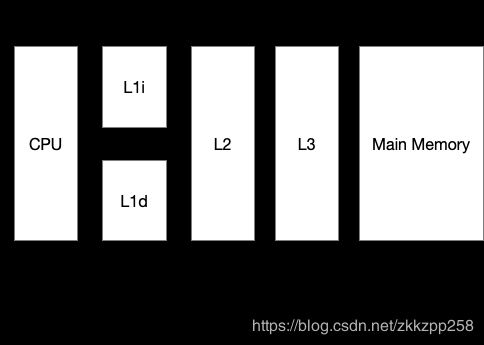
缓存是指可以进行高速数据交换的存储器,它先于内存与CPU交换数据,因此速率很快。前面提到过,计算机中,所有的运算操作都是由CPU的寄存器来完成的,CPU指令的执行过程需要涉及数据的读取和写入操作,CPU所能访问的所有数据只能是计算机的主存(通常RAM)。CPU和主存两边的速度严重的不对等,所以才有中间增加缓存的设计,其中L3、L2、L1分别为三级缓存、二级缓存、一级缓存,速度依次递增。
详细参看:CPU Cache模型_四问四不知的博客-CSDN博客_cpu缓存模型
做涉及数据库开发时,使用缓存提高性能是一个比较常用的方法。除了可以设置过期时间以外,当缓存满时,我们需要释放一定的资源来插入新的缓存,那么缓存淘汰算法是我们需要考虑到的。如下图(缓存调度流程),下面就介绍几种常见的缓存淘汰算法。
这里顺带提一下为什么要设置过期时间?
Redis数据存储是基于内存的,如果不设置过期时间,所有存储的数据都会积压在内存,直到内存满,触发类似LRU这样的缓存淘汰策略,会让Redis处理效率变慢。自己设置一个合理的过期时间则会在自己所设置的特定时间内存在于内存,超过过期时间则释放内存。
LRU(Least Recently Used)最近最少使用算法
淘汰最近不使用的页面。这个应该是我们听的比较多的,先来看一下leetCode的LRU算法题来加深对它的理解:力扣
实现LRU的关键点:
- 模式识别:键(key)和值(value)——哈希表(O(1)时间内通过key找到value)
- 改变数据访问时间:get和put操作后的数据需要设置为最新访问数据——能随机访问,且把该数据插入到头部或者尾部
public class LRUCache extends LinkedHashMap {
private int capacity;
public LRUCache(int capacity) {
super(capacity, 0.75F, true);
this.capacity = capacity;
}
public int get(int key) {
return super.getOrDefault(key, -1);
}
public void put(int key, int value) {
super.put(key, value);
}
/**
* 重写LinkedHashMap的removeEldestEntry方法,当前元素个数大于容量则返回true,
* 则在afterNodeInsertion方法里才会移除最老的元素
* @param eldest
* @return
*/
@Override
protected boolean removeEldestEntry(Map.Entry eldest) {
return size() > capacity;
}
/**
* 直接使用LinkedHashMap的原生方法来实现
* @param args
*/
public static void main(String[] args) {
LRUCache cache = new LRUCache(2 /* 缓存容量 */);
cache.put(1, 1);
cache.put(2, 2);
System.out.println(cache.get(1)); // 返回 1
cache.put(3, 3); // 该操作会使得密钥 2 作废
System.out.println(cache.get(2)); // 返回 -1 (未找到)
cache.put(4, 4); // 该操作会使得密钥 1 作废
System.out.println(cache.get(1)); // 返回 -1 (未找到)
System.out.println(cache.get(3)); // 返回 3
System.out.println(cache.get(4)); // 返回 4
}
} 上面是通过LinkedHashMap来实现LRU页面置换算法,前面也提到过,Redisson提供了基于Redis的以LRU为驱逐策略的分布式LRU有界映射对象。顾名思义,分布式LRU有界映射允许通过对其中元素按使用时间排序处理的方式,主动移除超过规定容量限制的元素。那来看一下Redis的效果是否也如预期。
@Slf4j
public class UserLogicTest extends BaseTest {
//注入Redis客户端
@Resource
private RedissonClient redissonClient;
@Test
public void LRUTest() {
RMapCache map = redissonClient.getMapCache("LRUCache");
map.trySetMaxSize(2);
map.put(1,1);
map.put(2,2);
System.out.println(map.get(1)); //1
map.put(3,3);
System.out.println(map.get(2)); //null
map.put(4,4);
System.out.println(map.get(1)); //null
System.out.println(map.get(3)); //3
System.out.println(map.get(4)); //4
}
} 可以看到测试结果符合预期。并且在Redis服务器中,存放了三个数据,LRUCache(redisson_options)放设置的最大容量,LRUCache放元素集合,redission_map_cache_last_access_set:(LRUCache)维护最后访问元素集合。有兴趣的可以进一步细细研究。

LFU(Least Frequently Used)最近频次最少算法
淘汰使用次数最少的页面。同样,我们先拿一道leetCode题目来熟悉算法:力扣
实现LFU的关键点:
- 模式识别:键(key)和值(value)——利用散列表实现O(1)的快速索引
- 排序要求:使用次数最少的排在前面,使用次数相同的情况下,最早使用的排在前面。(维护最小值)
- 解题方法:1)散列表+平衡二叉树 ;2)双散列表
public class LFUCache {
static class Node implements Comparable {
//使用频率
int cnt;
//最近一次使用时间
int time;
//键值对
int key, value;
Node(int cnt, int time, int key, int value) {
this.cnt = cnt;
this.time = time;
this.key = key;
this.value = value;
}
/**
* 比较两个节点的使用频率和最近使用时间是否相等
*
* @param anObject 输入对象
* @return 相等返回true,否则返回false
*/
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof Node) {
Node rhs = (Node) anObject;
return this.cnt == rhs.cnt && this.time == rhs.time;
}
return false;
}
/**
* 比较当前节点 和 参数节点
*
* @param rhs 输入节点
* @return 使用频率相同时返回 当前节点和输入节点使用时间差,不同则返回 当前节点和输入节点使用频次差
*/
public int compareTo(Node rhs) {
return cnt == rhs.cnt ? time - rhs.time : cnt - rhs.cnt;
}
/**
* HashCode方法
*
* @return
*/
public int hashCode() {
return cnt * 1000000007 + time;
}
}
//容量和时间戳
private int capacity, time;
//哈希表
private Map key_table;
//平衡二叉树,存最近最少使用的节点
private TreeSet S;
public LFUCache(int capacity) {
this.capacity = capacity;
this.time = 0;
this.key_table = new HashMap<>();
this.S = new TreeSet<>();
}
public int get(int key) {
if (capacity == 0) {
return -1;
}
if (!key_table.containsKey(key)) {
return -1;
}
// 从哈希表中得到旧的缓存
Node cache = key_table.get(key);
// 从平衡二叉树中删除旧的缓存
S.remove(cache);
// 将旧缓存更新
cache.cnt += 1;
cache.time = ++time;
// 将新缓存重新放入哈希表和平衡二叉树中
S.add(cache);
key_table.put(key, cache);
return cache.value;
}
public void put(int key, int value) {
if (capacity == 0) {
return;
}
if (!key_table.containsKey(key)) {
// 如果到达缓存容量上限
if (key_table.size() == capacity) {
// 从哈希表和平衡二叉树中删除最近最少使用的缓存
key_table.remove(S.first().key);
S.remove(S.first());
}
// 创建新的缓存
Node cache = new Node(1, ++time, key, value);
// 将新缓存放入哈希表和平衡二叉树中
S.add(cache);
key_table.put(key, cache);
} else {
Node cache = key_table.get(key);
S.remove(cache);
cache.cnt += 1;
cache.time = ++time;
//更新key对应的value值
cache.value = value;
S.add(cache);
key_table.put(key, cache);
}
}
public static void main(String[] args) {
// cnt(x) = 键 x 的使用计数
// cache=[] 将显示最后一次使用的顺序(最左边的元素是最近的)
LFUCache lFUCache = new LFUCache(2);
lFUCache.put(1, 1); // cache=[1,_], cnt(1)=1
lFUCache.put(2, 2); // cache=[2,1], cnt(2)=1, cnt(1)=1
System.out.println(lFUCache.get(1)); // 返回 1
// cache=[1,2], cnt(2)=1, cnt(1)=2
lFUCache.put(3, 3); // 去除键 2 ,因为 cnt(2)=1 ,使用计数最小
// cache=[3,1], cnt(3)=1, cnt(1)=2
System.out.println(lFUCache.get(2)); // 返回 -1(未找到)
System.out.println(lFUCache.get(3)); // 返回 3
// cache=[3,1], cnt(3)=2, cnt(1)=2
lFUCache.put(4, 4); // 去除键 1 ,1 和 3 的 cnt 相同,但 1 最久未使用
// cache=[4,3], cnt(4)=1, cnt(3)=2
System.out.println(lFUCache.get(1)); // 返回 -1(未找到)
System.out.println(lFUCache.get(3)); // 返回 3
// cache=[3,4], cnt(4)=1, cnt(3)=3
System.out.println(lFUCache.get(4)); // 返回 4
// cache=[3,4], cnt(4)=2, cnt(3)=3
}
} FIFO(First In First Out)先入先出算法
淘汰最先进来的页面。
ARC(Adjustable Replacement Cache)自适应缓存替换算法
同时跟踪记录LFU和LRU,以及驱逐缓存条目,来获得可用缓存的最佳使用。
MRU(Most Recently Used)最近最常使用算法
最先移除最近最常使用的条目。一个MRU算法擅长处理一个条目越久,越容易被访问的情况。
参考链接:
缓存淘汰算法系列(二) - 转瞬之夏 - 博客园