10- 天猫用户复购预测 (机器学习集成算法) (项目十) *
项目难点
- merchant: 商人
- 重命名列名: user_log.rename(columns={'seller_id':'merchant_id'}, inplace=True)
- 数据类型转换: user_log['item_id'] = user_log['item_id'].astype('int32')
- 主要使用方法: xgboost, lightbm
- 竞赛地址: 天猫复购预测之挑战Baseline_学习赛_天池大赛-阿里云天池
- 排名: 448/9361 score: 0.680989
项目简介:
阿里巴巴天池天猫复购预测的机器学习项目, 使用数据分析, 通过机器学习中的线性分类算法, 进行建模, 从而预测消费者行为, 复购情况 .
- 数据分析
- 特征工程
- 算法使用
- 算法集成
1 数据处理
1.1 模型导入
import gc # 垃圾回收
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
# 导入分析库
# 数据拆分
from sklearn.model_selection import train_test_split
# 同分布数据拆分
from sklearn.model_selection import StratifiedGroupKFold
import lightgbm as lgb
import xgboost as xgb1.2 加载数据
%%time
# 加载数据
# 用户行为日志
user_log = pd.read_csv('./data_format1/user_log_format1.csv', dtype = {'time_stamp':'str'})
# 用户画像
user_info = pd.read_csv('./data_format1/user_info_format1.csv')
# 训练数据和测试数据
train_data = pd.read_csv('./data_format1/train_format1.csv')
test_data = pd.read_csv('./data_format1/test_format1.csv')1.3 查看数据
print('---data shape---')
for data in [user_log, user_info, train_data, test_data]:
print(data.shape) 
print('---data info ---')
for data in [user_log, user_info, train_data, test_data]:
print(data.info()) 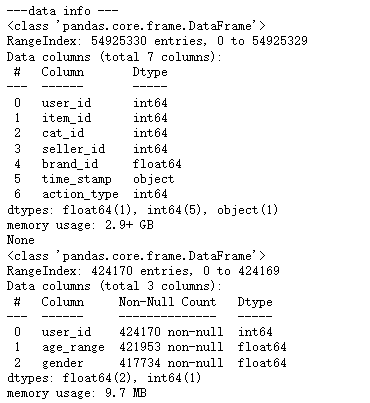
display(user_info.head()) 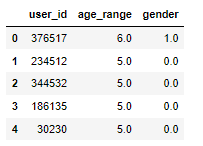
display(train_data.head(),test_data.head()) 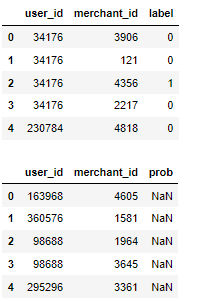
1.4 数据集成
train_data['origin'] = 'train'
test_data['origin'] = 'test'
# 集成
all_data = pd.concat([train_data, test_data], ignore_index=True, sort=False)
# prob测试数据中特有的一列
all_data.drop(['prob'], axis=1, inplace=True) # 删除概率这一列
display(all_data.head(),all_data.shape) 
# 连接user_info表,通过user_id关联
all_data = all_data.merge(user_info, on='user_id', how='left')
display(all_data.shape,all_data.head()) 
# 使用 merchant_id(原列名seller_id)
user_log.rename(columns={'seller_id':'merchant_id'}, inplace=True)del train_data,test_data,user_info
gc.collect()1.5 数据类型转换
%%time
display(user_log.info()) 
%%time
display(user_log.head()) 
%%time
# 用户行为数据类型转换
user_log['user_id'] = user_log['user_id'].astype('int32')
user_log['merchant_id'] = user_log['merchant_id'].astype('int32')
user_log['item_id'] = user_log['item_id'].astype('int32')
user_log['cat_id'] = user_log['cat_id'].astype('int32')
user_log['brand_id'].fillna(0, inplace=True)
user_log['brand_id'] = user_log['brand_id'].astype('int32')
user_log['time_stamp'] = pd.to_datetime(user_log['time_stamp'], format='%H%M')
user_log['action_type'] = user_log['action_type'].astype('int32')
display(user_log.info(),user_log.head()) 
display(all_data.isnull().sum()) 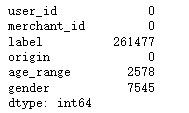
# 缺失值填充
all_data['age_range'].fillna(0, inplace=True)
all_data['gender'].fillna(2, inplace=True)
all_data.isnull().sum() 
all_data.info() 
all_data['age_range'] = all_data['age_range'].astype('int8')
all_data['gender'] = all_data['gender'].astype('int8')
all_data['label'] = all_data['label'].astype('str')
all_data['user_id'] = all_data['user_id'].astype('int32')
all_data['merchant_id'] = all_data['merchant_id'].astype('int32')
all_data.info() 
1.6 用户特征工程(5min)
%%time
##### 特征处理
##### User特征处理
groups = user_log.groupby(['user_id'])
# 用户交互行为数量 u1
temp = groups.size().reset_index().rename(columns={0:'u1'})
all_data = all_data.merge(temp, on='user_id', how='left')
# 细分
# 使用 agg 基于列的聚合操作,统计唯一值个数 item_id, cat_id, merchant_id, brand_id
# 用户,交互行为:点了多少商品呢?
temp = groups['item_id'].agg([('u2', 'nunique')]).reset_index()
all_data = all_data.merge(temp, on='user_id', how='left')
# 用户,交互行为,具体统计:类目多少
temp = groups['cat_id'].agg([('u3', 'nunique')]).reset_index()
all_data = all_data.merge(temp, on='user_id', how='left')
temp = groups['merchant_id'].agg([('u4', 'nunique')]).reset_index()
all_data = all_data.merge(temp, on='user_id', how='left')
temp = groups['brand_id'].agg([('u5', 'nunique')]).reset_index()
all_data = all_data.merge(temp, on='user_id', how='left')
# 购物时间间隔特征 u6 按照小时
temp = groups['time_stamp'].agg([('F_time', 'min'), ('B_time', 'max')]).reset_index()
temp['u6'] = (temp['B_time'] - temp['F_time']).dt.seconds/3600
all_data = all_data.merge(temp[['user_id', 'u6']], on='user_id', how='left')
# 统计操作类型为0,1,2,3的个数
temp = groups['action_type'].value_counts().unstack().reset_index().rename(
columns={0:'u7', 1:'u8', 2:'u9', 3:'u10'})
all_data = all_data.merge(temp, on='user_id', how='left')
del temp,groups
gc.collect()all_data.head() 
1.7 店铺特征工程(5min)
%%time
##### 商家特征处理
groups = user_log.groupby(['merchant_id'])
# 商家被交互行为数量 m1
temp = groups.size().reset_index().rename(columns={0:'m1'})
all_data = all_data.merge(temp, on='merchant_id', how='left')
# 统计商家被交互的 user_id, item_id, cat_id, brand_id 唯一值
temp = groups['user_id', 'item_id', 'cat_id', 'brand_id'].nunique().reset_index().rename(
columns={
'user_id':'m2',
'item_id':'m3',
'cat_id':'m4',
'brand_id':'m5'})
all_data = all_data.merge(temp, on='merchant_id', how='left')
# 统计商家被交互的 action_type 唯一值
temp = groups['action_type'].value_counts().unstack().reset_index().rename(
columns={0:'m6', 1:'m7', 2:'m8', 3:'m9'})
all_data = all_data.merge(temp, on='merchant_id', how='left')
del temp
gc.collect()display(all_data.tail()) 
1.8 用户和店铺联合特征工程(4min)
%%time
##### 用户+商户特征
groups = user_log.groupby(['user_id', 'merchant_id'])
# 用户在不同商家交互统计
temp = groups.size().reset_index().rename(columns={0:'um1'})
all_data = all_data.merge(temp, on=['user_id', 'merchant_id'], how='left')
# 统计用户在不同商家交互的 item_id, cat_id, brand_id 唯一值
temp = groups['item_id', 'cat_id', 'brand_id'].nunique().reset_index().rename(
columns={
'item_id':'um2',
'cat_id':'um3',
'brand_id':'um4'})
all_data = all_data.merge(temp, on=['user_id', 'merchant_id'], how='left')
# 统计用户在不同商家交互的 action_type 唯一值
temp = groups['action_type'].value_counts().unstack().reset_index().rename(
columns={
0:'um5',
1:'um6',
2:'um7',
3:'um8'})
all_data = all_data.merge(temp, on=['user_id', 'merchant_id'], how='left')
# 统计用户在不同商家购物时间间隔特征 um9 按照小时
temp = groups['time_stamp'].agg([('F_time', 'min'), ('B_time', 'max')]).reset_index()
temp['um9'] = (temp['B_time'] - temp['F_time']).dt.seconds/3600
all_data = all_data.merge(temp[['user_id','merchant_id','um9']], on=['user_id', 'merchant_id'], how='left')
del temp,groups
gc.collect()display(all_data.head()) 
1.9 购买点击比
all_data['r1'] = all_data['u9']/all_data['u7'] # 用户购买点击比
all_data['r2'] = all_data['m8']/all_data['m6'] # 商家购买点击比
all_data['r3'] = all_data['um7']/all_data['um5'] # 不同用户不同商家购买点击比
display(all_data.head()) 
1.10 空数据填充
display(all_data.isnull().sum()) 
all_data.fillna(0, inplace=True)
all_data.isnull().sum()1.11 年龄性别类别型转换
all_data['age_range'] 
%%time
# 修改age_range字段名称为 age_0, age_1, age_2... age_8
# 独立编码
temp = pd.get_dummies(all_data['age_range'], prefix='age')
display(temp.head(10))
all_data = pd.concat([all_data, temp], axis=1) 
# 性别转换
temp = pd.get_dummies(all_data['gender'], prefix='g')
all_data = pd.concat([all_data, temp], axis=1) # 列进行合并
# 删除原数据
all_data.drop(['age_range', 'gender'], axis=1, inplace=True)
del temp
gc.collect()all_data.head() 
1.12 数据存储
%%time
# train_data、test-data
train_data = all_data[all_data['origin'] == 'train'].drop(['origin'], axis=1)
test_data = all_data[all_data['origin'] == 'test'].drop(['label', 'origin'], axis=1)
train_data.to_csv('train_data.csv')
test_data.to_csv('test_data.csv')2 算法建模预测
# 训练数据和目标值
train_X, train_y = train_data.drop(['label'], axis=1), train_data['label']
# 数据拆分保留20%作为测试数据
X_train, X_valid, y_train, y_valid = train_test_split(train_X, train_y, test_size=.2)2.1 LGB 模型
def lgb_train(X_train, y_train, X_valid, y_valid, verbose=True):
model_lgb = lgb.LGBMClassifier(
max_depth=10, # 8 # 树最大的深度
n_estimators=5000, # 集成算法,树数量
min_child_weight=100,
colsample_bytree=0.7, # 特征筛选
subsample=0.9, # 样本采样比例
learning_rate=0.1) # 学习率
model_lgb.fit(
X_train,
y_train,
eval_metric='auc',
eval_set=[(X_train, y_train), (X_valid, y_valid)],
verbose=verbose, # 是否打印输出训练过程
early_stopping_rounds=10) # 早停,等10轮决策,评价指标不在变化,停止
print(model_lgb.best_score_['valid_1']['auc'])
return model_lgbX_train 
model_lgb = lgb_train(X_train.values, y_train, X_valid.values, y_valid, verbose=True) 
%%time
prob = model_lgb.predict_proba(test_data.values) # 预测
submission = pd.read_csv('./data_format1/test_format1.csv')
# 复购的概率
submission['prob'] = pd.Series(prob[:,1]) # 预测数据赋值给提交数据
display(submission.head())
submission.to_csv('submission_lgb.csv', index=False)
del submission
gc.collect() 
2.2 XGB 模型
def xgb_train(X_train, y_train, X_valid, y_valid, verbose=True):
model_xgb = xgb.XGBClassifier(
max_depth=10, # raw8
n_estimators=5000,
min_child_weight=300,
colsample_bytree=0.7,
subsample=0.9,
learing_rate=0.1)
model_xgb.fit(
X_train,
y_train,
eval_metric='auc',
eval_set=[(X_train, y_train), (X_valid, y_valid)],
verbose=verbose,
early_stopping_rounds=10) # 早停法,如果auc在10epoch没有进步就stop
print(model_xgb.best_score)
return model_xgb模型训练
model_xgb = xgb_train(X_train, y_train, X_valid, y_valid, verbose=False)模型预测
%%time
prob = model_xgb.predict_proba(test_data)
submission = pd.read_csv('./data_format1/test_format1.csv')
submission['prob'] = pd.Series(prob[:,1])
submission.to_csv('submission_xgb.csv', index=False)
display(submission.head())
del submission
gc.collect()3 交叉验证多轮建模
# 构造训练集和测试集
def get_train_test_datas(train_df,label_df):
skv = StratifiedKFold(n_splits=10, shuffle=True)
trainX = []
trainY = []
testX = []
testY = []
# 索引:训练数据索引train_index,目标值的索引test_index
for train_index, test_index in skv.split(X=train_df, y=label_df): # 10轮for循环
train_x, train_y, test_x, test_y = train_df.iloc[train_index, :], label_df.iloc[train_index], \
train_df.iloc[test_index, :], label_df.iloc[test_index]
trainX.append(train_x)
trainY.append(train_y)
testX.append(test_x)
testY.append(test_y)
return trainX, testX, trainY, testY3.1 LGB 模型(1min)
%%time
train_X, train_y = train_data.drop(['label'], axis=1), train_data['label']
# 拆分为10份训练数据和验证数据
X_train, X_valid, y_train, y_valid = get_train_test_datas(train_X, train_y)
print('----训练数据,长度',len(X_train))
print('----验证数据,长度',len(X_valid))
pred_lgbms = [] # 列表,接受目标值,10轮,平均值
for i in range(10):
print('\n=========LGB training use Data {}/10===========\n'.format(i+1))
model_lgb = lgb.LGBMClassifier(
max_depth=10, # 8
n_estimators=1000,
min_child_weight=100,
colsample_bytree=0.7,
subsample=0.9,
learning_rate=0.05)
model_lgb.fit(
X_train[i].values,
y_train[i],
eval_metric='auc',
eval_set=[(X_train[i].values, y_train[i]), (X_valid[i].values, y_valid[i])],
verbose=False,
early_stopping_rounds=10)
print(model_lgb.best_score_['valid_1']['auc'])
pred = model_lgb.predict_proba(test_data.values)
pred = pd.DataFrame(pred[:,1]) # 将预测概率(复购)去处理,转换成DataFrame
pred_lgbms.append(pred)
# 求10轮平均值生成预测结果,保存
# 每一轮的结果,作为一列,进行了添加
pred_lgbms = pd.concat(pred_lgbms, axis=1) # 级联,列进行级联
# 加载提交数据
submission = pd.read_csv('./data_format1/test_format1.csv')
submission['prob'] = pred_lgbms.mean(axis=1) # 10轮训练的平均值
submission.to_csv('submission_KFold_lgb.csv', index=False)3.2 XGB 模型(4min)
# 构造训练集和测试集
def get_train_test_datas(train_df,label_df):
skv = StratifiedKFold(n_splits=20, shuffle=True)
trainX = []
trainY = []
testX = []
testY = []
# 索引:训练数据索引train_index,目标值的索引test_index
for train_index, test_index in skv.split(X=train_df, y=label_df):# 10轮for循环
train_x, train_y, test_x, test_y = train_df.iloc[train_index, :], label_df.iloc[train_index], \
train_df.iloc[test_index, :], label_df.iloc[test_index]
trainX.append(train_x)
trainY.append(train_y)
testX.append(test_x)
testY.append(test_y)
return trainX, testX, trainY, testY%%time
train_X, train_y = train_data.drop(['label'], axis=1), train_data['label']
# 拆分为20份训练数据和验证数据
X_train, X_valid, y_train, y_valid = get_train_test_datas(train_X, train_y)
print('------数据长度',len(X_train),len(y_train))
pred_xgbs = []
for i in range(20):
print('\n============XGB training use Data {}/20========\n'.format(i+1))
model_xgb = xgb.XGBClassifier(
max_depth=10, # raw8
n_estimators=5000,
min_child_weight=200,
colsample_bytree=0.7,
subsample=0.9,
learning_rate = 0.1)
model_xgb.fit(
X_train[i],
y_train[i],
eval_metric='auc',
eval_set=[(X_train[i], y_train[i]), (X_valid[i], y_valid[i])],
verbose=False,
early_stopping_rounds=10 # 早停法,如果auc在10epoch没有进步就stop
)
print(model_xgb.best_score)
pred = model_xgb.predict_proba(test_data)
pred = pd.DataFrame(pred[:,1])
pred_xgbs.append(pred)
# 求20轮平均值生成预测结果,保存
pred_xgbs = pd.concat(pred_xgbs, axis=1)
submission = pd.read_csv('./data_format1/test_format1.csv')
submission['prob'] = pred_xgbs.mean(axis=1)
submission.to_csv('submission_KFold_xgb.csv', index=False)