天猫用户重复购买预测——特征工程
天猫用户重复购买预测——特征工程
- 1.特征工程
-
- 1.1 概念
- 1.2 特征归一化
- 1.3 类别型特征转换
- 1.4 高维组合特征的处理
- 1.5 组合特征
- 1.6 文本表示模型
- 2. 赛题特征工程思路
- 3. 特征工程构造
-
- 3.1 工具包导入
- 3.2 数据读取
- 3.3 数据压缩
- 3.4 数据处理
- 3.5 定义特征统计数据
- 3.5.1 定义统计函数
- 3.5.2 调用统计函数
- 3.6 提取统计特征
- 3.7 利用Countvector和TF-IDF提取特征
- 3.8 嵌入特征
- 3.9 Stacking分类特征
-
- 3.9.1 导包
- 3.9.2 定义stacking分类特征函数
- 3.9.3 读取训练与验证数据
- 3.9.4 使用lgb和xgb分类模型构造stacking特征
这两天在整理做的一些比赛的内容,再结合书籍汇总一下每一个完整的ML项目!
1.特征工程
1.1 概念

要选取具有实际物理意义的特征(深度学习除外),要能够从多方面表达或阐述一个事情(从不同角度去描述一个事情)。
1.2 特征归一化
特征归一化目的是消除数据特征之间的量纲影响,使不同指标之间具有可比性。
简单方法有:
- 线性函数归一化
x n o r m = X − X m i n X m a x − X m i n x_{norm} = {X-X_{min} \over X_{max} - X_{min}} xnorm=Xmax−XminX−Xmin
将数据映射到[0,1]的范围内 - 零均值归一化
z = x − μ σ z = {x- \mu \over \sigma} z=σx−μ
将数据映射到均值为0、标准差为1的分布上
通过梯度下降求解的模型,归一化会对收敛速度产生影响,因此需要归一化数据,比如线性回归、逻辑回归、支持向量机、神经网络等,决策树一类模型不需要进行归一化处理。
1.3 类别型特征转换
类别型特征常用处理方法:
- 序号编码
- 独热向量编码:处理类别间不具有大小关系的特征
- 二进制编码
1.4 高维组合特征的处理
把一阶离散特征两两组合,就构成高阶组合特征。高维组合特征处理可以提高复杂关系的拟合能力。
1.5 组合特征
简单两两组合特征,存在参数过多、过拟合等问题,可以引入决策树方法来组合特征。
1.6 文本表示模型
- 词袋模型
- N-gram模型
- 主题模型
- 词嵌入
2. 赛题特征工程思路
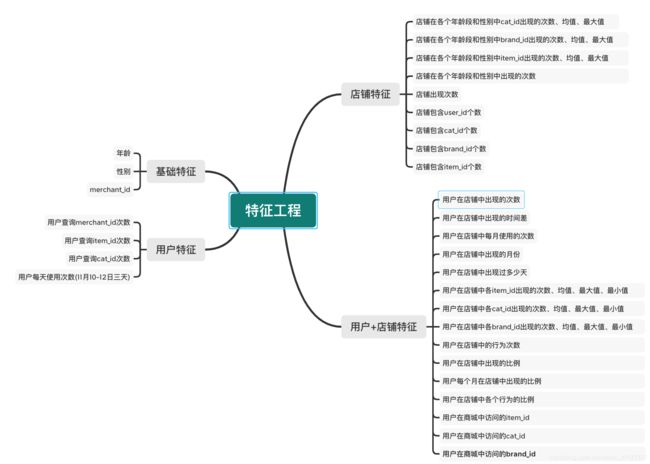
3. 特征工程构造
3.1 工具包导入
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats
import gc
from collections import Counter
import copy
import warnings
warnings.filterwarnings("ignore")
%matplotlib inline
3.2 数据读取
data_path = '比赛/天猫复购预测之挑战Baseline/datasets/' # 数据路径
#读取数据集
user_log = pd.read_csv(data_path + 'data_format1/user_log_format1.csv')
user_info = pd.read_csv(data_path + 'data_format1/user_info_format1.csv')
train_data = pd.read_csv(data_path + 'data_format1/train_format1.csv')
test_data = pd.read_csv(data_path + 'data_format1/test_format1.csv')
sample_submission = pd.read_csv(data_path + 'sample_submission.csv')
3.3 数据压缩
def read_csv(file_name, num_rows):
return pd.read_csv(file_name, nrows=num_rows)
# reduce memory
def reduce_mem_usage(df, verbose=True):
start_mem = df.memory_usage().sum() / 1024**2
numerics = ['int16', 'int32', 'int64', 'float16', 'float32', 'float64']
for col in df.columns:
col_type = df[col].dtypes
if col_type in numerics:
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == 'int':
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else:
if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:
df[col] = df[col].astype(np.float16)
elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
end_mem = df.memory_usage().sum() / 1024**2
print('Memory usage after optimization is: {:.2f} MB'.format(end_mem))
print('Decreased by {:.1f}%'.format(100 * (start_mem - end_mem) / start_mem))
return df
num_rows = None
num_rows = 200 * 10000 # 1000条测试代码使用
# num_rows = 1000
train_file = data_path + 'data_format1/train_format1.csv'
test_file = data_path + 'data_format1/test_format1.csv'
user_info_file = data_path + 'data_format1/user_info_format1.csv'
user_log_file = data_path + 'data_format1/user_log_format1.csv'
train_data = reduce_mem_usage(read_csv(train_file, num_rows))
test_data = reduce_mem_usage(read_csv(test_file, num_rows))
user_info = reduce_mem_usage(read_csv(user_info_file, num_rows))
user_log = reduce_mem_usage(read_csv(user_log_file, num_rows))
Memory usage after optimization is: 1.74 MB
Decreased by 70.8%
Memory usage after optimization is: 3.49 MB
Decreased by 41.7%
Memory usage after optimization is: 3.24 MB
Decreased by 66.7%
Memory usage after optimization is: 32.43 MB
Decreased by 69.6%
3.4 数据处理
del test_data['prob']
all_data = train_data.append(test_data)
all_data = all_data.merge(user_info,on=['user_id'],how='left')
del train_data, test_data, user_info
gc.collect()
"""
按时间排序
"""
user_log = user_log.sort_values(['user_id','time_stamp'])
"""
合并数据
"""
list_join_func = lambda x: " ".join([str(i) for i in x])
agg_dict = {
'item_id' : list_join_func,
'cat_id' : list_join_func,
'seller_id' : list_join_func,
'brand_id' : list_join_func,
'time_stamp' : list_join_func,
'action_type' : list_join_func
}
rename_dict = {
'item_id' : 'item_path',
'cat_id' : 'cat_path',
'seller_id' : 'seller_path',
'brand_id' : 'brand_path',
'time_stamp' : 'time_stamp_path',
'action_type' : 'action_type_path'
}
user_log_path = user_log.groupby('user_id').agg(agg_dict).reset_index().rename(columns=rename_dict)
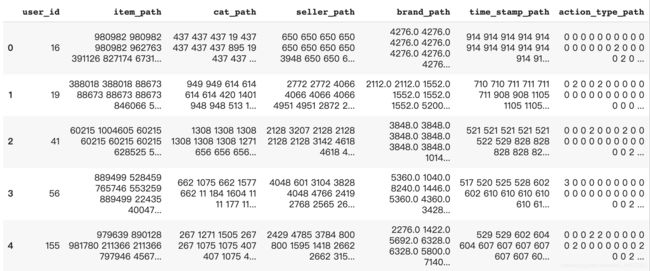
all_data_path = all_data.merge(user_log_path,on='user_id')
3.5 定义特征统计数据
3.5.1 定义统计函数
3.5.2 调用统计函数
3.6 提取统计特征
3.7 利用Countvector和TF-IDF提取特征
3.8 嵌入特征
3.9 Stacking分类特征
3.9.1 导包
from sklearn.model_selection import KFold
import pandas as pd
import numpy as np
from scipy import sparse
import xgboost
import lightgbm
from sklearn.ensemble import RandomForestClassifier,AdaBoostClassifier,GradientBoostingClassifier,ExtraTreesClassifier
from sklearn.ensemble import RandomForestRegressor,AdaBoostRegressor,GradientBoostingRegressor,ExtraTreesRegressor
from sklearn.linear_model import LinearRegression,LogisticRegression
from sklearn.svm import LinearSVC,SVC
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import log_loss,mean_absolute_error,mean_squared_error
from sklearn.naive_bayes import MultinomialNB,GaussianNB
3.9.2 定义stacking分类特征函数
3.9.3 读取训练与验证数据
features_columns = [c for c in all_data_test.columns if c not in ['label', 'prob', 'seller_path', 'cat_path', 'brand_path', 'action_type_path', 'item_path', 'time_stamp_path']]
x_train = all_data_test[~all_data_test['label'].isna()][features_columns].values
y_train = all_data_test[~all_data_test['label'].isna()]['label'].values
x_valid = all_data_test[all_data_test['label'].isna()][features_columns].values