利用python进行数据分析之时间序列--小白笔记
时间序列(time series)数据是一种重要的结构化数据形式。
- 时间戳(timestamp),特定的时刻
- 固定时期(period),如2007年1月或2010年全年
- 时间间隔(interval),由起始和结束时间戳表示。时期(period)可以被看做间隔(interval)的特例
- 实验或过程时间,每个时间点都是相对于特定起始时间的一个度量
import numpy as np
import pandas as pd
import datetime,time
from datetime import datetime
日期和时间数据类型及工具
python标准库包含用于日期(date)和时间(time)数据的数据类型,而且还有日历方面的功能。
主要用到datetime、time以及calendar模块
datetime.datetime是用到最多的数据类型
now=datetime.now()
now
datetime.datetime(2023, 9, 8, 15, 48, 53, 805615)
now.year,now.month,now.day
(2023, 9, 8)
datetime以毫秒形式存储日期和时间。timedelta表示两个datetime对象之间的时间差
delta=datetime(2011,1,7)-datetime(2008,6,24,8,15)
delta
datetime.timedelta(days=926, seconds=56700)
delta.days,delta.seconds
(926, 56700)
可以给datetime对象加上(或减去)一个或多个timedelta,这样会产生一个新对象
from datetime import timedelta
start=datetime(2011,1,7)
start+timedelta(12)
datetime.datetime(2011, 1, 19, 0, 0)
start-2*timedelta(12)
datetime.datetime(2010, 12, 14, 0, 0)
datetime模块中的数据类型
| 类型 | 说明 |
|---|---|
| date | 以公历形式存储日历日期(年、月、日) |
| time | 将时间存储为时、分、秒、毫秒 |
| datetime | 存储日期和时间 |
| timedelta | 表示两个datetime值之间的差(日、秒、毫秒) |
字符串和datetime的相互转换
利用str或strftime方法(传入一个格式化字符串),datetime对象和pandas的timestamp对象可以被格式化为字符串
stamp=datetime(2011,1,3)
str(stamp)
'2011-01-03 00:00:00'
stamp.strftime('%Y-%m-%d')
'2011-01-03'
datetime格式定义
| 代码 | 说明 |
|---|---|
| %Y | 4位数的年 |
| %y | 2位数的年 |
| %m | 2位数的月 |
| %d | 2位数的日 |
| %H | 时(24小时制) |
| %l | 时(12小时制) |
| %M | 2位数的分 |
| %S | 秒00-61(秒60和61用于表示闰秒) |
| %w | 用整数表示的星期几 |
| %U | 每年的第几周,星期天被认为每周的第一天 |
| %W | 每年的第几周,星期一被认为每周的第一天 |
| %z | 以+HHMM或-HHMM表示UTC时区偏移量。市区为naive,返回空字符串 |
| %F | %Y-%m-%d |
| %D | %m/%d/%y |
datetime.strptime可以用这些格式化编码将字符串转换为日期
value='2011-01-03'
datetime.strptime(value,'%Y-%m-%d')
datetime.datetime(2011, 1, 3, 0, 0)
datestrs=['7/6/2011','8/6/2011']
[datetime.strptime(x,'%m/%d/%Y') for x in datestrs]
[datetime.datetime(2011, 7, 6, 0, 0), datetime.datetime(2011, 8, 6, 0, 0)]
datetime.strptime是通过已知格式进行日期解析的一种方式
dateutil这个第三方包中的parser.parser方法可以直接解析日期格式
from dateutil.parser import parse
parse('2011-01-03')
datetime.datetime(2011, 1, 3, 0, 0)
parse('Jan 31 2011 10:45 PM')
datetime.datetime(2011, 1, 31, 22, 45)
在国际通用的格式中,日出现在月的前面很普遍,传入dayfirst=True即可解决这个问题
parse('6/11/2011',dayfirst=True)
datetime.datetime(2011, 11, 6, 0, 0)
pandas通常处理成组日期,不管这些日期是DateFrame的轴索引还是列。to_datetime方法可以解析多种不同的日期表现形式。对标准日期格式的解析非常快
datestrs=['2011-07-06 12:00:00','2011-08-06 00:00:00']
pd.to_datetime(datestrs)
DatetimeIndex(['2011-07-06 12:00:00', '2011-08-06 00:00:00'], dtype='datetime64[ns]', freq=None)
还可以处理缺失值(None、空字符串)
idx=pd.to_datetime(datestrs+[None])
idx
DatetimeIndex(['2011-07-06 12:00:00', '2011-08-06 00:00:00', 'NaT'], dtype='datetime64[ns]', freq=None)
idx[2]
NaT
pd.isnull(idx)
array([False, False, True])
NaT(Not a Time)是pandas中时间戳数据的null值
注:dateutil.parser是一个实用但不完美的工具。比如,他会把一些原本不是日期的字符串认作日期
时间序列基础
pandas最基本的时间序列类型就是以时间戳(通常以Python字符串或datetime对象表示)为索引的Series
from datetime import datetime
dates = [datetime(2011, 1, 2), datetime(2011, 1, 5),
datetime(2011, 1, 7), datetime(2011, 1, 8),
datetime(2011, 1, 10), datetime(2011, 1, 12)]
ts=pd.Series(np.random.randn(6),index=dates)
ts
2011-01-02 -0.399861
2011-01-05 0.403928
2011-01-07 0.193208
2011-01-08 -0.750923
2011-01-10 1.727515
2011-01-12 1.031623
dtype: float64
这些datetime对象实际上是被放在一个DatetimeIndex中
ts.index
DatetimeIndex(['2011-01-02', '2011-01-05', '2011-01-07', '2011-01-08',
'2011-01-10', '2011-01-12'],
dtype='datetime64[ns]', freq=None)
跟其他Series一样,不同索引的时间序列之间的算术运算会自动按日期对齐
ts+ts[::2]#ts[::2]每隔两个取一个
2011-01-02 -0.799723
2011-01-05 NaN
2011-01-07 0.386416
2011-01-08 NaN
2011-01-10 3.455029
2011-01-12 NaN
dtype: float64
pandas用Numpy的datetime64数据类型以纳秒的形式存储时间戳
ts.index.dtype
dtype('DatetimeIndex中的各个标量值是pandas的Timestamp对象
stamps=ts.index[0]
stamps
Timestamp('2011-01-02 00:00:00')
索引、选取、子集构造
当你根据标签索引选取数据时,时间序列和其他pandas.Series很像
stamp=ts.index[2]
ts[stamp]
0.19320782215895874
还可以传入一个可以被解释为日期的字符串
ts['1/07/2011']
0.19320782215895874
ts['20110107']
0.19320782215895874
对于较长的时间序列,只需传入“年”或“年月”即可进行数据切片
longer_ts=pd.Series(np.random.randn(1000),index=pd.date_range('1/1/2000',periods=1000))
longer_ts
2000-01-01 -0.994092
2000-01-02 0.243258
2000-01-03 0.929323
2000-01-04 -0.168871
2000-01-05 -0.381879
...
2002-09-22 -1.876726
2002-09-23 -0.611525
2002-09-24 -0.515910
2002-09-25 -0.282035
2002-09-26 0.787776
Freq: D, Length: 1000, dtype: float64
longer_ts['2001']
2001-01-01 1.009665
2001-01-02 -0.824374
2001-01-03 2.138398
2001-01-04 -1.191215
2001-01-05 -1.053082
...
2001-12-27 0.819645
2001-12-28 -0.743881
2001-12-29 0.633011
2001-12-30 0.733222
2001-12-31 0.497886
Freq: D, Length: 365, dtype: float64
longer_ts['2001-05']
2001-05-01 -2.195268
2001-05-02 0.419152
2001-05-03 -0.709574
2001-05-04 -1.131150
2001-05-05 -0.244608
2001-05-06 0.050070
2001-05-07 0.141571
2001-05-08 -1.966103
2001-05-09 -1.262891
2001-05-10 2.052505
2001-05-11 0.132736
2001-05-12 -0.870929
2001-05-13 0.997271
2001-05-14 0.032981
2001-05-15 -1.039543
2001-05-16 0.753542
2001-05-17 0.132935
2001-05-18 -0.794148
2001-05-19 0.490096
2001-05-20 1.279849
2001-05-21 -0.347668
2001-05-22 0.685715
2001-05-23 0.756410
2001-05-24 -0.073984
2001-05-25 -1.147314
2001-05-26 0.606999
2001-05-27 -0.427986
2001-05-28 -0.242120
2001-05-29 -0.250834
2001-05-30 -2.505071
2001-05-31 0.674570
Freq: D, dtype: float64
ts[datetime(2011,1,7):]
2011-01-07 0.193208
2011-01-08 -0.750923
2011-01-10 1.727515
2011-01-12 1.031623
dtype: float64
由于大部分时间序列数据都是按照时间先后排序的,因此你也可以用不存在于该时间序列中的时间戳对其进行切片(即范围查询)
ts
2011-01-02 -0.399861
2011-01-05 0.403928
2011-01-07 0.193208
2011-01-08 -0.750923
2011-01-10 1.727515
2011-01-12 1.031623
dtype: float64
ts['1/6/2011':'1/11/2011']
2011-01-07 0.193208
2011-01-08 -0.750923
2011-01-10 1.727515
dtype: float64
一个等价的实例方法truncate也可以截取两个日期之间的TimeSeries
ts.truncate(after='1/9/2011')
2011-01-02 -0.399861
2011-01-05 0.403928
2011-01-07 0.193208
2011-01-08 -0.750923
dtype: float64
对DateFrame也有效
dates = pd.date_range('1/1/2000', periods=100, freq='W-WED')
long_df = pd.DataFrame(np.random.randn(100, 4),
index=dates,
columns=['Colorado', 'Texas','New York', 'Ohio'])
long_df
| Colorado | Texas | New York | Ohio | |
|---|---|---|---|---|
| 2000-01-05 | -0.405523 | 0.908071 | 1.822543 | -0.562963 |
| 2000-01-12 | -0.049467 | 0.485990 | -0.279052 | -0.723333 |
| 2000-01-19 | 0.750311 | 1.042382 | 0.225140 | 1.395041 |
| 2000-01-26 | 0.270467 | 0.469076 | 0.040557 | 0.113861 |
| 2000-02-02 | 0.439021 | -0.097106 | -0.970282 | 0.491808 |
| ... | ... | ... | ... | ... |
| 2001-10-31 | 0.515944 | -0.564199 | -0.286108 | 1.551582 |
| 2001-11-07 | 1.012778 | -0.002377 | -2.118233 | -0.595119 |
| 2001-11-14 | 0.568788 | -0.546481 | -0.688155 | -0.106262 |
| 2001-11-21 | 0.404215 | 0.649409 | -0.479882 | -0.521904 |
| 2001-11-28 | 1.975573 | -1.068704 | 1.411288 | -0.924625 |
100 rows × 4 columns
long_df.loc['5-2001']
| Colorado | Texas | New York | Ohio | |
|---|---|---|---|---|
| 2001-05-02 | -0.613960 | 0.135393 | -0.826061 | -0.323646 |
| 2001-05-09 | -0.086363 | -0.045427 | -0.890787 | 0.175619 |
| 2001-05-16 | -0.492947 | -0.565851 | 0.253310 | 0.877704 |
| 2001-05-23 | -0.339650 | -0.191218 | -0.703612 | -1.292313 |
| 2001-05-30 | -0.795876 | 0.732028 | -1.208615 | 1.682128 |
带有重复索引的时间序列
dates = pd.DatetimeIndex(['1/1/2000', '1/2/2000', '1/2/2000','1/2/2000', '1/3/2000'])
dup_ts = pd.Series(np.arange(5), index=dates)
dup_ts
2000-01-01 0
2000-01-02 1
2000-01-02 2
2000-01-02 3
2000-01-03 4
dtype: int32
dup_ts.index.is_unique
False
对这个时间序列进行索引,要么产生标量值,要么产生切片,具体要看所选的时间点是否重复
dup_ts['1/3/2000']
4
dup_ts['1/2/2000']
2000-01-02 1
2000-01-02 2
2000-01-02 3
dtype: int32
假设你想要对具有非唯一时间戳的数据进行聚合。一个办法是使用groupby,并传入level=0
grouped=dup_ts.groupby(level=0)
grouped.mean()
2000-01-01 0.0
2000-01-02 2.0
2000-01-03 4.0
dtype: float64
grouped.count()
2000-01-01 1
2000-01-02 3
2000-01-03 1
dtype: int64
日期的范围、频率、以及移动
ts
2011-01-02 -0.399861
2011-01-05 0.403928
2011-01-07 0.193208
2011-01-08 -0.750923
2011-01-10 1.727515
2011-01-12 1.031623
dtype: float64
resampler=ts.resample('D')
resampler
生成日期范围
pandas.date_range可用于根据指定的频率生成指定长度的DatetimeIndex
index=pd.date_range('2012-04-01','2012-06-01')
index
DatetimeIndex(['2012-04-01', '2012-04-02', '2012-04-03', '2012-04-04',
'2012-04-05', '2012-04-06', '2012-04-07', '2012-04-08',
'2012-04-09', '2012-04-10', '2012-04-11', '2012-04-12',
'2012-04-13', '2012-04-14', '2012-04-15', '2012-04-16',
'2012-04-17', '2012-04-18', '2012-04-19', '2012-04-20',
'2012-04-21', '2012-04-22', '2012-04-23', '2012-04-24',
'2012-04-25', '2012-04-26', '2012-04-27', '2012-04-28',
'2012-04-29', '2012-04-30', '2012-05-01', '2012-05-02',
'2012-05-03', '2012-05-04', '2012-05-05', '2012-05-06',
'2012-05-07', '2012-05-08', '2012-05-09', '2012-05-10',
'2012-05-11', '2012-05-12', '2012-05-13', '2012-05-14',
'2012-05-15', '2012-05-16', '2012-05-17', '2012-05-18',
'2012-05-19', '2012-05-20', '2012-05-21', '2012-05-22',
'2012-05-23', '2012-05-24', '2012-05-25', '2012-05-26',
'2012-05-27', '2012-05-28', '2012-05-29', '2012-05-30',
'2012-05-31', '2012-06-01'],
dtype='datetime64[ns]', freq='D')
默认情况下,date_range会产生按天计算的时间点。如果只传入起始或结束日期,那还得传入一个表示一段时间的数字
pd.date_range(start='2012-04-01',periods=20)
DatetimeIndex(['2012-04-01', '2012-04-02', '2012-04-03', '2012-04-04',
'2012-04-05', '2012-04-06', '2012-04-07', '2012-04-08',
'2012-04-09', '2012-04-10', '2012-04-11', '2012-04-12',
'2012-04-13', '2012-04-14', '2012-04-15', '2012-04-16',
'2012-04-17', '2012-04-18', '2012-04-19', '2012-04-20'],
dtype='datetime64[ns]', freq='D')
pd.date_range(end='2012-06-01',periods=20)
DatetimeIndex(['2012-05-13', '2012-05-14', '2012-05-15', '2012-05-16',
'2012-05-17', '2012-05-18', '2012-05-19', '2012-05-20',
'2012-05-21', '2012-05-22', '2012-05-23', '2012-05-24',
'2012-05-25', '2012-05-26', '2012-05-27', '2012-05-28',
'2012-05-29', '2012-05-30', '2012-05-31', '2012-06-01'],
dtype='datetime64[ns]', freq='D')
起始和结束日期定义了日期索引的严格边界。
例如,如果你想要生成一个由每月最后一个工作日组成的日期索引,可以传入BM频率(表示business end of month),这样就只会包含时间间隔内(或刚好在边界上的)符合频率要求的日期
pd.date_range('2023-01-01','2023-12-01',freq='BM')
DatetimeIndex(['2023-01-31', '2023-02-28', '2023-03-31', '2023-04-28',
'2023-05-31', '2023-06-30', '2023-07-31', '2023-08-31',
'2023-09-29', '2023-10-31', '2023-11-30'],
dtype='datetime64[ns]', freq='BM')
基本的时间序列频率(部分)
| 别名 | 偏移量类型 | 说明 |
|---|---|---|
| D | Day | 每日历日 |
| B | BusinessDay | 每工作日 |
| H | Hour | 每小时 |
| T或min | Minute | 每分 |
| S | Second | 每秒 |
| L或ms | Milli | 每毫秒 |
| U | Micro | 每微秒 |
| M | MonthEnd | 每月最后一个日历日 |
| BM | BussinessMonthEnd | 每月最后一个工作日 |
| MS | MonthBegin | 每月第一个日历日 |
| BMS | BussinessMonthBegin | 每月第一个工作日 |
date_range默认会保留起始和结束时间戳的时间信息
pd.date_range('2012-05-02 12:56:31',periods=5)
DatetimeIndex(['2012-05-02 12:56:31', '2012-05-03 12:56:31',
'2012-05-04 12:56:31', '2012-05-05 12:56:31',
'2012-05-06 12:56:31'],
dtype='datetime64[ns]', freq='D')
虽然起始和结束日期带有时间信息,但你希望产生一组被规范化
(normalize)到午夜的时间戳。normalize选项即可实现该功能
pd.date_range('2012-05-02 12:56:31',periods=5,normalize=True)
DatetimeIndex(['2012-05-02', '2012-05-03', '2012-05-04', '2012-05-05',
'2012-05-06'],
dtype='datetime64[ns]', freq='D')
频率和日期偏移量
pandas中的频率是由一个基础频率(base frequency)和一个乘数组成的。基础频率通常以一个字符串别名表示,比如"M"表示每月,"H"表示每小时。对于每个基础频率,都有一个被称为日期偏移量(date offset)的对象与之对应。
from pandas.tseries.offsets import Hour, Minute
hour=Hour()
hour
four_hour=Hour(4)
four_hour
<4 * Hours>
一般来说,无需明确创建这样的对象,只需使用诸如H或4H这样的字符串别名即可。在基础频率前面放上一个整数即可创建倍数
pd.date_range('2000-01-01', '2000-01-03 23:59',freq='4h')
DatetimeIndex(['2000-01-01 00:00:00', '2000-01-01 04:00:00',
'2000-01-01 08:00:00', '2000-01-01 12:00:00',
'2000-01-01 16:00:00', '2000-01-01 20:00:00',
'2000-01-02 00:00:00', '2000-01-02 04:00:00',
'2000-01-02 08:00:00', '2000-01-02 12:00:00',
'2000-01-02 16:00:00', '2000-01-02 20:00:00',
'2000-01-03 00:00:00', '2000-01-03 04:00:00',
'2000-01-03 08:00:00', '2000-01-03 12:00:00',
'2000-01-03 16:00:00', '2000-01-03 20:00:00'],
dtype='datetime64[ns]', freq='4H')
大部分偏移量都可通过加法连接
Hour(2)+Minute(30)
<150 * Minutes>
也可以传入频率字符串
pd.date_range('2000-01-01',periods=10,freq='1h30min')
DatetimeIndex(['2000-01-01 00:00:00', '2000-01-01 01:30:00',
'2000-01-01 03:00:00', '2000-01-01 04:30:00',
'2000-01-01 06:00:00', '2000-01-01 07:30:00',
'2000-01-01 09:00:00', '2000-01-01 10:30:00',
'2000-01-01 12:00:00', '2000-01-01 13:30:00'],
dtype='datetime64[ns]', freq='90T')
有些频率所描述的时间点并不是均匀分隔的。例如,“M”(日历月末)和"BM"(每月最后一个工作日)就取决于每月的天数,对于后者,还要考虑月末是不是周末。由于没有更好的术语,我将这些称为锚点偏移量(anchored offset)
WOM日期
WOM(Week Of Month)是一种非常实用的频率类,它以WOM开头。它使你能获得诸如“每月第3个星期五”之类的日期
rng=pd.date_range('2012-01-01','2012-09-01',freq='WOM-3FRI')
list(rng)
[Timestamp('2012-01-20 00:00:00'),
Timestamp('2012-02-17 00:00:00'),
Timestamp('2012-03-16 00:00:00'),
Timestamp('2012-04-20 00:00:00'),
Timestamp('2012-05-18 00:00:00'),
Timestamp('2012-06-15 00:00:00'),
Timestamp('2012-07-20 00:00:00'),
Timestamp('2012-08-17 00:00:00')]
移动(超前和滞后)数据
移动(shifting)指的是沿着时间轴将数据迁移或后移。Series和DateFrame都有一个shift方法用于执行单纯的前移或后移操作,保持索引不变
ts=pd.Series(np.random.randn(4),
index=pd.date_range('1/1/2000',periods=4,freq='M'))
ts
2000-01-31 -0.517793
2000-02-29 1.572669
2000-03-31 -1.304866
2000-04-30 0.621373
Freq: M, dtype: float64
ts.shift(2)
2000-01-31 NaN
2000-02-29 NaN
2000-03-31 -0.517793
2000-04-30 1.572669
Freq: M, dtype: float64
ts.shift(-2)
2000-01-31 -1.304866
2000-02-29 0.621373
2000-03-31 NaN
2000-04-30 NaN
Freq: M, dtype: float64
当我们进行移动时,就会在时间序列的前面或后面产生缺失数据
shift通常用于计算一个时间序列或多个时间序列(如DateFrame)中的百分比变化
ts/ts.shift(2)-1
2000-01-31 NaN
2000-02-29 NaN
2000-03-31 1.520056
2000-04-30 -0.604892
Freq: M, dtype: float64
由于单纯的移位操作不会修改索引,所以部分数据会被丢弃。因此,如果频率已知,则可以将其传给shift以便实现对时间戳进行位移而不是对数据进行简单位移
ts.shift(2,freq='M')
2000-03-31 -0.517793
2000-04-30 1.572669
2000-05-31 -1.304866
2000-06-30 0.621373
Freq: M, dtype: float64
还可以使用其他频率,可以非常灵活的进行超前和滞后处理
ts.shift(3,freq='D')
2000-02-03 -0.517793
2000-03-03 1.572669
2000-04-03 -1.304866
2000-05-03 0.621373
dtype: float64
通过偏移量对日期进行位移
pandas的日期偏移量还可以用在datetime和timestamp对象上
from pandas.tseries.offsets import Day,MonthEnd
now=datetime(2011,11,17)
now+3*Day()
Timestamp('2011-11-20 00:00:00')
如果加的是锚点偏移量(比如MonthEnd),第一次增量会将原日期向前滚动到符合频率规则的下一个日期
now+MonthEnd()
Timestamp('2011-11-30 00:00:00')
now+MonthEnd(2)
Timestamp('2011-12-31 00:00:00')
通过锚点偏移量的rollforward和rollback方法,可明确的将日期向前或向后滚定动
offset=MonthEnd()
offset.rollforward(now)
Timestamp('2011-11-30 00:00:00')
offset.rollback(now)
Timestamp('2011-10-31 00:00:00')
日期偏移量还有一个巧妙的用法,即结合groupby使用上述两个滚动方法
ts = pd.Series(np.random.randn(20),index=pd.date_range('1/15/2000', periods=20, freq='4d'))
ts
2000-01-15 -0.211794
2000-01-19 0.462626
2000-01-23 0.329880
2000-01-27 1.114397
2000-01-31 -0.677630
2000-02-04 -0.349137
2000-02-08 -0.886134
2000-02-12 1.142536
2000-02-16 -0.863100
2000-02-20 -0.692893
2000-02-24 -1.139926
2000-02-28 -0.339441
2000-03-03 2.008366
2000-03-07 0.004030
2000-03-11 1.049552
2000-03-15 -1.150146
2000-03-19 -0.087416
2000-03-23 -2.220171
2000-03-27 1.279052
2000-03-31 -1.409034
Freq: 4D, dtype: float64
list(ts.groupby(offset.rollforward))
[(Timestamp('2000-01-31 00:00:00'),
2000-01-15 -0.211794
2000-01-19 0.462626
2000-01-23 0.329880
2000-01-27 1.114397
2000-01-31 -0.677630
Freq: 4D, dtype: float64),
(Timestamp('2000-02-29 00:00:00'),
2000-02-04 -0.349137
2000-02-08 -0.886134
2000-02-12 1.142536
2000-02-16 -0.863100
2000-02-20 -0.692893
2000-02-24 -1.139926
2000-02-28 -0.339441
Freq: 4D, dtype: float64),
(Timestamp('2000-03-31 00:00:00'),
2000-03-03 2.008366
2000-03-07 0.004030
2000-03-11 1.049552
2000-03-15 -1.150146
2000-03-19 -0.087416
2000-03-23 -2.220171
2000-03-27 1.279052
2000-03-31 -1.409034
Freq: 4D, dtype: float64)]
ts.groupby(offset.rollforward).mean()
2000-01-31 -0.325854
2000-02-29 -0.400242
2000-03-31 0.162939
dtype: float64
resample
list(ts.resample('M'))
[(Timestamp('2000-01-31 00:00:00'),
2000-01-15 -0.211794
2000-01-19 0.462626
2000-01-23 0.329880
2000-01-27 1.114397
2000-01-31 -0.677630
Freq: 4D, dtype: float64),
(Timestamp('2000-02-29 00:00:00'),
2000-02-04 -0.349137
2000-02-08 -0.886134
2000-02-12 1.142536
2000-02-16 -0.863100
2000-02-20 -0.692893
2000-02-24 -1.139926
2000-02-28 -0.339441
Freq: 4D, dtype: float64),
(Timestamp('2000-03-31 00:00:00'),
2000-03-03 2.008366
2000-03-07 0.004030
2000-03-11 1.049552
2000-03-15 -1.150146
2000-03-19 -0.087416
2000-03-23 -2.220171
2000-03-27 1.279052
2000-03-31 -1.409034
Freq: 4D, dtype: float64)]
ts.resample('M').mean()
2000-01-31 -0.325854
2000-02-29 -0.400242
2000-03-31 0.162939
Freq: M, dtype: float64
时期及其算术运算
时期(period)表示的是时间区间,比如数日、数月、数季、数年等。Period类所表示的就是这种数据类型,其构造函数需要用到一个字符串或整数,以及频率
p = pd.Period(2007, freq='A-DEC')
p
Period('2007', 'A-DEC')
这个Period对象表示的是从2007年1月1日到2007年12月31日之间的整段时
间。
只需对Period对象加上或减去一个整数即可达到根据其频率进行位移的效果
p+5
Period('2012', 'A-DEC')
p-2
Period('2005', 'A-DEC')
pd.Period('2014',freq='A-DEC')-p
<7 * YearEnds: month=12>
period_range函数可用于创建规则的时期范围
rng=pd.period_range('2000-01-01','2000-06-30',freq='M')
rng
PeriodIndex(['2000-01', '2000-02', '2000-03', '2000-04', '2000-05', '2000-06'], dtype='period[M]')
PeriodIndex类保存了一组Period,time可以在任何pandas数据结构中被用作轴索引
pd.Series(np.random.randn(6),index=rng)
2000-01 -1.664397
2000-02 0.677680
2000-03 0.074917
2000-04 1.056093
2000-05 0.849702
2000-06 -0.173546
Freq: M, dtype: float64
如果你有一个字符串数组,你也可以使用PeriodIndex类
values = ['2001Q3', '2002Q2', '2003Q1']
index=pd.PeriodIndex(values,freq='Q-DEC')
index
PeriodIndex(['2001Q3', '2002Q2', '2003Q1'], dtype='period[Q-DEC]')
时期的频率转换
Period和PeriodIndex对象都可以通过其asfreq方法被转换成别的频率。假设我们有一个年度时期,希望将其转换为当年年初或年末的一个月度时期
p=pd.Period('2007',freq='A-DEC')
p
Period('2007', 'A-DEC')
p.asfreq('M',how='start')
Period('2007-01', 'M')
p.asfreq('M',how='end')
Period('2007-12', 'M')
对于一个不以12月结束的财政年度,月度子时期的归属情况就不一样了
p = pd.Period('2007', freq='A-JUN')
p
Period('2007', 'A-JUN')
p.asfreq('M', 'start')
Period('2006-07', 'M')
p.asfreq('M', 'end')
Period('2007-06', 'M')
在将高频率转换为低频率时,超时期(superperiod)是由子时期(subperiod)所属的位置决定的。例如,在A-JUN频率中,月份“2007年8月”实际上是属于周期“2008年”的
p = pd.Period('Aug-2007', 'M')
p
Period('2007-08', 'M')
p.asfreq('A-JUN')
Period('2008', 'A-JUN')
完整的PeriodIndex或TimeSeries的频率转换方式也是如此
rng = pd.period_range('2006', '2009', freq='A-DEC')
ts = pd.Series(np.random.randn(len(rng)), index=rng)
ts
2006 -0.925806
2007 -0.170260
2008 0.691124
2009 0.493400
Freq: A-DEC, dtype: float64
ts.asfreq('M', how='start')
2006-01 -0.925806
2007-01 -0.170260
2008-01 0.691124
2009-01 0.493400
Freq: M, dtype: float64
根据年度时期的第一个月,每年的时期被取代为每月的时期。如果我们想要每年的最后一个工作日,我们可以使用“B”频率,并指明想要该时期的末尾
ts.asfreq('B', how='end')
2006-12-29 -0.925806
2007-12-31 -0.170260
2008-12-31 0.691124
2009-12-31 0.493400
Freq: B, dtype: float64
按季度计算的时期频率
季度型数据在会计、金融等领域中很常见。许多季度型数据都会涉及“财年末”的概念,通常是一年12个月中某月的最后一个日历日或工作日。就这一点来说,时期"2012Q4"根据财年末的不同会有不同的含义。pandas支持12种可能的季度型频率,即Q-JAN到Q-DEC
p = pd.Period('2012Q4', freq='Q-JAN')
p
Period('2012Q4', 'Q-JAN')
p.asfreq('D', 'start')
Period('2011-11-01', 'D')
p.asfreq('D', 'end')
Period('2012-01-31', 'D')
#工作日的前一天
p4pm = (p.asfreq('B', 'e') - 1).asfreq('T', 's') + 16* 60
p4pm
C:\Users\Dell\AppData\Local\Temp\ipykernel_7528\2800287024.py:2: FutureWarning: Period with BDay freq is deprecated and will be removed in a future version. Use a DatetimeIndex with BDay freq instead.
p4pm = (p.asfreq('B', 'e') - 1).asfreq('T', 's') + 16* 60
Period('2012-01-30 16:00', 'T')
p4pm.to_timestamp()
Timestamp('2012-01-30 16:00:00')
#工作日的倒数第二天,2012/1/31是星期二
p4am=(p.asfreq('B','e')-2).asfreq('T','s')+16*60
p4am
C:\Users\Dell\AppData\Local\Temp\ipykernel_7528\4207756690.py:2: FutureWarning: Period with BDay freq is deprecated and will be removed in a future version. Use a DatetimeIndex with BDay freq instead.
p4am=(p.asfreq('B','e')-2).asfreq('T','s')+16*60
Period('2012-01-27 16:00', 'T')
period_range可用于生成季度型范围。季度型范围的算术运算也跟上面是一样的
rng = pd.period_range('2011Q3', '2012Q4', freq='Q-JAN')
rng
PeriodIndex(['2011Q3', '2011Q4', '2012Q1', '2012Q2', '2012Q3', '2012Q4'], dtype='period[Q-JAN]')
ts = pd.Series(np.arange(len(rng)), index=rng)
ts
2011Q3 0
2011Q4 1
2012Q1 2
2012Q2 3
2012Q3 4
2012Q4 5
Freq: Q-JAN, dtype: int32
new_rng = (rng.asfreq('B', 'e') - 1).asfreq('T', 's')+ 16 * 60
ts.index = new_rng.to_timestamp()
ts
2010-10-28 16:00:00 0
2011-01-28 16:00:00 1
2011-04-28 16:00:00 2
2011-07-28 16:00:00 3
2011-10-28 16:00:00 4
2012-01-30 16:00:00 5
dtype: int32
将Timestamp转换为Period(及其反向过程)
通过使用to_period方法,可以将由时间戳索引的Series和DataFrame对象转换为以时期索引
rng = pd.date_range('2000-01-01', periods=3, freq='M')
ts = pd.Series(np.random.randn(3), index=rng)
ts
2000-01-31 0.319421
2000-02-29 0.697313
2000-03-31 -0.332460
Freq: M, dtype: float64
pts = ts.to_period()
pts
2000-01 0.319421
2000-02 0.697313
2000-03 -0.332460
Freq: M, dtype: float64
由于时期指的是非重叠时间区间,因此对于给定的频率,一个时间戳只能属于一个时期。新PeriodIndex的频率默认是从时间戳推断而来的,也可以指定任何别的频率
rng = pd.date_range('1/29/2000', periods=6, freq='D')
ts2 = pd.Series(np.random.randn(6), index=rng)
ts2
2000-01-29 -0.055344
2000-01-30 1.570756
2000-01-31 1.288053
2000-02-01 -0.084722
2000-02-02 -0.962208
2000-02-03 -0.693205
Freq: D, dtype: float64
ts2.to_period('M')
2000-01 -0.055344
2000-01 1.570756
2000-01 1.288053
2000-02 -0.084722
2000-02 -0.962208
2000-02 -0.693205
Freq: M, dtype: float64
要转回时间戳,使用to_timestamp即可
pts=ts2.to_period()
pts
2000-01-29 -0.055344
2000-01-30 1.570756
2000-01-31 1.288053
2000-02-01 -0.084722
2000-02-02 -0.962208
2000-02-03 -0.693205
Freq: D, dtype: float64
pts.to_timestamp(how='end')
2000-01-29 23:59:59.999999999 -0.055344
2000-01-30 23:59:59.999999999 1.570756
2000-01-31 23:59:59.999999999 1.288053
2000-02-01 23:59:59.999999999 -0.084722
2000-02-02 23:59:59.999999999 -0.962208
2000-02-03 23:59:59.999999999 -0.693205
Freq: D, dtype: float64
rng = pd.period_range('2011Q3', '2012Q4', freq='Q-JAN')
ts3 = pd.Series(np.arange(len(rng)), index=rng)
ts3
2011Q3 0
2011Q4 1
2012Q1 2
2012Q2 3
2012Q3 4
2012Q4 5
Freq: Q-JAN, dtype: int32
ts3.to_timestamp()
2010-08-01 0
2010-11-01 1
2011-02-01 2
2011-05-01 3
2011-08-01 4
2011-11-01 5
Freq: QS-NOV, dtype: int32
通过数组创建PeriodIndex
固定频率的数据集通常会将时间信息分开存放在多个列中。例如,在下面这个宏观经济数据集中,年度和季度就分别存放在不同的列中
data = pd.read_csv('F:/项目学习/利用Pyhon进行数据分析(第二版)/利用Pyhon进行数据分析/pydata-book-2nd-edition/examples/macrodata.csv')
data.head()
| year | quarter | realgdp | realcons | realinv | realgovt | realdpi | cpi | m1 | tbilrate | unemp | pop | infl | realint | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1959.0 | 1.0 | 2710.349 | 1707.4 | 286.898 | 470.045 | 1886.9 | 28.98 | 139.7 | 2.82 | 5.8 | 177.146 | 0.00 | 0.00 |
| 1 | 1959.0 | 2.0 | 2778.801 | 1733.7 | 310.859 | 481.301 | 1919.7 | 29.15 | 141.7 | 3.08 | 5.1 | 177.830 | 2.34 | 0.74 |
| 2 | 1959.0 | 3.0 | 2775.488 | 1751.8 | 289.226 | 491.260 | 1916.4 | 29.35 | 140.5 | 3.82 | 5.3 | 178.657 | 2.74 | 1.09 |
| 3 | 1959.0 | 4.0 | 2785.204 | 1753.7 | 299.356 | 484.052 | 1931.3 | 29.37 | 140.0 | 4.33 | 5.6 | 179.386 | 0.27 | 4.06 |
| 4 | 1960.0 | 1.0 | 2847.699 | 1770.5 | 331.722 | 462.199 | 1955.5 | 29.54 | 139.6 | 3.50 | 5.2 | 180.007 | 2.31 | 1.19 |
index=pd.PeriodIndex(year=data.year,quarter=data.quarter,freq='Q-DEC')
index
PeriodIndex(['1959Q1', '1959Q2', '1959Q3', '1959Q4', '1960Q1', '1960Q2',
'1960Q3', '1960Q4', '1961Q1', '1961Q2',
...
'2007Q2', '2007Q3', '2007Q4', '2008Q1', '2008Q2', '2008Q3',
'2008Q4', '2009Q1', '2009Q2', '2009Q3'],
dtype='period[Q-DEC]', length=203)
data.index=index
data.infl
1959Q1 0.00
1959Q2 2.34
1959Q3 2.74
1959Q4 0.27
1960Q1 2.31
...
2008Q3 -3.16
2008Q4 -8.79
2009Q1 0.94
2009Q2 3.37
2009Q3 3.56
Freq: Q-DEC, Name: infl, Length: 203, dtype: float64
重采样及频率转换
重采样(resampling)指的是将时间序列从一个频率转换到另一个频率的处理过程。
将高频率数据聚合到低频率称为降采样(downsampling),而将低频率数据转换到高频率则称为升采样(upsampling)。并不是所有的重采样都能被划分到这两个大类中。例如,将W-WED(每周三)转换为W-FRI既不是降采样也不是升采样。
pandas对象都带有一个resample方法,它是各种频率转换工作的主力函数。resample有一个类似于groupby的API,调用resample可以分组数据,然后会调用一个聚合函数
rng=pd.date_range('2000-01-01',periods=100,freq='D')
ts=pd.Series(np.random.randn(len(rng)),index=rng)
ts
2000-01-01 -0.669571
2000-01-02 -1.044461
2000-01-03 -0.481993
2000-01-04 -1.133404
2000-01-05 -1.288657
...
2000-04-05 1.080972
2000-04-06 -0.360568
2000-04-07 1.406234
2000-04-08 -0.120072
2000-04-09 0.935523
Freq: D, Length: 100, dtype: float64
list(ts.resample('M'))
[(Timestamp('2000-01-31 00:00:00'),
2000-01-01 -0.669571
2000-01-02 -1.044461
2000-01-03 -0.481993
2000-01-04 -1.133404
2000-01-05 -1.288657
2000-01-06 -0.272591
2000-01-07 -0.528013
2000-01-08 0.504589
2000-01-09 0.534209
2000-01-10 -0.195754
2000-01-11 -0.681871
2000-01-12 -1.112560
2000-01-13 2.096374
2000-01-14 -1.520705
2000-01-15 -0.254708
2000-01-16 -0.375709
2000-01-17 -1.130941
2000-01-18 -1.390601
2000-01-19 -0.237225
2000-01-20 -0.633101
2000-01-21 0.942845
2000-01-22 -0.993924
2000-01-23 -1.456749
2000-01-24 -0.006961
2000-01-25 0.956246
2000-01-26 -0.367833
2000-01-27 -1.756500
2000-01-28 -0.832491
2000-01-29 0.678083
2000-01-30 0.406221
2000-01-31 -0.736602
Freq: D, dtype: float64),
(Timestamp('2000-02-29 00:00:00'),
2000-02-01 0.464724
2000-02-02 -0.105031
2000-02-03 2.260643
2000-02-04 -0.291663
2000-02-05 -0.231378
2000-02-06 -0.911392
2000-02-07 1.369952
2000-02-08 0.328929
2000-02-09 0.666395
2000-02-10 -0.784090
2000-02-11 -0.987542
2000-02-12 -0.190643
2000-02-13 1.067442
2000-02-14 1.305757
2000-02-15 0.707780
2000-02-16 0.752850
2000-02-17 0.307574
2000-02-18 -1.372087
2000-02-19 -0.009484
2000-02-20 -0.415510
2000-02-21 -0.524290
2000-02-22 -0.410307
2000-02-23 1.618978
2000-02-24 -1.994847
2000-02-25 -0.924586
2000-02-26 2.621486
2000-02-27 -0.886171
2000-02-28 -0.792322
2000-02-29 -0.353683
Freq: D, dtype: float64),
(Timestamp('2000-03-31 00:00:00'),
2000-03-01 0.101989
2000-03-02 1.386227
2000-03-03 0.378749
2000-03-04 1.376517
2000-03-05 0.530842
2000-03-06 1.112294
2000-03-07 0.991104
2000-03-08 -1.196767
2000-03-09 0.118670
2000-03-10 -0.910018
2000-03-11 0.576264
2000-03-12 -0.142747
2000-03-13 -1.161403
2000-03-14 -0.334490
2000-03-15 0.556489
2000-03-16 -0.587923
2000-03-17 0.089454
2000-03-18 -0.234425
2000-03-19 -0.829286
2000-03-20 0.973448
2000-03-21 0.759351
2000-03-22 0.115352
2000-03-23 -0.561077
2000-03-24 -1.165458
2000-03-25 0.161576
2000-03-26 0.185810
2000-03-27 -0.058259
2000-03-28 -1.500683
2000-03-29 0.703913
2000-03-30 -1.543016
2000-03-31 0.525858
Freq: D, dtype: float64),
(Timestamp('2000-04-30 00:00:00'),
2000-04-01 -0.072181
2000-04-02 0.845489
2000-04-03 0.256463
2000-04-04 0.552494
2000-04-05 1.080972
2000-04-06 -0.360568
2000-04-07 1.406234
2000-04-08 -0.120072
2000-04-09 0.935523
Freq: D, dtype: float64)]
ts.resample('M').mean()
2000-01-31 0.383776
2000-02-29 -0.180275
2000-03-31 -0.086058
2000-04-30 0.083742
Freq: M, dtype: float64
ts.resample('M',kind='period').mean()
2000-01 0.383776
2000-02 -0.180275
2000-03 -0.086058
2000-04 0.083742
Freq: M, dtype: float64
resample是一个灵活高效的方法,可用于处理非常大的时间序列
resample方法参数说明
| 参数 | 说明 |
|---|---|
| freq | 表示重采样频率的字符串或DateOffset |
| axis | 重采样的轴,默认axis=0 |
| fill_method | 升采样如何插值,比如‘ffill’或‘bfill’,默认不插值 |
| closed | 在降采样中,各时间段的哪一端是闭合的,right(默认)或left |
| label | 在降采样中,如何设置聚合值标签,right或left |
| loffset | 面元标签的时间校正值 |
| limit | 在前向或后向填充时,允许填充的最大时期数 |
| kind | 聚合到周期(period)或时间戳(timestamp),默认聚合到时间序列的索引类型 |
| convention | 当对周期进行重采样,将低频周期转换为高频的惯用法(start或end),默认end |
降采样
- 端点如何选
- 如何标记各个聚合面元,用区间的开头还是末尾
rng = pd.date_range('2000-01-01', periods=12, freq='T')
ts = pd.Series(np.arange(12), index=rng)
ts
2000-01-01 00:00:00 0
2000-01-01 00:01:00 1
2000-01-01 00:02:00 2
2000-01-01 00:03:00 3
2000-01-01 00:04:00 4
2000-01-01 00:05:00 5
2000-01-01 00:06:00 6
2000-01-01 00:07:00 7
2000-01-01 00:08:00 8
2000-01-01 00:09:00 9
2000-01-01 00:10:00 10
2000-01-01 00:11:00 11
Freq: T, dtype: int32
ts.resample('5min').sum()
#左端点
2000-01-01 00:00:00 10
2000-01-01 00:05:00 35
2000-01-01 00:10:00 21
Freq: 5T, dtype: int32
#以求和的方式将数据聚合到5分钟块中
ts.resample('5min', closed='right').sum()
1999-12-31 23:55:00 0
2000-01-01 00:00:00 15
2000-01-01 00:05:00 40
2000-01-01 00:10:00 11
Freq: 5T, dtype: int32
ts.resample('5min', closed='right', label='right').sum()
2000-01-01 00:00:00 0
2000-01-01 00:05:00 15
2000-01-01 00:10:00 40
2000-01-01 00:15:00 11
Freq: 5T, dtype: int32
ts.resample('5min', closed='right', label='right',offset='1s').sum()
#loffset现改为offset,
2000-01-01 00:00:01 0
2000-01-01 00:05:01 15
2000-01-01 00:10:01 40
2000-01-01 00:15:01 11
Freq: 5T, dtype: int32
ts.resample?
OHLC重采样
金融领域中有一种无所不在的时间序列聚合方式,即计算各面元的四个值:第一个值(open,开盘)、最后一个值(close,收盘)、最大值(high,最高)以及最小值(low,最低)
ts.resample('5min').ohlc()
| open | high | low | close | |
|---|---|---|---|---|
| 2000-01-01 00:00:00 | 0 | 4 | 0 | 4 |
| 2000-01-01 00:05:00 | 5 | 9 | 5 | 9 |
| 2000-01-01 00:10:00 | 10 | 11 | 10 | 11 |
升采样和插值
低频率转换到高频率
frame = pd.DataFrame(np.random.randn(2, 4),
index=pd.date_range('1/1/2000', periods=2,freq='W-WED'),
columns=['Colorado', 'Texas', 'New York', 'Ohio'])
frame
| Colorado | Texas | New York | Ohio | |
|---|---|---|---|---|
| 2000-01-05 | 0.039652 | 0.408064 | -0.510078 | 0.185826 |
| 2000-01-12 | -0.615524 | -0.037849 | -1.418894 | 0.653989 |
df_daily=frame.resample('D').asfreq()
df_daily
| Colorado | Texas | New York | Ohio | |
|---|---|---|---|---|
| 2000-01-05 | 0.039652 | 0.408064 | -0.510078 | 0.185826 |
| 2000-01-06 | NaN | NaN | NaN | NaN |
| 2000-01-07 | NaN | NaN | NaN | NaN |
| 2000-01-08 | NaN | NaN | NaN | NaN |
| 2000-01-09 | NaN | NaN | NaN | NaN |
| 2000-01-10 | NaN | NaN | NaN | NaN |
| 2000-01-11 | NaN | NaN | NaN | NaN |
| 2000-01-12 | -0.615524 | -0.037849 | -1.418894 | 0.653989 |
frame.resample('D').ffill()
| Colorado | Texas | New York | Ohio | |
|---|---|---|---|---|
| 2000-01-05 | 0.039652 | 0.408064 | -0.510078 | 0.185826 |
| 2000-01-06 | 0.039652 | 0.408064 | -0.510078 | 0.185826 |
| 2000-01-07 | 0.039652 | 0.408064 | -0.510078 | 0.185826 |
| 2000-01-08 | 0.039652 | 0.408064 | -0.510078 | 0.185826 |
| 2000-01-09 | 0.039652 | 0.408064 | -0.510078 | 0.185826 |
| 2000-01-10 | 0.039652 | 0.408064 | -0.510078 | 0.185826 |
| 2000-01-11 | 0.039652 | 0.408064 | -0.510078 | 0.185826 |
| 2000-01-12 | -0.615524 | -0.037849 | -1.418894 | 0.653989 |
frame.resample('D').ffill(limit=2)#limit限制前面的观测值的持续使用距离
| Colorado | Texas | New York | Ohio | |
|---|---|---|---|---|
| 2000-01-05 | 0.039652 | 0.408064 | -0.510078 | 0.185826 |
| 2000-01-06 | 0.039652 | 0.408064 | -0.510078 | 0.185826 |
| 2000-01-07 | 0.039652 | 0.408064 | -0.510078 | 0.185826 |
| 2000-01-08 | NaN | NaN | NaN | NaN |
| 2000-01-09 | NaN | NaN | NaN | NaN |
| 2000-01-10 | NaN | NaN | NaN | NaN |
| 2000-01-11 | NaN | NaN | NaN | NaN |
| 2000-01-12 | -0.615524 | -0.037849 | -1.418894 | 0.653989 |
frame.resample('W-THU').ffill()
| Colorado | Texas | New York | Ohio | |
|---|---|---|---|---|
| 2000-01-06 | 0.039652 | 0.408064 | -0.510078 | 0.185826 |
| 2000-01-13 | -0.615524 | -0.037849 | -1.418894 | 0.653989 |
通过时期进行重采样
对那些使用时期索引的数据进行重采样与时间戳相似
frame=pd.DataFrame(np.random.randn(24,4),
index=pd.period_range('1-2000','12-2001',freq='M'),
columns=['Colorado','Texas','New York','Ohio'])
frame[:5]
| Colorado | Texas | New York | Ohio | |
|---|---|---|---|---|
| 2000-01 | -0.638649 | -1.405857 | 0.415621 | -1.001946 |
| 2000-02 | 1.266635 | 0.550081 | -0.212091 | -0.355084 |
| 2000-03 | 1.703974 | 0.651728 | 0.990770 | 0.323334 |
| 2000-04 | -0.482890 | -0.609073 | 1.771766 | 0.546269 |
| 2000-05 | 1.356010 | 1.584438 | 0.788411 | -2.729561 |
annual_frame=frame.resample('A-DEC').mean()
annual_frame
| Colorado | Texas | New York | Ohio | |
|---|---|---|---|---|
| 2000 | 0.446096 | -0.051901 | 0.142156 | -0.407821 |
| 2001 | 0.127696 | 0.079421 | 0.186049 | 0.064369 |
升采样要稍微麻烦一些,必须要决定在新频率中各区间的哪端用于放置原来的值,就像asfreq方法。convention参数默认‘start’,也可设置‘end’
annual_frame.resample('Q-DEC').ffill()#Q-DEC每季度一次,截止到12月
| Colorado | Texas | New York | Ohio | |
|---|---|---|---|---|
| 2000Q1 | 0.446096 | -0.051901 | 0.142156 | -0.407821 |
| 2000Q2 | 0.446096 | -0.051901 | 0.142156 | -0.407821 |
| 2000Q3 | 0.446096 | -0.051901 | 0.142156 | -0.407821 |
| 2000Q4 | 0.446096 | -0.051901 | 0.142156 | -0.407821 |
| 2001Q1 | 0.127696 | 0.079421 | 0.186049 | 0.064369 |
| 2001Q2 | 0.127696 | 0.079421 | 0.186049 | 0.064369 |
| 2001Q3 | 0.127696 | 0.079421 | 0.186049 | 0.064369 |
| 2001Q4 | 0.127696 | 0.079421 | 0.186049 | 0.064369 |
annual_frame.resample('Q-DEC',convention='end').ffill()
| Colorado | Texas | New York | Ohio | |
|---|---|---|---|---|
| 2000Q4 | 0.446096 | -0.051901 | 0.142156 | -0.407821 |
| 2001Q1 | 0.446096 | -0.051901 | 0.142156 | -0.407821 |
| 2001Q2 | 0.446096 | -0.051901 | 0.142156 | -0.407821 |
| 2001Q3 | 0.446096 | -0.051901 | 0.142156 | -0.407821 |
| 2001Q4 | 0.127696 | 0.079421 | 0.186049 | 0.064369 |
由于时期指的是时间区间,所以升采样和降采样的规则就比较严格:
- 降采样中,目标频率必须是源频率的子时期(subperiod)
- 升采样中,目标频率必须是源频率的超时期(superperiod)
不满足上述条件,就会引发异常
annual_frame.resample('Q-MAR').ffill()
| Colorado | Texas | New York | Ohio | |
|---|---|---|---|---|
| 2000Q4 | 0.446096 | -0.051901 | 0.142156 | -0.407821 |
| 2001Q1 | 0.446096 | -0.051901 | 0.142156 | -0.407821 |
| 2001Q2 | 0.446096 | -0.051901 | 0.142156 | -0.407821 |
| 2001Q3 | 0.446096 | -0.051901 | 0.142156 | -0.407821 |
| 2001Q4 | 0.127696 | 0.079421 | 0.186049 | 0.064369 |
| 2002Q1 | 0.127696 | 0.079421 | 0.186049 | 0.064369 |
| 2002Q2 | 0.127696 | 0.079421 | 0.186049 | 0.064369 |
| 2002Q3 | 0.127696 | 0.079421 | 0.186049 | 0.064369 |
移动窗口函数
在移动窗口(可以带有指数衰减权数)上计算的各种统计函数也是一类常见于时间序列的数组变换。这样可以圆滑噪音数据或断裂数据。我将它们称为移动窗口函数(moving window function),其中还包括那些窗口不定长的函数(如指数加权移
动平均)。跟其他统计函数一样,移动窗口函数也会自动排除缺失值
close_px_all = pd.read_csv('F:/项目学习/利用Pyhon进行数据分析(第二版)/利用Pyhon进行数据分析/pydata-book-2nd-edition/examples/stock_px_2.csv',parse_dates=True, index_col=0)
close_px=close_px_all[['AAPL','MSFT','XOM']]
close_px
| AAPL | MSFT | XOM | |
|---|---|---|---|
| 2003-01-02 | 7.40 | 21.11 | 29.22 |
| 2003-01-03 | 7.45 | 21.14 | 29.24 |
| 2003-01-06 | 7.45 | 21.52 | 29.96 |
| 2003-01-07 | 7.43 | 21.93 | 28.95 |
| 2003-01-08 | 7.28 | 21.31 | 28.83 |
| ... | ... | ... | ... |
| 2011-10-10 | 388.81 | 26.94 | 76.28 |
| 2011-10-11 | 400.29 | 27.00 | 76.27 |
| 2011-10-12 | 402.19 | 26.96 | 77.16 |
| 2011-10-13 | 408.43 | 27.18 | 76.37 |
| 2011-10-14 | 422.00 | 27.27 | 78.11 |
2214 rows × 3 columns
close_px=close_px.resample('B').ffill()
close_px
| AAPL | MSFT | XOM | |
|---|---|---|---|
| 2003-01-02 | 7.40 | 21.11 | 29.22 |
| 2003-01-03 | 7.45 | 21.14 | 29.24 |
| 2003-01-06 | 7.45 | 21.52 | 29.96 |
| 2003-01-07 | 7.43 | 21.93 | 28.95 |
| 2003-01-08 | 7.28 | 21.31 | 28.83 |
| ... | ... | ... | ... |
| 2011-10-10 | 388.81 | 26.94 | 76.28 |
| 2011-10-11 | 400.29 | 27.00 | 76.27 |
| 2011-10-12 | 402.19 | 26.96 | 77.16 |
| 2011-10-13 | 408.43 | 27.18 | 76.37 |
| 2011-10-14 | 422.00 | 27.27 | 78.11 |
2292 rows × 3 columns
close_px.AAPL.plot()
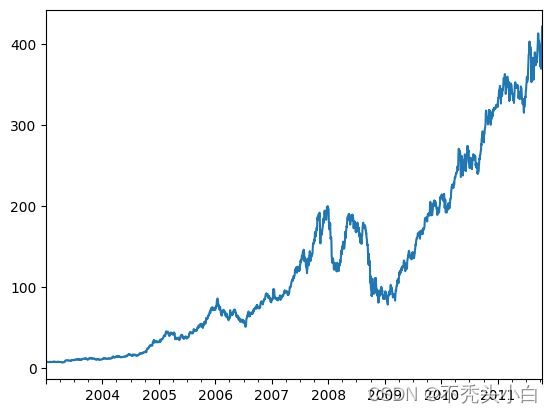
close_px.AAPL.plot()
close_px.AAPL.rolling(250).mean().plot()
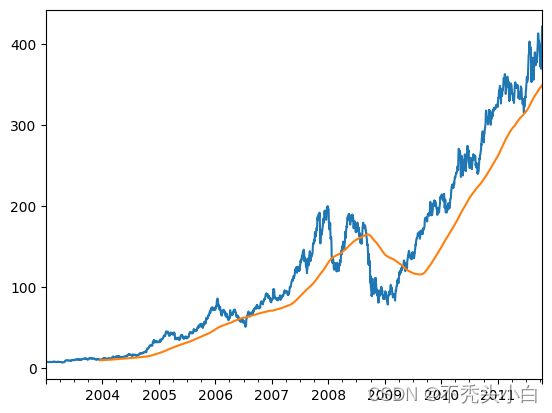
表达式rolling(250)与groupby很像,但不是对其进行分组,而是创建一个按照250天分组的滑动窗口对象。然后,我们就得到了苹果公司股价的250天的移动窗口。
默认情况下,rolling函数需要窗口中所有的值为非NA值。可以修改该行为以解决缺失数据的问题。其实,在时间序列开始处尚不足窗口期的那些数据就是个特例
appl_std250 = close_px.AAPL.rolling(250, min_periods=10).std()
appl_std250[5:12]
2003-01-09 NaN
2003-01-10 NaN
2003-01-13 NaN
2003-01-14 NaN
2003-01-15 0.077496
2003-01-16 0.074760
2003-01-17 0.112368
Freq: B, Name: AAPL, dtype: float64
appl_std250.plot()

要计算扩展窗口平均(expanding window mean),可以使用expanding而不是rolling。“扩展”意味着,从时间序列的起始处开始窗口,增加窗口直到它超过所有的序列。
expanding_mean = appl_std250.expanding().mean()
close_px.rolling(60).mean().plot(logy=True)

rolling函数也可以接受一个指定固定大小时间补偿字符串,而不是一组时期。这样可以方便处理不规律的时间序列。这些字符串也可以传递给resample
close_px.rolling('20D').mean()
| AAPL | MSFT | XOM | |
|---|---|---|---|
| 2003-01-02 | 7.400000 | 21.110000 | 29.220000 |
| 2003-01-03 | 7.425000 | 21.125000 | 29.230000 |
| 2003-01-06 | 7.433333 | 21.256667 | 29.473333 |
| 2003-01-07 | 7.432500 | 21.425000 | 29.342500 |
| 2003-01-08 | 7.402000 | 21.402000 | 29.240000 |
| ... | ... | ... | ... |
| 2011-10-10 | 389.351429 | 25.602143 | 72.527857 |
| 2011-10-11 | 388.505000 | 25.674286 | 72.835000 |
| 2011-10-12 | 388.531429 | 25.810000 | 73.400714 |
| 2011-10-13 | 388.826429 | 25.961429 | 73.905000 |
| 2011-10-14 | 391.038000 | 26.048667 | 74.185333 |
2292 rows × 3 columns
指数加权函数
另一种使用固定大小窗口及相等权数观测值的办法是,定义一个衰减因子(decayfactor)常量,以便使近期的观测值拥有更大的权数。衰减因子的定义方式有很多,比较流行的是使用时间间隔(span),它可以使结果兼容于窗口大小等于时间间隔的简单移动窗口(simple moving window)函数。
由于指数加权统计会赋予近期的观测值更大的权数,因此相对于等权统计,它能“适应”更快的变化。
除了rolling和expanding,pandas还有ewm运算符。
aapl_px = close_px.AAPL['2006':'2007']
ma60 = aapl_px.rolling(30, min_periods=20).mean()
ewma60 = aapl_px.ewm(span=30).mean()
ma60.plot(style='k--', label='Simple MA')
ewma60.plot(style='k-', label='EW MA')
plt.legend()

二元移动函数
有些统计运算(如相关系数和协方差)需要在两个时间序列上执行。例如,金融分析师常常对某只股票对某个参考指数(如标准普尔500指数)的相关系数感兴趣
spx_px = close_px_all['SPX']
spx_rets = spx_px.pct_change()
returns = close_px.pct_change()
corr = returns.AAPL.rolling(125, min_periods=100).corr(spx_rets)
corr.plot()
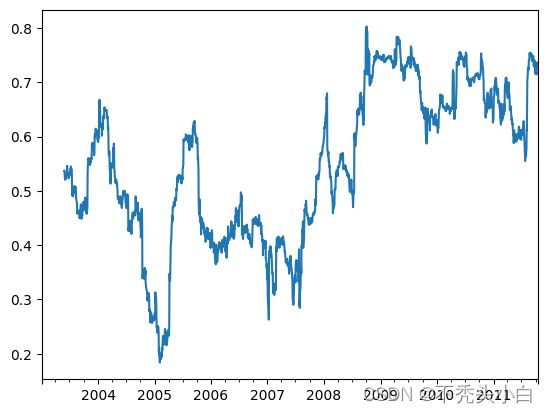
只需传入一个TimeSeries和一个DataFrame,rolling_corr就会自动计算TimeSeries(本例中就是spx_rets)与DataFrame各列的相关系数
corr = returns.rolling(125, min_periods=100).corr(spx_rets)
corr.plot()

用户自定义函数
rolling_apply函数使你能够在移动窗口上应用自己设计的数组函数。唯一要求的就是:该函数要能从数组的各个片段中产生单个值(即约简)
from scipy.stats import percentileofscore
score_at_2percent = lambda x: percentileofscore(x, 0.02)
result = returns.AAPL.rolling(250).apply(score_at_2percent)
result.plot()
