树和二叉树之线索二叉树(包括对前驱后继的疑惑)
1 树的概念
树的结点:包含一个数据元素及若干指向其子树的分支。
结点的度:结点拥有的子树数目。(一个分支就是一个树,二叉树结点的度最多为2,最少为0)
叶子:度为0的结点称为叶子。
树的度:整个树内出现的最大结点的度就是树的度。
孩子:结点的子树的根称为该结点的孩子。(结点的子树是指这个结点的一个分支,这个分支就是一个子树)
双亲:子树的根结点上面的结点就是他的双亲。(双亲是值一个父结点,不要看到双以为是两个结点)
结点的深度:树中结点的最大层数称为树的深度或高度。
如图1所示:

图1 树的结构
1.1、二叉树
1.1.1 二叉树的特点
由二叉树定义以及图示分析得出二叉树有以下特点:
1)每个结点最多有两颗子树,所以二叉树中不存在度大于2的结点。
2)左子树和右子树是有顺序的,次序不能任意颠倒。
3)即使树中某结点只有一棵子树,也要区分它是左子树还是右子树。
1.1.2 二叉树的性质
性质1 在二叉树的第i层上至多有 个结点。
个结点。
性质2 深度为k的二叉树至多有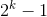 个结点。
个结点。
性质3 任意二叉树,如果度为0的结点树等于度为2的结点树+1。
性质4 具有n个结点的完全二叉树的深度为,其中是向下取整(如4.3取整数4)。
性质5 若对含 n 个结点的完全二叉树从上到下且从左至右进行 1 至 n 的编号,则对完全二叉树中任意一个编号为 i 的结点有如下特性:
(1)若 i=1,则该结点是二叉树的根,无双亲, 否则,编号为 [i/2] 的结点为其双亲结点;
(2)若 2i>n,则该结点无左孩子, 否则,编号为 2i 的结点为其左孩子结点;
(3)若 2i+1>n,则该结点无右孩子结点, 否则,编号为2i+1 的结点为其右孩子结点。
1.2、满二叉树
1.2.1 满二叉树定义
在一棵二叉树中。如果所有分支结点都存在左子树和右子树,并且所有叶子都在同一层上,这样的二叉树称为满二叉树。
1.2.2 满二叉树的特点有:
(1)叶子只能出现在最下一层。出现在其它层就不可能达成平衡。
(2)非叶子结点的度一定是2。
(3)在同样深度的二叉树中,满二叉树的结点个数最多,叶子数最多
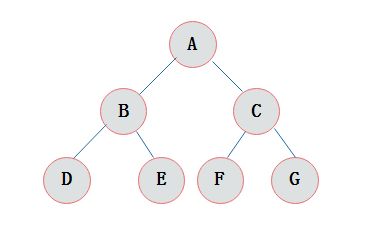
图2 满二叉树
1.3、完全二叉树
1.3.1 完全二叉树定义
若设二叉树的深度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第 h 层所有的结点都连续集中在最左边,这就是完全二叉树。(国内的定义).
1.3.2 完全二叉树特点:
(1)叶子结点只能出现在最下层和次下层。
(2)最下层的叶子结点集中在树的左部。
(3)倒数第二层若存在叶子结点,一定在左部连续位置。
(4)如果结点度为1,则该结点只有左孩子,即没有右子树。
(5)同样结点数目的二叉树,完全二叉树深度最小。
如图3所示:

图3 完全二叉树
具体看该博客:https://blog.csdn.net/xiaojin21cen/article/details/96148829#371__235
1.4 线索二叉树
这里只针对本人曾经理解线索二叉树时存在的误区做一些笔记,方便自己阅读。
首先要知道为什么需要线索二叉树,是为了更容易得到一颗二叉树任意一个结点的前去后继结点,对于一般的二叉树我们想要知道某个结点的前去后继时,那就是对该二叉树进行一次遍历,那么问题来了?
(1)什么是结点的前驱后继
解析:比如一颗二叉树经过中序遍历后,得到了一个线性的排序(这里的线性表示将那些结点按照中序遍历放入一个线性数组),比如一颗二叉树中序排列后为HDIBJEAFCG,J结点的前驱为B,后继为E,所以前驱后继是按照排序来定义

(2)书上和博客里面只有中序遍历二叉树的前驱和后继,难道不存在前序、后序遍历的前驱后继?还是用的很少,还是不存在?
解析:前序、中序、后序遍历结点会得到不同的排列,所以前驱后继都不一样,一般我们要知道这颗二叉树在创建时被要求按照什么方式存储的,比如前序还是中序或后序方式创建。譬如有个算法题:给出二叉树的一个结点,返回它中序遍历顺序的下一个结点。所以他也会要求你返回中序顺序的下一个,也就是中序结点的后继。
(3)很多书上说要使用线索二叉树将结点的前驱后继信息存放在该结点的空指针域上,因为普通二叉树每次想要得到一个结点的前驱后继时,都要重新遍历一次二叉树,而线索二叉树只需要遍历一次后就能终身想用。为什么普通二叉树每次都要遍历,不是遍历一次后就把排序存起来了吗?这样每次都去那个数组里面找它的前后不就行了?
解析:我的想法,首先我们确实可以遍历的时候将二叉树按照顺序重新排序放在一个数组里,这个数组中a[i]的前驱是a[i-1],后继是a[i+1],可是当一个二叉树很大时(10000个结点),如果你按照数组存起来,占用新的内存,工程中可能要不停的寻找前去后继,所以数组占用的内存不能释放,这将是多恐怖的事情,然后我突然想要找到第9998结点的前驱后继,难道你去对比数组里面的值,找到后再分别输出他的前驱和后继吗?既然不能那还有一种方式,每次想知道一个结点时,你传入这个结点地址(一般传入的参数就是这个结点的指针,有了该节点指针你可以指向自己结构体内的元素),我再去遍历这个二叉树,遍历过程中,结点指针会匹配到我们要找的那个结点,这时再将它遍历时前一个结点指针与后一个将要遍历的接口保存起来。下一次我又要树里面的一个结点的前去后继,这时你还是要重新遍历,对于需要经常访问某个结点的前驱后继代码中,这样时间不划算。所以出现了线索二叉树,创建二叉树时(创建过程也在遍历)就把空域的指针指向前驱后继,这样遍历一次后,那些结点本身包含了前驱后继的信息,你需要那里一个就找这个结点内的包含前去后继信息的指针。