大数据学习笔记-HDFS(一)
目录
1、企业存储系统
1.1 认识硬盘、RAID
1.2 存储架构
1.3 文件系统
1.4 文件系统的分类(按照位置)
1.5海量数据存储面临的问题
2、场景案例:如何实现分布式文件存储
2.1如何解决海量数据存的下的问题
2.2如何解决海量数据文件查询边界问题
2.3如何解决大文件传输效率慢的问题
2.4如何解决硬件故障导致的数据丢失问题
2.5 如何解决用户查询视角统一规整问题
3、分布式文件系统HDFS入门
3.1简介
3.2起源发展
3.3HDFS设计目标
3.4适用场景
3.5重要特性
4、微博HDFS案例
4.1 HDFS Shell Cli客户端
4.2 微博用户数据HDFS操作
4.3 HDFS Java 客户端API操作
学习目标:(1)了解企业存储系统相关概念、(2)掌握如何实现分布式文件存储系统、(3)理解HDFS概述、设计目标、应用场景(4)掌握HDFS重要特性(5)掌握HDFS Shell、Java操作(6)了解LibHDFS客户端
1、企业存储系统
近几年为何企业重视存储系统?
数字经济:人类通过大数据识别、选择、过滤、使用,引导资源快速优化配置和再生,实现经济高质量发展
产业互联网:企业数字化转型,传统业务数字化改造。降低成本、进行资源精准配置、提升效率、增加资产附加值、整合企业内外部数据,以数据支撑精细化运营
面临的首要问题:大规模数据存储
1.1 认识硬盘、RAID
硬盘:是计算机的主要存储硬件,可以用来存储数据,目前硬盘存储比较流行的是TB级的,分类:机械、固态、混合
硬盘不够了怎么办?
RAID(磁盘阵列):很多快独立的磁盘组合成一个容量巨大的磁盘组,容错。相关文章RAID磁盘阵列详解_kid00013的博客-CSDN博客,
1.2 存储架构
DAS存储架构:直连式存储,通过电缆、SCSI接口直接挂到服务器总线上,依赖操作系统进行IO,接口个数受限(结构:应用<-->存储系统<-->存储设备)
NAS网络接入存储:通过网络拓扑结构如以太网连接,共享文档、图片、电影等。一些NAS厂商也推出云存储和云共享。(结构:应用 《《网络》》存储系统<-->存储设备)
SAN存储区域网络存储:高速的、专门的用于存储的操作的网络,局域网内,通过高速交换机进行数据交换。(结构:应用<-->存储系统《《网络》》存储设备)
1.3 文件系统
文件系统:是一种存储和组织数据的方法。,下图是windows系统的文件目录。
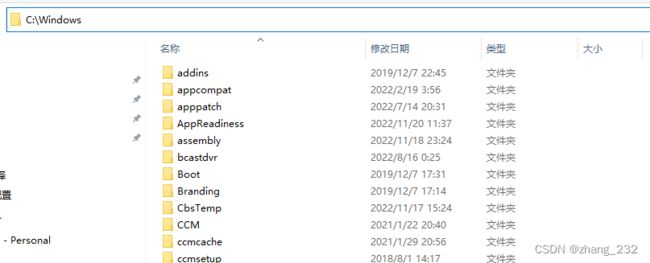
使用文件和树形目录的抽象概念代替了物理设备使用数据块的概念,用户使用文件系统没有必要关系底层数据存储再哪里(扇区,盘片),只需要记住文件所属目录和文件名。
文件系统通常使用硬盘、光盘这样的存储设备存储,并维护文件在设备中的物理位置
文件系统时一套实现了数据的存储、分级组织、访问和获得的一种抽象数据模型。
文件名:相同目录下不能重名(唯一性),DOS操作系统中包含文件主名和扩展名,之间一个小圆点隔开。可用于定位位置、区分不同文件。计算机实行按名存取的操作方式,某些特殊字符不能出现在文件名中。
元数据:解释性数据,记录数据的数据,例如
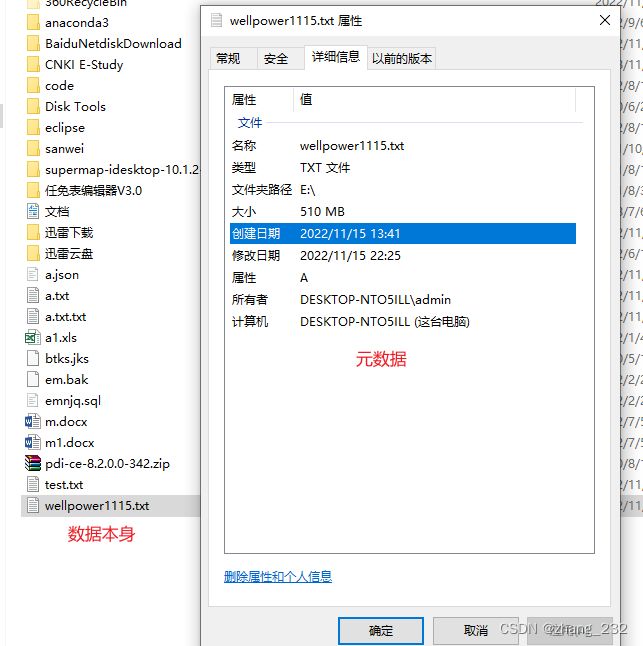
文件系统中一般是指文件的各类信息。
1.4 文件系统的分类(按照位置)
基于磁盘的文件系统,非易失。
虚拟文件系统:比如proc,Linux内核
网络文件系统:文件系统在其他地方,文件操作网络进行
1.5海量数据存储面临的问题
成本高:通用性差、设备投资加上后期维护、升级扩容的成本非常高
性能低:单节点IO瓶颈
可扩展性差:无法实现快速部署、动态扩容、缩容实现难度大
如何支撑高效率的计算分析:传统存储意味着存储是存储,计算是计算,需要将处理的数据移动过来,程序和数据存储不同厂商实现,无法有机整合
2、场景案例:如何实现分布式文件存储
产品设计不能追求单一指标的极限性。
2.1如何解决海量数据存的下的问题
- 单机纵向扩展,内存不够加内存,硬盘不够加硬盘,不能无限增加
- 多台横向扩展,采用多台机器存储,一台不够再加一台,可以无限扩展。
多台机器存储意味着分布式存储
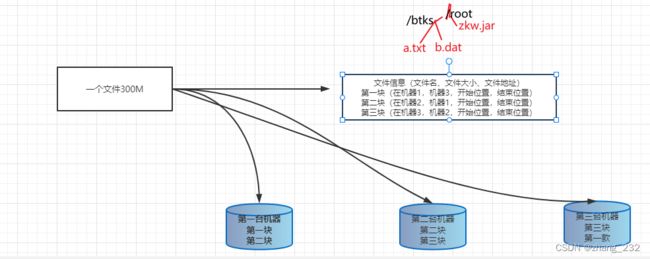
2.2如何解决海量数据文件查询边界问题
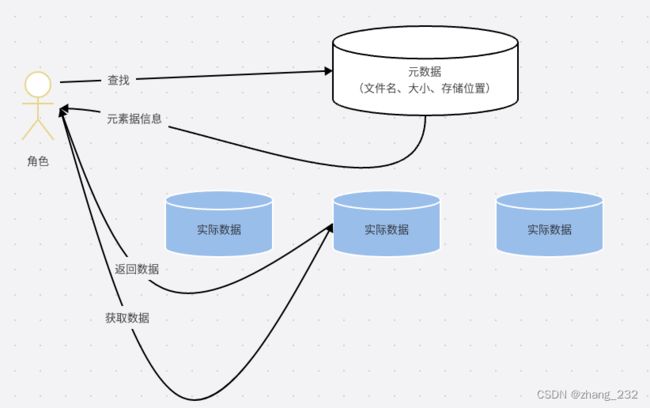
文件分布到多台机器,如何快速查找到文件哪,例如图书馆查找图书
借助元数据记录来姐姐这个问题,把文件和其存储的机器位置记录下来。
2.3如何解决大文件传输效率慢的问题
分块存储,把大文件拆分成若干小块,分别存储在不同机器上,并行操作,提高效率
同时解决了存储负载均衡的问题
元数据应该记录每一个文件块的信息。

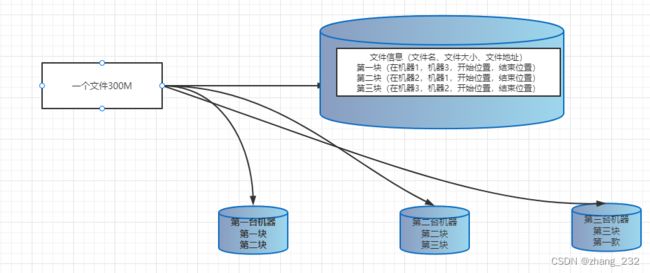
2.4如何解决硬件故障导致的数据丢失问题
冗余存储、副本机制,图下图,将每一块在其他机器上在存储一份。
2.5 如何解决用户查询视角统一规整问题
带有层次感的命名控件(namespace),抽象成树目录结构。
3、分布式文件系统HDFS入门
3.1简介
Hadoop Distributed File System,意为Hadoop分布文件存储系统,是Hadoop和核心组件之一,作为大数据生态圈最底层的分布式存储服务而存在,之解决存储问题,不解决计算和分析。
解决大数据如何存储的问题,横跨在多台机器上(可以是普通的廉价的已有的计算机)
高容错,适用于大数据集存储
提供统一的访问接口
3.2起源发展
Doug cutting(卡大爷)领导Nutch项目研发,Natch设计目标是构建一个大型的全网搜索引擎,网页抓取-->索引-->查询
数据抓取越来越多,遇到严重的可扩展性问题,如何解决数十亿网页的数据存储和索引问题
2003年谷歌开发出来GFS文件存储系统,写了一篇论文《分布式文件系统(GFS),可用于处理海量网页的存储》
Nutch开发人员完成了相应的开源实现,从Nutch中剥离出来和Mapreduce成立了Hadoop开源软件
3.3HDFS设计目标
- 硬件故障是常态,故障检测和自动快速恢复是HDFS的核心架构目标
- 流失读取输几局,而不是用户交互式,相较于数据访问的反应时间,更注重访问的高吞吐量
- 文件大小是GB到TB级的
- write-one-read-many(一次写入,多次读取)访问模型,一旦创建、写入、关闭之后不需要修改了,这一假设简化了数据一致性问题。
- 移动计算的代价比之移动数据的代价低。一个应用亲求的计算,操作的数据越近就越高效,将计算移动到数据附近
- 可以从一个平台轻松移植到另一个平台。
3.4适用场景
大文件、数据流式访问、一次写入多次读取、低成本部署,廉价pc、高容错
不适合场景:小文件、数据交互式访问(想怎么开发,编辑,保存)、频繁任意修改、低延迟处理。
3.5重要特性
主从架构:master/slave架构,几个HDFS集群有一个namenode和一定数目的datanode,namenode是主节点,datanode是HDFS的从节点
分块存储机制:物理上分块存储(block),块的大小可以通过参数配置来规定,参数位于hdfs-defalt.xml中,dfs.blocksize。默认大小是128M(134217728)
副本机制:文件的所有block都会有副本。每个文件的block大小和副本系数(dfs.replication)都是可以配置的默认是3,副本系统可以在文件创建的时候指定,,也可以通过命令改变,
namespace :支持传统的层次文件组织结构。用户可以创建目录、然后将文件保存在这些目录里面。文件系统名字控件的层次结构和大多数现有文件系统类似:用户可以创建、删除、移动、重命名文件。HDFS提供一个统一的抽象目录
元数据管理:namenode元数据具有两种类型:文件自身属性信息(名称、权限、修改时间、文件大小、复制因子、数据块大小)、文件块位置映射信息(记录文件块和datanode之间的映射信息,即哪个块位于那个节点上)
数据块存储:存储管理由dataNode节点承担

4、微博HDFS案例
4.1 HDFS Shell Cli客户端
命令行界面,指用户通过键盘数据指令,予以一种人机交互
命令行用法
hdfs dfs #根文件读写相关的命令
Usage: hadoop fs [generic options]
[-appendToFile ... ]
[-cat [-ignoreCrc] ...]
[-checksum ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] [-l] [-d] [-t ] ... ]
[-copyToLocal [-f] [-p] [-ignoreCrc] [-crc] ... ]
[-count [-q] [-h] [-v] [-t []] [-u] [-x] [-e] ...]
[-cp [-f] [-p | -p[topax]] [-d] ... ]
Usage: hdfs dfs [COMMAND [COMMAND_OPTIONS]]
Run a filesystem command on the file system supported in Hadoop. The various COMMAND_OPTIONS can be found at File System Shell Guide.
HDFS shell cli 支持操作多种文件系统,本地,分布式等
操作什么文件系统取决于url中前缀的协议file:/// ,hdfs://,,可以在文件中配置默认选项
hdfs dfs -ls hdfs://node1:8020 /
hdfs dfs -ls file:///hadoop dfs 只能操作HDFS文件系统(包括于local fs之间的操作),已经过时了
hdfs dfs 只能操作HDFS文件系统(包括Local fs之间的操作),常用
hadoop fs 可操作任意文件系统,不仅仅是hdfs文件系统,使用范围更广
目前官方推荐使用hadoop fs,当然hdfs dfs使用也较多文件操作命令根linux相似,可以通过hadoop fs --help学习。命令官网:Apache Hadoop 3.3.4 – Overview
4.2 微博用户数据HDFS操作
微博的大量用户评论数据,用于分析用户行为和习惯,进行精准分析和推送。
目录规划
| 目录 | 说明 |
| /source | 原始数据 |
| /common | 公共数据,ip,省份、经纬度 |
| /workspace | 计算出来的结果数据 |
| /tmp | 临时数据,每周清理 |
| /warehourse | 存储hive数据仓库中的数据 |
HDFS创建目录
hadoop fs -mkdir [-p]
# -p 创建父目录,可选
# path 创建的目录
hadoop fs -mkdir /common/
hadoop fs -mkdir /workspace/
hadoop fs -mkdir /tmp/
hadoop fs -mkdir /warehouse/
hadoop fs -mkdir /source/ 查看创建的目录
hadoop fs -ls -h -R /上传文件
# 创建目录
hadoop fs -mkdir -p /source/weibo/star/comment_log/20190810_node1.itcast.cn/
# 上传文件,本地还在
hadoop fs -put /export/data/caixukun.csv /source/weibo/star/comment_log/20190810_node1.itcast.cn
# moveFromLocal 上传,本地没有了
hadoop fs -moveFromLocal /export/data/caixukun.csv /tmp/查看hdfs文件
# 慎重使用cat命令,尤其是大文件
hadoop fs -cat /tmp/caixukun.csv
# 查看前1kb的内容
hadoop fs -head /tmp/caixukun.csv
# 查看后1kb的命令,可选参数-f,查看动态添加的内容
hadoop fs -tail /tmp/caixukun.csv
下载HDFS文件
hadoop fs -get [-f] [-p]
# -f 覆盖目标文件
# -p 保留访问和修改时间
hadoop fs -get /tmp/caixukun.csv /export/data/
hadoop fs -getmerge [-nl] [-skip-empty-file]
# [-nl] 每个文件后添加换行符
echo hello1 >> /export/data/1.txt
echo hello2 >> /export/data/2.txt
echo hello3 >> /export/data/3.txt
hadoop fs -put /export/data/1.txt /tmp/small
hadoop fs -put /export/data/2.txt /tmp/small
hadoop fs -put /export/data/3.txt /tmp/small
hadoop fs -getmerge /tmp/small/* /export/data/Hello.txt
cat /export/data/Hello.txt HDFS拷贝文件
# 准备文件夹
hadoop fs -mkdir -p /source/weibo/star/comment_log/20221121_node1.itcast.cn
# 拷贝数据
hadoop fs -cp /source/weibo/star/comment_log/20190810_node1.itcast.cn/caixukun.csv /source/weibo/star/comment_log/20221121_node1.itcast.cn/HDFS文件追加
hadoop fs -appendToFile /export/data/caixukun_new.csv /source/weibo/star/comment_log/20190810_node1.itcast.cn/caixukun.csv查看剩余空间
# 磁盘空间
hadoop fs -df -h /
# 文件使用的空间量
# hadoop fs -du [-s] [-h] [-v] /source/weibo/
hadoop fs -du -s -h -v /source/weibo/
-s 表示显示指定文件长度的汇总摘要,而不是单个文件的摘要数据移动
hadoop fs -mv
hadoop fs -mv /source/weibo/star/comment_log/20221121_node1.itcast.cn/caixukun.csv /tmp/caixukun_dirtydata.csv 修改HDFS文件副本个数(特别耗时,在文件上传时确定好)
hdfs dfs -setrep [-R] [-w]
#-w:标志请求命令等待复制完成。 这可能会花费很长时间。
#-R:标志是为了向后兼容。 没有作用。
hadoop fs -setrep -w 2 /tmp/caixukun_dirtydata.csv 其他命令
再次上官方手册
HDFS命令官方手册
奇yin巧计,在hdfs webui中操作,文件和文件夹属性具有下划线的属性,可以直接修改。
4.3 HDFS Java 客户端API操作
客户端核心类 Configuration 配置对象类,加载和设置参数属性
文件系统类 FileSystem 基类,针对不同实现,具有不同文件系统,封装了各类方法。
配置windows 系统hadoop。
- 将已经编译好的Windows版本Hadoop解压到到一个没有中文没有空格的路径下面
- 在windows上面配置hadoop的环境变量: HADOOP_HOME,并将%HADOOP_HOME%\bin添加到path中
配置HADOOP_HOME
建立maven项目
导包
org.apache.hadoop
hadoop-common
3.1.4
org.apache.hadoop
hadoop-client
3.1.4
org.apache.hadoop
hadoop-hdfs
3.1.4
junit
junit
4.13
org.apache.maven.plugins
maven-compiler-plugin
3.1
1.8
1.8
java代码
package cn.itcast.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
/**
* @author admin
*/
public class HdfsClientTest {
private static Configuration conf;
private static FileSystem fs;
/**
* 初始化方法,用于和hdfs集群建立连接
* @throws IOException
*/
@Before
public void connect2Hdfs() throws IOException {
//设置客户端身份,已具备权限在hdfs上进行操作
System.setProperty("HADOOP_USER_NAME","root");
//创建配置对象实例
conf = new Configuration();
//设置操作的文件系统时HDFS,并且指定HDFS操作地址 ,
// 因为虚拟机和程序不再同一网络,通过端口映射进行设置
//conf.set("fs.defaultFS","hdfs://node1:8020");
conf.set("fs.defaultFS","hdfs://192.168.31.201:8020");
//创建配置对象实例
fs = FileSystem.get(conf);
}
/**
* 创建文件夹操作
*/
@Test
public void mkdir() throws IOException {
//首先判断文件家是否存在,如果不存在再创建
String dirString = "/itheima";
if (!fs.exists(new Path(dirString))){
fs.mkdirs(new Path(dirString));
}
}
/**
* 上传文件到HDFS
*/
@Test
public void putFile2HDFS() throws IOException {
//创建本地文件路径,hdfs上传路径
String fileScrString = "D:\\hadoop-3.1.4\\README.txt";
String fileDstString = "/itheima/README.txt";
Path src = new Path(fileScrString);
Path dst = new Path(fileDstString);
fs.copyFromLocalFile(src,dst);
}
/**
* 下载文件
* @throws IOException
*/
@Test
public void getFile2HDFS() throws IOException {
//源路径
String fileScrString = "/tmp/small/1.txt";
String fileDstString = "D:\\hadoop-3.1.4\\README.txt";
Path src = new Path(fileScrString);
Path dst = new Path(fileDstString);
fs.copyToLocalFile(src,dst);
}
/**
* 关闭客户端和hfds连接
*/
@After
public void close(){
//首先判断文件系统对象是否为空,如果不为空,进行关闭
if (fs!=null){
try {
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
下载文件错误

因为不是编译源码的问题。缺失