从零开始搭建 Spring Cloud Alibaba(更新中)
一 简介
1.1 SCA简介
第⼀代 Spring Cloud (主要是 SCN)很多组件已经进⼊停更维护模式。Alibaba 搞出了Spring Cloud Alibaba(SCA),SCA 是由⼀些阿⾥巴巴 的开源组件和云产品组成的,2018年,Spring Cloud Alibaba 正式⼊住了 Spring Cloud 官⽅孵化器。Nacos(服务注册中⼼、配置中⼼) Sentinel哨兵(服 务的熔断、限流等) Seata分布式事务解决⽅案。
1.2 Nacos简介
是阿⾥巴巴开源的⼀个针 对微服务架构中服务发现、配置管理和服务管理平台。 Nacos就是注册中⼼ +配置中⼼的组合(Nacos= Eureka + Config + Bus) 官⽹:https://nacos.io 下载地址:https://githu b.com/alibaba/Nacos 。Nacos有⼀个ui⻚⾯,可以看到注册的 服务及其实例信息(元数据信息) 等),动态的服务权重调整、动态服务优雅下 线,都可以去做 Nacos功能特性 服务发现与健康检查 动 态配置管理 服务和元数据管理
1.3 Nacos单例服务部署
下载解压安装包,执⾏命令启动
linux/mac:
sh startup.sh -m standalone
windows:
cmd startup.cmd
访问nacos管理界面: http://IP地址:8848/nacos/#login(默认端⼝8848, 账号和密码 nacos/nacos)
二 使用Nacos 作为服务的注册中心
2.1 服务提供者注册到Nacos
在父项目中引入SCA依赖(原来的SCN依赖可以不删除,因为原来的服务提供则可以使用)
com.alibaba.cloud
spring-cloud-alibaba-dependencies
2.1.0.RELEASE
pom
import
服务提供者添加依赖
cn.kgc.qh
commons
1.0-SNAPSHOT
org.springframework.cloud
spring-cloud-starter-netflix-eureka-client
com.alibaba.cloud
spring-cloud-starter-alibaba-nacos-discovery
修改application.yml文件
server:
port: 100
spring:
application:
name: service-resume
datasource:
username: root
password: root
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/springcloud?serverTimezone=GMT&useUnicode=true&characterEncoding=utf8&useSSL=false
dbcp2:
max-idle: 10
min-idle: 10
cloud:
nacos:
discovery:
server-addr: 自己的外网ip:8848
username: 自己的用户名
password: 自己的密码
mybatis-plus:
type-aliases-package: cn.kgc.cn.kgc.qh.entity
mapper-locations: classpath:mapper/*.xml
configuration:
auto-mapping-behavior: full
map-underscore-to-camel-case: false
global-config:
db-config:
logic-delete-value: 1
logic-not-delete-value: 0
management:
endpoints:
web:
exposure:
include: "*"启动调用微服务

保护阈值:可以设置为0-1之间的浮点数,它其实是⼀个⽐例值(当前服务健康实例 数/当前服务总实例 数)。 场景: ⼀般流程下,nacos是服务注册中⼼,服务消费者要从nacos获取某⼀个服务的可⽤ 实例 信息,对于服务实例有健康/不健康状态之分,nacos在返回给消费者实例信息 的时候,会返回健康实 例。这个时候在⼀些⾼并发、⼤流量场景下会存在⼀定的问题。 如果服务A有50个实例,40个实例都不 健康了,只有10个实例是健康的,如果nacos 只返回这两个健康实例的信息的话,那么后续消费者的请 求将全部被分配到这两个 实例,流量洪峰到来,10个健康的实例也扛不住了,整个服务A 就扛不住,上 游的微 服务也会导致崩溃,,,产⽣雪崩效应。 保护阈值的意义在于当服务A健康实例数/总实例数 < 保护阈值 的时候,说明健康实例真的不多了,这个 时候保护阈值会被触发(状态true)。 nacos将会 把该服务所有的实例信息(健康的+不健康的)全部提供给消费者,消费 者可能访问到不健康的实例, 请求失败,但这样也⽐造成雪崩要好,牺牲了⼀些请 求,保证了整个系统的⼀个可⽤。
2.2 服务消费者从Nacos获取服务提供者
依赖
cn.kgc.qh
commons
1.0-SNAPSHOT
org.springframework.cloud
spring-cloud-starter-netflix-eureka-client
com.alibaba.cloud
spring-cloud-starter-alibaba-nacos-discovery
配置文件
server:
port: 82
spring:
application:
name: service-autodeliver
cloud:
nacos:
discovery:
server-addr: 自己的外网ip:8848
username: 自己的用户名(这个地方可以不需要配置,不配置就是默认的)
password: 自己的密码 (这个地方可以不需要配置,不配置就是默认的)
hystrix:
command:
default:
circuitBreaker:
forceOpen: false
# 触发熔断错误⽐例阈值,默认值50%
errorThresholdPercentage: 50
# 熔断器打开以后,每隔3秒钟 尝试调用服务的提供者
sleepWindowInMilliseconds: 3000
# 熔断触发最⼩请求次数,默认值是20
requestVolumeThreshold: 2
execution:
isolation:
thread:
# 熔断超时设置,默认为1秒
timeoutInMilliseconds: 4000
threadpool:
service-resume:
#线程池大小
coreSize: 2
#请求等待队列 默认值:-1 如果使用正数,队列将从SynchronizeQueue改为LinkedBlockingQueue
maxQueueSize: 1
#默认值:5 注意:如果maxQueueSize == -1,则此属性不适用。 此属性设置队列大小拒绝阈值
queueSizeRejectionThreshold: 10
#此属性设置保持活动时间,以分钟为单位
keepAliveTimeMinutes: 2
management:
endpoints:
web:
exposure:
include: "*"
# 暴露健康接⼝的细节
endpoint:
health:
show-details: always
feign:
hystrix:
enabled: true
compression:
request:
enabled: true # 开启请求压缩
mime-types: text/html,application/xml,application/json
min-request-size: 2048 # 设置触发压缩的⼤⼩下限,此处也是默认值
response:
enabled: true # 开启响应压缩
service-resume:
ribbon:
#请求连接超时时间
ConnectTimeout: 2000
#请求处理超时时间
ReadTimeout: 5000
#对所有操作都进⾏重试
OkToRetryOnAllOperations: true
MaxAutoRetries: 1 #对当前选中实例重试次数,不包括第⼀次调⽤
MaxAutoRetriesNextServer: 1 #切换实例的重试次数
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RoundRobinRule #负载策略调整三 搭建集群环境下的Nacos
3.1 安装3个或3个以上的Nacos
复制解压后的nacos⽂件夹,分别命名为nacos-01、nacos-02、nacos-03
#关闭nacos
cd /usr/software/nacos/bin
sh shutdown.sh
#修改nacos的文件的名字,将其改为nacos-01
cd /usr/software
mv nacos nacos-01
#复制
cp -r nacos-01 nacos-02
cp -r nacos-02 nacos-03
3.2 修改项目配置⽂件
同⼀台机器模拟,将上述三个⽂件夹中application.properties中的server.port分别改为 8848、8849、8850
3.3 分别修改Nacos的配置文件
application.properties文件
cd /usr/software/nacos-01/conf
vi applcation.properties
按 "i"键 进入编辑模式 修改以下内容:
server.port=8848
nacos.inetutils.ip-address=内网IP
db.num=1
### Connect URL of DB:
db.url.0=jdbc:mysql://内网IP:3306/nacos-config?
characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true
db.user=root
db.password=密码
按 "ESC" 键 进入命令模式
输入":wq"保存退出
cd /usr/software/nacos-01/conf
vi applcation.properties
按 "i"键 进入编辑模式 修改以下内容:
server.port=8849
nacos.inetutils.ip-address=内网IP
db.num=1
### Connect URL of DB:
db.url.0=jdbc:mysql://内网IP:3306/nacos-config?
characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true
db.user=root
db.password=密码
按 "ESC" 键 进入命令模式
输入":wq"保存退出
cd /usr/software/nacos-01/conf
vi applcation.properties
按 "i"键 进入编辑模式 修改以下内容:
server.port=8850
nacos.inetutils.ip-address=内网IP
db.num=1
### Connect URL of DB:
db.url.0=jdbc:mysql://内网IP:3306/nacos-config?
characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true
db.user=root
db.password=密码
按 "ESC" 键 进入命令模式
输入":wq"保存退出
三个服务器中都配置cluster.conf文件 依次修改3个文件
cd /usr/software/nacos-01/conf
mv cluster.conf.example cluster.conf
vi cluster.conf
按 "i"键 进入编辑模式,将原有内容删除掉,改为以下内容
内网IP:8848
内网IP:8849
内网IP:8850
按 "ESC" 键 进入命令模式
输入":wq"保存退出3.4 分别启动每个实例
sh startup.sh -m cluster如果有错误检查是 cat
cat /usr/software/nacos-n/logs/start.out没问题重新启动
cd /usr/software/nacos-0x/bin
sh shutdwon.sh
sh startup.sh -m cluster注意: 因为内存的问题,后面我们不使用集群了,还是使用单实例启动;
关闭集群
cd /usr/software/nacos-01/bin
sh shutdwon.sh
cd /usr/software/nacos-02/bin
sh shutdwon.sh
cd /usr/software/nacos-03/bin
sh shutdwon.sh3.5 设置nacos的内存大小

vi /usr/software/nacos-01/bin/startup.sh
按照上图内容进行修改。保存退出。重新单实例启动nacos-01
cd /usr/software/nacos-01/bin
sh startup.sh -m standalone四 Nacos 配置中心
4.1 领域模型
Namespace命名空间、Group分组、集群这些都是为了进⾏归类管理,把服务和配 置⽂件进⾏归类,归类之后就可以实现⼀定的效果,比如隔离⽐如,对于服务来说,不同命名空间中的服务不能够互相访问调用。
Namespace:命名空间,对不同的环境进⾏隔离,⽐如隔离开发环境、测试环境和 ⽣产环境Group:分组,将若⼲个服务或者若⼲个配置集归为⼀组,通常习惯⼀个系统归为 ⼀个组Service:某⼀个服务,⽐如简历微服务 DataId:配置集或者可以认为是⼀个配置⽂件Namespace + Group + Service 可以锁定对应的文件。

4.2 在Nacos Server中添加配置信息
创建配置之前先选中命名空间


4.3 改造具体的微服务
使其成为Nacos Config Client,能够从Nacos Server中获取到配置信息
4.3.1 添加依赖
com.alibaba.cloud
spring-cloud-starter-alibaba-nacos-config
4.3.2 微服务中需要指定配置文件(dataId)
通过 Namespace + Group + dataId 来锁定配置⽂件,Namespace不指定就默认 public,Group不指定就默认 DEFAULT_GROUP
dataId的完整格式如下:
${prefix}-${spring.profile.active}.${file-extension}prefix 默认为 spring.application.name 的值,也可以通过配置项 spring.cloud.nacos.config.prefix来配置。
spring.profile.active 即为当前环境对应的 profile。 注意:当 spring.profile.active 为空时,对应的连接符 - 也将不存在,dataId 的拼 接格式变成
${prefix}.${file-extension}file-exetension 为配置内容的数据格式,可以通过配置项 spring.cloud.nacos.config.file-extension 来配置。⽬前只⽀持 properties 和 yaml 类型。
注意此时配置文件名必须是bootstrap.yml
cloud:
nacos:
discovery:
# 集群中各节点信息都配置在这⾥
server-addr: 自己的外网ip:8848
config:
server-addr: 自己的外网ip:8848
namespace: 自己的namespace #namespace的一长串
group: DEFAULT_GROUP #默认的名字
file-extension: yaml #文件的格式
prefix: test #文件的前缀
这个时候我的前缀是 test 文件格式是yaml 去访问看能不能访问的到


最后是拿到了结果 是正常的!
但是大家想一个问题 我如果有多个一样的文件 哪个优先级最高呢?怎么写?还有开启动态刷新 总不能每次都手动重启服务吧
ext-config[0]:
data-id: a.yml
group: DEFAULT_GROUP
refresh: true #开启扩展dataId的动态刷新
ext-config[1]:
data-id: b.yml
group: DEFAULT_GROUP
refresh: true #开启扩展dataId的动态刷新


写个测试访问一下


拿到了第二个
15 Sentinel
一 Sentinel介绍
1.1 Hystrix
服务消费者(⾃动投递微服务)--> 调⽤服务提供者(简历微服务) 在调用方引入Hystrix --> 单独搞了⼀个Dashboard项目 --> Turbine。
问题
1) 自己搭建监控平台 dashboard 2)没有提供UI界⾯进⾏服务熔断、服务降级等配置
1.2 Sentinel
Sentinel是⼀个⾯向云原⽣微服务的流量控制、熔断降级组件。 替代Hystrix,针对问题:服务雪崩、服务降级、服务熔断、服务限流。
1)独⽴可部署Dashboard/控制台组件 2)减少代码开发,通过UI界⾯配置即可完成细粒度控制(⾃动投递微服务)
Sentinel 分为两个部分:核⼼库:(Java 客户端)不依赖任何框架/库,能够运⾏于所有 Java 运⾏时环境,同时对 Dubbo / Spring Cloud 等框架也有较好的⽀持。 控制台:(Dashboard)基于 Spring Boot 开发,打包后可以直接运⾏,不需 要额外的 Tomcat 等应⽤容器。
1.3 Sentinel 具有以下特征
丰富的应⽤场景:Sentinel 承接了阿⾥巴巴近 10 年的双⼗⼀⼤促流量的核⼼场景,例如秒杀(即突发流量控制在系统容量可以承受的范围)、消息削峰填⾕、 集群流量控制、实时熔断下游不可用应用等。
完备的实时监控:Sentinel 同时提供实时的监控功能。您可以在控制台中看到 接⼊应⽤的单台机器秒级数据,甚至 500 台以下规模的集群的汇总运⾏情况。 ⼴泛的开源⽣态:Sentinel 提供开箱即⽤的与其它开源框架/库的整合模块,例 如与 Spring Cloud、Dubbo的整合。您只需要引⼊相应的依赖并进⾏简单的配 置即可快速地接⼊ Sentinel。
完善的 SPI 扩展点:Sentinel 提供简单易⽤、完善的 SPI 扩展接⼝。您可以通过 实现扩展接⼝来快速地定制逻辑。例如定制规则管理、适配动态数据源等。
1.4 下载运行Sentinel
http://localhost:8080
帐号 sentinel
密码 sentinel
二 使用Sentinel
2.1 接入sentinel
在我们已有的业务场景中,“⾃动投递微服务”调⽤了“简历微服务”,我们在⾃动投递 微服务进⾏的熔断降级等控制,那么接下来我们改造⾃动投递微服务,引⼊Sentinel 核⼼包。
com.alibaba.cloud
spring-cloud-starter-alibaba-sentinel
application.yml
server:
port: 81
spring:
application:
name: service-autodeliver
cloud:
nacos:
discovery:
server-addr: 内网IP:8848
username: 账号
password: 密码
config:
file-extension: yaml
server-addr:内网IP:8848
group: DEFAULT_GROUP
prefix: autodeliver
namespace: #自己填写
ext-config[0]:
data-id: a.yaml
group: DEFAULT_GROUP
refresh: true #开启扩展dataId的动态刷新
ext-config[1]:
data-id: b.yaml
group: DEFAULT_GROUP
refresh: true #开启扩展dataId的动态刷新
sentinel:
transport:
dashboard: 127.0.0.1:8080 #指定dashboard位置
port: 8719 #接收sentinel dashboard发送给我们的数据(dashboard配置的规则)
management:
endpoints:
web:
exposure:
include: "*"
# 暴露健康接⼝的细节
endpoint:
health:
show-details: always
service-resume:
ribbon:
#请求连接超时时间
ConnectTimeout: 2000
#请求处理超时时间
##########################################Feign超时时⻓设置
ReadTimeout: 3000
#对所有操作都进⾏重试
OkToRetryOnAllOperations: true
MaxAutoRetries: 0 #对当前选中实例重试次数,不包括第⼀次调⽤
MaxAutoRetriesNextServer: 0 #切换实例的重试次数
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RoundRobinRule #负载策略调整启动⾃动投递微服务,访问接口后,使⽤ Sentinel 监控⾃动投递微服务。
2.2 Sentinel 关键概念
资源:它可以是 Java 应⽤程序中的任何内容,例如,由应⽤程序提供的服务,可以是⼀段代码。我们请求 的API接⼝就是资源。
规则:围绕资源的实时状态设定的规则,可以包括流量控制规则、熔断降级规则 以及系统保护规则。所有规则可以动态实时调整。
2.3 Sentinel 流量规则模块
系统并发能⼒有限,⽐如系统A的QPS⽀持1个,如果太多请求过来,那么A就应该进 ⾏流量控制了,⽐如其他请求直接拒绝。

2.4 限流规则讲解
2.4.1 QPS
当调⽤该资源的QPS达到阈值时进⾏限流
超过此频率直接报错

如果服务A 调用服务B,服务B达到指定压力后,限流服务A
 选择关联 qps一秒 请求超过1 就会报错
选择关联 qps一秒 请求超过1 就会报错
如果B的服务 超过了阈值 那么就会失败
我们这里用 postman 测一下


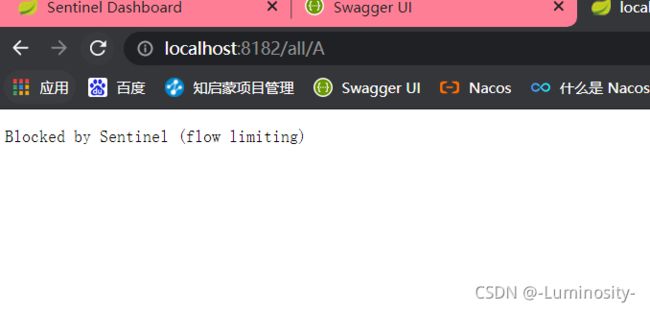
这时候去访问A就会挂掉
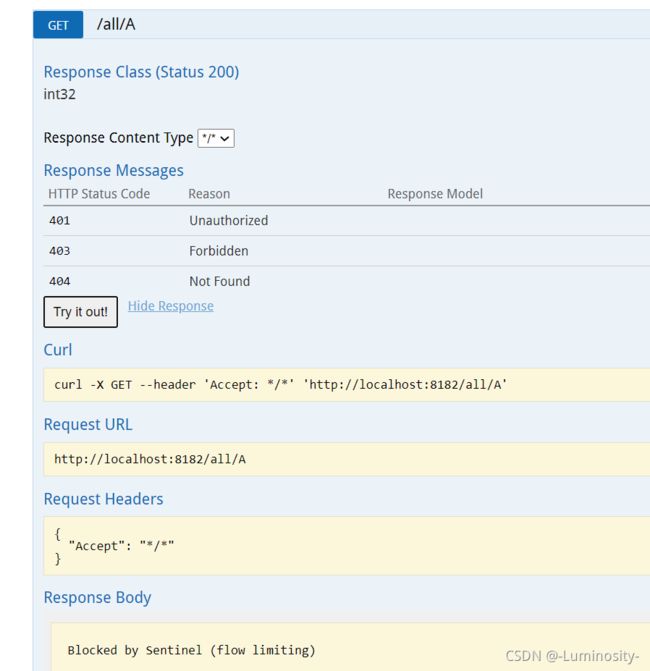
排队等待 如果B的请求超过了1 就会排队等待1秒钟
下面测一测线程 
用的是JMeter 测试线程
第一步新建线程组




访问测试 是不行的
链路

比如链路模式下设置 入口资源为 Entrance1 来表示只有从入口 Entrance1 的调用才会记录到 NodeA 的限流统计当中,而不关心经 Entrance2 到来的调⽤。
预热

排队等待
必须在QPS中使用,否则无效。

排队等待模式下会严格控制请求通过的间隔时间,即请求会匀速通过,允许部分请 求排队等待,通常⽤于消息队列削峰填⾕等场景。需设置具体的超时时间,当计算 的等待时间超过超时时间时请求就会被拒绝。
很多流量过来了,并不是直接拒绝请求,⽽是请求进⾏排队,⼀个⼀个匀速通过 (处理),请求能等就等着被处理,不能等(等待时间>超时时间)就会被拒绝。例如,QPS 配置为 5,则代表请求每 200 ms 才能通过⼀个,多出的请求将排队等 待通过。超时时间代表最⼤排队时间,超出最⼤排队时间的请求将会直接被拒绝。 排队等待模式下,QPS 设置值不要超过 1000(请求间隔 1 ms)。
2.4.2 线程数
当调⽤该资源的线程数达到阈值的时候进⾏限流(线程处理请求的时候, 如果说业务逻辑执⾏时间很⻓,流量洪峰来临时,会耗费很多线程资源,这些线程 资源会堆积,最终可能造成服务不可⽤,进⼀步上游服务不可⽤,最终可能服务雪 崩)
2.5 熔断规则讲解
2.5.1 Hystrix熔断规则

Sentinel不会像Hystrix那样放过⼀个请求尝试⾃我修复,就是明明确确按照时间窗 ⼝来,熔断触发后, 时间窗⼝内拒绝请求,时间窗⼝后就恢复。
2.5.2 RT
当 1s 内持续进⼊ >=5 个请求,平均响应时间超过阈值(以 ms 为单位),那么 在接下的时间窗⼝(以 s 为单位)之内,对这个⽅法的调⽤都会⾃动地熔断(抛 出 DegradeException)。
注意 Sentinel 默认统计的 RT 上限是 4900 ms,超出 此阈值的都会算作 4900 ms,若需要变更此上限可以通过启动配置项 -Dcsp.sentinel.statistic.max.rt=xxx 来配置。

2.5.3 异常比
当资源的每秒请求量 >= 5,并且每秒异常总数占通过量的⽐值超过阈值之后, 资源进⼊降级状态,即在接下的时间窗⼝(以 s 为单位)之内,对这个⽅法的调 ⽤都会⾃动地返回。异常⽐率的阈值范围是 [0.0, 1.0],代表 0% - 100%。

2.5.4 异常数
当资源近 1 分钟的异常数⽬超过阈值之后会进⾏熔断。
注意由于统计时间窗⼝ 是分钟级别的,若 timeWindow ⼩于 60s,则结束熔断状态后仍可能再进⼊熔 断状态。

三 兜底 Sentinel
@GetMapping("/{id}")
@ApiOperation(value = "根据ID获得简历信息",
produces = "application/json;charset=utf-8",httpMethod = "GET",
response = CommonsResponse.class)
@ApiImplicitParam(name = "id",value = "简历的ID",paramType = "path",dataType = "int") @SentinelResource(value = "get",blockHandlerClass = RResumeHandler.class,
blockHandler = "getHandler")
public CommonsResponse get(@PathVariable(value = "id") int id){
int result=5/0;
return rResumeService.get(id);
} @FeignClient(value = "service-resume",path = "/rResume",fallback =RResumeServiceImpl.class )
public interface RResumeService {
@GetMapping("/{id}")
CommonsResponse get(@PathVariable(value = "id") int id);
} public class RResumeHandler {
public static CommonsResponse getHandler(int id, BlockException blockException){
return CommonsResponse.builder().data(null).code(200).message("ok").build();
}
}将以前commons中的异常处理代码拷入。
四 基于 Nacos 实现 Sentinel 规则持久化
Sentinel Dashboard中添加的规则数据存储在内存,微服务停掉规则数据就 消失,在⽣产环境下不合适。我们可以将Sentinel规则数据持久化到Nacos配置中 心,让微服务从Nacos获取规则数据。

需要保存sentiel配置的微服务中添加依赖
com.alibaba.csp
sentinel-datasource-nacos
修改配置文件
spring:
application:
name: service-autodeliver
cloud:
nacos:
discovery:
server-addr: 外网:8848
username: nacos
password: kgcqh
config:
namespace: f4a1a383-289f-471e-a907-220a1bcfc55a
prefix: deliver #默认读取的是和服务的名字相同的配置文件
group: DEFAULT_GROUP
file-extension: yaml
server-addr: 外网:8848
#Data ID: ${spring.application.name}-${spring.profiles.active}.yaml
ext-config[0]:
data-id: a.yaml
group: DEFAULT_GROUP
refresh: true #动态刷新
ext-config[1]:
data-id: b.yaml
group: DEFAULT_GROUP
refresh: true
sentinel:
transport:
dashboard: localhost:8080
port: 8719
datasource:
ds1: # 流控规则1
nacos:
server-addr: ${spring.cloud.nacos.discovery.server-addr}
data-id: ${spring.application.name}-flow-rule
groupId: DEFAULT_GROUP
data-type: json
rule-type: flow
ds2:
nacos:
server-addr: ${spring.cloud.nacos.discovery.server-addr}
data-id: ${spring.application.name}-degrade-rules
groupId: DEFAULT_GROUP
data-type: json
rule-type: degrade在nacos中保存相应规则
dataId: service-autodeliver-flow-rule
[
{
"resource": "/findResume",
"limitApp": "default",
"grade": 1,
"count": 5,
"strategy": 0,
"controlBehavior": 0,
"clusterMode": false
}
]resource:资源名称
limitApp:来源应⽤
grade:阈值类型 0 线程数 1 QPS
count:单机阈值
strategy:流控模式,0 直接 1 关联 2 链路
controlBehavior:流控效果,0 快速失败 1 Warm Up 2 排队等待
clusterMode:true/false 是否集群dataId: service-autodeliver-degrade-rules
[
{
"resource":"/findResume",
"grade":2,
"count":1,
"timeWindow":5
}
]resource:资源名称
grade:降级策略: 0 RT 1:异常⽐例 2:异常数
count:阈值
timeWindow:时间窗待更新..........(服务器 JDK的安装,nacos的安装,数据库的安装,nacos各种组件,中间件的使用)