leetcode 11.27 双周赛题解(前三题)
leetcode 11.27 双周赛题解(前三题)
昨天打了双周赛,感觉下来就是手速场,由于今天上午去打了校内的蓝桥杯校选赛,也就没有打今天上午的周赛,有机会开下模拟写下题解
昨天的前三题并不难,我认为涵盖了哈希表,贪心(半模拟),脑筋急转弯(对,你没看错)
1. 先装一下

噢,不会以为我是要装*吧,当然不是
因为

555 这些人都是什么怪物,(太恐怖了吧)
向这些大佬salute!
2. 统计出现过一次的公共字符串——哈希表
给你两个字符串数组 words1 和 words2 ,请你返回在两个字符串数组中 都恰好出现一次 的字符串的数目。
题目链接:https://leetcode-cn.com/contest/biweekly-contest-66/problems/count-common-words-with-one-occurrence/
题目样例
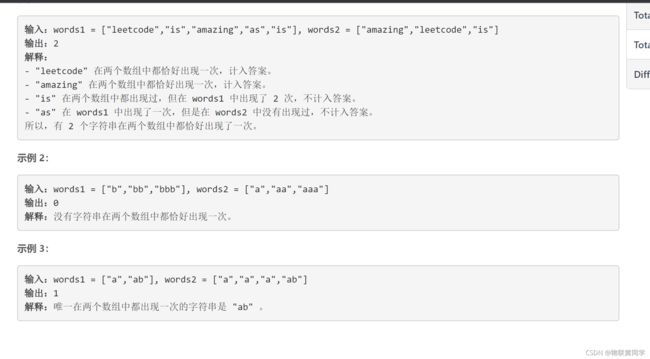
提示:
1 <= words1.length, words2.length <= 10001 <= words1[i].length, words2[j].length <= 30words1[i]和words2[j]都只包含小写英文字母。
对于第一题,我们都是可以比较暴力的解决的,所以我们可以直接两个循环套上去,很快的,但是啊,难道我们打竞赛是为了快点AC嘛?(其实是再快也快不过那些大佬),其实我一开始并不是使用暴力两重循环,而是想到了哈希表
什么是哈希表
个人见解:哈希表就是一个映射表,含key和value,键值对映射,说白了就是就是一个变量指向另一个变量,你想到了什么?
我想到了数组,因为我们的数组的下标就是索引,而索引 i 就是key,而 arr[i] 则是对应的value
下面是题解代码
class Solution {
public:
int countWords(vector<string>& words1, vector<string>& words2) {
// 哈希图,string作为key, int存储次数
unordered_map<string, int> hashmap;
// 遍历第一个字符串数组,存入哈希图
for(string word : words1)
{
hashmap[word]++;
}
unordered_map<string, int> hashmap1;
// 遍历第二个
for(string word : words2)
{
hashmap1[word]++;
}
int ans = 0;
// 这里遍历哪一个都行
for(string word : words1)
{
// 必须是都为对应的数量都为1才可以满足题目要求
if(hashmap[word] == 1 && hashmap1[word] == 1)
{
ans++;
hashmap[word] = 0;
hashmap1[word] = 0;
}
}
return ans;
}
};
3. 从房屋收集雨水需要的最小桶数——贪心,模拟
给你一个下标从 0 开始的字符串 street 。street 中每个字符要么是表示房屋的 'H' ,要么是表示空位的 '.' 。
你可以在 空位 放置水桶,从相邻的房屋收集雨水。位置在 i - 1 或者 i + 1 的水桶可以收集位置为 i 处房屋的雨水。一个水桶如果相邻两个位置都有房屋,那么它可以收集 两个 房屋的雨水。
在确保 每个 房屋旁边都 至少 有一个水桶的前提下,请你返回需要的 最少 水桶数。如果无解请返回 -1 。
题目链接:https://leetcode-cn.com/contest/biweekly-contest-66/problems/minimum-number-of-buckets-required-to-collect-rainwater-from-houses/
实例,可以自己点链接跳转(太多了,不想截屏)
题解思路
我是采用模拟的思路,需要规避一些特殊情况,看一写dalao是用贪心写的,有兴趣的小伙伴可以去看一下
代码
class Solution {
public:
int minimumBuckets(string street) {
int ans = 0;
int len = street.length();
// 特殊情况
if(len == 1 && street[0] == 'H')
{
return -1;
}
for(int i = 0; i < len; ++i)
{
// 中间下标,访问两边
if(i > 0 && i < len - 1)
{
// 只考虑当前为房屋
if(street[i] == 'H')
{
if(street[i - 1] == 'H' && street[i + 1] == 'H')
{
return -1;
}
if(street[i + 1] =='.' && street[i - 1] == '.')
{
ans++;
// 默认把后一个作为水桶,并修改,防止二次访问
street[i + 1] = '+';
}
else if(street[i + 1] == 'H' && street[i - 1] == '.')
{
ans++;
street[i - 1] = '+';
}
else if(street[i - 1] == 'H' && street[i + 1] == '.')
{
ans++;
street[i + 1] = '+';
}
}
}
// 首位
else if(i == 0)
{
if(street[i] == 'H')
{
if(street[i + 1] == 'H')
{
return -1;
}
street[i + 1] = '+';
ans++;
}
}
// 末位
else
{
if(street[i] == 'H')
{
if(street[i - 1] == 'H')
{
return -1;
}
else if(street[i - 1] == '.')
{
ans++;
}
}
}
}
return ans;
}
};
这代码写得是真的臭,但是时间和空间复杂度是真的低。
4. 网格图中机器人回家的最小代价——脑筋急转弯
给你一个 m x n 的网格图,其中 (0, 0) 是最左上角的格子,(m - 1, n - 1) 是最右下角的格子。给你一个整数数组 startPos ,startPos = [startrow, startcol] 表示 初始 有一个 机器人 在格子 (startrow, startcol) 处。同时给你一个整数数组 homePos ,homePos = [homerow, homecol] 表示机器人的 家 在格子 (homerow, homecol) 处。
机器人需要回家。每一步它可以往四个方向移动:上,下,左,右,同时机器人不能移出边界。每一步移动都有一定代价。再给你两个下标从 0 开始的额整数数组:长度为 m 的数组 rowCosts 和长度为 n 的数组 colCosts 。
- 如果机器人往 上 或者往 下 移动到第
r行 的格子,那么代价为rowCosts[r]。 - 如果机器人往 左 或者往 右 移动到第
c列 的格子,那么代价为colCosts[c]。
请你返回机器人回家需要的 最小总代价 。
题目链接https://leetcode-cn.com/contest/biweekly-contest-66/problems/minimum-cost-homecoming-of-a-robot-in-a-grid/
示例
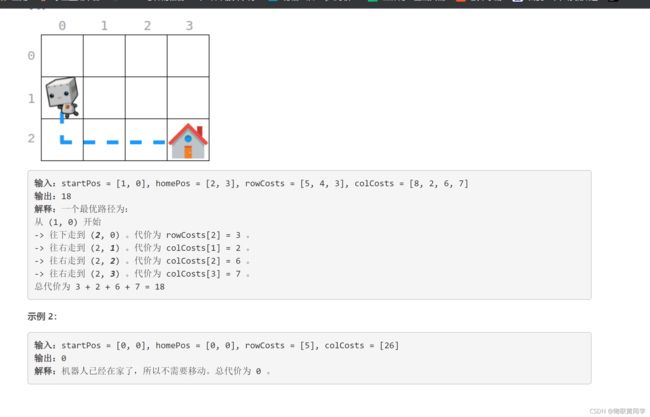
思路
说实话,我差点用dp,后面一看,这不是固定走的嘛,不管怎么走,都是要跨行跨列(指始末点的行列不同),直接对应加即可,但是,我们可以做一些处理
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-X14nSRFl-1638112391004)(C:\Users\86152\AppData\Roaming\Typora\typora-user-images\image-20211128230429747.png)]
我们一般希望start和end的关系能这样,即起始点的行和列都小于等于终点,而由于无论从起点到终点还是终点到起点的代价都是一样(除了端点)所以在算结果前,我们只需要做下交换,就可以在计算结果时,只需考虑一种路径即可。
题解代码
class Solution {
public:
int minCost(vector<int>& startPos, vector<int>& homePos, vector<int>& rowCosts, vector<int>& colCosts) {
// 判断是否需要交换
if(startPos[0] > homePos[0])
{
// 交换坐标前,需要把对应的代价也交换
swap(rowCosts[startPos[0]], rowCosts[homePos[0]]);
swap(startPos[0], homePos[0]);
}
if(startPos[1] > homePos[1])
{
swap(colCosts[startPos[1]], colCosts[homePos[1]]);
swap(startPos[1], homePos[1]);
}
int ans = 0;
// 遍历即可,至同行同列,即到终点
while(startPos[0] < homePos[0])
{
ans += rowCosts[startPos[0] + 1];
startPos[0]++;
}
while(startPos[1] < homePos[1])
{
ans += colCosts[startPos[1] + 1];
startPos[1]++;
}
return ans;
}
};