机器学习: 简单讲极大似然估计和贝叶斯估计、最大后验估计
一、前言
我在概率论:参数估计里面提到了极大似然估计,不熟悉的可以看一下,本文重点介绍后两者估计方法。
在这里两种估计方法估计的是什么?我们使用一个较为泛化的问题表示:
考虑这样一个问题:总体X的概率密度函数为 p ( x ∣ θ ) p(x|\theta) p(x∣θ),但该密度函数未知,我们只观测到一组样本 ( x 1 , x 2 , … , x n ) \left(x_{1}, x_{2}, \ldots, x_{n}\right) (x1,x2,…,xn) ,我们需要估计的是参数 θ \theta θ,且最终目的都是根据 θ \theta θ给出总体X的概率密度函数 p ( x ∣ θ ) p(x|\theta) p(x∣θ)。
下面我们将采用不同的估计方法来求解这个问题,并将说明三种估计方法的区别和联系。
二、极大似然估计
1. 极大似然估计的过程
在进行贝叶斯分类的时候,通常需要知道 P ( w i ) , P ( x ∣ w i ) P(w_i), P(x|w_i) P(wi),P(x∣wi)的值,在这里 w i w_i wi表示第i类。但是与 P ( x ∣ w i ) P(x|w_i) P(x∣wi)所相关的分布所包含的参数通常是未知的(比如说假设 P ( x ∣ w i ) P(x|w_i) P(x∣wi)服从正态分布,那么它的均值和方差通常是未知的。
为了简化问题,我们认为 P ( x ∣ w i ) ∼ N ( u i , Σ i ) P(x | w_i) \sim N( u_i, \Sigma _i) P(x∣wi)∼N(ui,Σi)(即服从正态分布,一般都这样干):。此时我们想知道概率 P ( x ∣ w i ) P(x | w_i) P(x∣wi),就需要根据已有的样本估计 u i , Σ i u_i, \Sigma _i ui,Σi
根据上述的问题简化,我们有
p ( x ∣ ω j ) ∼ N ( μ j , Σ j ) p ( x ∣ ω j ) ≡ p ( x ∣ ω j , θ j ) \begin{aligned} &p\left(x \mid \omega_{j}\right) \sim N\left(\mu_{j}, \Sigma_{j}\right) \\ &p\left(x \mid \omega_{j}\right) \equiv p\left(x \mid \omega_{j}, \theta_{j}\right) \end{aligned} p(x∣ωj)∼N(μj,Σj)p(x∣ωj)≡p(x∣ωj,θj)
其中,
θ j = ( μ j , Σ j ) = ( μ j 1 , μ j 2 , … , σ j 1 , σ j 2 … ) \theta_{j}=\left(\mu_{j}, \Sigma_{j}\right)=\left(\mu_{j}^{1}, \mu_{j}^{2}, \ldots, \sigma_{j}^{1}, \sigma_{j}^{2} \ldots\right) θj=(μj,Σj)=(μj1,μj2,…,σj1,σj2…)
给定训练样本 D = ( x 1 , x 2 , … , x n ) D=(x_1,x_2,…,x_n) D=(x1,x2,…,xn)如何估计 θ \theta θ?
极大似然估计的一个思想就是“存在即合理”。就是样本既然存在了,那么我认为在它所服从的分布中,它的出现的可能性是最大的(这就是极大似然)
接下来就求所有数据出现的一个联合概率。
p ( D ∣ θ ) = ∏ k = 1 k = n p ( x k ∣ w , θ ) = ∏ k = 1 k = n p ( x k ∣ θ ) = F ( θ ) p(D \mid \theta)=\prod_{k=1}^{k=n} p\left(x_{k} \mid w, \theta\right)=\prod_{k=1}^{k=n} p\left(x_{k} \mid \theta\right)=F(\theta) p(D∣θ)=k=1∏k=np(xk∣w,θ)=k=1∏k=np(xk∣θ)=F(θ)
p ( D ∣ θ ) p(D \mid \theta) p(D∣θ) is called the likelihood of θ \theta θ
此时我们把这个联合概率看作 θ \theta θ的函数(似然函数),那么当该函数取得最大值时的 θ ^ \hat \theta θ^,是 θ \theta θ真实值的一个合理估计。举例说明:

2. 极大似然估计的优缺点
- 优点
具有良好的收敛性,即使样本量增加
比任何其他替代技术都更简单,因此计算复杂度更低。 - 缺点
极大似然估计的参数只拟合观测到的样本,如果观测到的样本并不能很好的代表总体样本的分布,那么极大似然估计是不准确的。
三、贝叶斯估计
在极大似然估计中,它认为参数是固定的,但未知!固定就是指它只有一个值。
但是贝叶斯估计将参数视为具有某些已知先验分布的随机变量。也就是说 θ \theta θ本身也服从一个分布。这样其实是可以避免参数只拟合观测到的样本的,因为我们假设参数 θ \theta θ本身也服从一个分布,不是由观测样本完全决定的。
1. 浅谈 p ( x ) 和 p ( x ∣ θ ) p(x)和p(x|\theta) p(x)和p(x∣θ)的关系
给定一个随机变量X,现在经过抽样,我们得到一组样本 D = ( x 1 , x 2 , … , x n ) D=\left(x_{1}, x_{2}, \ldots, x_{n}\right) D=(x1,x2,…,xn), 我们希望通过观察到的这组样本知道X的一个具体分布,该分布的概率密度函数为p(x),因为借此我们可以得知一个具体的样本,它出现的概率是多少。
所以一切的目标是想要得到p(x)。但是只有一组样本,我们甚至连p(x)是关于什么的函数都不知道。
于是我们进一步做出合理的假设(称为条件),设p(x)的参数是 θ \theta θ,但它未知。
这还不够,我并不知道这个概率密度函数是个什么形式,我们还需要进行假设。一般我们会假设它是正态分布(当然也可以是其他分布),这就是我们说的服从什么什么分布。
所以可以知道p(x)是x的一个关于某个分布的概率密度函数(没法根据样本求出)。
p ( x ∣ θ ) p(x|\theta) p(x∣θ)是设定了参数 θ \theta θ, 且设定了是关于某种分布的概率密度函数(可以根据假设和给定样本求出)。
所以不同的符号表示其实都是表示关于x的概率密度函数,符号 p ( x ∣ θ ) p(x|\theta) p(x∣θ)表示给出的关于x的概率密度函数是基于某两个条件的。
2. θ \theta θ本身也服从一个分布,如何给出x的概率密度函数 p ( x ) p(x) p(x)
此时一种思路就是遍历变量 θ \theta θ的每一种可能取值,然后求 p ( x ∣ θ ) p(x|\theta) p(x∣θ)的平均,作为关于x的概率密度函数。也就是:
∫ p ( x ∣ θ ) p ( θ ∣ D ) d θ \int p(\mathbf{x} \mid \boldsymbol{\theta}) p(\boldsymbol{\theta} \mid \mathcal{D}) d \boldsymbol{\theta} ∫p(x∣θ)p(θ∣D)dθ
这里我们认为 θ \theta θ的分布应当从训练样本D中得到,所以使用了后验条件分布的概率密度函数 p ( θ ∣ D ) p(\boldsymbol{\theta} \mid \mathcal{D}) p(θ∣D)。
另外,这样得到的关于x的概率密度函数的信息其实最开始是从D中得到的,为了做区别,我们认为这个关于x的概率密度函数应当用一个后验分布的新符号表示,即
p ( x ∣ D ) = ∫ p ( x ∣ θ ) p ( θ ∣ D ) d θ p(\mathbf{x} \mid \mathcal{D})=\int p(\mathbf{x} \mid \boldsymbol{\theta}) p(\boldsymbol{\theta} \mid \mathcal{D}) d \boldsymbol{\theta} p(x∣D)=∫p(x∣θ)p(θ∣D)dθ
值得注意的是当变量 θ \theta θ取定某一个值时,跟本节1.讨论的结果一样,也是假设 p ( x ∣ θ ) p(x|\theta) p(x∣θ)的分布形式是已知的(人为选定的,如是参数为 θ \theta θ的正态分布)。
因此,现在需要求的就是 p ( θ ∣ D ) p(\boldsymbol{\theta} \mid \mathcal{D}) p(θ∣D)。直接求没法求,这里用到了贝叶斯公式(或许这就是称为贝叶斯估计的原因)。
p ( θ ∣ D ) = p ( D ∣ θ ) p ( θ ) ∫ p ( D ∣ θ ) p ( θ ) d θ = α ∏ k = 1 n p ( x k ∣ θ ) p ( θ ) \begin{aligned} p(\theta \mid \mathcal{D}) &=\frac{p(\mathcal{D} \mid \theta) p(\theta)}{\int p(\mathcal{D} \mid \theta) p(\theta) d \theta} \\ &=\alpha \prod_{k=1}^{n} p\left(x_{k} \mid\theta\right) p(\theta) \end{aligned} p(θ∣D)=∫p(D∣θ)p(θ)dθp(D∣θ)p(θ)=αk=1∏np(xk∣θ)p(θ)
根据上面的讨论可知, p ( x k ∣ θ ) p\left(x_{k} \mid\theta\right) p(xk∣θ)的分布形式是已知的,因此它的值是可求的。这里的 p ( θ ) p(\theta) p(θ)又是什么呢?根据贝叶斯公式我们需要这个值才能计算,因此我们又需要再次假设一个 θ \theta θ的原始分布,它的概率密度函数是 p ( θ ) p(\theta) p(θ)。这个分布的形式和参数是人为选定的,常见的如均匀分布,正态分布等。
下面我们从一个例子再次阐述上面的过程。
3. 例子:单变量的情况 θ = μ \theta=\mu θ=μ
现在我们假设
p ( x ∣ μ ) ∼ N ( μ , σ 2 ) ( 3.1 ) p(x \mid \mu) \sim N\left(\mu, \sigma^{2}\right) (3.1) p(x∣μ)∼N(μ,σ2)(3.1)
并且设 θ \theta θ的原始分布为已知值 µ 0 , σ 0 2 µ_0, σ_0^2 µ0,σ02的正态分布
p ( μ ) ∼ N ( μ 0 , σ 0 2 ) ( 3.2 ) p(\mu) \sim N\left(\mu_{0}, \sigma_{0}^{2}\right)(3.2) p(μ)∼N(μ0,σ02)(3.2)
此时我们求参数 μ \mu μ的后验分布
p ( μ ∣ D ) = p ( D ∣ μ ) p ( μ ) ∫ p ( D ∣ μ ) p ( μ ) d μ = α ∏ k = 1 n p ( x k ∣ μ ) p ( μ ) ( 3.3 ) \begin{aligned} p(\mu \mid \mathcal{D}) &=\frac{p(\mathcal{D} \mid \mu) p(\mu)}{\int p(\mathcal{D} \mid \mu) p(\mu) d \mu} \\ &=\alpha \prod_{k=1}^{n} p\left(x_{k} \mid \mu\right) p(\mu) \end{aligned}(3.3) p(μ∣D)=∫p(D∣μ)p(μ)dμp(D∣μ)p(μ)=αk=1∏np(xk∣μ)p(μ)(3.3)
根据上面的两个分布假设3.1,3.1,我们有
p ( μ ∣ D ) = α ∏ k = 1 n 1 2 π σ exp [ − 1 2 ( x k − μ σ ) 2 ] 1 2 π σ 0 exp [ − 1 2 ( μ − μ 0 σ 0 ) 2 ] = α ′ exp [ − 1 2 ( ∑ k = 1 n ( μ − x k σ ) 2 + ( μ − μ 0 σ 0 ) 2 ) ] = α ′ ′ exp [ − 1 2 [ ( n σ 2 + 1 σ 0 2 ) μ 2 − 2 ( 1 σ 2 ∑ k = 1 n x k + μ 0 σ 0 2 ) μ ] ( 3.4 ) \begin{aligned} p(\mu \mid \mathcal{D}) &=\alpha \prod_{k=1}^{n} \frac{1}{\sqrt{2 \pi} \sigma} \exp \left[-\frac{1}{2}\left(\frac{x_{k}-\mu}{\sigma}\right)^{2}\right] \frac{1}{\sqrt{2 \pi} \sigma_{0}} \exp \left[-\frac{1}{2}\left(\frac{\mu-\mu_{0}}{\sigma_{0}}\right)^{2}\right] \\ &=\alpha^{\prime} \exp \left[-\frac{1}{2}\left(\sum_{k=1}^{n}\left(\frac{\mu-x_{k}}{\sigma}\right)^{2}+\left(\frac{\mu-\mu_{0}}{\sigma_{0}}\right)^{2}\right)\right] \\ &=\alpha^{\prime \prime} \exp \left[-\frac{1}{2}\left[\left(\frac{n}{\sigma^{2}}+\frac{1}{\sigma_{0}^{2}}\right) \mu^{2}-2\left(\frac{1}{\sigma^{2}} \sum_{k=1}^{n} x_{k}+\frac{\mu_{0}}{\sigma_{0}^{2}}\right) \mu\right]\right. \end{aligned}(3.4) p(μ∣D)=αk=1∏n2πσ1exp[−21(σxk−μ)2]2πσ01exp[−21(σ0μ−μ0)2]=α′exp[−21(k=1∑n(σμ−xk)2+(σ0μ−μ0)2)]=α′′exp[−21[(σ2n+σ021)μ2−2(σ21k=1∑nxk+σ02μ0)μ](3.4)
然后我们可以将其化简为正态分布的形式
p ( μ ∣ D ) = 1 2 π σ n exp [ − 1 2 ( μ − μ n σ n ) 2 ] ( 3.5 ) p(\mu \mid \mathcal{D})=\frac{1}{\sqrt{2 \pi} \sigma_{n}} \exp \left[-\frac{1}{2}\left(\frac{\mu-\mu_{n}}{\sigma_{n}}\right)^{2}\right](3.5) p(μ∣D)=2πσn1exp[−21(σnμ−μn)2](3.5)
其中需满足:
1 σ n 2 = n σ 2 + 1 σ 0 2 μ n σ n 2 = n σ 2 x ˉ n + μ 0 σ 0 2 ( 3.6 ) \begin{gathered} \frac{1}{\sigma_{n}^{2}}=\frac{n}{\sigma^{2}}+\frac{1}{\sigma_{0}^{2}} \\ \frac{\mu_{n}}{\sigma_{n}^{2}}=\frac{n}{\sigma_{2}} \bar{x}_{n}+\frac{\mu_{0}}{\sigma_{0}^{2}} \end{gathered}(3.6) σn21=σ2n+σ021σn2μn=σ2nxˉn+σ02μ0(3.6)
求解上述方程可得
x ˉ n = 1 n ∑ k = 1 n x k μ n = ( n σ 0 2 n σ 0 2 + σ 2 ) x ˉ n + σ 2 n σ 0 2 + σ 2 μ 0 σ n 2 = σ 0 2 σ 2 n σ 0 2 + σ 2 ( 3.7 ) \begin{gathered} \bar{x}_{n}=\frac{1}{n} \sum_{k=1}^{n} x_{k}\\ \mu_{n}=\left(\frac{n \sigma_{0}^{2}}{n \sigma_{0}^{2}+\sigma^{2}}\right) \bar{x}_{n}+\frac{\sigma^{2}}{n \sigma_{0}^{2}+\sigma^{2}} \mu_{0} \\ \sigma_{n}^{2}=\frac{\sigma_{0}^{2} \sigma^{2}}{n \sigma_{0}^{2}+\sigma^{2}} \end{gathered} (3.7) xˉn=n1k=1∑nxkμn=(nσ02+σ2nσ02)xˉn+nσ02+σ2σ2μ0σn2=nσ02+σ2σ02σ2(3.7)
此时将3.5带入下式求积分可得到最终的关于x的概率密度函数
p ( x ∣ D ) = ∫ p ( x ∣ μ ) p ( μ ∣ D ) d μ p(\mathbf{x} \mid \mathcal{D})=\int p(\mathbf{x} \mid \boldsymbol{\mu}) p(\boldsymbol{\mu} \mid \mathcal{D}) d \boldsymbol{\mu} p(x∣D)=∫p(x∣μ)p(μ∣D)dμ
三、极大后验估计(MAP estimators (Max a posteriori))
极大后验估计可以说是极大似然估计和贝叶斯估计思想的融合。首先它跟贝叶斯估计一样,也假设参数是变量,服从某个已知分布。但是它不会遍历变量 θ \theta θ的每一种可能取值,然后求 p ( x ∣ θ ) p(x|\theta) p(x∣θ)的平均。相反,它是取 θ \theta θ的所有值中最有可能的取值 θ ^ \hat \theta θ^,然后给出 p ( x ∣ θ ^ ) p(x|\hat \theta) p(x∣θ^)。那这个最有可能的取值其实就是 p ( θ ∣ D ) p(\boldsymbol{\theta} \mid \mathcal{D}) p(θ∣D)取最大值时参数 θ \theta θ的取值 θ ^ \hat \theta θ^.
θ ^ map = arg max θ p ( θ ∣ D ) = arg max θ p ( D ∣ θ ) p ( θ ) ∫ p ( D ∣ θ ) p ( θ ) d θ = arg max θ p ( D ∣ θ ) p ( θ ) \hat{\boldsymbol{\theta}}_{\text {map }}=\arg \max _{\boldsymbol{\theta}} p(\boldsymbol{\theta} \mid \mathcal{D})=\arg \max _{\boldsymbol{\theta}} \frac{p(\mathcal{D} \mid \theta) p(\theta)}{\int p(\mathcal{D} \mid \theta) p(\theta) d \theta}=\arg \max _{\boldsymbol{\theta}} p(\mathcal{D} \mid \theta) p(\theta) θ^map =argθmaxp(θ∣D)=argθmax∫p(D∣θ)p(θ)dθp(D∣θ)p(θ)=argθmaxp(D∣θ)p(θ)
这里 ∫ p ( D ∣ θ ) p ( θ ) d θ \int p(\mathcal{D} \mid \theta) p(\theta) d \theta ∫p(D∣θ)p(θ)dθ求完积分后不再是包含 θ \theta θ的函数,因此视为常数忽略掉。
在很多文章里面,最大后验估计是如下这样表达的:
θ ^ map = arg max θ π ( θ ∣ x ) = arg max θ f ( x ∣ θ ) π ( θ ) m ( x ) = arg max θ f ( x ∣ θ ) π ( θ ) \hat{\boldsymbol{\theta}}_{\text {map }}=\arg \max _{\boldsymbol{\theta}} \pi(\boldsymbol{\theta} \mid \boldsymbol{x})=\arg \max _{\boldsymbol{\theta}} \frac{f(\boldsymbol{x} \mid \boldsymbol{\theta}) \pi(\boldsymbol{\theta})}{m(\boldsymbol{x})}=\arg \max _{\boldsymbol{\theta}} f(\boldsymbol{x} \mid \boldsymbol{\theta}) \pi(\boldsymbol{\theta}) θ^map =argθmaxπ(θ∣x)=argθmaxm(x)f(x∣θ)π(θ)=argθmaxf(x∣θ)π(θ)
上面两个式子的 D \mathcal{D} D和 x \boldsymbol{x} x意义是一致的,表示观测样本。但本文使用 D \mathcal{D} D表示观测样本,用 x \boldsymbol{x} x表示总体样本,所以为了避免混淆,采用第一个公式表达。
四、贝叶斯估计和最大后验估计
当 p ( θ ∣ D ) p(\boldsymbol{\theta} \mid \mathcal{D}) p(θ∣D)的函数图像非常的尖锐的时候,贝叶斯估计约等于最大后验估计。
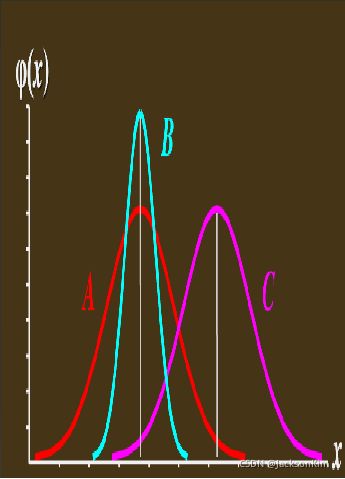
比如图中B曲线十分尖锐,对于即当 θ = θ ^ \theta = \hat \theta θ=θ^时,概率接近于1.此时
p ( x ∣ D ) = ∫ p ( x ∣ θ ) p ( θ ∣ D ) d θ ≅ p ( x ∣ θ ^ ) p(x \mid D)=\int p(x \mid \theta) p(\theta \mid D) d \theta\cong p(x \mid \hat\theta) p(x∣D)=∫p(x∣θ)p(θ∣D)dθ≅p(x∣θ^)
此时贝叶斯估计给出的关于x的概率密度函数非常接近 p ( x ∣ θ ^ ) p(x \mid \hat\theta) p(x∣θ^),最大后验估计给出的关于x的概率密度函数就是 p ( x ∣ θ ^ ) p(x \mid \hat\theta) p(x∣θ^),因此我们说他们此时是近似的。
五、极大似然估计和最大后验估计
在最大后验估计中,如果我们认为 θ \theta θ的先验分布是一个均匀分布,即 p ( θ ) p(\theta) p(θ)为常数C,那么最大后验估计变为
arg max θ p ( D ∣ θ ) C \arg \max _{\boldsymbol{\theta}} p(\mathcal{D} \mid \theta) C argθmaxp(D∣θ)C
此时它等价于极大似然估计。
六、频率学派和贝叶斯学派
1.频率学派
他们认为世界是确定的。他们直接为事件本身建模,也就是说事件在多次重复实验中趋于一个稳定的值p,那么这个值就是该事件的概率。
他们认为模型参数是个定值,希望通过类似解方程组的方式从数据中求得该未知数。这就是频率学派使用的参数估计方法-极大似然估计(MLE),这种方法往往在大数据量的情况下可以很好的还原模型的真实情况。
2.贝叶斯学派
他们认为世界是不确定的,因获取的信息不同而异。假设对世界先有一个预先的估计,然后通过获取的信息来不断调整之前的预估计。 他们不试图对事件本身进行建模,而是从旁观者的角度来说。因此对于同一个事件,不同的人掌握的先验不同的话,那么他们所认为的事件状态也会不同。
他们认为模型参数源自某种潜在分布,希望从数据中推知该分布。对于数据的观测方式不同或者假设不同,那么推知的该参数也会因此而存在差异。这就是贝叶斯派视角下用来估计参数的常用方法-最大后验概率估计(MAP),这种方法在先验假设比较靠谱的情况下效果显著,随着数据量的增加,先验假设对于模型参数的主导作用会逐渐削弱,相反真实的数据样例会大大占据有利地位。极端情况下,比如把先验假设去掉,或者假设先验满足均匀分布的话,那她和极大似然估计就如出一辙了。
可见,贝叶斯估计和最大后验估计其实是基于贝叶斯学派的哲学思想发展的参数估计方法。
七、参考资料
- 《模式分类》Richard O. Duda ,Peter E.Hart ,David G.Stork
- 极大似然估计和贝叶斯估计
- 极大似然估计与最大后验概率估计