RubbleDB: CPU-Efficient Replication with NVMe-oF
RubbleDB: CPU-Efficient Replication with NVMe-oF
前言
- 这是ATC2023的文章,作者来自哥伦比亚大学
- 这篇工作在LSM-tree多副本存储的场景下,利用NVMe-oF技术避免了LSM-tree副本上的重复合并,减少了CPU开销。
Introduction
为了提供高可用性,基于磁盘的键值存储通常在会复制到多台计算机节点上。 然而,以LSM-tree为代表的键值存储在后台执行的合并操作上消耗了大量的计算资源,这些操作会对磁盘上的数据进行垃圾回收。 先前的研究表明,在生产工作负载中,合并操作可能占用高达45%的CPU资源,并且通过避免合并,键值存储的吞吐量可以提高高达2倍。作者重现了这些实验,并发现在RocksDB中,合并操作占用了高达总CPU周期的72%。
这一简单的观察结果是,在多副本的键值存储场景下,每个节点都收到相同的命令且每个存储副本进行的合并操作是完全相同的,那么这些副本上的合并操作就是冗余的。作者可以设计一种架构,其中主节点在本地进行合并操作,然后将已经合并的文件传送给副本节点,从而显著降低总体的CPU消耗。
然而,这种方法有两个重要的缺点。
- 它增加了网络带宽的压力,因为需要复制常规操作以及合并后的文件到副本上。幸运的是,在现代数据中心中,网络流量通常是低利用率的;例如,来自阿里巴巴和Snowflake的集群跟踪数据显示,50-75%的网络带宽始终保持空闲。因此,在通过增加网络流量来减少CPU消耗之间进行权衡,通常是可取的。
- 从主节点将文件传送到副本节点仍然需要一些处理:在极端情况下,如果两端都使用TCP,那么传送文件将导致两端处理TCP数据包的开销,以及在副本节点上遍历存储堆栈的成本。
为了解决第二个问题,作者可以采用NVMe-oF,这是一种网络存储协议,可以最小化副本节点上的CPU开销。NVMe-oF扩展了NVMe协议,允许一个服务器直接访问远程服务器的磁盘,而对远程服务器的CPU干预最小。更好的是,大多数通用数据中心网络适配器(NIC)支持将整个NVMe处理工作在远程服务器上完成,通过允许远程NIC直接与NVMe存储设备通信。因此,如果作者使用NVMe-oF,副本节点的主机CPU将完全不涉及处理传入的复制文件,从而完全消除由传输合并结果引起的所有CPU开销。
然而,使用NVMe-oF在存储节点之间复制文件会带来两个挑战。 1. 由于远程节点的本地文件系统(例如ext4)不参与文件的写入,它无法意识到更新后的文件及其位置,无法读取它,甚至可能意外地覆盖它。 2. 运行在远程节点上的副本必须与主节点进行同步。以便从在其本地存储设备上更新的新文件中查找和读取数据,并且不能从在合并过程中删除的陈旧文件中读取数据。
作者提出了RubbleDB,这是第一个利用NVMe-oF进行高效复制的分布式存储系统。RubbleDB设计的关键贡献在于提供了在远程节点进行文件系统同步和应用程序同步的机制,从而使其能够安全且正确地读取通过NVMe-oF写入的数据。
Background and Motivation
The High Cost of Compactions
CPU consumption of compactions 合并操作是昂贵的,并且会影响键值存储的性能。进行合并作业需要读取涉及到合并的所有文件的数据(通常涉及数十兆字节或更多的数据),对其进行排序,并将其写回磁盘。
举个例子,作者通过在三副本键值存储上运行YCSB测试(§5.2),测量了合并消耗的CPU时间。在这个工作负载中,72%的CPU时间用于合并作业,由于合并操作的高成本,在LSM-tree上有大量的工作来减少其资源消耗,例如通过延迟合并或者优化LSM树的数据结构和参数以减少其开销。
Saving compaction CPU and I/O bandwidth in replicated key-value stores. 作者观察到,在多个相同副本上,作者不需要在所有节点上运行多个相同的合并任务,这些任务本质上执行完全相同的计算。因此,合并只需要在主节点上发生一次,已经合并的SST文件可以被传送到备份副本节点。
这种方法有潜力显著降低副本节点上的CPU消耗,因为它们不再需要执行合并任务,这将消除副本节点合并产生的CPU开销和读IO开销,但它不会消除副本节点的写IO开销,因为新文件仍然需要写回磁盘。最后,这也将减少副本节点因合并而产生的内存开销。
然而,仅在主节点上执行合并也是有代价的。这种方法的主要成本是增加了网络带宽和NIC资源消耗,因为现在不仅需要复制“常规”的传入读写请求,还需要复制合并后的SST文件。幸运的是,在许多数据中心中,网络通常是低利用率的。此外,主节点在将文件传送到副本节点的磁盘时会消耗一些额外的CPU资源。
因此,由于这种方法主要涉及在减少副本节点上的CPU消耗和增加总网络带宽之间的权衡,作者希望使用一种协议来传送SST文件,以最小化副本节点上的CPU使用。为此,作者采用NVMe-oF,这是一种由Linux和现代NIC支持的最先进的网络存储协议,可以在不涉及副本节点CPU的情况下运行。
Motivation for Using NVMe-oF

NVMe-oF是NVMe协议的网络存储扩展。NVMe-oF允许应用程序直接访问连接到远程服务器的存储设备,使用NVMe协议,NVMe-oF有两种实现方式一种是基于TPC的另一种是基于RDMA的。图1描述了NVMe-oF请求的流程。主机(图表左侧)是发起请求的服务器,而目标是远程服务器和连接到它的SSD。NVMe-oF请求由主机上的应用程序发起,该应用程序发出系统调用,并随后穿过整个操作系统存储堆栈,将其视为常规本地NVMe请求,直到到达NVMe驱动程序。
写请求过程(图1): 1. 用户空间应用程序在连接到NVMe-oF的挂载磁盘上发出WRITE()系统调用(步骤1), 2. 像正常的本地I/O一样,通过Linux虚拟文件系统(VFS)查找inode(文件元信息),该inode将磁盘上的物理扇区映射,并提交给块层(步骤2) 3. 在块层中由I/O调度程序批处理,并分派给主机端NVMe驱动程序(步骤3)。 4. 主机和目标驱动程序维护多个I/O队列,用于交换NVMe-oF数据包(capsule,它是一个主机和目标节点之间进行NVMe通信的数据结构,包含NVMe-oF读写命令和数据)。然后,根据传输协议类型(TCP、RDMA等),将数据包转发到相应的网络堆栈(步骤4),然后转发到目标节点。对于NVMe/TCP,数据包被嵌入在TCP数据包中,并包含数据和元数据。而对于NVMe/RDMA,目标节点和主机使用双边RDMA操作交换数据包。使用NVMe/RDMA时,数据包记录了主机中数据缓冲区的内存地址,目标节点随后使用单边RDMA读取该部分内存。 5. 在目标节点(步骤5)上,驱动程序从网络数据包中提取NVMe-oF读写命令和用户数据,生成块层请求 6. 将块请求提交给块层进行I/O调度(步骤6a) 7. 目标节点的NVMe驱动程序接收块层的I/O请求(步骤7) 8. 通过PCIe总线将用户的数据写入本地NVMe SSD(步骤8)。
在过去的几年中,主要的NIC型号(例如NVIDIA ConnectX、Broadcom Stingray、Intel IPU)已经支持将NVMe-oF目标数据通路完全卸载到NIC,并允许NIC直接将数据写入NVMe设备。这提供了一个可绕过目标CPU的备选数据通路(步骤6b)。当连接到目标的NIC收到来自主机的NVMe数据包时,它会执行NVMe请求,并通过DMA直接将数据写入NVMe SSD。
使用NVMe-oF带来的优点

流行的分布式存储系统(例如CockroachDB和Ceph)通常使用RPC(例如gRPC)将数据从主节点发送到副本节点,然后副本节点将数据本地写入SSD(例如使用WRITE()系统调用)。
作者在一个测试中比较了传统基于RPC的远程写入(gRPC+WRITE())与两种NVMe-oF协议(NVMe/RDMA,即基于RDMA的NVMe-oF,以及NVMe/TCP,即基于TCP的NVMe-oF)的吞吐量和CPU使用率。在实验中,每台服务器包含一个主节点,该主节点将数据写入第二台服务器上的一个副本节点,每个测试点远程写入1MB的数据块。结果如表1所示。
结果显示,使用WRITE()的gRPC的吞吐量仅为NVMe/TCP的34%,而CPU使用率高出20%。 这是因为(1)RPC框架本身存在一定的开销,会影响一部分性能。(2)传统的远程写入需要先写入远程节点的用户层buffer上,然后通过系统调用写入文件系统,产生了额外的用户态->内核态的切换开销。 而NVMe/TCP在内核的NVMe驱动程序中处理数据写入,因此在每个写入请求中节省了大量CPU周期,从而增加了吞吐量。此外,由于消除了不必要的复制和绕过了CPU,NVMe/RDMA的性能优于NVMe/TCP。
Challenges
使用NVMe-oF替换传统的远程复制协议带来了两个不同的层面上的挑战:文件系统层面和应用程序层面的挑战。
File system inconsistency. 文件系统的不一致性。NVMe-oF在文件系统层面引入了不一致性。通过NVMe-oF简单地在远程磁盘上分配一个新文件并写入数据是一种基本的文件传送方式。然而,在这种方案中,副本节点甚至无法在其文件系统中看到新的SST文件。这是因为SST文件是在主节点的文件系统中创建的,而NVMe-oF只转发NVMe命令,这些命令在副本节点的存储堆栈中的文件系统层以下执行(见图1)。更糟糕的是,主机发送的数据可能会意外地覆盖副本节点上不应该访问的物理块中的数据,因为副本节点的本地文件系统可能已经改变了其文件到块的映射。
Application inconsistency.

即使副本节点的文件视图与主机的视图同步,NVMe-oF在应用程序层面引入了不一致性。由于持久的键值存储维护着内存中的数据结构(例如用于缓冲写入),这些数据结构可能在主节点和副本节点之间不同步,导致数据丢失。特别地,在RocksDB中,主节点和副本节点的MemTable之间将出现差异。
图2举了了一个例子,在该示例中,主节点和副本节点的MemTable不一致导致了副本节点的数据丢失。假设有一个活动的MemTable(MemTable 1),它几乎已满,只能容纳一个更多的对象(图2a)。现在考虑两个对象(A和B)同时到达。主节点和副本节点都使用两个线程来处理传入的请求,在这种情况下,RocksDB不保证写入将被处理的顺序。在主节点中,对象A先于B被写入,因此被写入到MemTable 1,然后将其封存并标记为非活动状态,而对象B被写入新的活动MemTable 2。接下来,主节点将对象A和B转发到副本节点,但由于非确定性线程调度,副本节点会按相反的顺序应用它们:B被写入到MemTable 1,而A被写入到MemTable 2。因此,副本节点的MemTable 1存储的数据与主节点的MemTable 1不同(图2b)。
现在,主节点将MemTable 1刷新到磁盘,导致将存储在MemTable 1中的对象从内存中删除。如果它然后将新的SST文件传送到副本节点,并指示副本节点也删除MemTable 1,这将导致副本节点上的B丢失,因为B既不会存储在其MemTable中,也不会存储在其磁盘上(图2c)。在这种情况下,数据丢失的原因是由于非确定性方式跨节点进行线程调度,因此操作的应用顺序不同,导致差异。
从本质上来讲,这个问题出现的原因是无法保证主节点和副节点的Memtable完全一致。
Design and Implementation
为了克服这些问题,作者设计了RubbleDB,接下来介绍RubbleDB的设计和实现,并解释RubbleDB是如何通过关键机制解决NVMe-oF复制引入的不一致性问题。
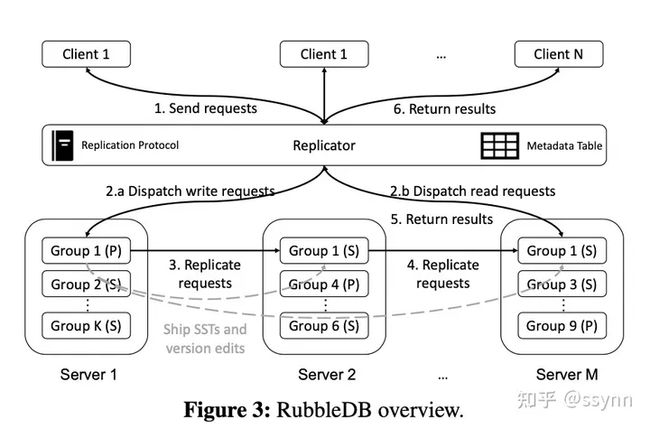
作者介绍了RubbleDB的设计和实现,并解释了关键机制,使RubbleDB能够解决通过NVMe-oF复制引入的不一致性问题。 RubbleDB是一个复制的键值存储系统,由一组RocksDB实例组成,并在其上方有一个复制层。RubbleDB使用链式复制来提供强一致性和快速恢复。客户端只与复制层进行通信,复制层负责将请求分派到适当的主节点(写操作)或尾节点(读操作),以及处理故障恢复。图3描述了RubbleDB的整体架构。系统中有N个客户端和K个复制组,复制层位于它们之间。复制组包含R个RocksDB实例或节点,其中一个是主节点,其他的是副本节点。只有主节点执行刷新或合并操作。因此,除了复制客户端的写请求外,主节点还通过NVMe-oF传送合并后的SST文件,前提是有足够的网络带宽可用。
如果网络拥塞,RubbleDB可以回退到所有副本上的本地合并。具体来说,RubbleDB比较了传送SST文件和本地合并的延迟。如果前者在一段时间内始终较大,RubbleDB将回退到常规合并。不同的复制组存储不重叠的键空间。默认情况下,R个副本存储在R个不同的随机服务器上。接下来,作者将讨论RubbleDB的两个主要关键组件的设计细节:复制层和复制组。
Replicator Layer
为了为用户提供干净的键值接口并隐藏处理复制协议的复杂性,RubbleDB使用一个复制层作为用户和复制组之间的代理层。用户只需向复制层发送常规的RocksDB请求,并从复制层接收结果,复制层会透明地处理复制协议。因此,复制层有两个角色:1)将请求路由到包含所请求的键值对的复制组的副本;2)检测和恢复任何失败的副本。
不同的复制组包含不同的键空间。为了路由请求,复制层维护一个元数据表,记录每个复制组的键空间和网络地址。一旦收到请求,复制层首先在元数据表中查找相应的组号。然后,根据复制协议,它将请求转发到该组内的特定副本。复制层还会定期向每个副本发送心跳消息,以确认其健康状态。如果在一定时间阈值内没有从副本收到任何回复,认为该副本已失败,复制层将启动恢复过程。
在图3中,前台数据流由实线箭头表示,后台数据流由虚线表示。图中仅显示属于复制组1的后台请求,该复制组复制在服务器1、2和M上。
- 客户端首先将请求发送给复制层(步骤1),复制层在查阅元数据表后将请求转发给复制组1(步骤2)。
- 按照链式复制协议,写请求(如put和update)发送到头部(步骤2.a),而读请求(如get和scan)发送到尾部(步骤2.b)。
- 在写请求的情况下,主节点(头部)将写请求复制到链中的下一个副本节点(步骤3),
- 副本节点执行写入操作,然后将其复制到链中的下一个节点(步骤4)。
- 当尾节点完成一个请求(读或写)时,它会回复给复制层(步骤5),最后复制层将结果返回给客户端(步骤6)。
值得注意的是,复制层只是一个逻辑上的集中式组件,用于协调流量和恢复。为了防止复制层成为性能瓶颈或单点故障,可以将其实现为一个分布式容错集群。作者将这个方向,以及复制层设计的其他方面(例如动态负载平衡和动态键空间分区),留待未来的工作。
Replication Groups

在复制组内的每个节点都是一个小型的RocksDB实例,由一个主节点(链的头部)和一系列副本节点组成,这些副本节点存储数据的备份副本。图4展示了主节点与其副本节点之间的交互过程。实线箭头和虚线箭头分别表示前台和后台操作。写请求从头部副本(主节点)执行到尾部副本(步骤1-3)。图4中省略了读请求,因为它们只发送到尾部副本节点。
步骤I至III展示了RubbleDB如何在副本节点中避免后台合并作业。
- 在步骤I中,主节点正常进行Flush和合并作业。这些作业以三种方式改变主节点的LSM树:1)删除正在合并的数据(包括内存中的不可变MemTables和磁盘上的SST文件,在图4中用虚线矩形表示),2)创建合并后的SST文件(虚线圆角矩形),以及3)修改LSM树版本(记录树中当前SST文件的信息)。
- RubbleDB通过在网络上发送合并后的SST文件和版本编辑来确保副本节点也进行相同的更改(步骤II)。
- 发送合并后的SST文件解决了2),因此副本节点只需要根据版本编辑删除原始的过时SST文件,并更新自己的LSM树版本(步骤III)。
然而,由于在第3节中描述的挑战,确保步骤II和III的正确性并不是简单的。在下面两节中,作者讨论了RubbleDB如何解决文件系统的不一致性问题和如何解决LSM-tree应用程序的不一致性问题。
File Pre-allocation
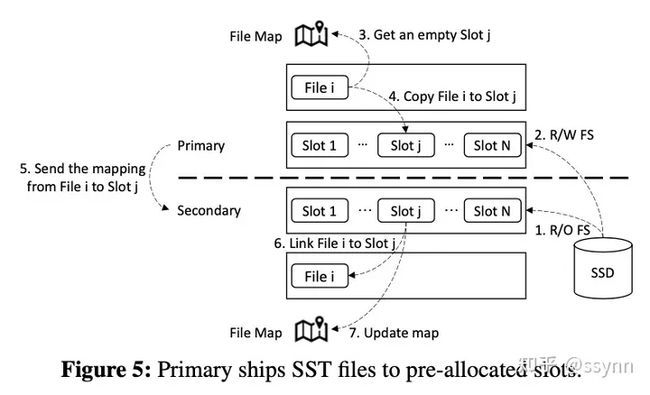
为了确保副本节点能够看到主节点发送的SST文件,RubbleDB使用文件预分配的方式。在运行之前,副本节点在其本地存储设备上分配许多预分配的文件槽(Slot),作者称之为文件池,主节点和副本节点的文件池一一对应。在运行时,主节点通过使用直接I/O(以确保文件被写入磁盘并绕过主节点的本地缓存)将SST文件的内容写入池中的固定大小的槽,将SST文件发送到副本节点。因此,只更新槽文件的数据块,而inode保持不变。在文件写入后,副本节点也可以通过直接I/O读取其内容。这样便解决了副本节点看不到主节点发过来的文件的问题。
值得注意的是,这意味着副本节点和主节点不能依赖操作系统的文件缓存从磁盘读取的热数据块,因为副本节点的文件系统不知道文件池里的文件什么时候被修改。幸运的是,RocksDB(以及大多数其他键值存储)实现了自己的用户空间缓存,即块缓存,可以取代操作系统的缓冲区高速缓存。
这种预分配方案存在四个实际问题:
这种预分配方案存在四个实际问题:
- 如何确定Slot的大小
- 解决方案:RocksDB中文件大小是可以设置为固定的,所以只需要将Slot设置为固定大小即可
- 在池中管理槽文件
- 解决方案:作者设计了一个文件映射来跟踪槽与SST文件之间的映射关系,并指示槽是否包含活动SST文件。
- 避免副本文件系统的进行文件重新映射(remapping)
- 解决方案:RubbleDB在每个副本节点中使用了一个专用且静态的磁盘分区作为文件池。在副本节点中,该分区被以只读方式挂载,因为副本节点不会对其SSD进行写入。
- Slot文件池的文件是固定的,如何确保RocksDB在更改文件名时仍能正确指向预分配的文件。
- 解决方案:RubbleDB维护了一个文件名映射表,将具有RocksDB定义名称的文件链接到槽文件,这样副本节点上的RocksDB实例就可以正确地访问其只读文件池。
这一节通过上述手段维护了副本文件系统的一致性
LSM Tree Synchronization
接下来介绍作者如何避免LSM-tree的不一致性问题
Flush和compaction作业本质上执行合并排序,并且从客户端的角度来看,不改变RocksDB的实际状态。这些合并包含输入:在刷和合并作业中要合并的MemTable和SST文件,而输出始终是要写入磁盘的SST文件。这意味着刷写作业和合并作业的输入和输出必须包含相同的存活键值对集合。主节点自然满足这个要求,因为它们在本地执行合并。然而,当应用版本编辑时,副本节点有时会有不匹配的输入和输出存活键值对集合。回顾图2中的示例,在副本节点中,刷写作业的输入(MemTable 1)与输出(SST 1)包含不同的存活对象。因此,副本节点丢失了B,同时冗余地存储了两个副本的A。
为了保证副本节点的数据一致性,它们需要确保每个版本编辑的输入和输出在应用之前包含相同的存活对象集合。然而,跨多个MemTable或SST文件比较所有对象是非常昂贵的。因此,RubbleDB采用了部分顺序和版本编辑的全局顺序。这两种排序技术同步副本节点的LSM树与主节点的LSM树。作者在下面对它们进行描述。

避免图2的写Memtable不一致问题: 图6描述了RubbleDB如何通过使用MemTable ID对写入请求进行排序来解决图2中示例中讨论的MemTable不一致问题。
- 在主节点中,当对象被插入到活动的MemTable中时,每个写入请求都会返回带有该MemTable ID的标识(步骤1)。
- 主节点使用这个MemTable ID标记每个写入请求并将其转发给副本节点(步骤2,下标是ID)。
- 有了这些ID,副本节点现在知道主节点写入每个请求的MemTable是哪个。副本节点按照主节点的顺序执行相同的操作,通过维护一个请求缓冲区来缓存无序的请求。例如,即使副本节点先执行了线程2,然后执行了线程1,它将无法将B2写入到MemTable 1,因为其标识(2)与MemTable ID(1)不匹配(步骤3)。
- 线程2将请求B2存储在请求缓冲区中(步骤4)。当线程1执行时,A1将被写入到MemTable 1中。因此,主节点和副本节点上的MemTable 1将具有相同的对象集,这将不会像图2c中那样导致数据丢失。
- 每当RocksDB切换到一个新的MemTable时,副本节点中的每个线程都会检查缓冲区,以执行可以正确应用于MemTable的任何请求,即其标识等于活动MemTable的ID(步骤5)。
Evaluation
Experimental Setup
作者使用RocksDB 6.14.0和gRPC 1.34.0来实现RubbleDB,总共约有900行Java代码和4000行C++代码。RubbleDB中的每个副本都是一个RocksDB实例,系统的不同部分使用流式gRPC调用相互通信。为了模拟并发客户端,作者修改了YCSB,将请求作为批次发送到作者的复制器中,并在一个开放的循环中运行。作者将所有的代码开源在GitHub上。
baseline是一个多副本RocksDB,即没有实现本文基于NVMe-oF复制的RubbleDB。
Performance Breakdown

这一节测试RubbleDB对CPU和IO的节约情况负载为YCSB。
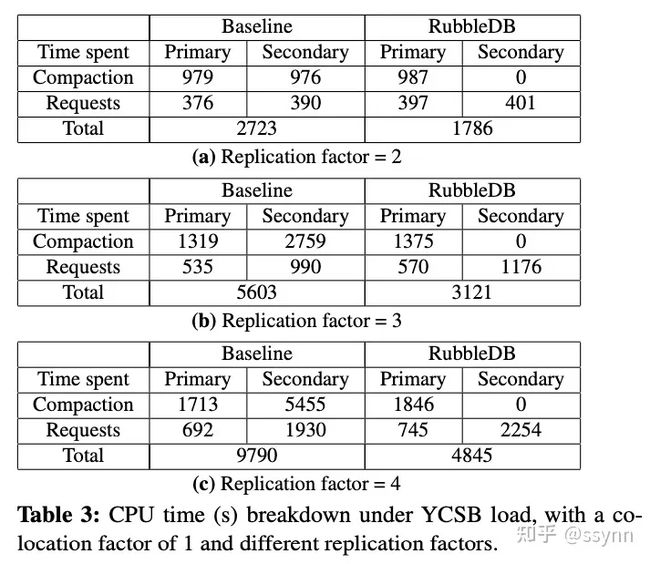
节约的CPU 表格3显示了baseline和RubbleDB在执行合并和处理传入请求时所消耗的CPU时间。
Replication factor表示服务器的数量,也等于副本的数量
如预期的那样,RubbleDB中的辅助节点在执行合并时不消耗CPU周期,而在baseline中,每个辅助节点消耗的CPU周期大约与主节点相同(每个主节点有R-1个辅助节点)。在R = 2、3和4的情况下,RubbleDB的主节点比baseline的主节点消耗更多合并CPU,分别增加了0.8%、4.2%和7.8%。这是因为主节点必须将合并的SST文件和版本编辑发送到每个辅助节点。开销随辅助节点数量增加而增加。
在处理常规请求方面,RubbleDB的主节点消耗的CPU略多于baseline的主节点(最多增加7.7%),因为它为每个写入请求打上一个MemTable ID。RubbleDB的辅助节点消耗的CPU比baseline的辅助节点多多达18.8%,因为需要缓冲传入的请求和版本编辑。总体而言,由于辅助节点合并负载的减少,RubbleDB处理相同工作负载的时间比baseline少34.4%、44.3%和50.5%,对应于R=2、3和4。
I/O节约 表4展示了一个节点读写的数据量。由于作者运行YCSB负载工作负载并禁用了WAL,因此表中的I/O全部是由合并引起的。在RubbleDB中,只有主节点执行合并,它读取输入文件并将合并的SST文件发送到每个辅助节点。因此,RubbleDB的读取I/O保持几乎恒定,平均为98.0 GB,而其写入I/O随着复制因子成比例增长,平均为R×103.1 GB。然而,在baseline中,读写I/O随着复制因子增加而增加,因为所有节点都执行合并。因此,RubbleDB在更高的复制因子下节约更多的读取I/O,当R=4时,节约率高达44.2%。由于RubbleDB中SST文件的填充,写入I/O略有增加(最多增加12.9%),这会增加每个SST文件的写入数据量。作者将减少填充的开销留给未来的工作。
网络开销 表5显示了gRPC和NVMe-oF的流量。前者包括转发键值请求和版本编辑,而后者包括传输SST文件。RubbleDB中的网络开销包括:(a)通过gRPC发送版本编辑和(b)通过NVMe-oF传输SST文件。作者通过计算传输的SST文件的总体积来近似(b)。从表5中可以看出,(a)几乎可以忽略不计,而(b)接近于合并写入I/O的量。
End-to-end Performance

通过YCSB的吞吐量。上图比较了,RubbleDB和baseline的每个核心的吞吐量。与baseline相比,RubbleDB始终提供相同或更高的每个核心吞吐量,并且对于具有高写入百分比的工作负载,其相对加速比更高。
随着R的增加,RubbleDB提供更高的相对增益。例如,在共存因子为2的负载工作负载下,复制因子为4的加速比为1.9倍,而R = 2的加速比为1.5倍。原因是随着更高的复制因子,baseline在每个复制组中花费更多的辅助节点核心周期来执行压缩,而RubbleDB的主节点的CPU消耗只有非常小的增加(由于需要将SST文件传输给额外的辅助节点)。因此,随着复制因子的增加,RubbleDB能够调动更多释放的辅助节点核心的可用CPU周期,以处理更多传入请求。此外,RubbleDB在共存因子为2时实现了更高的绝对吞吐量和加速比。原因是在更多的共存复制组下,RubbleDB能够更好地利用CPU,因为在任何给定时间都有更多可用的待处理任务。
总结
- 总的看下来这篇文章并没提出什么很深刻的问题或者很有新意的解决方案,唯一的亮点就是用了NVMe-oF这一技术。
- 整篇文章读起来比较舒服,逻辑顺畅抓住重点,图也画的清晰易懂,作者的表达能力值得学习。