音频编解码基础
1. PCM
PCM 脉冲编码调制是Pulse Code Modulation的缩写。脉冲编码调制是数字通信的编码方式之一。主要过程是将话音、图像等模拟信号每隔一定时间进行取样,使其离散化,同时将抽样值按分层单位四舍五入取整量化,同时将抽样值按一组二进制码来表示抽样脉冲的幅值。
1.1 语音编码原理
有一定电子基础的都知道传感器采集音频信号是模拟量,而我们实际传输过程中使用的是数字量。而这就涉及到模拟转数字的过程。而模拟信号数字化必须经过三个过程,即抽样、量化和编码,以实现话音数字化的脉冲编码调制(PCM,Pulse Coding Modulation)技术。
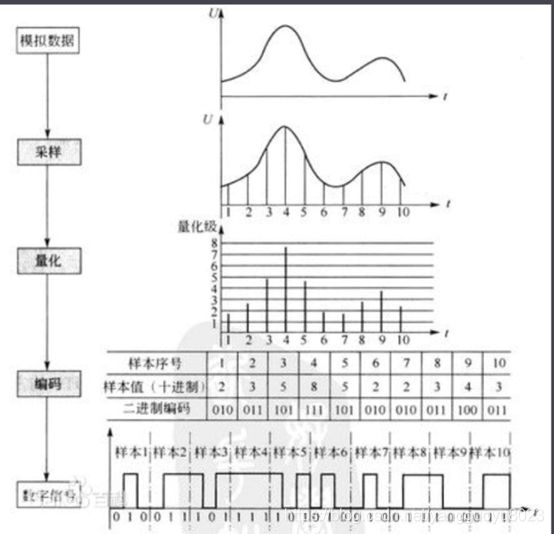
模拟信号转换为数字信号
1.1.1 抽样(Sampling)
抽样是把模拟信号以其信号带宽2倍以上的频率提取样值,变为在时间轴上离散的抽样信号的过程。
采样率 (sample):每秒从连续信号中提取并组成离散信号的采样个数,用赫兹(Hz)来表示。
1.1.2 量化(quantizing)
抽样信号虽然是时间轴上离散的信号,但仍然是模拟信号,其采样值在一定的取值范围内,可有无限多个值。显然,对无限个采样值一一给出数字码组来对应是不可能的。为了实现以数字码表示样值,必须采用“四舍五入”的方法把采样值分级“取整”,使一定取值范围内的采样值由无限多个值变为有限个值。这一过程称为量化。
量化后的抽样信号与量化前的抽样信号相比较,当然有所失真,且不再是模拟信号。这种量化失真在接收端还原模拟信号时表现为噪声,并称为量化噪声。量化噪声的大小取决于把采样值分级“取整”的方式,分的级数越多,即量化级差或间隔越小,量化噪声也越小。
采样位数:指的是描述数字信号所使用的位数。
8位(8bit)代表2的8次方=256,16 位(16bit)则代表2的16次方=65536; 采样位数越高,精度越高。
1.1.3 编码(Coding)
量化后的抽样信号就转化为按抽样时序排列的一串十进制数字码流,即十进制数字信号。简单高效的数据系统是二进制码系统,因此,应将十进制数字代码变换成二进制编码,根据十进制数字代码的总个数,可以确定所需二进制编码的位数,即字长(采样位数)这种把量化的抽样信号变换成给定字长的二进制码流的 过程称为编码。
1.2 PCM 音频编码
PCM信号未经过任何编码和压缩处理(无损压缩)。与模拟信号比,它不易受传送系统的杂波及失真的影响。动态范围宽,可得到音质相当好的效果。编码上采用A律13折线编码。
声道:声道可以分为单声道和立体声(双声道)
PCM的每个样本值包含在一个整数i中,i的长度为容纳指定样本长度所需的最小字节数。
首先存储低有效字节,表示样本幅度的位放在i的高有效位上,剩下的位置为0,这样8位和16位的PCM波形样本的数据格式如下所示。

1.2.1 采样频率
人对频率的识别范围是 20HZ - 20000HZ, 如果每秒钟能对声音做20000个采样, 回放时就足可以满足人耳的需求。
① 8000hz 为电话采样。
② 22050 的采样频率是常用的。
③ 44100已是CD音质, 超过48000的采样对人耳已经没有意义。
1.2.2 音频帧
对采样率为44.1kHz的AAC(Advanced Audio Coding)音频进行解码时,一帧的解码时间须控制在23.22毫秒内。通常是按1024个采样点一帧。
为什么这里需要说下音频帧呢?
音频的帧的概念没有视频帧那么清晰,几乎所有视频编码格式都可以简单的认为一帧就是编码后的一副图像。但音频帧跟编码格式相关,它是各个编码标准自己实现的。因为如果以PCM(未经编码的音频数据)来说,它根本就不需要帧的概念,根据采样率和采样精度就可以播放了。比如采样率为44.1kHZ,采样精度为16位的音频,你可以算出bitrate(比特率)是44100*16kbps,每秒的音频数据是固定的44100*16/8 字节。
但是我们不希望每一次采样都返回给我们进行处理,我们希望的是返回一段时间内的所有采样数据。这里的音频帧就是每次返回给我们多少个采样数据,一般情况是下返回2048个采样数据。
那么单声道 采用16位采样位数 2048个采样数据的大小是多少呢 2048*16/8 = 4096字节。
1.2.3 比特率
码率是指经过编码后的音频数据每秒钟需要用多少个比特来表示.
1.2.4 有损和无损
对于我们最常说的“无损音频”来说,一般都是指传统CD格式中的16bit/44.1kHz采样率的文件格式,而之所以称为无损压缩,也是因为其包含了20Hz-22.05kHz这个完全覆盖人耳可闻范围的频响频率而得名。
这里我有个混淆的地方是 声道和采样频率之间的关系?刚开始假设采样频率是44100,要是使用双声道的话,那么每个声道的采样率就是22100了。其实这是错误的,采样频率是在每个声道上的采样速率,不是在所有频道的采样速率。
因此,要是采样速率是44100 ,那么双声道,采集的样本个数应该是88200个。
2. LPCM
LPCM: linear pulse code modulation
LPCM,即线性脉冲编码调制,是一种非压缩音频数字化技术,是一种未压缩的原音重现,在普通CD、DVD及其他各种要求最高音频质量的场合中已经得到广泛的应用。
各种应用场合中的LPCM(PCM)原理是一样的,区别在于采样频率和量化精度不同。
声音之所以能够数字化,是因为人耳所能听到的声音频率不是无限宽的,主要在20kHz以下。按照抽样定理,只有抽样频率大于40kHz,才能无失真地重建原始声音。如CD采用44.1kHz的抽样频率,其他则主要采用48kHz或96kHz。
PCM(脉冲编码调制)是一种将模拟语音信号变换为数字信号的编码方式。主要经过3个过程:抽样、量化和编码。抽样过程将连续时间模拟信号变为离散时间、连续幅度的抽样信号,量化过程将抽样信号变为离散时间、离散幅度的数字信号,编码过程将量化后的信号编码成为一个二进制码组输出。
量化分为线性量化和非线性量化。线性量化在整个量化范围内,量化间隔均相等。非线性量化采用不等的量化间隔。量化间隔数由编码的二进制位数决定。例如,CD采用16bit线性量化,则量化间隔数L=65536。位数(n)越多,精度越高,信噪比SNR=6.02n+1.76(dB)也越高。但编码的二进制位数不是无限制的,需要根据所需的数据率确定。比如:CD可以达到的数据率为2×44.1×16=1411.2Kbit/s。
简单的理解,LPCM就是把原始模拟声音波形经过采样和线性量化后得到的数字信号,这些数据信号还没被压缩。
3. ADPCM
ADPCM :Adaptive Differential Pulse Code Modulation
说到ADPCM, 就得先说下DPCM。
Differential(差异)或Delta PCM(DPCM)纪录的是目前的值与前一个值的差异值。DPCM对信号的差值进行量化,可以进一步减少量化比特数。与相等的PCM比较,这种编码只需要25%的比特数。这与一些视频的压缩理念类似,用该帧与前一帧的差异来进行记录该帧以达到压缩的目的。
ADPCM (Adaptive Differential Pulse Code Modulation), 是一种针对16bit (或者更高) 声音波形数据的一种有损压缩算法, 它将声音流中每次采样的 16bit 数据以 4bit 存储, 所以压缩比1:4. 而压缩/解压缩算法非常的简单, 所以是一种低空间消耗,高质量声音获得的好途径。
该算法利用了语音信号样点间的相关性,并针对语音信号的非平稳特点,使用了自适应预测和自适应量化,即量化器和预测器的参数能随输入信号的统计特性自适应于或接近于最佳的参数状态,在32kbps◎8khz速率上能够给出网络等级话音质量。
特性:ADPCM综合了APCM的自适应特性和DPCM系统的差分特性,是一种性能比较好的波形编码。它的核心想法是:
①利用自适应的思想改变量化阶的大小,即使用小的量化阶(step-size)去编码小的差值,使用大的量化阶去编码大的差值;
②使用过去的样本值估算下一个输入样本的预测值,使实际样本值和预测值之间的差值总是最小。
优点:算法复杂度低,压缩比小,编解码延时最短(相对其它技术)
缺点:声音质量一般
简单理解,ADPCM就是对LPCM数据进行有损压缩,压缩过程中量化参数遇小则小,遇大则大,根据差值来自己调整大小;另外它可以对之前的数据统计后来预测后来的数据差值,尽量使差值比较小。
4. AAC
AAC,全称Advanced Audio Coding,中文名:高级音频编码,是一种专为声音数据设计的文件压缩格式。与MP3不同,它采用了全新的算法进行编码,更加高效,具有更高的“性价比”。利用AAC格式,可使人感觉声音质量没有明显降低的前提下,更加小巧。苹果ipod、诺基亚手机支持AAC格式的音频文件。
优点:相对于mp3,AAC格式的音质更佳,文件更小。
不足:AAC属于有损压缩的格式,与时下流行的APE、FLAC等无损格式相比音质存在“本质上”的差距。加之,传输速度更快的USB3.0和16G以上大容量MP3正在加速普及,也使得AAC头上“小巧”的光环不复存在。
AAC是新一代的音频有损压缩技术,它通过一些附加的编码技术(比如PS,SBR等),衍生出了LC-AAC,HE-AAC,HE-AACv2三种主要的编码,LC-AAC就是比较传统的AAC,相对而言,主要用于中高码率(>=80Kbps),HE-AAC(相当于AAC+SBR)主要用于中低码(<=80Kbps),而新近推出的HE-AACv2(相当于AAC+SBR+PS)主要用于低码率(<=48Kbps),事实上大部分编码器设成<=48Kbps自动启用PS技术,而>48Kbps就不加PS,就相当于普通的HE-AAC。
频带复制技术(Spectral Band Replication,SBR)AAC的核心之一是SBR,这是一种使用极少位数就可描述高频部分并在解码时进行特殊优化从而实现频域扩展的模块。
参数立体声(Parametric Stereo,PS) , PS模块也是AAC的核心模块之一,主要用于分析左右声道属性并使用非常少的位数表示左右声道相关性,而后在解码端将左右声道分离。这里比较巧妙的是PS的向下兼容特性,整体数据打包是分开进行的。如果获取到AAC、SBR、PS三者的基本数据包后,在解码阶段我们就只需AAC—LC。
AAC的音频文件格式有以下两种:
ADIF:Audio Data Interchange Format 音频数据交换格式。这种格式的特征是可以确定的找到这个音频数据的开始,不需进行在音频数据流中间开始的解码,即它的解码必须在明确定义的开始处进行。故这种格式常用在磁盘文件中。
ADTS:Audio Data Transport Stream 音频数据传输流。这种格式的特征是它是一个有同步字的比特流,解码可以在这个流中任何位置开始。它的特征类似于mp3数据流格式。
简单说,ADTS可以在任意帧解码,也就是说它每一帧都有头信息。ADIF只有一个统一的头,所以必须得到所有的数据后解码。且这两种的header的格式也是不同的,目前一般编码后的和抽取出的都是ADTS格式的音频流。如果是ADTS格式的AAC文件,AAC音频文件有一帧一帧的ADTS帧组成,每个ADTS帧包含ADTS头部和AAC数据,如下所示。

ADTS头部的大小通常为7个字节,包含着这一帧数据的信息,内容如下

 图1 AAC的ADTS头部
图1 AAC的ADTS头部
各字段的意思如下:
@ syncword:
总是0xFFF, 代表一个ADTS帧的开始, 用于同步。
@ ID:MPEG Version: 0 for MPEG-4,1 for MPEG-2。
@ Layer:always: ‘00’。
@ protection_absent:Warning, set to 1 if there is no CRC and 0 if there is CRC。
@ profile:表示使用哪个级别的AAC,如01 Low Complexity(LC) – AAC LC。
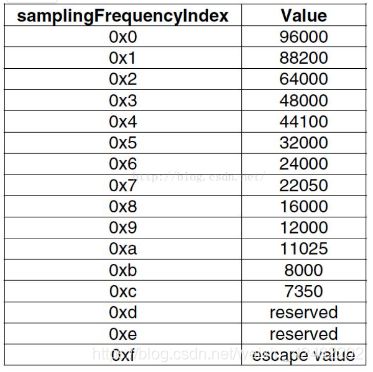
@ sampling_frequency_index:采样率的下标
@ aac_frame_length:一个ADTS帧的长度包括ADTS头和AAC原始流。
@ adts_buffer_fullness:0x7FF,说明是码率可变的码流。
@ number_of_raw_data_blocks_in_frame:表示ADTS帧中有number_of_raw_data_blocks_in_frame + 1个AAC原始帧
这里主要记住ADTS头部通常为7个字节,并且头部包含aac_frame_length,表示ADTS帧的大小
5. G711
G711是国际电信联盟ITU-T定制出来的一套语音压缩标准,它代表了对数PCM(logarithmic pulse-code modulation)抽样标准,主要用于电话。它主要用脉冲编码调制对音频采样,采样率为8k每秒。它利用一个 64Kbps 未压缩通道传输语音讯号。起压缩率为1:2,即把16位数据压缩成8位。G.711是主流的波形声音编解码器。
G.711 标准下主要有两种压缩算法。一种是u-law algorithm (又称often u-law, ulaw, mu-law),主要运用于北美和日本;另一种是A-law algorithm,主要运用于欧洲和世界其他地区。其中,后者是特别设计用来方便计算机处理的
G711的内容是将14bit(uLaw)或者13bit(aLaw)采样的PCM数据编码成8bit的数据流,播放的时候在将此8bit的数据还原成14bit或者13bit进行播放,不同于MPEG这种对于整体或者一段数据进行考虑再进行编解码的做法,G711是波形编解码算法,就是一个sample对应一个编码,所以压缩比固定为:
8/14 = 57% (uLaw)
8/13 = 62% (aLaw)
简单理解,G.711就是语音模拟信号的一种非线性量化, bitrate 是64kbps。
6. G726
G.726是ITU-T定义的音频编码算法。1990年 CCITT(ITU前身)在G.721和G.723标准的基础上提出。G.726可将64kbps的PCM信号转换为40kbps、32kbps、24kbps、16kbps的ADPCM信号。
最为常用的方式是 32 kbit/s,但由于其只是 G.711速率的一半,所以就将网络的可利用空间增加了一倍。G.726具 体规定了一个 64 kbpsA-law 或 μ-law PCM 信号是如何被转化为40, 32, 24或16 kbps 的 ADPCM 通道的。在这些通道中,24和16 kbps 的通道被用于数字电路倍增设备(DCME)中的语音传输,而40 kbps 通道则被用于 DCME 中的数据解调信号(尤其是4800 kbps 或更高的调制解调器)。
实际上,G.726 encoder 输入一般都是G.711 encoder的输出:64kbit/s 的A-law或µ-law;G.726算法本质就是一个ADPCM, 自适应量化算法,把64kbit/s 压缩到32kbit/s 。
7. AEC
回声消除原理:从通讯回音产生的原因看,可以分为声学回音(Acoustic Echo)和线路回音(Line Echo),相应的回声消除技术就叫声学回声消除(Acoustic Echo Cancellation,AEC)和线路回声消除(Line Echo Cancellation, LEC)。声学回音是由于在免提或者会议应用中,扬声器的声音多次反馈到麦克风引起的(比较好理解);线路回音是由于物理电子线路的二四线匹配耦合引起的(比较难理解)。解决方法:自适应滤波器和自适应算法。
回音的产生主要有两种原因:
(1)由于空间声学反射产生的声学回音(见下图)

图中的男子说话,语音信号(speech1)传到女士所在的房间,由于空间的反射,形成回音speech1(Echo)重新从麦克风输入,同时叠加了女士的语音信号(speech2)。此时男子将会听到女士的声音叠加了自己的声音,影响了正常的通话质量。此时在女士所在房间应用回音抵消模块,可以抵消掉男子的回音,让男子只听到女士的声音。
(2)由于2-4线转换引入的线路回音(见下图):
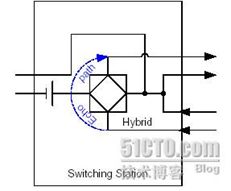
在ADSL Modem和交换机上都存在2-4线转换的电路,由于电路存在不匹配的问题,会有一部分的信号被反馈回来,形成了回音。如果在交换机侧不加回音抵消功能,打电话的人就会自己听到自己的声音。
尽管回声消除是非常复杂的技术,但我们可以简单的描述这种处理方法:
1、房间A的音频会议系统接收到房间B中的声音
2、声音被采样,这一采样被称为回声消除参考
3、随后声音被送到房间A的音箱和声学回声消除器中
4、房间B的声音和房间A的声音一起被房间A的话筒拾取
5、声音被送到声学回声消除器中,与原始的采样进行比较,移除房间B的声音
8. AGC
当有对语音的响度进行调整的需要时,就要做语音自动增益(AGC)算法处理,当你在跟远方的朋友进行语音交流时,背后都有这个算法在默默的工作,如大名鼎鼎的QQ聊天软件、做语音起家的YY等,语音聊天时都会用到这个算法。
最简单的硬性增益处理是对所有音频采样乘上一个增益因子,它也等同于在频域每个频率都同时乘上这个增益因子,但由于人的听觉对所有频率的感知不是线性的,是遵循等响度曲线的,导致这样处理后,听起来感觉有的频率加强了,有的频率削弱了,导致语言失真的放大。
要让整个频段的频率听起来响度增益都是“相同”的,就必须在响度这个尺度下做增益,而不是在频率域,即按照等响度曲线对语音的频率进行加权,不能采用一个固定的增益因子进行加权。
由些可见,语音的自动增益处理可以大致分为两个部分:
(1)响度增益因子的确定。
(2)把响度增益因子映射到等响度曲线上,确定最终各频率的增益权重。
最后要做的就是把各频率乘上最终的增益权重,我们就可以得到最终增益后的语音了!
这里再说下如何获取等响度曲线的值,总体思路是可以利用数值分析中的逼近理论做插值和拟合。
9. 参考文献
https://www.jianshu.com/p/cfb3d4dc3676
https://blog.csdn.net/u014470361/article/details/88837776
https://www.cnblogs.com/Ph-one/p/8795320.html
https://blog.csdn.net/qinglongzhan/article/details/80972174
https://www.jianshu.com/p/839b11e0638b?utm_campaign=maleskine&utm_content=note&utm_medium=seo_notes&utm_source=recommendation
https://www.jianshu.com/p/0eb1d055ecf8
https://www.jianshu.com/p/6b4c481f4294