一个复杂的nf_conntrack实例全景解析
本文关注两点,一点是细节,另外一点是概览:
- 细节:一个完整的关于nf_conntrack和NAT互动的例子
- 概览:关于人云亦云的讽刺
近期搜集了一些关于iptables,NAT相关的问题,其中最令人觉得麻烦的还是nf_conntrack相关的东西,比如它和NAT的关系,它和state match的关系,它的Helper机制怎么使用等等。
因此决定写一篇随笔来一个情景分析,也是方便自己终有一天遗忘了细节知识后复查。
拓扑说明
本文全文将围绕Netfilter主题的一片小的领地nf_conntrack来讨论,类似于一个情景分析,在给出全解之前,我先给出一个拓扑:
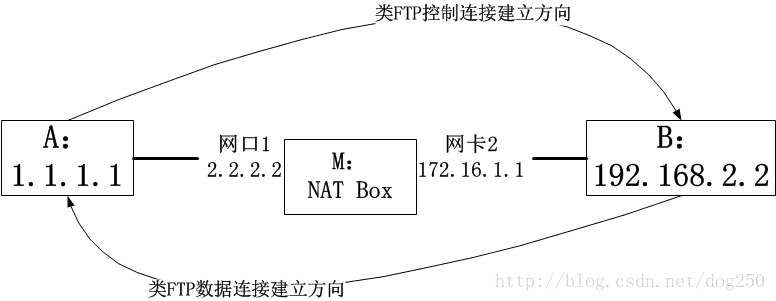
大意就是A试图与B的21端口建立一个类似FTP控制通道连接,然后B反连A的23端口,创建一个类似FTP数据通道连接,中间经过一个NAT Box的节点,旨在实现地址隔离,将1.1.1.1/2.2.2.2元组转换为172.16.1.1/192.168.2.2元组,就这么简单。
指出一点,以上的拓扑中展示的连接细节跟FTP很像,但却不是FTP,为了指出其不同之处,我来说一下B得以反连A的23端口的细节。
首先,B并不知道要反连哪个地址的哪个端口,这一切都是A在适当的时候告诉B的。
其次,A告诉B的方式很简单,就是把信息封装在应用层数据中,比如把请反连1.1.1.1的23端口这句话作为buffer写入到应用层缓存里。
因此,由于A的地址1.1.1.1已经被NAT Box改成了172.16.1.1,那么应用层buffer里的IP地址信息也应该做相应的改变,如果关联这一切,这就是本文的要旨,虽然说很简单(至少不会太难),但是对于nf_conntrack机制而言,这个案例却可以说它覆盖了其方方面面,可谓集大成者于一例,不可不学。
实例全景图解
在本节中,我将给出几幅图例,按照实际的情景了来当对应的数据包到达NAT Box的时候,Box的conntrack机制到底在做什么以及怎么做。
当来自A的TCP建链包首次从NAT Box网口1到达时
这是首次到达的SYN包,显然在此之前,NAT Box上没有关于该连接的任何记录: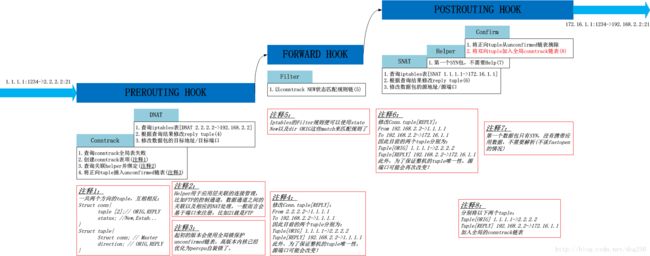
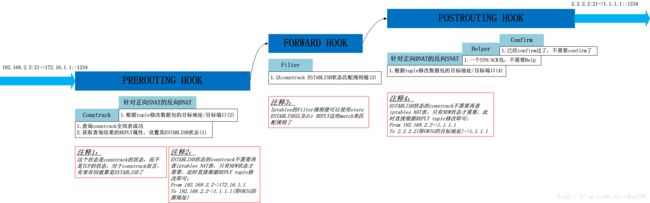
当来自B的SYN/ACK返回包从NAT Box网口2到达时
这个情景的重点在于conntrack状态的更新:
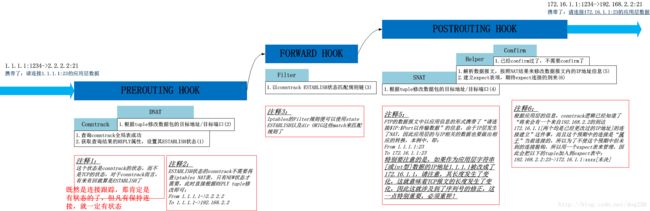
当来自A的带有反连命令的数据包从NAT Box网口1到达时
这里的重点是应用层数据的解析,即Helper开始发挥作用:
当来自B的反连A的SYN包从NAT Box网口2到达时
这是Helper使能的核心:
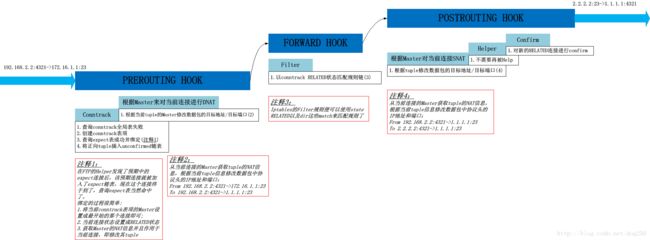
……
后续的部分我想没有必要列举了
代码提纲
看了上面的图并且看明白了,我相信你对conntrack就基本了解了,然而对于一个初学者,或者说仅仅想在简历上写上”精读过XXX代码“的人而言,没有什么比弄懂代码更有成就感了。本节我给出Linux 4.14内核版本关于conntrack实现的提纲式概览,对照着上一节的图示,我想应该能把细节全部搞明白。
Netfilter HOOK函数(只包含转发)
static const struct nf_hook_ops ipv4_conntrack_ops[] = {
{ // PREROUTING在RAW之后首先进入
.hook = ipv4_conntrack_in,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_PRE_ROUTING,
.priority = NF_IP_PRI_CONNTRACK,
},
{ // POSTROUTING在confirm之前
.hook = ipv4_helper,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_POST_ROUTING,
.priority = NF_IP_PRI_CONNTRACK_HELPER,
},
{
.hook = ipv4_confirm,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_POST_ROUTING,
.priority = NF_IP_PRI_CONNTRACK_CONFIRM,
},
};然后我们分别看下。
nf_conntrack_in的细节
nf_conntrack_in()
{
l4proto = __nf_ct_l4proto_find(pf, protonum);
// 这个error调用对于ICMP的RELATED关联比较重要
ret = l4proto->error(net, tmpl, skb, dataoff, pf, hooknum);
if (ret <= 0) {
goto out;
}
// 在既有的全局conntrack链表中查找,查不成功则创建
h = __nf_conntrack_find_get;
if (!h) {
h = init_conntrack;
}
}
init_conntrack()
{
// 分配结构体内存空间
ct = __nf_conntrack_allo
// 确认expect表中有项
if (net->ct.expect_count) {
spin_lock(&nf_conntrack_expect_lock);
// 先查找看自己是不是一个既有的连接所期待的连接
exp = nf_ct_find_expectation(net, zone, tuple);
if (exp) {
// 将其状态设置为RELARED
__set_bit(IPS_EXPECTED_BIT, &ct->status);
ct->master = exp->master;
// 继承其Master的mark
ct->mark = exp->master->mark;
}
}
if (!exp){
// 如果不属于任何期待的连接,那它就是一个潜在的Master,因此查一下看有没有和它关联的Helper,以备将来帮助它发现它自己所期待的连接。
__nf_ct_try_assign_helper
}
// 不管怎样,将其加入unconfirmed链表
nf_ct_add_to_unconfirmed_list(ct);
if (exp) {
// 这个很重要,如果Master经历了NAT的洗礼,那么会将当前的这个Slave的tuple也依照Master进行相应的更改,以帮助其在NAT Hook中顺利进行NAT
if (exp->expectfn)
exp->expectfn(ct, exp);
}
}ipv4_helper的细节
ipv4_helper
{
if (!ct || ctinfo == IP_CT_RELATED_REPLY)
return NF_ACCEPT;
help = nfct_help(ct);
helper = rcu_dereference(help->helper);
if (!helper)
return NF_ACCEPT;
return helper->help(skb, skb_network_offset(skb) + ip_hdrlen(skb),
ct, ctinfo);
}以上框架性的东西,无需解释,如果想知道help回调里到底做了什么,请参考FTP的help回调,一般人都是懂FTP协议的,所以理解起来超级典型,超级简便,比那些SIP之类的强多了,敢问除了搞视频,语音相关的,哪位能精通SIP,可是FTP可是大学标准要学习的玩意儿,要是不会,那是要考试挂科的。大体上,FTP的help回调逻辑如下:
help()
{
1.解析数据包内容,看能不能发现注册的正则模式,如果不能,则返回
2.如果发现了,则:
exp = nf_ct_expect_alloc(ct);
if (其Mater发生了NAT) {
修正新发现的exp的tuple
修正数据包中关于exp内容的IP地址,端口相关的内存
如果数据包修改前和修改后的长度不同,则标记此数据包需要调整整个TCP数据段的序列号信息,并且重新计算校验和
...
}
}也怪复杂的,然而配合上节的图示以及抓包,也是很容易理解的,毕竟这是唯一的解释,即便你不看代码,只要你能对FTP和NAT有了很好的把握,你自己也能设计出这个逻辑,如果你设计出的不是这个逻辑,那说明你错了。
ipv4_confirm的细节
ipv4_confirm()
{
if (test_bit(IPS_SEQ_ADJUST_BIT, &ct->status) &&
!nf_is_loopback_packet(skb)) {
// 如果在helper里面标记了数据包需要重新调整序号后,那么就在此处调吧
if (!nf_ct_seq_adjust(skb, ct, ctinfo, ip_hdrlen(skb))) {
return NF_DROP;
}
}
out:
return {
if (!nf_ct_is_confirmed(ct))
ret = __nf_conntrack_confirm(skb);
}
}关于Helper的注册
nf_conntrack有一个nf_conntrack_helper_register接口用于注册一个Helper,在调用该接口前,需要初始化一个nf_conntrack_helper结构体,nf_conntrack同样提供了很方便的接口来帮你进行数据结构的初始化,即nf_ct_helper_init。
以标准FTP为例,其nf_conntrack_helper结构体会包含端口信息,比如默认就是TCP端口21,在该Helper注册成功后,它将成为匹配链的一员,每当调用init_conntrack初始化一个conntrack表项的时候,均会用当前数据包的端口信息去匹配Helper匹配链,试图绑定一个Helper,以便在合适的时候,帮助其解析或者适配应用层的信息。
注意事项
他们总说conntrack效率低下甚至使用了conntrack之后会急剧影响Linux Box的网络处理性能,然而内核社区却一直没有取消conntrack甚至都没有发出过类似的声音,这说明前面说的这帮人是多么不可理喻,他们某时仅仅会求教于别人彻底去除conntrack的方法,然而当我反问“你能列出可以替代state match的规则吗?如果可以,那就可以去掉conntrack”,他们却根本不知道我在说什么,当然,我所提到的肯定跟state match相关,不过话又说回来,如果他们知道了state match的本质,他们肯定也就知道如何彻底去除conntrack的方法,所以说这不能怪他们。还是那句话,不与无知者辩论,沉默是金。
不管怎么说,虽然我并不认为conntrack存在问题,但是还是要说下使用conntrack时要注意的几个问题,我归纳了三个:
避开不必要的自旋锁
- init_conntrack调用时expect查表自旋锁
高版本内核已经已经优化为有条件查询了,具体要不要查询取决于当前expect表中有没有可用项。 - init_conntrack调用时的unconfirmed list自旋锁
高版本内核已经被优化成percpu,不用担心。 - helper调用时发现应用层数据需要help时的expect插入自旋锁
比如本文所示的类FTP实例,当Helper逻辑发现了应用层存在一个预期的连接时,会插入一个项到expect表中,这个时候会使用一个自旋锁来保护插入动作。
这里的问题在于,即便你的系统中只有一个流创建了哪怕一个expect表项,所有的流在进入conntrack逻辑时均将会去查询expect表以确定自己是不是一个从属于一个Master的Slave,这意味着所有的流都要去抢这个全局的expect自旋锁,这件事是悲哀的。如何优化掉它呢?请自行思考。 - confirm时的unconfirmed自旋锁
在一个流被confirm时,它首先要从unconfirmed链表中被删除,如前所述,这个锁已经优化为percpu的了,因此不必担心。 - confirm时的全局自旋锁
在一个流被confrm时,它的ORIG tuple和REPLY tuple(如果发生了NAT,REPLY tuple会被更改)会被同时插入到一个全局的hash链表中,此时需要一个自旋锁保护,这是避不开的,好在这个锁对于一个连接而言只需要锁两次,一次是confirm时,一次是被删除时,这显然意味着我们不必过分担心。
然而,问题在于,如果存在大量的短链接或者同时有大量的连接(比如TCP Timewait)被销毁,这笔开销将是高昂且不可避免的。更有甚至,如果存在DDoS攻击,很多不请自来的数据包将会confirm海量的数据流,自旋锁将会锁死整个江湖…关于这个问题,请参见:
SYNPROXY抵御DDoS攻击的原理和优化:http://blog.csdn.net/dog250/article/details/77920696
注意CPU和内存操作
仅说几句,不会逗留。
如果一个变态的熟知协议在应用层牵扯了大量的IP层信息,且该协议在Linux系统中注册了Helper,那么当NAT发生的时候,Helper将花费高昂的成本对应用层的IP地址以及端口信息进行不得已的适配性修改(底层的IP信息被修改要求上层做对应适配),这种内存操作是不可避免的。那么你会怎么选择呢?不注册Helper任其默默失败以保持性能,还是说来者不拒式地提供服务?
除此之外,抛开内存我们想象一下CPU资源的一种浪费方式。如果应用层保存了大量的基于IP地址的校验码,是不是意味着在NAT发生了之后要将其重新计算一遍呢?
注意net.nf_conntrack_max的大小
这个就不啰嗦了,如果你的机器内存足够,不要吝啬,多多的用于网络协议栈是没有坏处的,特别是当你的机器用于转发设备而不是服务器时,这意味着你没有数据库的开销,没有应用服务器的开销,你的内存设置甚至都不会用于TCP/UDP(我一再强调TCP/UDP属于端到端的技术范畴,而根本就不属于网络技术范畴),因为数据根本就到不了四层处理…那你的内存何用呢?
…..
时间和精力关系,我只能列出以上几点了,如果有人连上面这些都说不上,那还有什么资格说conntrack不好呢?当然,请忽略并原谅那些人云亦云的人。
___________________________
该track的就使用conntrack,不该track的就NOTRACK,这难道不是正确的解题思路吗?如果你在抱怨为什么iptables提供了NOTRACK却没有提供TRACK,那干嘛不去试试ipset呢?其实我自己在很多年前也抱怨过,也人云亦云过,但随着我对Netfilter各个机制各个模块不断深入的理解,我发现即便有问题,不还是可以解决的嘛,如果在根本一无所知的情况下去抵触一个东西,当然不可能有任何解决问题的办法,除了抱怨。
后记
一天喝8杯水原来是卖水的广告语,悟性不好的人再努力也不会成为佼佼者,四大美女原来凭的不是长相而是品德,喝酒伤身原来应该把“喝”改成“酗”,原来南方城市和农村过年不吃饺子,粽子和月饼一开始就是包肉的,在这个真假难辨的年代,我知道的唯一确定的事情就是吸烟有害健康!
我不是流言终结者,但我也不会人云亦云,听说某人很牛逼,那必然至少在我面前耍两下才能承认他牛逼,不然都是别人或者他自己吹的。曾经偶然偶尔的一次功绩让一个人成为了神,那他就是永远的神,这显然是屁理论,不信你去问问被人捅了几十刀的Gaius Julius Caesar大神,但人们有找到自己崇拜的人的需求,所以才造就了很多的假大神。
所以当我听到或者看到一群连conntrack是什么都不懂的人在瞎BB什么conntrack影响性能之类的Pi话,我就感到非常气愤…最终还是选择了奥迪,我倒要看看大部分出自键盘侠的喷子们所说的烧机油是不是真的!